聚类算法
聚类算法: 将数据分成不同的组,如K均值(K-Means)和层次聚类(Hierarchical Clustering)。
聚类是机器学习中一类重要的无监督学习问题,其目标是将数据集中的样本划分为不同的组,使得同一组内的样本相似度较高,不同组之间的相似度较低。
常见的聚类算法如下:
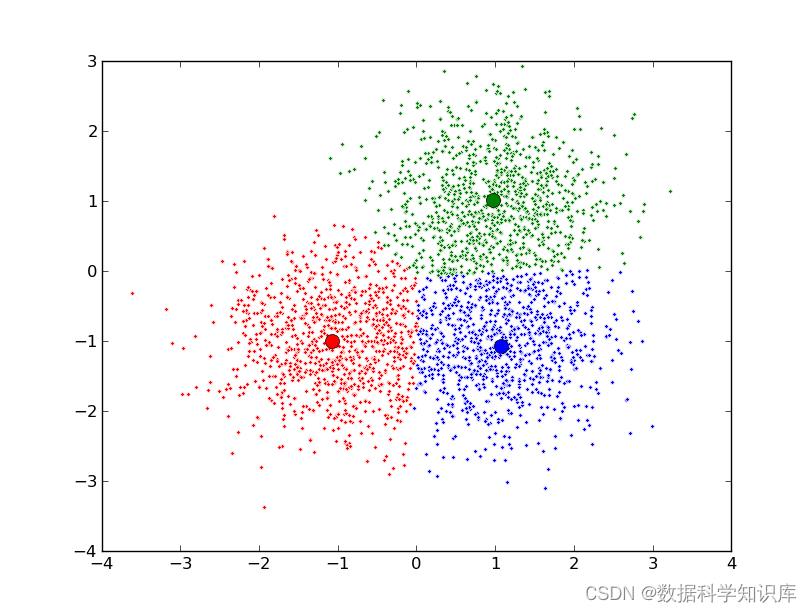
K均值聚类(K-Means Clustering):
原理: 将数据划分为K个簇,每个簇的中心是该簇中所有样本的平均值。
特点: 适用于凸形簇,对大规模数据集有效。
算法流程图:
初始化: 选择K个初始聚类中心点。
分配: 将每个数据点分配到最近的聚类中心。
更新: 根据分配的数据点,更新每个聚类中心的位置。
迭代: 重复步骤2和步骤3,直到收敛(聚类中心不再改变)或达到最大迭代次数。
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成随机数据作为示例
np.random.seed(42)
data = np.random.randn(300, 2) + np.array([4, 4])
# 设定聚类数K
k = 3
# 使用K均值聚类算法
kmeans = KMeans(n_clusters=k)
kmeans.fit(data)
# 获取聚类中心和预测标签
centroids = kmeans.cluster_centers_
labels = kmeans.labels_
# 可视化结果
colors = ['r.', 'g.', 'b.']
for i in range(len(data)):
plt.plot(data[i][0], data[i][1], colors[labels[i]], markersize=10)
# 绘制聚类中心
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=150, linewidths=5, zorder=10)
plt.show()
层次聚类(Hierarchical Clustering):
原理: 通过构建树状结构(聚类树)来表示数据的层次结构,可以是自底向上(凝聚性聚类)或自顶向下(分裂性聚类)。
特点: 不需要预先指定簇的数量,可视化结果更直观。
层次聚类(Hierarchical Clustering)是一种基于树状结构的聚类方法,它可以分为两类:凝聚型(Agglomerative)和分裂型(Divisive)。下面是凝聚型层次聚类的算法代码流程图和Python代码示例。
算法流程图:
初始化: 每个数据点视为一个初始簇。
计算相似度: 计算每一对簇之间的相似度。
合并最相似的簇: 将最相似的两个簇合并为一个新簇。
更新相似度矩阵: 更新相似度矩阵,将新簇与其他簇的相似度计算出来。
重复: 重复步骤3和步骤4,直到只剩下一个簇。
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
# 生成随机数据作为示例
np.random.seed(42)
data = np.random.randn(10, 2)
# 使用层次聚类算法
linkage_matrix = linkage(data, 'ward')
# 绘制树状图
dendrogram(linkage_matrix, labels=range(1, 11))
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data Point Index')
plt.ylabel('Distance')
plt.show()
谱聚类(Spectral Clustering):
原理: 将数据投影到特征空间,然后在新的空间中使用K均值等算法进行聚类。
特点: 在处理复杂结构的数据上表现较好,如图像分割。
算法流程图:
构建相似度图: 根据数据点之间的相似度构建相似度图,通常使用高斯核函数。
计算拉普拉斯矩阵: 从相似度图中计算拉普拉斯矩阵。
特征分解: 对拉普拉斯矩阵进行特征分解,得到特征向量。
K均值聚类: 将特征向量作为新的数据表示,然后使用K均值聚类进行最终的聚类。
import numpy as np
from sklearn.cluster import SpectralClustering
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成示例数据
data, labels = make_blobs(n_samples=300, centers=3, random_state=42)
