目录
目录
前言
Orchestrator另外一个重要的功能是监控集群,发现故障。根据从复制拓扑本身获得的信息,它可以识别各种故障场景。Orchestrator介绍四-失败/故障检测_orchestrator 心跳-CSDN博客
核心流程函数调用路径
ContinuousDiscovery
--> CheckAndRecover // 检查恢复的入口函数
--> GetReplicationAnalysis // 查询SQL,根据实例的状态确定故障或者警告类型。检查复制问题 (dead master; unreachable master; 等)
--> executeCheckAndRecoverFunction // 根据分析结果选择正确的检查和恢复函数。然后会同步执行该函数。
--> getCheckAndRecoverFunction // 根据分析结果选择正确的检查和恢复函数。然后会同步执行该函数。
--> runEmergentOperations //
--> checkAndExecuteFailureDetectionProcesses // 尝试往数据库中插入这个故障发现记录,然后执行故障发现阶段所需的操作,执行 OnFailureDetectionProcesses (故障发现阶段的)钩子脚本
--> AttemptFailureDetectionRegistration // 尝试往数据库中插入故障发现记录 ,如果失败 意味着这个问题可能已经被发现了,
--> checkAndRecoverDeadMaster // 根据故障情况 执行恢复,这里选择DeadMaster 故障类型举例
--> AttemptRecoveryRegistration // 尝试往数据库中插入一条恢复记录;如果这一尝试失败,那么意味着恢复已经在进行中。
--> recoverDeadMaster // 用于恢复DeadMaster故障类型的函数,其中包含了完整的逻辑。会执行PreFailoverProcesses 钩子脚本GetReplicationAnalysis
该函数将检查复制问题 (dead master; unreachable master; 等),根据实例的状态确定故障或者警告类型。
该函数会运行一个复杂SQL ,该SQL会每秒执行一次 ,执行间隔是由定时器 recoveryTick决定 ,SQL如下
SELECT
master_instance.hostname,
master_instance.port,
master_instance.read_only AS read_only,
MIN(master_instance.data_center) AS data_center,
MIN(master_instance.region) AS region,
MIN(master_instance.physical_environment) AS physical_environment,
MIN(master_instance.master_host) AS master_host,
MIN(master_instance.master_port) AS master_port,
MIN(master_instance.cluster_name) AS cluster_name,
MIN(master_instance.binary_log_file) AS binary_log_file,
MIN(master_instance.binary_log_pos) AS binary_log_pos,
MIN(
IFNULL(
master_instance.binary_log_file = database_instance_stale_binlog_coordinates.binary_log_file
AND master_instance.binary_log_pos = database_instance_stale_binlog_coordinates.binary_log_pos
AND database_instance_stale_binlog_coordinates.first_seen < NOW() - interval 10 second,
0
)
) AS is_stale_binlog_coordinates,
MIN(
IFNULL(
cluster_alias.alias,
master_instance.cluster_name
)
) AS cluster_alias,
MIN(
IFNULL(
cluster_domain_name.domain_name,
master_instance.cluster_name
)
) AS cluster_domain,
MIN(
master_instance.last_checked <= master_instance.last_seen
and master_instance.last_attempted_check <= master_instance.last_seen + interval 6 second
) = 1 AS is_last_check_valid,
/* To be considered a master, traditional async replication must not be present/valid AND the host should either */
/* not be a replication group member OR be the primary of the replication group */
MIN(master_instance.last_check_partial_success) as last_check_partial_success,
MIN(
(
master_instance.master_host IN ('', '_')
OR master_instance.master_port = 0
