简介:计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(nlog(n))的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是O(nlog(n)), 如归并排序,堆排序)。
历史攻略:
算法思想:
计数排序对输入的数据有附加的限制条件:
1、输入的线性表的元素属于有限偏序集S;
2、设输入的线性表的长度为n,|S|=k(表示集合S中元素的总数目为k),则k=O(n)。
在这两个条件下,计数排序的复杂性为O(n)。
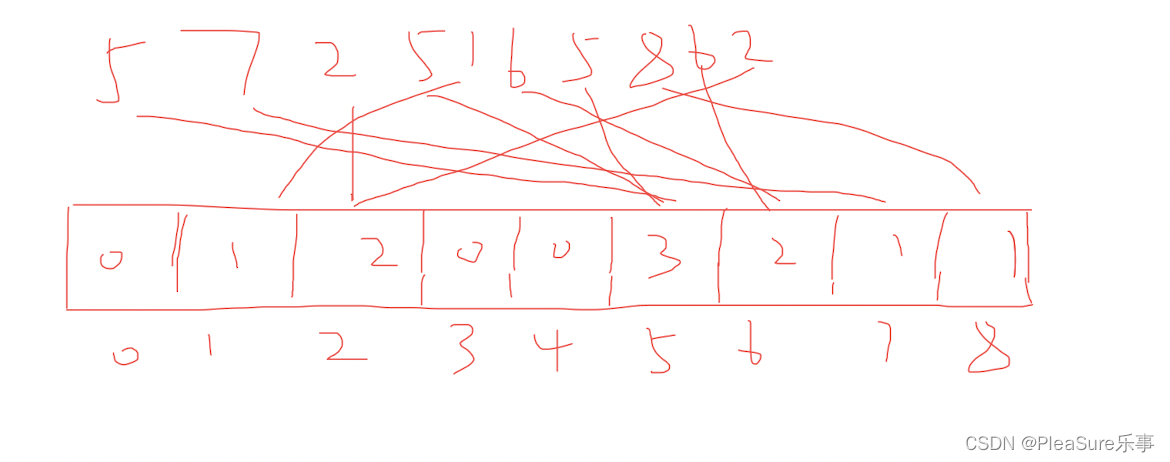
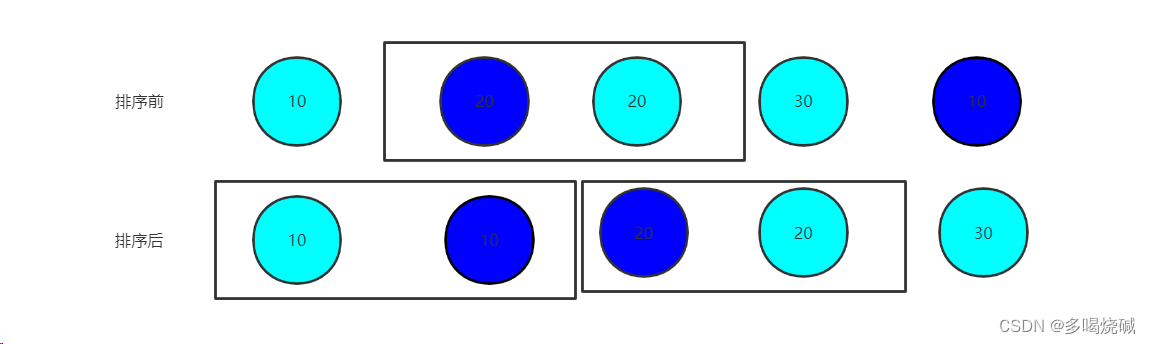
计数排序的基本思想是对于给定的输入序列中的每一个元素x,确定该序列中值小于x的元素的个数(此处并非比较各元素的大小,而是通过对元素值的计数和计数值的累加来确定)。一旦有了这个信息,就可以将x直接存放到最终的输出序列的正确位置上。例如,如果输入序列中只有17个元素的值小于x的值,则x可以直接存放在输出序列的第18个位置上。当然,如果有多个元素具有相同的值时,我们不能将这些元素放在输出序列的同一个位置上,因此,上述方案还要作适当的修改。
Python语言描述:
def count_sort(input_list):
length = len(input_list)
if length < 2:
return input_list
max_num = max(input_list)
count = [0] * (max_num + 1)
for element in input_list:
count[element] += 1
output_list = []
for i in range(max_num + 1):
for j in range(count[i]): # count[i]表示元素i出现的次数,如果有多次,通过循环重复追加
output_list.append(i)
return output_list
案例源码:5题
# -*- coding: utf-8 -*-
# time: 2023/12/17 10:18
# file: count_sort_demo.py
# 公众号: 玩转测试开发
from typing import List
# 1051. 高度检查器
# 学校打算为全体学生拍一张年度纪念照。根据要求,学生需要按照非递减的高度顺序排成一行。
# 排序后的高度情况用整数数组expected表示,其中expected[i]是预计排在这一行中第i位的学生的高度(下标从0开始)。
# 给你一个整数数组heights ,表示当前学生站位的高度情况。heights[i]是这一行中第i位学生的高度(下标从0开始)。
# 返回满足heights[i] != expected[i]的下标数量 。
#
# 示例1:输入:heights = [1, 1, 4, 2, 1, 3]
# 输出:3
# 解释:
# 高度:[1, 1, 4, 2, 1, 3]
# 预期:[1, 1, 1, 2, 3, 4]
# 下标
# 2 、4 、5
# 处的学生高度不匹配。
# 示例2:
# 输入:heights = [5, 1, 2, 3, 4]
# 输出:5
# 解释:
# 高度:[5, 1, 2, 3, 4]
# 预期:[1, 2, 3, 4, 5]
# 所有下标的对应学生高度都不匹配。
# 示例3:
# 输入:heights = [1, 2, 3, 4, 5]
# 输出:0
# 解释:
# 高度:[1, 2, 3, 4, 5]
# 预期:[1, 2, 3, 4, 5]
# 所有下标的对应学生高度都匹配。
class Solution1051:
def heightChecker(self, heights: List[int]) -> int:
# 先赋值给其他
# 排序本身
# 遍历对比
n = heights[:]
heights.sort()
count = 0
for i, v in enumerate(n):
if v != heights[i]:
count += 1
return count
s1051 = Solution1051()
r1051 = s1051.heightChecker([1, 1, 4, 2, 1, 3])
print(f"r1051:{
r1051}") # r1051:3
# 561. 数组拆分
# 给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,
# 使得从 1 到 n 的 min(ai, bi) 总和最大。
# 返回该 最大总和 。
# 示例 1:
# 输入:nums = [1,4,3,2]
# 输出:4
# 解释:所有可能的分法(忽略元素顺序)为:
# 1. (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
# 2. (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
# 3. (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
# 所以最大总和为 4
# 示例 2:
# 输入:nums = [6,2,6,5,1,2]
# 输出:9
# 解释:最优的分法为 (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9
class Solution561:
def arrayPairSum(self, nums: List[int]) -> int:
# 排序。一次22取。排序后,双数位为最小。隔取求和
nums.sort()
count = int(len(nums) / 2)
return sum([i for i in nums[0::2]])
s561 = Solution561()
