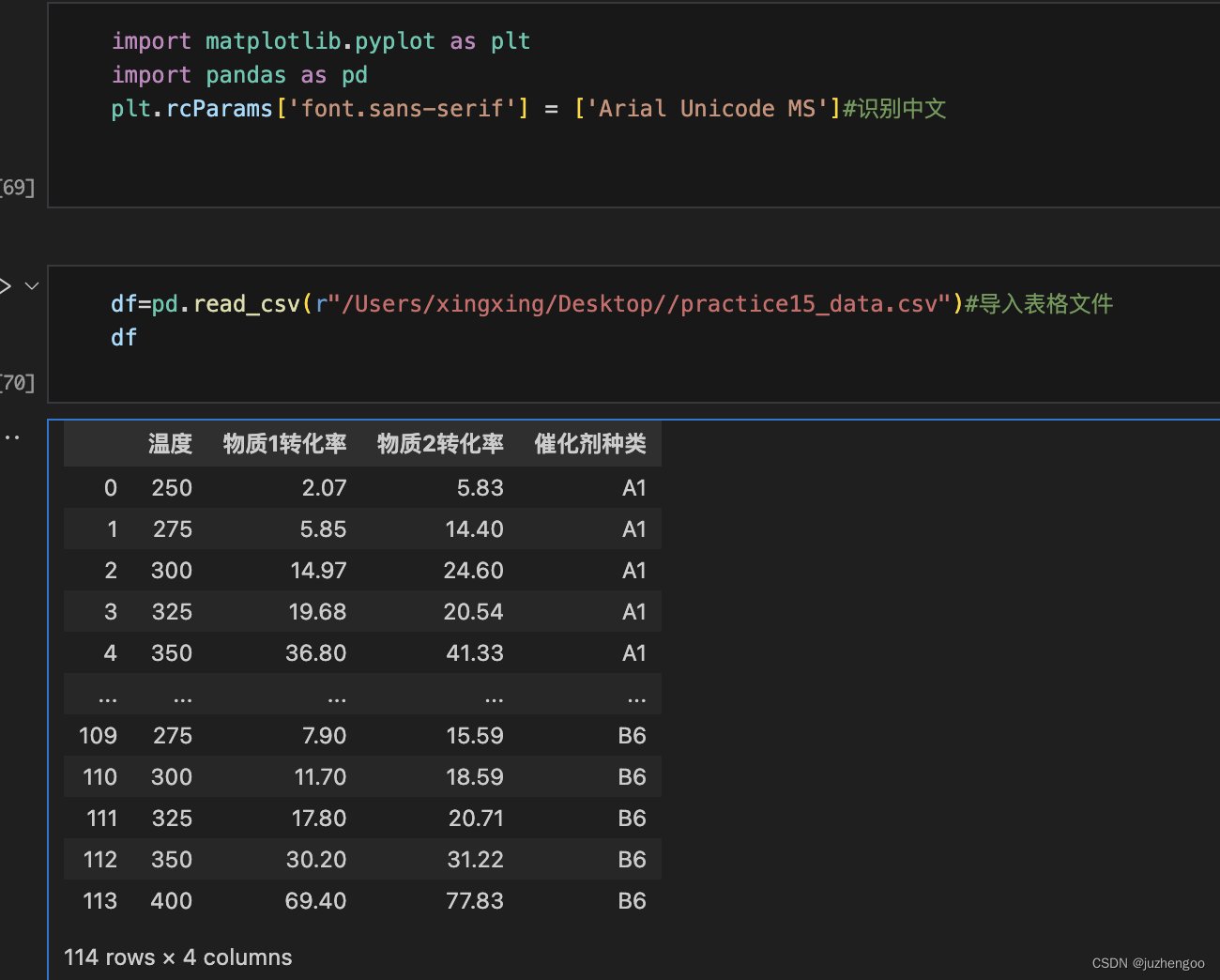
一、基础知识点
1. Python基础语法
变量与数据类型
- 定义变量,理解变量的命名规则
- 基本数据类型:整数、浮点数、字符串
- 列表、元组、字典、集合等复合数据类型
1. 1 变量
1.1.1 变量的定义
在Python中,变量是用来存储数据值的标识符。你可以将变量看作是数据的容器,用于存储和操作数据。
# 变量的定义
x = 5
name = "John"
1.1.2 变量的命名规则
- 变量名只能包含字母(大小写敏感)、数字和下划线。
- 变量名不能以数字开头。
- 变量名不能是Python的关键字(如
if、for、while等)。 - 变量名应该具有描述性,方便理解代码的含义。
my_variable = 10
user_age = 25
1.1.3 动态类型
Python是一种动态类型的语言,意味着你可以在运行时更改变量的类型。例如:
x = 5 # x是整数类型
x = "Hello" # x变成字符串类型
1.2 数据类型
1.2.1 基本数据类型
整数(int): 用于表示整数,例如
5,-10。浮点数(float): 用于表示带有小数的数字,例如
3.14,-0.01。字符串(str): 用于表示文本,可以使用单引号或双引号,例如
'Hello',"Python"。
1.2.2 复合数据类型
列表(List): 有序可变的序列,用方括号表示,例如
[1, 2, 3]。元组(Tuple): 有序不可变的序列,用圆括号表示,例如
(1, 2, 3)。字典(Dictionary): 无序的键值对集合,用花括号表示,例如
{'name': 'John', 'age': 25}。集合(Set): 无序的唯一元素集合,用花括号表示,例如
{1, 2, 3}。
1.2.3 类型转换
在需要时,可以使用类型转换来将一个数据类型转换为另一个数据类型。
x = 5
y = float(x) # 将整数转换为浮点数
z = str(x) # 将整数转换为字符串
1.2.4 None类型
None 是Python中的特殊类型,表示空或缺失值。
result = None
1.3 运算符和表达式
- 算术运算符、比较运算符、逻辑运算符
- 表达式的计算顺序和优先级
1.3.1 算术运算符
算术运算符用于执行基本的数学运算。
+:加法-:减法*:乘法/:除法%:取模(余数)**:幂运算//:整除(取商的整数部分)
a = 10
b = 3
print(a + b) # 13
print(a - b) # 7
print(a * b) # 30
print(a / b) # 3.333...
print(a % b) # 1
print(a ** b) # 1000
print(a // b) # 3
1.3.2 比较运算符
比较运算符用于比较两个值。
==:等于!=:不等于>:大于<:小于>=:大于等于<=:小于等于
x = 5
y = 10
print(x == y) # False
print(x != y) # True
print(x > y) # False
print(x < y) # True
print(x >= y) # False
print(x <= y) # True
1.3.3 逻辑运算符
逻辑运算符用于组合条件。
and:与,两个条件都为True时结果为Trueor:或,两个条件有一个为True时结果为Truenot:非,取反
a = True
b = False
print(a and b) # False
print(a or b) # True
print(not a) # False
1.3.4 表达式的计算顺序和优先级
表达式中的运算符有不同的优先级,计算时会按照一定的顺序执行。通常,算术运算符优先级高于比较运算符,比较运算符优先级高于逻辑运算符。