OR substr(master_instance.master_host, 1, 2) = '//'
)
AND (
master_instance.replication_group_name = ''
OR master_instance.replication_group_member_role = 'PRIMARY'
)
) AS is_master,
MIN(
master_instance.replication_group_name != ''
AND master_instance.replication_group_member_state != 'OFFLINE'
) AS is_replication_group_member,
MIN(master_instance.is_co_master) AS is_co_master,
MIN(
CONCAT(
master_instance.hostname,
':',
master_instance.port
) = master_instance.cluster_name
) AS is_cluster_master,
MIN(master_instance.gtid_mode) AS gtid_mode,
COUNT(replica_instance.server_id) AS count_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
),
0
) AS count_valid_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.slave_io_running != 0
AND replica_instance.slave_sql_running != 0
),
0
) AS count_valid_replicating_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.slave_io_running = 0
AND replica_instance.last_io_error like '%error %connecting to master%'
AND replica_instance.slave_sql_running = 1
),
0
) AS count_replicas_failing_to_connect_to_master,
MIN(master_instance.replication_depth) AS replication_depth,
GROUP_CONCAT(
concat(
replica_instance.Hostname,
':',
replica_instance.Port
)
) as slave_hosts,
MIN(
master_instance.slave_sql_running = 1
AND master_instance.slave_io_running = 0
AND master_instance.last_io_error like '%error %connecting to master%'
) AS is_failing_to_connect_to_master,
MIN(
master_downtime.downtime_active is not null
and ifnull(master_downtime.end_timestamp, now()) > now()
) AS is_downtimed,
MIN(
IFNULL(master_downtime.end_timestamp, '')
) AS downtime_end_timestamp,
MIN(
IFNULL(
unix_timestamp() - unix_timestamp(master_downtime.end_timestamp),
0
)
) AS downtime_remaining_seconds,
MIN(
master_instance.binlog_server
) AS is_binlog_server,
MIN(master_instance.pseudo_gtid) AS is_pseudo_gtid,
MIN(
master_instance.supports_oracle_gtid
) AS supports_oracle_gtid,
MIN(
master_instance.semi_sync_master_enabled
) AS semi_sync_master_enabled,
MIN(
master_instance.semi_sync_master_wait_for_slave_count
) AS semi_sync_master_wait_for_slave_count,
MIN(
master_instance.semi_sync_master_clients
) AS semi_sync_master_clients,
MIN(
master_instance.semi_sync_master_status
) AS semi_sync_master_status,
SUM(replica_instance.is_co_master) AS count_co_master_replicas,
SUM(replica_instance.oracle_gtid) AS count_oracle_gtid_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.oracle_gtid != 0
),
0
) AS count_valid_oracle_gtid_replicas,
SUM(
replica_instance.binlog_server
) AS count_binlog_server_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.binlog_server != 0
