NoSQL数据库的定义和优势
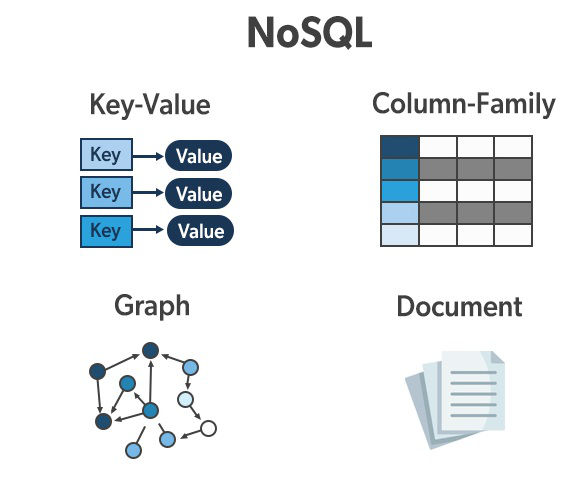
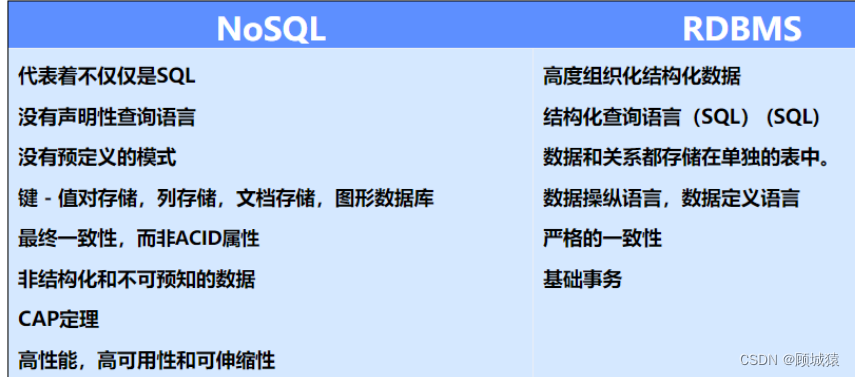
NoSQL(not only SQL)定义:NoSQL是指一类非关系型数据库,用于处理大量、松散结构或半结构化数据,不遵循传统关系型数据库的数据模型。
NoSQL的优势:
1. 灵活性:NoSQL数据库适用于不同类型的数据,可以处理半结构化或非结构化数据。
2. 可扩展性:NoSQL数据库通常更容易水平扩展,适应大规模数据和流量的增长。
3. 性能:针对特定用途的读写模式进行了优化,提供更高的性能。
4. 简化复杂性:对于某些应用场景,NoSQL数据库可以降低复杂性和开发的难度。
5. 适应变化:适应快速变化的数据结构和需求,更适合敏捷开发和迭代。
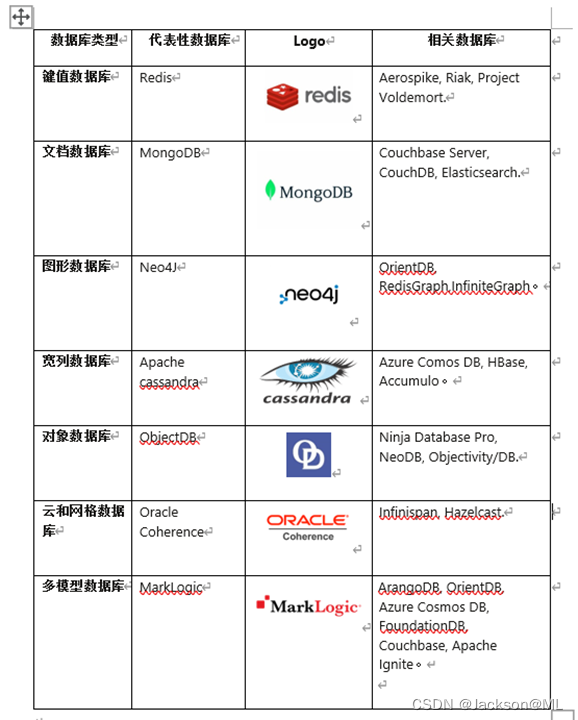
常见的NoSQL数据库类型和应用场景:
1. 文档型数据库:
- 特点:
- 数据以文档的形式存储,通常使用JSON或类似的格式。
- 文档是一个键值对的集合,可以嵌套其他文档或数据。
- 优势:
- 灵活的数据模型,适应变化和复杂性。
- 查询性能高,特别适用于读多写少的场景。
- 常见数据库:MongoDB、CouchDB。
- 应用场景:
- 适用于存储和查询具有复杂结构的文档,如博客、新闻文章。
- 博客平台,存储文章、评论和标签信息。
- 电商平台,存储产品、订单和用户信息。
2. 键值型数据库:
- 特点:
- 数据以键值对的形式存储,简单、高效。
- 键和值可以是任意数据类型。
- 优势:
- 高速读写,适用于对简单数据的快速存储和检索。
- 适用于需要高度可扩展性的场景。
- 常见数据库:Redis、DynamoDB。
- 应用场景:
- 适用于需要高速读写、简单数据模型的场景,如缓存、会话存储。
- 缓存系统,存储频繁访问的数据。
- 会话存储,存储用户登陆状态。
3. 列族型数据库:
- 特点:
- 数据以列族的形式存储,适合大规模的分布式存储。
- 列族中的列可以动态添加,每行不需要完全相同的列。
- 优势:
- 高度可扩展,适应大规模数据存储和分析。
- 适合处理需要按列进行聚合的场景。
- 常见数据库:Apache Cassandra、HBase。
- 应用场景:
- 日志存储和分析,存储大量时间序列数据。
- 大规模数据仓库,存储海量结构化数据。
- 适用于需要横向扩展、大规模数据存储和分析的场景,如日志、时间序列数据。
4. 图形型数据库:
- 特点:
- 以图的形式存储数据,强调数据之间的关系。
- 节点和边分别表示实体和它们之间的关系。
- 优势:
- 高效处理复杂的关系和图算法。
- 适合存储和查询网络关系、社交网络等数据。
- 常见数据库:Neo4j、ArangoDB。
- 应用场景:
- 适用于需要处理复杂关系和图算法的场景,如社交网络、推荐系统。
- 社交网络,存储用于、关系和活动信息。
- 推荐系统,分析用户和商品之间的关系。
数据库示例
文档型数据库示例(以MongoDB为例):
假设我们要设计一个存储图书信息的文档型数据库,其中每本图书有基本信息(书名、作者、出版日期)以及多个读者的评论。
MongoDB集合结构示意:
- 集合名:Books
- 文档结构:
- '_id' : 图书唯一标识
- 'title' : 书名
- 'author' : 作者
- 'publication_date' : 出版日期
- 'comments' : 评论数组,每个评论包含'user'和'comment_text'字段
数据示例:
{
"_id": ObjectId("5fbc5b3a5bc45a74e44b2c00"),
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"publication_date": ISODate("1925-04-10"),
"comments":[
{"user": "User1", "comment_text":"Classic novel!"},
{"user": "User2", "comment_text":"I love the characters."}
{"user": "User3", "comment_text": "The ending was unexpected."}
]
}在这个示例中,每本图书的信息被表示为一个文档,包含了基本信息和评论的数组。这样的结构对于嵌套和复杂的数据非常适用。
键值型数据库示例(以Redis为例):
考虑一个简单的缓存场景,我们要存储用户的会话信息。
Redis键值对示意:
- 键:‘user_session:UserID123’
- 值:存储用户会话信息的JSON对象,包括'user_id'、'session_token'、'expiry_time'等字段。