可以使用小括号 () 来改变运算的优先级。
result = (3 + 4) * 5
print(result) # 35
通常,建议使用小括号来明确运算的优先级,以提高代码的可读性。
1.4 控制流程
- 条件语句:if、elif、else
- 循环语句:for、while
- 循环控制语句:break、continue
1.4.1条件语句
在 Python 中,条件语句主要包括 if、elif(else if 的缩写)、else。条件语句用于根据不同的条件执行不同的代码块。
if语句
if 语句用于执行一个代码块,当指定条件为 True 时。语法如下:
if 条件:
# 当条件为 True 时执行的代码块
elif语句
elif 语句用于指定多个条件,如果前面的 if 或 elif 条件不满足,则继续检查下一个条件。语法如下:
if 条件1:
# 条件1为 True 时执行的代码块
elif 条件2:
# 条件2为 True 时执行的代码块
elif 条件3:
# 条件3为 True 时执行的代码块
# 可以有多个 elif
else:
# 所有条件均不满足时执行的代码块
else语句
else 语句用于指定当所有条件都不满足时执行的代码块。语法如下:
if 条件:
# 条件为 True 时执行的代码块
else:
# 条件不满足时执行的代码块
1.4.2 循环语句
在 Python 中,常见的循环语句有 for 循环和 while 循环。
for循环
for 循环用于遍历可迭代对象(例如列表、元组、字符串等),并执行循环体中的代码块。语法如下:
for 变量 in 可迭代对象:
# 循环体中执行的代码块
while循环
while 循环用于在条件为 True 的情况下执行循环体中的代码块,直到条件变为 False。语法如下:
while 条件:
# 循环体中执行的代码块
1.4.3 循环控制语句
循环控制语句用于在循环中控制代码的执行流程。
break语句
break 语句用于跳出当前循环,不再执行循环体中未执行的代码,直接跳到循环后面的代码。语法如下:
for 变量 in 可迭代对象:
if 条件:
# 满足条件时执行的代码块
break
continue语句
continue 语句用于结束当前循环的本次迭代,继续执行下一次迭代。语法如下:
for 变量 in 可迭代对象:
if 条件:
# 满足条件时执行的代码块
continue
# 不满足条件时执行的代码块
这些控制流程的语句使得 Python 能够更灵活地根据条件执行不同的代码块或者循环遍历数据。
1.5 函数
- 定义函数,函数的参数传递
- 函数的返回值
- 函数的调用和传递参数的方式
1.5.1 定义函数
在 Python 中,函数使用 def 关键字进行定义。函数定义的基本语法如下:
def function_name(parameter1, parameter2, ...):
# 函数体,执行具体的操作
return result # 可选,用于返回函数结果
function_name是函数的名称,要符合标识符的命名规则。(parameter1, parameter2, ...)是函数的参数列表,可以包含零个或多个参数。return result是可选的返回语句,用于返回函数的执行结果。
1.5.2 函数的参数传递
Python 中的函数参数传递有两种方式:位置参数和关键字参数。
- 位置参数
位置参数是最普通的参数传递方式,根据参数的位置进行传递。例如:
def greet(name, age):
print(f"Hello, {
name}! You are {
age} years old.")
# 调用函数
greet("Alice", 25)
在这个例子中,name 和 age 是位置参数,根据调用函数时传递的位置进行赋值。
- 关键字参数