),
0
) AS count_valid_binlog_server_replicas,
SUM(
replica_instance.semi_sync_replica_enabled
) AS count_semi_sync_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.semi_sync_replica_enabled != 0
),
0
) AS count_valid_semi_sync_replicas,
MIN(
master_instance.mariadb_gtid
) AS is_mariadb_gtid,
SUM(replica_instance.mariadb_gtid) AS count_mariadb_gtid_replicas,
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.mariadb_gtid != 0
),
0
) AS count_valid_mariadb_gtid_replicas,
IFNULL(
SUM(
replica_instance.log_bin
AND replica_instance.log_slave_updates
),
0
) AS count_logging_replicas,
IFNULL(
SUM(
replica_instance.log_bin
AND replica_instance.log_slave_updates
AND replica_instance.binlog_format = 'STATEMENT'
),
0
) AS count_statement_based_logging_replicas,
IFNULL(
SUM(
replica_instance.log_bin
AND replica_instance.log_slave_updates
AND replica_instance.binlog_format = 'MIXED'
),
0
) AS count_mixed_based_logging_replicas,
IFNULL(
SUM(
replica_instance.log_bin
AND replica_instance.log_slave_updates
AND replica_instance.binlog_format = 'ROW'
),
0
) AS count_row_based_logging_replicas,
IFNULL(
SUM(replica_instance.sql_delay > 0),
0
) AS count_delayed_replicas,
IFNULL(
SUM(replica_instance.slave_lag_seconds > 10),
0
) AS count_lagging_replicas,
IFNULL(MIN(replica_instance.gtid_mode), '') AS min_replica_gtid_mode,
IFNULL(MAX(replica_instance.gtid_mode), '') AS max_replica_gtid_mode,
IFNULL(
MAX(
case when replica_downtime.downtime_active is not null
and ifnull(replica_downtime.end_timestamp, now()) > now() then '' else replica_instance.gtid_errant end
),
''
) AS max_replica_gtid_errant,
IFNULL(
SUM(
replica_downtime.downtime_active is not null
and ifnull(replica_downtime.end_timestamp, now()) > now()
),
0
) AS count_downtimed_replicas,
COUNT(
DISTINCT case when replica_instance.log_bin
AND replica_instance.log_slave_updates then replica_instance.major_version else NULL end
) AS count_distinct_logging_major_versions
FROM
database_instance master_instance
LEFT JOIN hostname_resolve ON (
master_instance.hostname = hostname_resolve.hostname
)
LEFT JOIN database_instance replica_instance ON (
COALESCE(
hostname_resolve.resolved_hostname,
master_instance.hostname
) = replica_instance.master_host
AND master_instance.port = replica_instance.master_port
)
LEFT JOIN database_instance_maintenance ON (
master_instance.hostname = database_instance_maintenance.hostname
AND master_instance.port = database_instance_maintenance.port
AND database_instance_maintenance.maintenance_active = 1
)
LEFT JOIN database_instance_stale_binlog_coordinates ON (
