版本:Centos 7 Hadoop 3.2.0 JDK 1.8
虚拟机信息:内存3.2G 处理器 2*2 内存50G
ISO:Centos-7-x86_64-DVD-2009
一、在虚拟机上搭建Linux Centos7
略
二、选择root登录并管理防火墙
systemctl stop direwalld # 关闭防火墙
systemctl disable firewalld # 关闭开机自启
systemctl status firewalld # 查看防火墙状态
三、实现ssh免密码登录
配置ssh的无密码访问
ssh-keygen -t rsa
连续按回车

cd ~/.ssh
cat id_rsa.pub >> authorized_keys
vi ~/.bashrc # ssh服务开机自启
在文件最末尾加上:
/etc/init.d/ssh start
立即生效
source ~/.bashrc
四、Centos 7 安装 JDK 1.8
安装之前先查看系统是否自带jdk,有的话先卸载
rpm -qa | grep jdk # 查询
rpm -e --nodeps # 卸载
rpm -qa | grep java # 检查是否卸载干净
java -version
卸载完重新安装jdk1.8
yum list java* # 查看可安装版本
yum -y install java-1.8.0-openjdk* # 安装1.8版本的openjdk
查看安装位置
rpm -qa | grep java
rpm -ql java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64
配置全局变量
vi ~/.bashrc # 当前用户
vi /etc/profile # 全局用户
添加
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
执行
source ~/.bashrc
source /etc/profile
验证安装
which java
java -version
五、下载Hadoop
我是用的Hadoop版本是3.2.0
Hadoop下载地址
上传文件并解压缩,并在opt目录下创建一个名为hadoop的目录,并将下载好的hadoop-3.2.0.tar解压到该目录
mkdir /opt/hadoop
tar -zxvf hadoop-3.2.0-tar.gz
配置Hadoop环境变量
vim ~/.bashrc
添加Hadoop环境变量
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:/opt/hadoop/hadoop-3.2.0/bin:/opt/hadoop/hadoop-3.2.0/sbin
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.0
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
tips:这里的$PATH:$JAVA_HOME/bin:/opt/hadoop/hadoop-3.2.0/bin:/opt/hadoop/hadoop-3.2.0/sbin表示在保留原来的$PATH环境变量的基础上,再增加$JAVA_HOME/bin和/opt/hadoop/hadoop-3.2.0/bin和/opt/hadoop/hadoop-3.2.0/sbin这些路径作为新的$PATH环境变量。
source ~/.bashrc # 使修改生效
六、 Hadoop配置文件修改
新建目录
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
修改etc/hadoop中的一系列配置文件
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/core-site.xml
在节点内加入配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
修改hadoop-env.sh
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
修改hdfs-site.xml
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
在节点内加入配置
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
新建并修改mapred-site-xml
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/mapred-site.xml
在节点内加入配置
<configuration>
<!-- 配置mapReduce在Yarn上运行(默认本地运行) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改workers文件
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/workers
将里面的localhost删除,添加以下内容(master和node1节点都要修改)
master
node1
tips:这里面不能有多余空格,文件中不允许有空行
7、 xsync命令直接分发集群具体配置(可跳过)
xsync是对rsync脚本的二次封装,需要给每台服务器下载rsync
yum install -y rsync
修改/usr/local/bin/下得xsync文件,如果没有就新建
cd /usr/local/bin/
vim xsync
文件中加入以下内容
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0))
then
echo no args
exit
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=20; host<=21;host++))
do
echo ------------------- @192.168.95.$host --------------
rsync -rvl $pdir/$fname $user@192.168.95.$host:$pdir/