# 使用谱聚类算法
spectral = SpectralClustering(n_clusters=3, affinity='nearest_neighbors', random_state=42)
predicted_labels = spectral.fit_predict(data)
# 可视化结果
plt.scatter(data[:, 0], data[:, 1], c=predicted_labels, cmap='viridis', marker='o', s=50)
plt.title('Spectral Clustering')
plt.show()
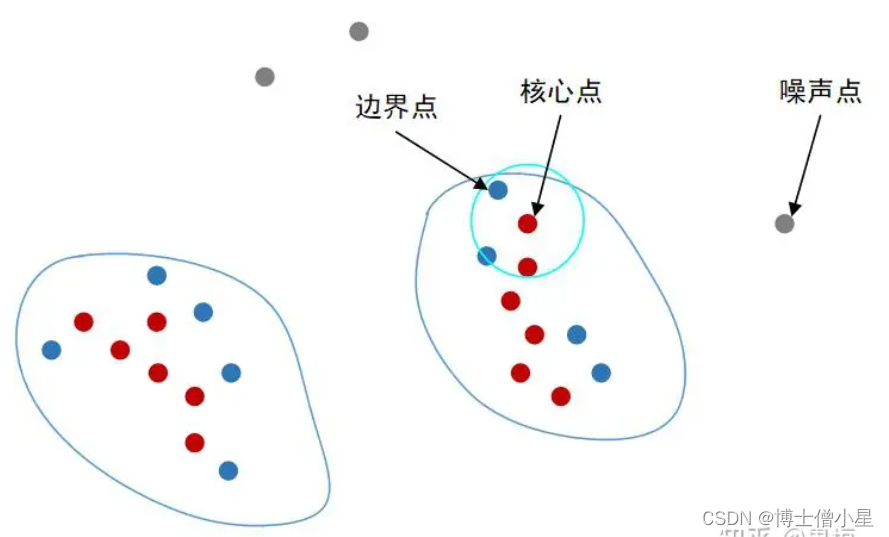
OPTICS(Ordering Points To Identify the Clustering Structure):
原理: 基于样本的密度和可达性建立聚类结构,不需要预先设定簇的数量。
特点: 对密度变化较大的数据集有较好的适应性。
OPTICS(Ordering Points To Identify the Clustering Structure)是一种基于密度的聚类算法,它不需要预先设定簇的数量,并可以发现不同密度的簇。以下是OPTICS的简要算法流程图和Python代码示例:
算法流程图:
计算核心距离和可达距离: 对每个数据点计算核心距离,然后计算可达距离。
生成簇: 通过对可达距离进行排序,确定簇的边界。
构建簇的层次结构: 将数据点组织成一个层次结构,其中较高层次的点表示较高的可达距离。
提取簇: 根据层次结构,提取具有一定密度的簇。
from sklearn.cluster import OPTICS
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成示例数据
data, labels = make_blobs(n_samples=300, centers=3, random_state=42)
# 使用OPTICS算法
optics = OPTICS(min_samples=5, xi=0.05, min_cluster_size=0.1)
optics.fit(data)
# 可视化结果
plt.scatter(data[:, 0], data[:, 1], c=optics.labels_, cmap='viridis', marker='o', s=50)
plt.title('OPTICS Clustering')
plt.show()
Affinity Propagation:
原理: 通过样本之间的消息传递来确定簇的中心,具有自动选择簇数的特点。
特点: 对于数据集中存在多个簇的情况表现较好。
Affinity Propagation是一种基于数据点之间消息传递的聚类算法。该算法通过在数据点之间传递“责任”和“可用性”来确定聚类的中心。以下是Affinity Propagation的算法流程图和Python代码示例:
算法流程图:
初始化相似度矩阵: 计算数据点之间的相似度矩阵。
初始化责任矩阵和可用性矩阵: 将责任矩阵R和可用性矩阵A初始化为零矩阵。
迭代传递消息: 迭代传递“责任”和“可用性”消息,更新矩阵R和A。
计算聚类: 根据矩阵R和A计算聚类结果。
迭代更新: 重复步骤3和步骤4,直到收敛或达到最大迭代次数。
from sklearn.cluster import AffinityPropagation
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成示例数据
data, labels = make_blobs(n_samples=300, centers=3, random_state=42)
# 使用Affinity Propagation算法
affinity_propagation = AffinityPropagation(damping=0.9, preference=-200)
affinity_propagation.fit(data)
# 获取聚类中心的索引
cluster_centers_indices = affinity_propagation.cluster_centers_indices_
# 获取聚类标签
labels = affinity_propagation.labels_
# 可视化结果
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis', marker='o', s=50)
plt.title('Affinity Propagation Clustering')
plt.show()