master_instance.hostname = database_instance_stale_binlog_coordinates.hostname
AND master_instance.port = database_instance_stale_binlog_coordinates.port
)
LEFT JOIN database_instance_downtime as master_downtime ON (
master_instance.hostname = master_downtime.hostname
AND master_instance.port = master_downtime.port
AND master_downtime.downtime_active = 1
)
LEFT JOIN database_instance_downtime as replica_downtime ON (
replica_instance.hostname = replica_downtime.hostname
AND replica_instance.port = replica_downtime.port
AND replica_downtime.downtime_active = 1
)
LEFT JOIN cluster_alias ON (
cluster_alias.cluster_name = master_instance.cluster_name
)
LEFT JOIN cluster_domain_name ON (
cluster_domain_name.cluster_name = master_instance.cluster_name
)
WHERE
database_instance_maintenance.database_instance_maintenance_id IS NULL
AND '' IN ('', master_instance.cluster_name)
GROUP BY
master_instance.hostname,
master_instance.port
HAVING
(
MIN(
master_instance.last_checked <= master_instance.last_seen
and master_instance.last_attempted_check <= master_instance.last_seen + interval 6 second
) = 1
/* AS is_last_check_valid */
) = 0
OR (
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.slave_io_running = 0
AND replica_instance.last_io_error like '%error %connecting to master%'
AND replica_instance.slave_sql_running = 1
),
0
)
/* AS count_replicas_failing_to_connect_to_master */
> 0
)
OR (
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
),
0
)
/* AS count_valid_replicas */
< COUNT(replica_instance.server_id)
/* AS count_replicas */
)
OR (
IFNULL(
SUM(
replica_instance.last_checked <= replica_instance.last_seen
AND replica_instance.slave_io_running != 0
AND replica_instance.slave_sql_running != 0
),
0
)
/* AS count_valid_replicating_replicas */
< COUNT(replica_instance.server_id)
/* AS count_replicas */
)
OR (
MIN(
master_instance.slave_sql_running = 1
AND master_instance.slave_io_running = 0
AND master_instance.last_io_error like '%error %connecting to master%'
)
/* AS is_failing_to_connect_to_master */
)
OR (
COUNT(replica_instance.server_id)
/* AS count_replicas */
> 0
)
ORDER BY
is_master DESC,
is_cluster_master DESC,
count_replicas DESC\G故障类型和对应的处理函数
| 故障类型 | 处理函数 |
| NoProblem | 没有 |
| DeadMasterWithoutReplicas | 没有 |
| DeadMaster | checkAndRecoverDeadMaster |
| DeadMasterAndReplicas | checkAndRecoverGenericProblem |
| DeadMasterAndSomeReplicas | checkAndRecoverDeadMaster |
| UnreachableMasterWithLaggingReplicas | checkAndRecoverGenericProblem |
| UnreachableMaster | checkAndRecoverGenericProblem |
| MasterSingleReplicaNotReplicating | |