done
给脚本文件可执行权限
chomod 777 xsync
sudo cp xsync /bin # 拷贝到系统目录bin下
xsync /opt/hadoop/hadoop-3.2.0/etc # 使用xsync命令分发配置
7.1 修改yarm-site.xml文件
hadoop classpath
vi /opt/hadoop/hadopp-3.2.0/etc/hadoop/yarn-site.xml
添加一个配置
<property>
<name>yarn.application.classpath</name>
<value>hadoop classpath返回信息</value>
</property>
查看我得yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop/hadoop-3.2.0/etc/hadoop:/opt/hadoop/hadoop-3.2.0/share/hadoop/common/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/common/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn/*</value>
</property>
</configuration>
配置hadoop-3.2.0/sbin/目录下start-dfs.sh、start-yarn.sh、stop-dfs.sh、stop-yarn.sh文件
cd /opt/hadoop/hadoop-3.2.0 # 服务启动权限配置
vi sbin/start-dfs.sh # 配置start-dfs 和 stop-dfs.sh 文件
vi sbin/stop-dfs.sh
加入下面内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置start-yarn.sh与stop-yarn.sh文件
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
加入下面内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置好基础设置(SSH、JDK、Hadooop、环境变量、Hadoop和MapReduce配置信息)后,克隆虚拟机,获得从机node1节点
如果已经复制master为node1节点虚拟机了,但是node1节点的Hadoop配置文件信息还没修改,那么我们直接可以在master节点中运行下面这条命令,将已经配置好的Hadoop配置信息分发给集群各节点,这样我们就不用再修改其它节点的Hadoop配置文件了:
xsync /opt/hadoop/hadoop-3.2.0/etc/hadoop
8、克隆master主机后的设置
修改网卡信息
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改node1节点主机名
vi /etc/hostname
修改node1节点对应的ip和主机名
vim /etc/hosts
master节点和node1节点连接
ssh node1
ssh master
互联成功,exit退出
九、启动Hadoop
进入到master主机的/opt/hadoop/hadoop-3.2.0/bin目录
cd /opt/hadoop/hadoop-3.2.0/bin
./hadoop nameode -format # 执行初始化脚本
./sbin/start-all.sh # 执行启动进程
jps # 查看启动情况
运行结果
访问http://192.168.95.20:9870/
我忘了截图 略
使用以下命令配置
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input # 在hdfs上建立一个目录存放文件
./bin/hdfs dfs -ls /home/hadoop/myx/wordcount/input # 查看分发复制是否正常
十、运行MapReduce集群
在hdfs上简历一个目录存放文件
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input
简单写两个文件测试以下
vim text1
加入下面内容
hadoop is very good
mapreduce is very good
将两个文件存入hdfs并用wordcount进行处理
./bin/hdfs dfs -put text1 //home/hadoop/myx/wordcount/input
查看分发情况
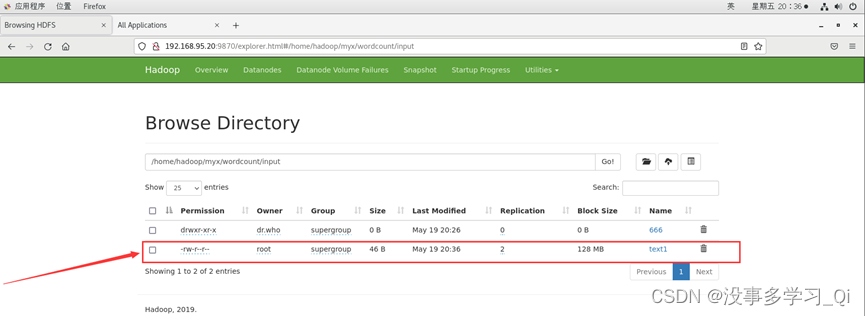
运行MapReduce用WordCount处理
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /home/hadoop/myx/wordcount/input /home/hadoop/myx/wordcount/output
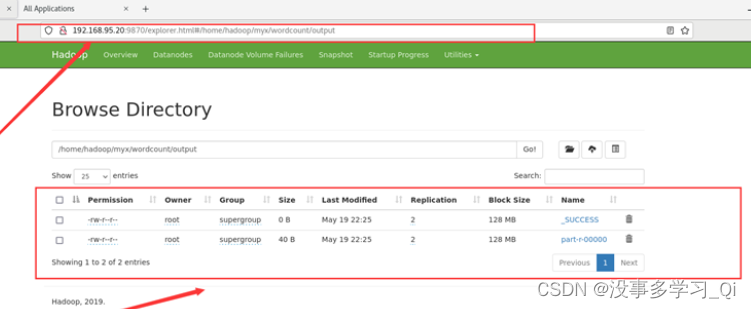
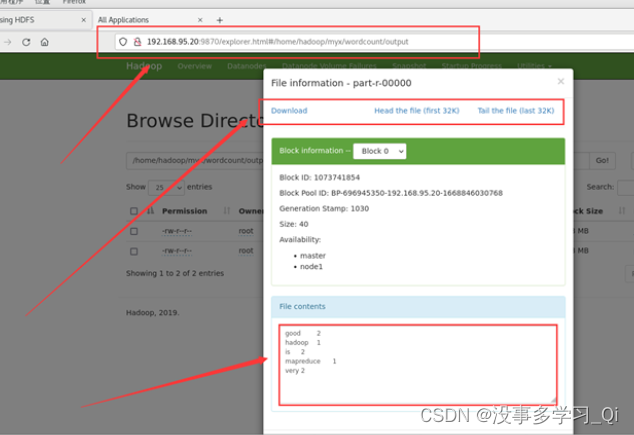
最终结果会存储在指定的输出目录中,查看输出目录里面可以看到以下内容
./bin/hdfs dfs -cat /home/hadoop/myx/wordcount/output/part-r-00000*

web端查看
http://192.168.95.20:9870/explorer.html#/home/hadoop/myx/wordcount/output
十一、运行测试程序WordCount
新建文件夹WordCount
mkdir WordCount
ls
cd WordCount
vim file1.txt
file1.txt file2.txt文件内容为
This is the first hadoop test program!
This program is not very difficult,but this program is a common hadoop program!