关键字参数是通过参数名进行传递的,可以不按照函数定义时的参数顺序传递。例如:
def greet(name, age):
print(f"Hello, {
name}! You are {
age} years old.")
# 调用函数,使用关键字参数
greet(age=25, name="Bob")
在这个例子中,通过 name="Bob" 和 age=25 这样的形式传递参数,不受参数位置的限制。
1.5.3 函数的返回值
函数可以通过 return 语句返回结果。一个函数可以返回多个值,用逗号隔开。
def add_and_multiply(a, b):
sum_result = a + b
product_result = a * b
return sum_result, product_result
# 调用函数,并接收返回值
sum_result, product_result = add_and_multiply(3, 4)
print(f"Sum: {
sum_result}, Product: {
product_result}")
1.5.4 函数的调用和传递参数的方式
函数的调用是通过函数名和参数列表完成的。在调用函数时,可以使用位置参数、关键字参数,也可以混合使用。例如:
# 使用位置参数
result1 = add_and_multiply(3, 4)
# 使用关键字参数
result2 = add_and_multiply(a=3, b=4)
# 混合使用位置参数和关键字参数
result3 = add_and_multiply(3, b=4)
2. Python数据结构
2.1 列表(List):
- 列表的创建、索引和切片
- 列表的增删改查操作
2.1.1 列表的创建、索引和切片
在 Python 中,列表是一种有序、可变的数据类型,可以存储任意类型的元素。列表的创建可以通过 [] 符号或者使用 list() 函数进行。
# 创建列表
my_list = [1, 2, 3, 'a', 'b', 'c']
# 索引和切片
print(my_list[0]) # 输出:1
print(my_list[1:4]) # 输出:[2, 3, 'a']
print(my_list[-1]) # 输出:'c'
2.1.2 列表的增删改查操作
- 增加元素:
append(): 在列表末尾添加元素。insert(): 在指定位置插入元素。
my_list = [1, 2, 3]
my_list.append(4) # [1, 2, 3, 4]
my_list.insert(1, 5) # [1, 5, 2, 3, 4]
- 删除元素:
remove(): 移除列表中指定的值。pop(): 移除列表中指定位置的元素,如果不指定位置,默认移除末尾元素。del: 删除列表中指定位置的元素或整个列表。
my_list = [1, 5, 2, 3, 4]
my_list.remove(2) # [1, 5, 3, 4]
my_list.pop(1) # [1, 3, 4]
del my_list[0] # [3, 4]
- 修改元素:
- 通过索引直接赋值。
my_list = [1, 2, 3]
my_list[1] = 5 # [1, 5, 3]
- 查找元素:
index(): 返回指定值的索引,如果不存在会抛出异常。count(): 返回指定值在列表中出现的次数。
my_list = [1, 5, 2, 3, 4, 5]
index = my_list.index(5) # 返回值的索引,index = 1
count = my_list.count(5) # 返回值出现的次数,count = 2
以上是列表的基本操作,列表是 Python 中非常常用且灵活的数据结构,可以用于存储和处理各种类型的数据。
2.2 元组(Tuple):
- 元组的不可变性
- 元组的基本操作
