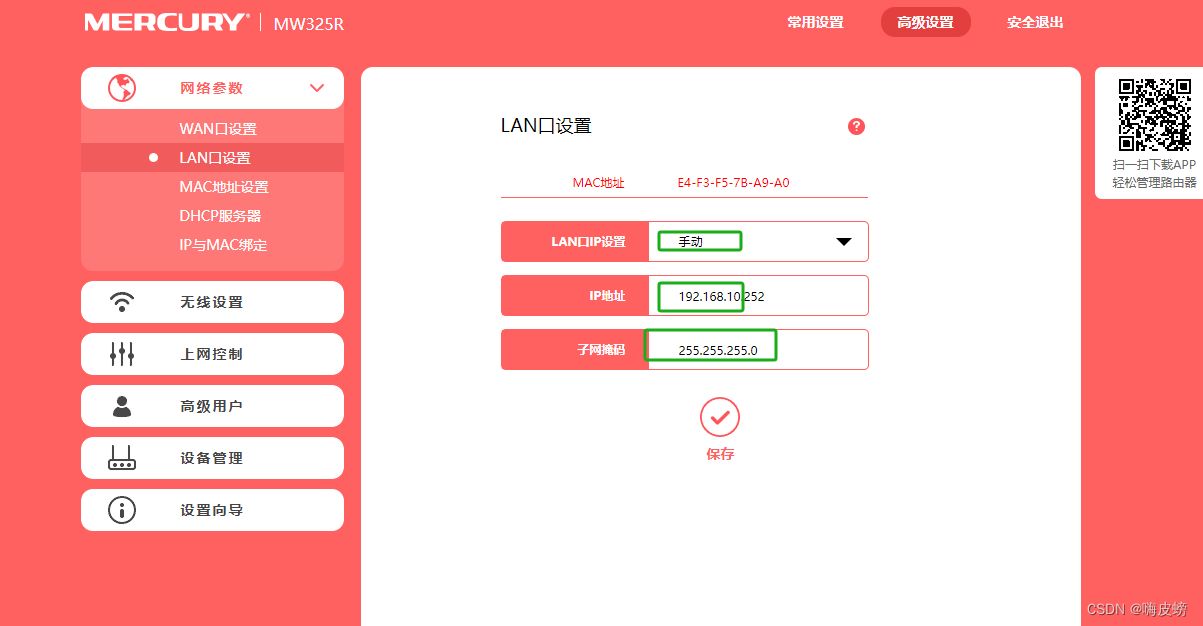
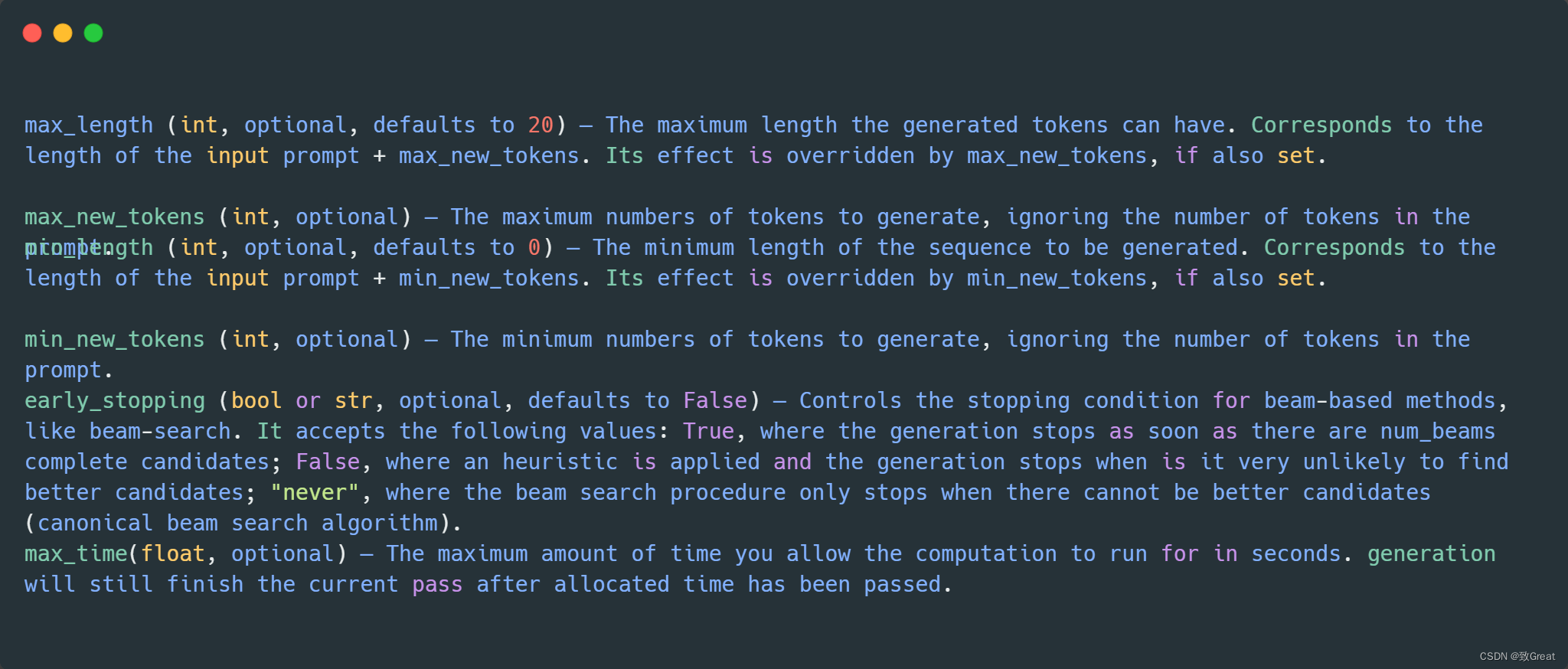
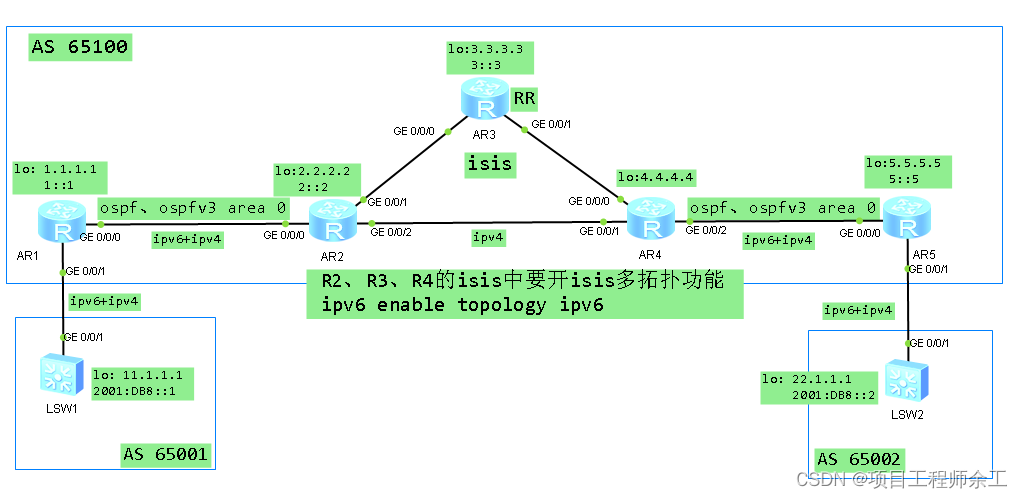
打开wiki,不知道从哪儿爬起
一般倾向于 自顶向下的方式去 分析网站结构
但wiki的网页结构并不是非常明了,于是找了个视频看看:
https://www.bilibili.com/video/BV14T4y177vE/
发现,是可以根据 当前网页的链接跳转,来获取有效的内容页面
另一个思路:
根据关键字,拼接详情页面 url,有些关键字没有对应页面就作罢
关键字,可以将文本分词 来获取
打开wiki,不知道从哪儿爬起
一般倾向于 自顶向下的方式去 分析网站结构
但wiki的网页结构并不是非常明了,于是找了个视频看看:
https://www.bilibili.com/video/BV14T4y177vE/
发现,是可以根据 当前网页的链接跳转,来获取有效的内容页面
另一个思路:
根据关键字,拼接详情页面 url,有些关键字没有对应页面就作罢
关键字,可以将文本分词 来获取