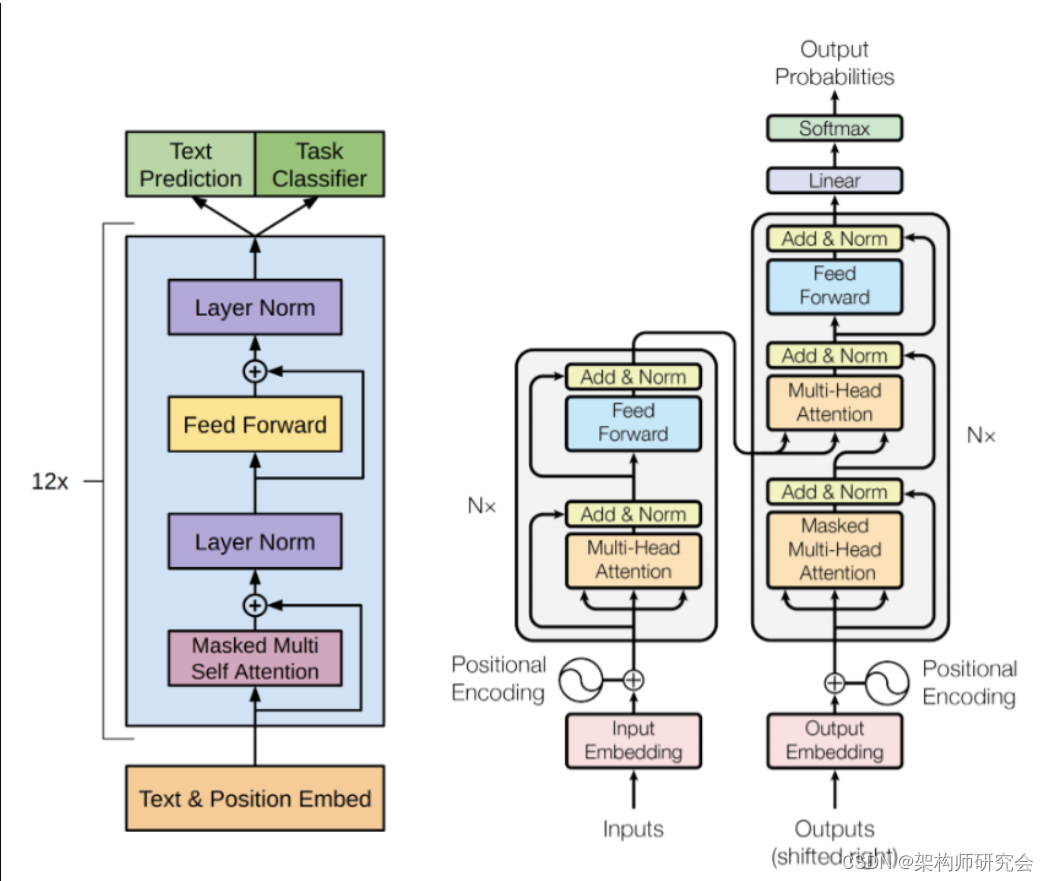
1 StarRocks介绍
StarRocks是新一代极速全场景MPP(Massively Parallel Processing)数据库,它充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果,在业界实践的基础上,进一步改进优化、升级架构,并增添了众多全新功能,形成了全新的企业级产品。
StarRocks致力于构建极速统一分析体验,满足企业用户的多种数据分析场景,支持多种数据模型(明细模型、聚合模型、更新模型),多种导入方式(批量和实时),可整合和接入多种现有系统(Spark、Flink、Hive、 ElasticSearch)。
StarRocks兼容MySQL协议,可使用MySQL客户端和常用BI工具对接StarRocks来进行数据分析。
StarRocks采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持10PB级别的数据分析; 支持MPP框架,并行加速计算; 支持多副本,具有弹性容错能力。