数据示例:
SET user_session:UserID123 '{"user_id": "UserID123", "session_token":"abc123", "expiry_time":"2023-01-20 18:00:00"}'在这个示例中,每个用户的会话信息被表示为一个键值对,键是用户会话的唯一标识,值是存储会话信息的JSON对象。这样的结构非常适合简单键值存储和快速检索。
示例1和2展示了文档型数据库和键值型数据库在不同场景下的应用。文档型数据库适合存储复杂结构的文档,而键值型数据适合简单的键值存储和快速检索。
列族型数据库示例:
假设我么要设计一个存储学生考试成绩的列族型数据库,其中每个学生的成绩记录包含学生的基本信息(姓名、年龄等)和考试科目的成绩。
HBase表结构示意:
- 表名:StudentScores
- 列族1: StudentInfo
- 列: Name, Age, Gender
- 列族2: ExamScores
- 列: Math, Physics, Chemistry
数据示例:
RowKey: Student101
Column Family: StudentInfo
Name: John
Age: 18
Gender: Male
Column Family: ExamScores
Math: 95
Physics: 88
Chemistry: 92
RowKey: Student002
Column Family: StudentInfo
Name: Alice
Age: 17
Gender: Female
Column Family: ExamScores
Math: 88
Pysics: 90
Chemistry: 85在这个示例中,每个学生的基本信息存储在"StudentInfo"列族中,而每个学生的考试成绩存储在"ExamScores"列族中。列族的动态性使得我们可以灵活地添加新的科目和相关的成绩,适应了数据结构的变化。
图形型数据库示例(以Neo4j为例):
考虑一个社交网络场景,我们想要存储用户之间的关系以及用户发布的文章和评论。
Neo4j图结构示意:
- 节点类型1:User
- 属性:UserID, Name, Age
- 节点类型2: Post
- 属性: PostID, Content, Timestamp
- 关系类型1: FOLLOWS(用户之间的关注关系)
- 关系类型2: WROTE(用户发布了文章)
- 关系类型3:COMMENTED_ON(用户对文章进行了评论)
数据示例:
(User:UserID1 {Name:'Alice', Age: 25}) - [:FOLLOWS] -> (User:UserID2 {Name:'Bob', Age:28})
(User:UserID1) - [:WROTE] -> (Post:PostID1{Content: 'Interesting article', Timestamp: '2023-01-15'})
(User:UserID2) - [:COMMENTED_ON] -> (Post:PostID1 {Content:'Great content!', Timestamp: '2023-01-16'})在这个示例中,节点表示用户和文章,关系表示用户之间的关注关系、用户发布文章和用户对文章的评论。这种图形结构使得查询用户之间的关系、用户发布的文章以及评论等操作变得非常直观和高效。
示例3和4展示了列族型数据库和图形型数据库在不同场景下的应用。列族型数据库适合大规模的分布式存储和处理结构化数据,而图形型数据库适合存储和查询复杂的关系网络。
代码创建四种类型数据库的一般步骤:
当涉及到不同类型的数据库时,具体的步骤和代码会取决于所选择的数据库系统。以下是对四种类型数据库的一般步骤概述:
文档型数据库(Document-oriented Database)
文档型数据库的例子包括MongoDB、CouchDB等。
1. 安装数据库:
- 对于MongoDB,可以从官方网站下载并安装。
- 在Linux上,可以使用命令'sudo apt-get install mongodb'进行安装。
2. 连接数据库:
- 使用相应的驱动程序在代码中连接到数据库。在MongoDB中,可以使用官方的MongoDB驱动程序。
3. 创建文档:
- 插入文档,文档是以JSON格式存储的。
- 在MongDB中,可以使用'insertOne'或'insertMany'方法。
# Python代码示例(使用PyMongo)
from pymongo import MongoClient
client = MongonClient('mongodb://localhost:27017/')
db = client['mydatabase']
collection = db['mycollection']