r561 = s561.arrayPairSum([1, 1, 4, 2, 1, 3])
print(f"r561:{
r561}") # r561:5
# 1122. 数组的相对排序
# 给你两个数组,arr1 和 arr2,arr2 中的元素各不相同,arr2 中的每个元素都出现在 arr1 中。
# 对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。
# 未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
# 示例 1:
# 输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
# 输出:[2,2,2,1,4,3,3,9,6,7,19]
# 示例 2:
# 输入:arr1 = [28,6,22,8,44,17], arr2 = [22,28,8,6]
# 输出:[22,28,8,6,17,44]
class Solution1122:
def relativeSortArray(self, arr1: List[int], arr2: List[int]) -> List[int]:
# 字典:arr1的元素和个数
# 遍历arr2,将符合的全部加入结果列表。加入后移除字典中对应的键值对。
# 遍历字典。将剩余的值重新排序,并入结果列表
import collections
tmp_dict = dict(collections.Counter(arr1))
result = []
for i in arr2:
if i in tmp_dict:
loop = tmp_dict[i]
for count in range(loop):
result.append(i)
tmp_dict.pop(i)
others = [k for k, v in tmp_dict.items() for i in range(v)]
others.sort()
return result + others
s1122 = Solution1122()
r1122 = s1122.relativeSortArray([2, 3, 1, 3, 2, 4, 6, 7, 9, 2, 19], [2, 1, 4, 3, 9, 6])
print(f"r1122:{
r1122}") # r1122:[2, 2, 2, 1, 4, 3, 3, 9, 6, 7, 19]
# 912. 排序数组
# 给你一个整数数组 nums,请你将该数组升序排列。
# 示例 1:
# 输入:nums = [5,2,3,1]
# 输出:[1,2,3,5]
# 示例 2:
# 输入:nums = [5,1,1,2,0,0]
# 输出:[0,0,1,1,2,5]
class Solution912:
def sortArray(self, nums: List[int]) -> List[int]:
return sorted(nums)
s912 = Solution912()
r912 = s912.sortArray([2, 1, 4, 3, 9, 6])
print(f"r912:{
r912}") # r912:[1, 2, 3, 4, 6, 9]
# 274. H 指数
# 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
# 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,
# 并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
# 示例 1:
# 输入:citations = [3,0,6,1,5]
# 输出:3
# 解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
# 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
# 示例 2:
# 输入:citations = [1,3,1]
# 输出:1
class Solution274:
def hIndex(self, citations: List[int]) -> int:
loop = len(citations)
if sum(citations) == 0:
return 0
if loop == 1:
return 1
for i in range(loop, 0, -1):
if sum([1 for j in citations if j >= i]) >= i:
return i
s274 = Solution274()
r274 = s274.hIndex([2, 1, 4, 3, 9, 6])
print(f"r274:{
r274}") # r274:3
运行结果:
r1051:3
r561:5
r1122:[2, 2, 2, 1, 4, 3, 3, 9, 6, 7, 19]
r912:[1, 2, 3, 4, 6, 9]
r274:3
总结:计数排序算法没有用到元素间的比较,它利用元素的实际值来确定它们在输出数组中的位置。因此,计数排序算法不是一个基于比较的排序算法,从而它的计算时间下界不再是O(nlogn)。另一方面,计数排序算法之所以能取得线性计算时间的上界是因为对元素的取值范围作了一定限制,即k=O(n)。如果k=n2,n3,…,就得不到线性时间的上界。此外,我们还看到,由于算法第4行使用了downto语句,经计数排序,输出序列中值相同的元素之间的相对次序与他们在输入序列中的相对次序相同,换句话说,计数排序算法是一个稳定的排序算法。































![[Kubernetes]5. k8s集群StatefulSet详解,以及数据持久化(SC PV PVC)](https://img-blog.csdnimg.cn/direct/2338c45a9af940bdb98f957efab8d406.png)