2.2.1 元组的不可变性
元组是 Python 中的另一种有序、可迭代、且具有不可变性的数据类型。不可变性意味着一旦创建,元组的元素不可修改,添加或删除。
# 创建元组
my_tuple = (1, 2, 3, 'a', 'b', 'c')
# 不可变性
my_tuple[0] = 5 # 会抛出 TypeError,元组的元素不可修改
2.2.2 元组的基本操作
- 索引和切片:
- 与列表类似,可以通过索引和切片来访问元组中的元素。
my_tuple = (1, 2, 3, 'a', 'b', 'c')
print(my_tuple[0]) # 输出:1
print(my_tuple[1:4]) # 输出:(2, 3, 'a')
print(my_tuple[-1]) # 输出:'c'
- 拼接和复制:
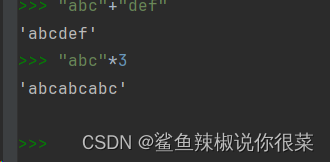
- 使用
+号进行元组的拼接。 - 使用
*号进行元组的复制。
tuple1 = (1, 2, 3)
tuple2 = ('a', 'b', 'c')
result = tuple1 + tuple2 # (1, 2, 3, 'a', 'b', 'c')
repeated = tuple1 * 3 # (1, 2, 3, 1, 2, 3, 1, 2, 3)
- 内置方法:
count(): 返回指定值在元组中出现的次数。index(): 返回指定值的索引,如果不存在会抛出异常。
my_tuple = (1, 2, 3, 'a', 'b', 'c', 2)
count = my_tuple.count(2) # 返回值出现的次数,count = 2
index = my_tuple.index('b') # 返回值的索引,index = 4
元组相较于列表更加轻量,适合用于不需要修改的场景,同时也可以用于多个值的解包(unpacking)操作。
2.3 字典(Dictionary):
- 字典的键值对映射
- 字典的基本操作
2.3.1 字典的键值对映射
字典是 Python 中的一种无序集合,用于存储键值对。每个键值对之间使用冒号 : 分隔,而不同的键值对使用逗号 , 分隔,整个字典包裹在花括号 {} 中。
# 创建字典
my_dict = {
'name': 'John', 'age': 25, 'city': 'New York'}
# 访问字典中的值
print(my_dict['name']) # 输出:John
print(my_dict['age']) # 输出:25
print(my_dict['city']) # 输出:New York
2.3.2字典的基本操作
- 增加或修改键值对:
- 使用键来访问字典中的值,如果键不存在,会抛出 KeyError。
# 增加键值对
my_dict['occupation'] = 'Engineer'
# 修改键值对
my_dict['age'] = 26
- 删除键值对:
- 使用
del语句删除指定键值对,或使用pop()方法返回并删除指定键的值。
# 删除键值对
del my_dict['city']
# 使用 pop() 方法删除键值对
removed_age = my_dict.pop('age')
- 获取所有键、值、键值对:
- 使用
keys()方法获取所有键。 - 使用
values()方法获取所有值。 - 使用
items()方法获取所有键值对。
# 获取所有键
keys = my_dict.keys()
# 获取所有值
values = my_dict.values()
# 获取所有键值对
items = my_dict.items()
- 检查键的存在:
- 使用
in关键字检查键是否存在于字典中。
# 检查键是否存在
if 'name' in my_dict:
print('Key exists!')
