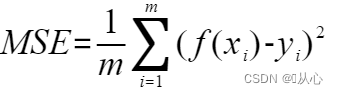近年来随着扩散模型(diffusion models)的进步和发展,给定文本提示进行高质量视频生成技术有着显著的提升。这些技术方案大多针对已有的二维图像扩散模型进行拓展,将图像二维神经网络修正为视频三维神经网络,并基于扩散概率模型进行视频帧序列的去噪,完成视频生成。然而,这些现有方法依然围绕着单个场景的视频生成,对于多场景视频生成并未考虑,并且生成的视频长度也仅为2秒到4秒。
基于这样的问题,来自HiDream.ai公司的算法研究人员提出利用大语言模型针对输入的文本提示进行多场景事件描述的拓展,保证不同事件之间的逻辑性和场景中前景背景描述的一致性。其后,针对大语言模型提供的每一个事件所对应的前景背景描述,以及动作描述,利用视频扩散模型生成具有内容一致的视频片段,从而构建一个多场景的长视频。

项目主页: VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM
01. 研究背景:多场景视频生成任务及难点
当下基于扩散模型的视频生成主要针对单个场景下的动作事件,而对多场景的视频生成鲜有涉及。给定一个文本提示,并且生成具有良好逻辑性的多场景视频,是本工作研究的重点。相应的技术难点主要体现在以下两个方面:
- 如何保证不同事件之间具有良好的逻辑性(例如,给定文本提示为一个男孩踢球射门,在时序上男孩应该先进行运球,然后射门)
- 如何保证生成视频主体的视觉外貌特征一致(例如,以男孩踢球射门为例,不同场景下男孩的外貌穿着应该保持一致)
02. 以大语言模型为基础的内容一致多场景视频生成模型:VideoDrafter
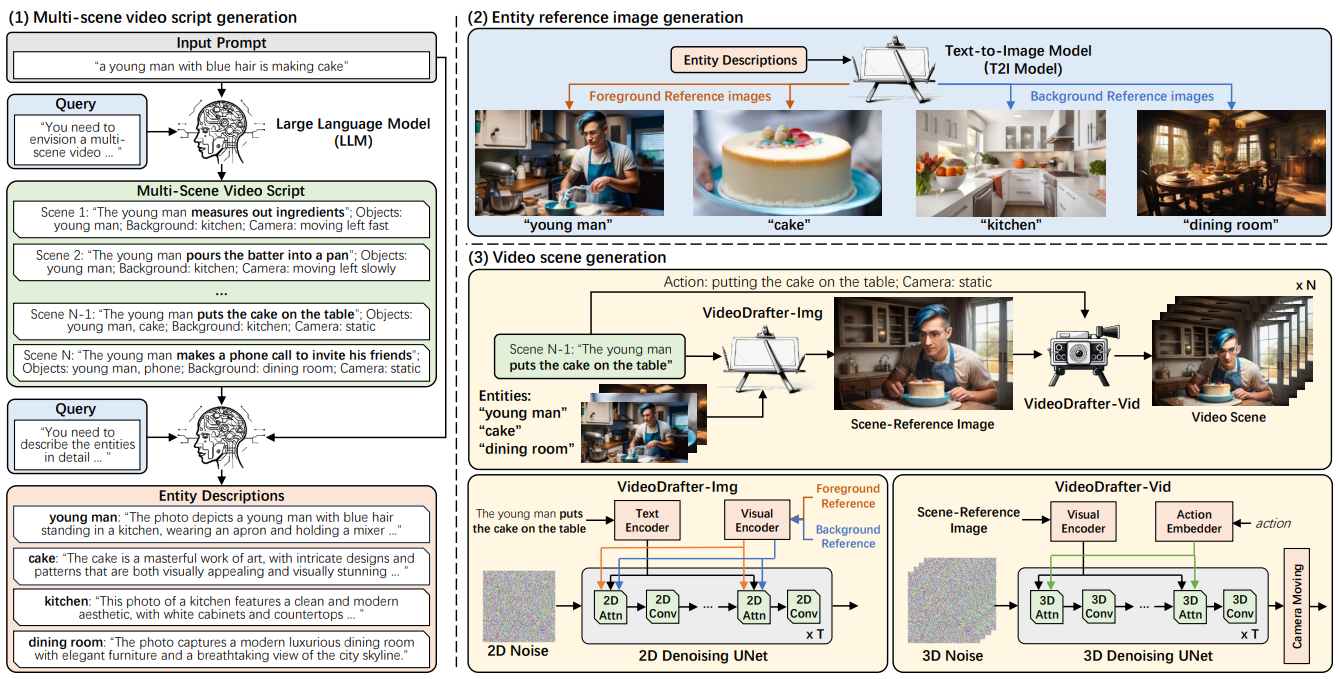
针对上述的两个技术难点,本工作提出了一个以大语言模型为基础的内容一致多场景视频生成方案VideoDrafter。该方案通过主要的三个步骤完成多场景视频生成。
第一步是首先通过大语言模型对输入的文本提示进行多场景事件描述拓写,将输入的单句文本转换为多场景的视频描述(Multi-scene video script generation),并且输出每个事件对应的前景和背景实体描述(Entity description)。
第二步是将每个事件对应的前景和背景实体描述利用文本到图像的扩散模型生成对应的前景和背景实体参考图(Entity reference image generation)。
最后一步是针对每个事件对应前景和背景实体参考图,以及事件的动作描述,利用视频扩散模型完成对该事件的视频生成。这里的最后一步本方案拆解为主要的两个步骤,即首先通过VideoDrafter-Img模型,利用前景和背景实体参考图以及事件动作描述,生成对应的场景事件参考图片(Scene reference image);然后通过VideoDrafter-Vid模型,再将动作赋予给场景事件参考图片,生成对应场景的视频。
本方案利用大语言模型保证了生成的不同事件描述的逻辑性,同时利用前景和背景实体参考图指导不同场景下视频内容的生成,因此可以良好地保证不同场景中的内容实体的视觉外貌特征的一致性。
03. 视频生成结果
首先用户可以通过输入一个文本提示(input prompt),生成具有良好逻辑性的,内容一致的多场景视频,以下是对应的文本提示和多场景视频生成结果:
生成视频1:

生成视频2:

生成视频3:

动态视频例子:


其次,对于用户提供的真实图像作为前景和背景实体参考图,以及对应的事件文本提示,本方案同样可以生成内容一致的多场景视频,生成的视频结果如下:

动态视频例子:


(对应文本提示:The cat lies in the room → The cat lies in the driving car → The cat plays in the flowers)


(对应文本提示:The motorcyclist stays in the town → The motorcyclist is riding on the road under the sunset → The motorcyclist is riding on the moon)
对该方案的完整性能评测,以及更多的视频生成例子,请参考论文和对应的项目主页。
04. 总结
- 本方案提出了VideoDrafter模型,一种以大语言模型为基础的内容一致多场景视频生成技术。
- 利用大语言模型对文本信息的强理解性,对输入的单个文本提示进行多场景视频事件的拓写,保证不同视频事件的逻辑相关性。
- 在对应不同事件的不同场景视频生成的过程中,利用前景和背景实体参考图指导视频的生成,保证了不同场景中视频内容主体在视觉外貌特征上的一致性。
- 本方案提及的多场景视频生成方案,对大语言模型的利用和保持视频内容一致性的尝试,希望对后续具有因果关系的视频生成具有一定的启发作用。
更多的技术细节,敬请参考论文原文。
































![[前车之鉴] SpringBoot原生使用Hikari数据连接池升级到动态多数据源的深坑解决方案 & RocketMQ吞掉异常问题排查](https://img-blog.csdnimg.cn/direct/34358f5a2f1d46719d7f8a1e2a3c2724.png)