在Hadoop文件系统HDFS中/home目录下新建文件夹input
cd /opt/hadoop/hadoop-3.2.0
./bin/hadoop fs -mkdir /input
./bin/hadoop fs -ls /
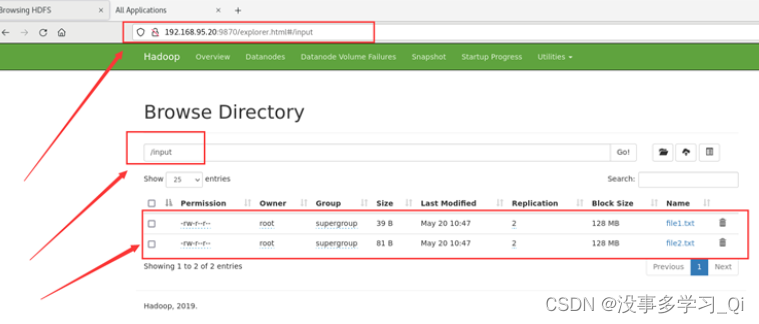
在浏览器端查看
http://192.168.95.20:9870/explorer.html#/input
将WordCount文件夹中file1.txt\file2.txt文件上传到刚刚创建的“input”文件夹
./bin/hadoop fs -put /opt/hadoop/hadoop-3.2.0/WordCount/*.txt /input
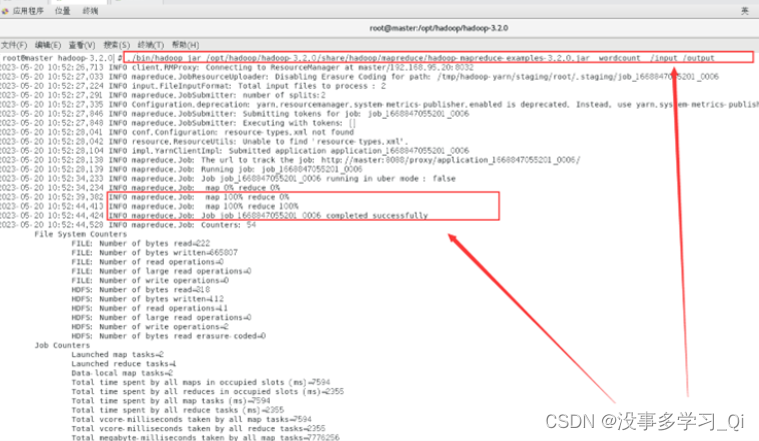
运行Hadoop的示例程序,设置输出的目录为/output
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output
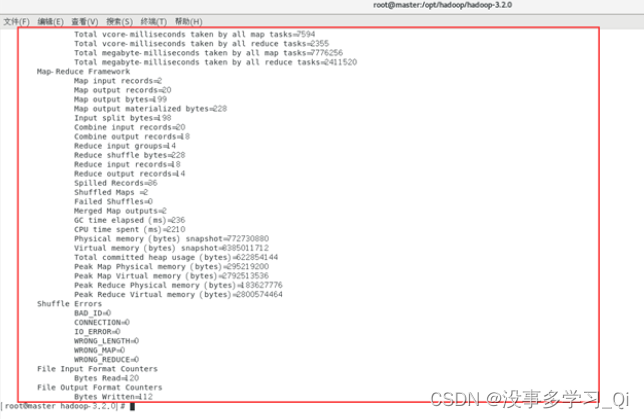
查看结果
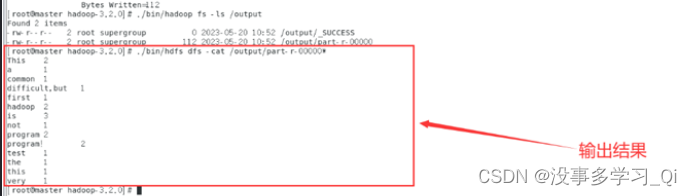
./bin/hadoop fs -ls /output
./bin/hdfs dfs -cat /output/part-r-00000*
http://192.168.95.20:9870/explorer.html#/output # web端查看
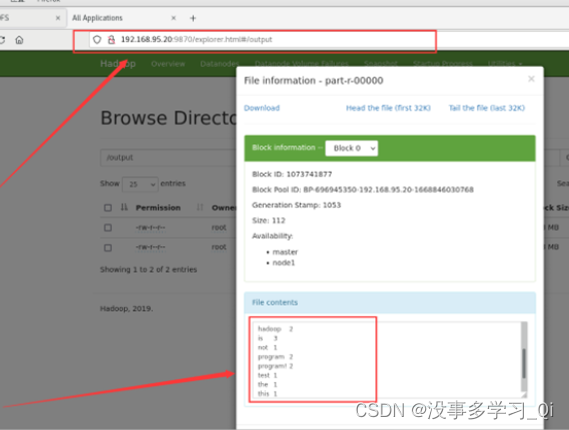
以上实验结束
Hadoop3.0x版本的重要服务进行端口号
| Hadoop3.0x | 对应端口号 |
|---|---|
| HDFS NameNode 内部通信端口 | 8020 / 9000 / 9820 |
| HDFS NameNode对用户的查询端口HTTP UI | 9870 |
| MapReduce查看执行任务的端口 | 8088 |
| 历史服务通信端口 | 19888 |
希望此教程有所帮助,各环境配置和操作没问题的话,基本都能部署完成,可以根据自己需要增加3台或者更多node节点,节点配置信息修改的操作都是一样的,直接复制虚拟机改主机名ip一些基本配置就行了。