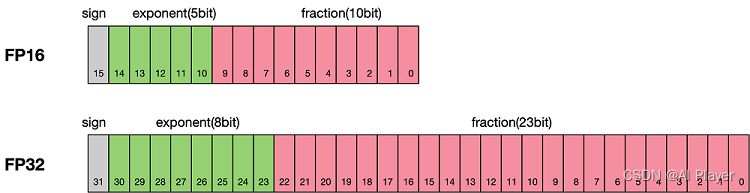
浮点数据类型主要分为双精度(Fp64)、单精度(Fp32)、半精度(FP16)。
首先来看看为什么需要混合精度。使用FP16训练神经网络,相对比使用FP32带来的优点有:
- 减少内存占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
- 加快通讯效率:针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,通讯的位宽少了意味着可以提升通讯性能,减少等待时间,加快数据的流通。
- 计算效率更高:在特殊的AI加速芯片如华为Ascend 910和310系列,或者NVIDIA VOTAL架构的Titan V and Tesla V100的GPU上,使用FP16的执行运算性能比FP32更加快。
但是使用FP16同样会带来一些问题,其中最重要的是1)精度溢出和2)舍入误差。
- 数据溢出:数据溢出比较好理解,FP16的有效数据表示范围为 6.10 × 10 − 5 ∼ 655046.10 × 1 0 − 5 ∼ 65504 6.10×10−5∼655046.10\times10^{-5} \sim 65504 6.10×10−5∼655046.10×10−5∼65504,FP32的有效数据表示范围为 1.4 × 10 − 451.7 × 10381.4 × 1 0 − 45 1.7 × 1 0 38 1.4×10−45 1.7×10381.4\times10^{-45} ~ 1.7\times10^{38} 1.4×10−451.7×10381.4×10−45 1.7×1038。可见FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况。而在深度学习中,需要计算网络模型中权重的梯度(一阶导数),因此梯度会比权重值更加小,往往容易出现下溢情况。
- 舍入误差:Rounding Error指示是当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入。