字典是 Python 中灵活且强大的数据结构,常用于存储和处理各种数据信息。
2.4 集合(Set):
- 集合的创建和基本操作
- 集合的交、并、差运算
2.4 集合(Set)
2.4.1 集合的创建和基本操作
集合是一种无序、不重复的元素集,可以使用大括号 {} 或者 set() 函数创建。
# 创建集合
my_set = {
1, 2, 3, 4, 5}
another_set = set([3, 4, 5, 6, 7])
# 添加元素
my_set.add(6)
# 移除元素
my_set.remove(3)
集合的特点是不允许重复元素,因此添加重复元素不会改变集合。集合还支持一些基本的数学运算,如并集、交集、差集等。
2.4.2 集合的交、并、差运算
# 集合的交集
intersection_set = my_set.intersection(another_set)
# 集合的并集
union_set = my_set.union(another_set)
# 集合的差集
difference_set = my_set.difference(another_set)
集合是一种高效的数据结构,常用于去除重复元素,以及进行集合运算。需要注意的是,集合是无序的,不支持通过索引访问元素。
3. 文件操作:
3.1 文件读写操作:
- 使用
open()打开文件 - 文件的读取、写入和关闭
- with语句的使用
3.1.1 使用 open() 打开文件
在 Python 中,可以使用内置的 open() 函数来打开文件。open() 函数的基本语法如下:
file = open("filename", "mode")
其中,filename 是要打开的文件名,mode 是打开文件的模式,常见的模式包括:
'r':读取模式(默认)'w':写入模式,会覆盖已存在的文件'a':追加模式,将内容追加到已存在文件的末尾'b':二进制模式,用于处理二进制文件
3.1.2 文件的读取、写入和关闭
# 读取文件
with open("example.txt", "r") as file:
content = file.read()
print(content)
# 写入文件
with open("output.txt", "w") as file:
file.write("Hello, Python!")
# 追加内容到已存在文件
with open("output.txt", "a") as file:
file.write("\nAppended Line.")