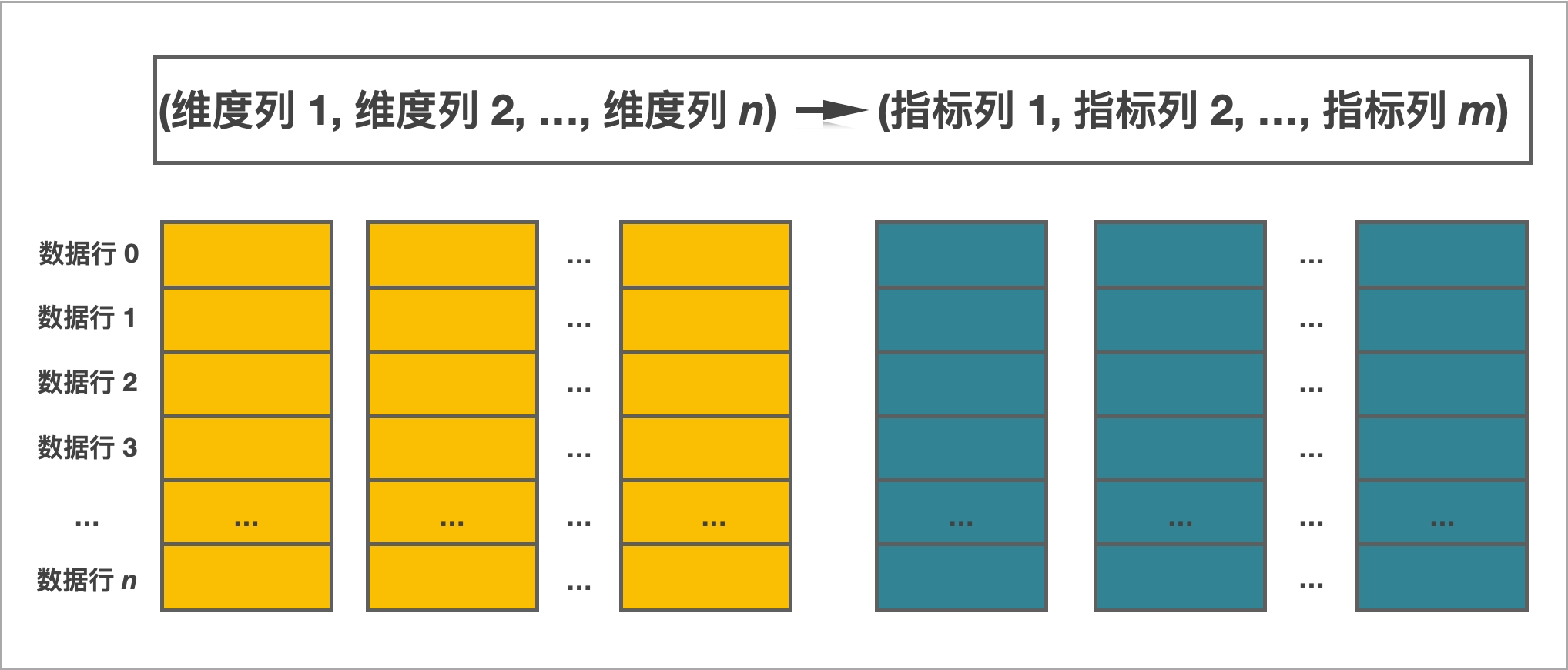
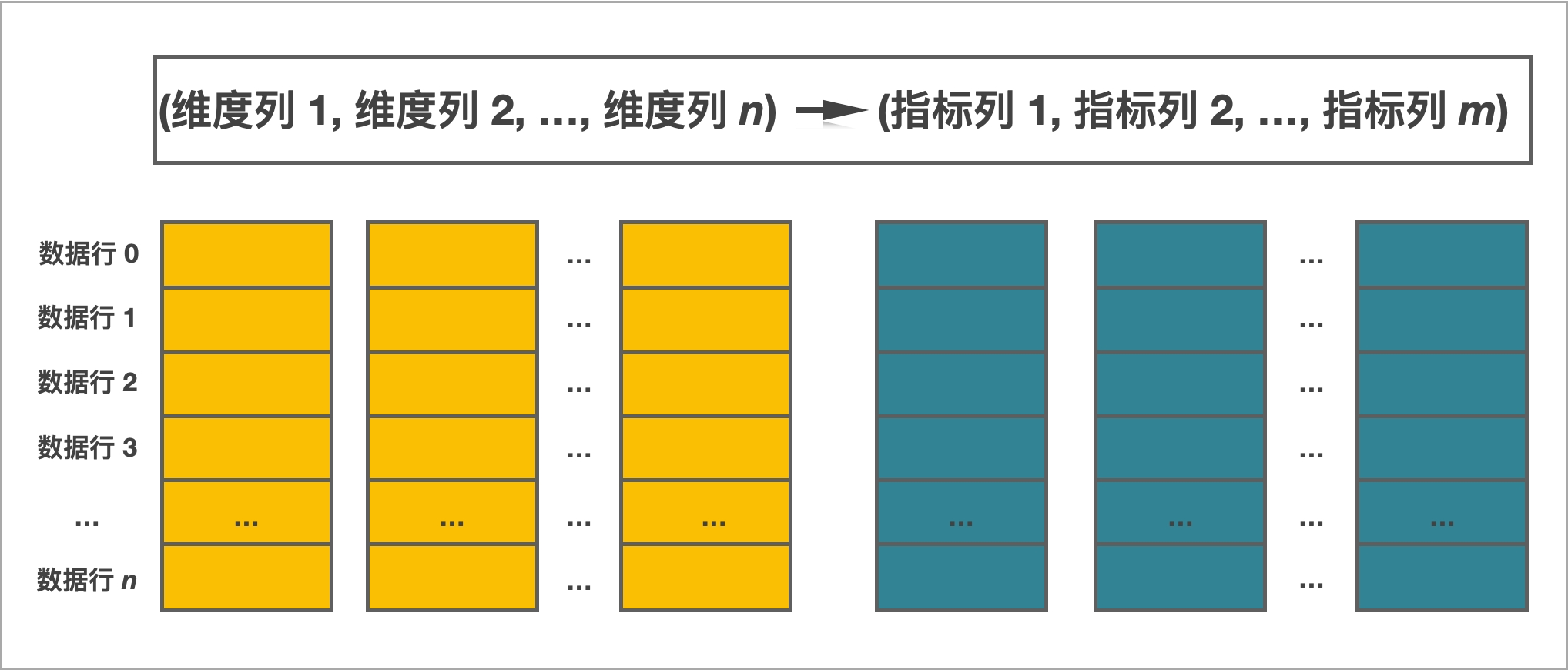
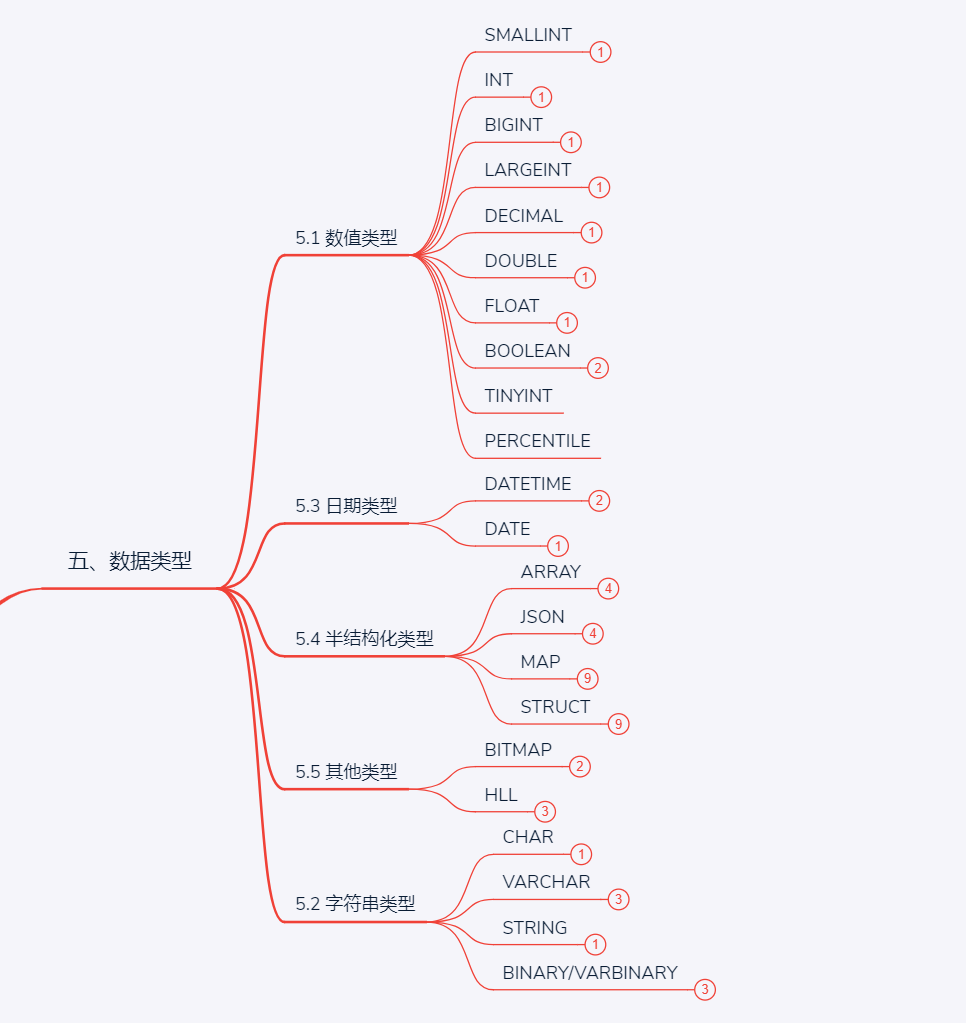
StarRocks采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;
使用向量化执行方式,充分挖掘多核CPU的并行计算能力,从而显著提升查询性能。
为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在CPU寄存器层面实现数据的并行操作。
2. StarRocks适合什么场景
StarRocks可以满足企业级用户的多种分析需求,包括OLAP多维分析、定制报表、实时数据分析和Ad-hoc数据分析等。具体的业务场景包括:
(1)OLAP多维分析:用户行为分析、用户画像、财务报表、系统监控分析
(2)实时数据分析:电商数据分析、直播质量分析、物流运单分析、广告投放分析
(3)高并发查询:广告主表分析、Dashbroad多页面分析
(4)统一分析:通过使用一套系统解决上述场景,降低系统复杂度和多技术栈开发成本
3. StarRocks基本概念
(1)FE:FrontEnd简称FE,是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。
(2)BE:BackEnd简称BE,是StarRocks的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作
(3) Broker:StarRocks中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
(4)StarRocksManager:StarRocks的管理工具,提供StarRocks集群管理、在线查询、故障查询、监控报警的可视化工具。
(5)Tablet:StarRocks中表的逻辑分片,也是StarRocks中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
4. StarRocks系统架构
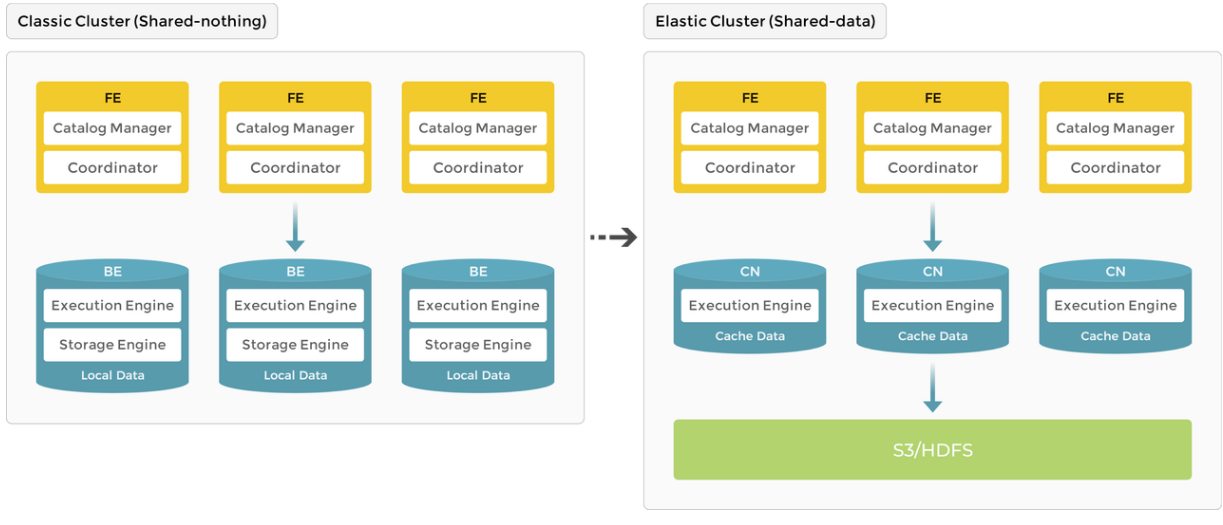
随着 StarRocks 产品的不断演进,系统架构也从原先的存算一体 (shared-nothing) 进化到存算分离 (shared-data)。
3.0 版本之前使用存算一体架构,BE 同时负责数据存储和计算,数据访问和分析都在本地进行,提供极速的查询分析体验。
3.0 版本开始引入存算分离架构,数据存储功能从原来的 BE 中抽离,BE 节点升级为无状态的 CN 节点。数据可持久存储在远端对象存储或 HDFS 上,CN 本地磁盘只用于缓存热数据来加速查询。存算分离架构下支持动态增删计算节点,实现秒级的扩缩容能力。
下图展示了存算一体到存算分离的架构演进。
5. 组件介绍