| MasterSingleReplicaDead | |
| AllMasterReplicasNotReplicating | checkAndRecoverGenericProblem |
| AllMasterReplicasNotReplicatingOrDead | checkAndRecoverGenericProblem |
| LockedSemiSyncMasterHypothesis | |
| LockedSemiSyncMaster | checkAndRecoverLockedSemiSyncMaster |
| MasterWithTooManySemiSyncReplicas | checkAndRecoverMasterWithTooManySemiSyncReplicas |
| MasterWithoutReplicas | |
| DeadCoMaster | checkAndRecoverDeadCoMaster |
| DeadCoMasterAndSomeReplicas | checkAndRecoverDeadCoMaster |
| UnreachableCoMaster | |
| AllCoMasterReplicasNotReplicating | |
| DeadIntermediateMaster | checkAndRecoverDeadIntermediateMaster |
| DeadIntermediateMasterWithSingleReplica | checkAndRecoverDeadIntermediateMaster |
| DeadIntermediateMasterWithSingleReplicaFailingToConnect | checkAndRecoverDeadIntermediateMaster |
| DeadIntermediateMasterAndSomeReplicas | checkAndRecoverDeadIntermediateMaster |
| DeadIntermediateMasterAndReplicas | checkAndRecoverGenericProblem |
| UnreachableIntermediateMasterWithLaggingReplicas | checkAndRecoverGenericProblem |
| UnreachableIntermediateMaster | |
| AllIntermediateMasterReplicasFailingToConnectOrDead | checkAndRecoverDeadIntermediateMaster |
| AllIntermediateMasterReplicasNotReplicating | |
| FirstTierReplicaFailingToConnectToMaster | |
| BinlogServerFailingToConnectToMaster | |
| // Group replication problems | |
| DeadReplicationGroupMemberWithReplicas | checkAndRecoverDeadGroupMemberWithReplicas |
拓扑结构警告类型
- StatementAndMixedLoggingReplicasStructureWarning
- StatementAndRowLoggingReplicasStructureWarning
- MixedAndRowLoggingReplicasStructureWarning
- MultipleMajorVersionsLoggingReplicasStructureWarning
- NoLoggingReplicasStructureWarning
- DifferentGTIDModesStructureWarning
- ErrantGTIDStructureWarning
- NoFailoverSupportStructureWarning
- NoWriteableMasterStructureWarning
- NotEnoughValidSemiSyncReplicasStructureWarning
与MHA相比
MHA探活
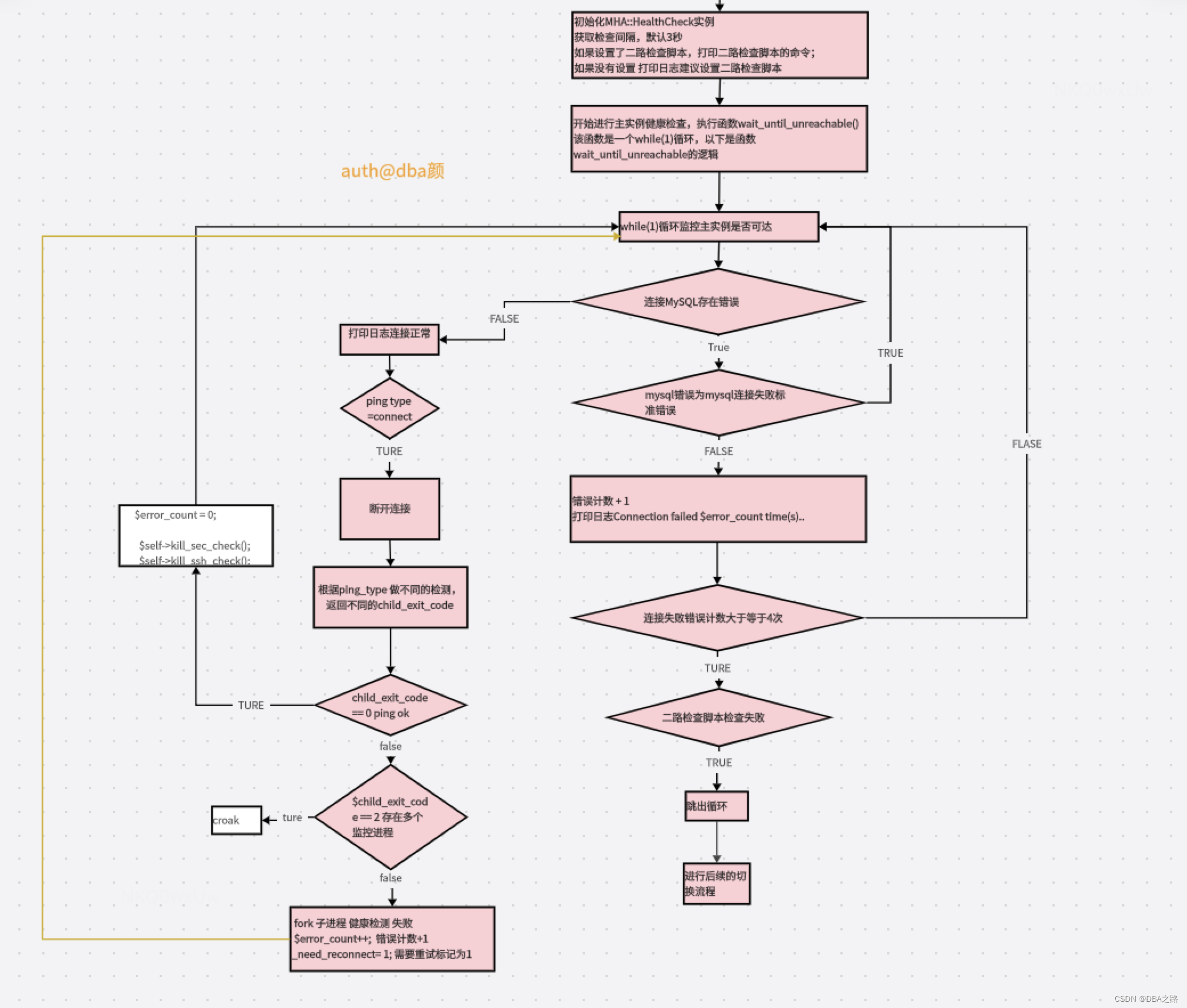
核心功能主要有 MHA::HealthCheck::wait_until_unreachable 实现:
该函数通过一个死循环,检测 4 次,每次 sleep ping_interval 秒(这个值在配置文件指定,参数是 ping_interval),持续四次失败,就认为数据已经宕机;
如果有二路检测脚本,需要二路检测脚本检测主库宕机,才是真正的宕机,否则只是推出死循环,结束检测,不切换
通过添加锁来保护数据库的访问,防止脚本多次启动;
该函数可调用三种检测方法:ping_select、ping_insert、ping_connect
MHA探活流程图
| MHA | OC | |
| 故障类型 | 故障类型单一, 主要就是主库是否存活 |
故障类型丰富 有多种故障与警告类型 见上面的总结 |
| 探活节点 | 支持多个节点探活 即manager服务器与二次检查脚本中定义的服务器 |
多个OC节点 以及 配合该实例的从库复制状态是否正常进行检测 |
| 探活方式 | ping_select、 ping_insert、 ping_connect |
查询被管理的数据库,将数据写入到OC的后台管理数据库中,进行时间戳的比较或状态值比较等方式 |
| 探活间隔 | 默认3秒 | 默认每1秒 |
| 探活次数 | 4次 | 1次 |
| 故障探测速度 | 慢,需要多次探活。 | 快 |
| 探活理念 | 多次多个节点避免网络抖动等 | 配合从副本的主从状态以及OC节点的探活 |