# 读取文件的每一行并放入列表中
with open("example.txt", "r") as file:
lines = file.readlines()
for line in lines:
print(line.strip()) # strip() 用于去除行尾的换行符
# 关闭文件
file.close()
3.1.3 使用 with 语句的好处
with 语句可以确保文件在使用完毕后正确关闭,即便发生异常。在 with 语句块执行完成后,Python 会自动关闭文件,无需手动调用 close() 方法。
with open("example.txt", "r") as file:
content = file.read()
# 在这里进行文件操作,无需手动关闭文件
# 文件已在退出 with 语句块后自动关闭
这样可以避免忘记关闭文件而导致资源泄漏的问题。
3.2 文件路径:
- 相对路径和绝对路径
- 常用路径操作
3.2.1 相对路径和绝对路径
相对路径:相对于当前工作目录的路径。例如,
"example.txt"表示当前目录下的example.txt文件。绝对路径:从根目录开始的完整路径。例如,
"/home/user/documents/example.txt"表示系统中的完整路径。
在使用文件路径时,相对路径更具灵活性,但有时需要确保当前工作目录的设置。绝对路径则更具明确性。
3.2.2 常用路径操作
在 Python 中,使用 os 模块进行常用路径操作。
import os
# 获取当前工作目录
current_directory = os.getcwd()
print("Current Directory:", current_directory)
# 拼接路径
file_path = os.path.join(current_directory, "example.txt")
print("File Path:", file_path)
# 获取文件名和目录名
filename = os.path.basename(file_path)
directory = os.path.dirname(file_path)
print("Filename:", filename)
print("Directory:", directory)
# 检查路径是否存在
exists = os.path.exists(file_path)
is_directory = os.path.isdir(current_directory)
is_file = os.path.isfile(file_path)
print("Exists:", exists)
print("Is Directory:", is_directory)
print("Is File:", is_file)
这些操作可以用于构建跨平台的路径,同时检查文件和目录是否存在。
4. 函数和模块:
4.1 函数:
- 函数的定义和调用
- 函数的参数传递方式
- 匿名函数(lambda函数)
4.1.1 函数的定义和调用
在 Python 中,函数通过 def 关键字进行定义。函数定义的一般格式如下:
def function_name(parameter1, parameter2, ...):
# 函数体
# ...
return result # 可选的返回值
其中:
function_name为函数名称。parameter1,parameter2, … 为函数的参数,可以有零个或多个。- 函数体包含了函数的具体实现。
return语句用于返回函数的结果,可以省略。
调用函数时,使用函数名和相应的参数进行调用:
result = function_name(arg1, arg2, ...)
4.1.2 函数的参数传递方式
Python 中的函数参数传递方式有两种:传值(传递对象的引用)和传引用(传递对象的副本)。
- 传值(传递对象的引用):传递的是对象的引用,函数内对参数的修改会影响到原始对象。
def modify_list(my_list):
my_list.append(4)
original_list = [1, 2, 3]
modify_list(original_list)
print(original_list) # 输出 [1, 2, 3, 4]
- 传引用(传递对象的副本):传递的是对象的副本,函数内对参数的修改不会影响到原始对象。
def modify_variable(my_var):
my_var = 10
original_var = 5
modify_variable(original_var)
print(original_var) # 输出 5
4.1.3 匿名函数(lambda 函数)
Lambda 函数是一种简化的函数定义方式,使用 lambda 关键字。它可以有多个参数,但只能有一个表达式。
# lambda 函数的定义
add = lambda x, y: x + y
# lambda 函数的调用
result = add(2, 3)
print(result) # 输出 5
Lambda 函数通常用于需要一个简单函数的地方,而不必正式定义一个完整的函数。
4.2 模块:
- 模块的导入和使用
- 模块的命名空间
4.2.1 模块的导入和使用
在 Python 中,模块是一组相关的函数、类和变量的集合,保存在一个以 .py 结尾的文件中。通过导入模块,我们可以使用其中定义的函数、类和变量。
# 导入整个模块
import module_name
# 使用模块中的函数
module_name.function_name()
# 导入模块中的特定函数
from module_name import specific_function
# 使用导入的函数
specific_function()
4.2.2 模块的命名空间
模块在 Python 中拥有自己的命名空间,这意味着它包含的函数、类和变量都位于模块的命名空间内。通过模块名加点操作符可以访问这些内容。
# 导入模块
import module_name
# 使用模块的函数
module_name.function_name()
# 使用模块的变量
variable = module_name.variable_name
这种方式避免了命名冲突,因为模块的命名空间隔离了不同模块之间的变量和函数。
5. 面向对象编程:
5.1 类与对象:
- 类的定义,实例化对象
- 类的属性和方法
- 类的继承、封装、多态
5.1.1 类的定义,实例化对象
在 Python 中,类是一种用于创建对象的抽象数据类型。类定义了对象的属性(变量)和方法(函数),通过实例化类可以创建对象。以下是一个简单的类定义和实例化过程:
# 定义一个简单的类
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def display_info(self):
print(f"{
self.year} {
self.make} {
self.model}")
# 实例化对象
my_car = Car("Toyota", "Camry", 2022)
# 访问对象的属性
print(my_car.make) # 输出:Toyota
# 调用对象的方法
my_car.display_info() # 输出:2022 Toyota Camry
5.1.2 类的属性和方法
- 类的属性:类中定义的变量,用于存储对象的状态。
- 类的方法:类中定义的函数,用于表示对象的行为。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
def bark(self):
print("Woof!")