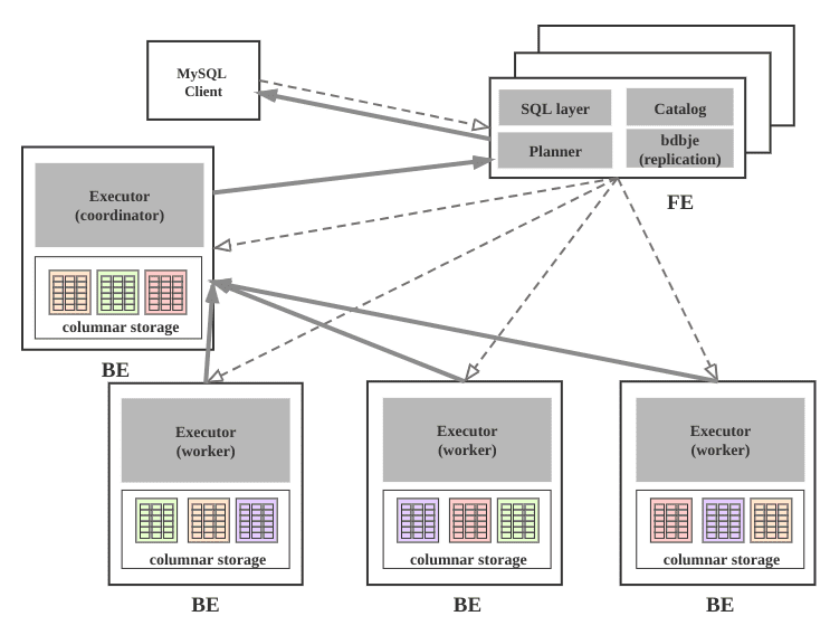
StarRocks集群由FE和BE构成, 可以使用MySQL客户端访问StarRocks集群。
FE
FE接收MySQL客户端的连接, 解析并执行SQL语句。
管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
FE协调数据导入, 保证数据导入的一致性。
FE 有三种角色:Leader FE,Follower FE 和 Observer FE

BE
BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
BE受FE指导, 创建或删除子表。
BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
BE后台执行compact任务, 减少查询时的读放大。
数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。