document = {"key":"value", "another_key":"another_value"}
collection.insert_one(document)上述代码向数据库中插入了如下所示的JSON格式文档, 包含两个键值对:
{
"key": "value",
"another_key": "another_value"
}
键值型数据库(Key-value Store)
键值型数据库的例子包括Redis、Amazon DynamoDB等。
1. 安装数据库:
- 对于Redis,可以从官方网站下载并安装。
- 在Linux上,可以使用命令'sudo apt-get install redis-server'进行安装。
2. 连接数据库:
- 使用相应的客户端库在代码中连接到数据库。
3. 存储键值对:
- 使用适当的方法将键值对存储到数据库中。
# Python代码示例(使用redis.py)
import redis
client = redis.StrictRedis(host='localhost', port=6379, db=0)
client.set('key', 'value')列族型数据库(Wide-column Store)
列族型数据库的例子包括Apache Cassandra, HBase等。
1. 安装数据库:
- 对于Cassandra,可以从官方网站下载并安装。
- 在Linux上,可以使用命令'sudo apt-get install cassandra'进行安装。
2. 连接数据库:
- 使用相应的驱动程序在代码中连接到数据库。
3. 创建表和插入数据:
- 定义表结构,插入数据。
# Python代码示例(使用Cassandra驱动程序)
from cassandra.cluster import Cluster
cluster = Cluster(['localhost'])
session = Cluster.connect()
session.execute("CREATE KEYSPACE IF NOT EXISTS mykeyspace WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor':1}")
session.set_keyspace('mykeyspace')
session.execute("CREATE TABLE IF NOT EXISTS mytable (id UUID PRIMARY KEY, column1 text, column2 int)")
session.execute("INSERT INTO mytable (id, column1, column2) VALUES (uuid(), 'value', 42)")在Cassandra中,上述CQL语句将一行数据插入名为 mytable 的表中,该行包含一个UUID(唯一标识符)、一个字符串列(column1)和一个整数列(column2)。
INSERT INTO mytable (id, column1, column2) VALUES (uuid(), 'value1', 42)
图形数据库(Graph Database)
图形数据库的例子包括Neo4j、ArangoDB等。
1. 安装数据库:
- 对于Neo4j, 可以从官方网站下载并安装。
- 在Linux上,可以使用命令'sudo apt-get install neo4j'进行安装。
2. 启动数据库:
- 启动数据库服务。
3. 连接数据库:
- 使用相应的驱动程序在代码中连接到数据库。
4. 创建节点和关系:
- 创建节点和关系,并添加属性。
# Python代码示例(使用py2neo)
from py2neo import Graph, Node, Relationship
graph = Graph("bolt://localhost:7687", user="neo4j", password="password")
node_a = Node("Person", name="Alice")
node_b = Node("Person", name="Bob")
relationship_ab = Relationship(node_a, "KNOWS", nobe_b)
graph.create(node_a)
graph.create(node_b)
graph.create(relationship_ab)在Neo4j中,上述代码创建了两个带有属性的节点(代表人物Alice和Bob),以及一个关系(代表Alice和Bob之间的关系)。节点和关系都具有相应的标签和属性。
以上代码示例是简单的入门代码,实际上,每个数据库都有更多的功能和配置选项。在使用这些数据库之前,建议仔细阅读相应数据库的官方文档。