# 创建 Dog 对象
my_dog = Dog("Buddy", 3)
# 访问属性
print(my_dog.name) # 输出:Buddy
# 调用方法
my_dog.bark() # 输出:Woof!
5.1.3 类的继承、封装、多态
- 继承:一个类可以继承另一个类的属性和方法。
- 封装:将类的属性和方法封装在类的内部,通过访问控制符(如私有属性
__private_attr)控制对类内部的访问。 - 多态:不同的对象可以对同一个方法做出不同的响应,提高灵活性。
# 继承
class ElectricCar(Car):
def __init__(self, make, model, year, battery_size):
super().__init__(make, model, year)
self.battery_size = battery_size
# 封装
class Student:
def __init__(self, name, age):
self.__name = name # 私有属性
self.__age = age
def get_name(self):
return self.__name
# 多态
def animal_sound(animal):
animal.make_sound()
class Cat:
def make_sound(self):
print("Meow!")
class Dog:
def make_sound(self):
print("Woof!")
my_cat = Cat()
my_dog = Dog()
animal_sound(my_cat) # 输出:Meow!
animal_sound(my_dog) # 输出:Woof!
5.2 特殊方法:
__init__初始化方法__str__字符串表示方法
5.2.1 __init__ 初始化方法
__init__ 是一个特殊的方法,用于在创建对象时进行初始化操作。该方法在对象实例化时自动调用,用于设置对象的初始状态。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 创建对象时自动调用 __init__ 方法
person = Person("John", 25)
print(person.name) # 输出:John
print(person.age) # 输出:25
5.2.2 __str__ 字符串表示方法
__str__ 方法用于定义对象的字符串表示形式。当使用 print 函数打印对象时,会调用该方法返回字符串。
class Book:
def __init__(self, title, author):
self.title = title
self.author = author
def __str__(self):
return f"{
self.title} by {
self.author}"
# 创建对象并打印对象
book = Book("Python Basics", "John Doe")
print(book) # 输出:Python Basics by John Doe
通过实现 __str__ 方法,我们可以自定义对象的字符串输出,使其更具可读性。
这两个特殊方法是 Python 中常用的,还有其他一些特殊方法用于重载运算符、实现迭代器等,提供了更多的灵活性和控制权。
6. 异常处理:
6.1 异常处理机制:
- try、except、finally的使用
- 常见的异常类型处理
在 Python 中,异常处理是一种处理程序运行时可能发生错误的机制。异常是程序在运行过程中发生的事件,它会中断正常的程序流程。为了使程序更加健壮,我们可以使用 try、except、finally 语句进行异常处理。
6.1.1 try、except、finally 语句的使用
try语句块中包含可能发生异常的代码。except语句块中包含异常的处理逻辑,当try语句块中的代码发生异常时,程序会跳转到相应的except语句块。finally语句块中的代码无论是否发生异常,都会被执行。
try:
# 可能发生异常的代码
result = 10 / 0
except ZeroDivisionError:
# 处理特定类型的异常
print("Cannot divide by zero!")
except Exception as e:
# 处理其他类型的异常
print(f"An error occurred: {
e}")
finally:
# 无论是否发生异常,都会执行的代码
print("This code always runs.")
6.1.2 常见异常类型的处理
在 except 语句块中,可以处理特定类型的异常,也可以使用通用的 Exception 来捕获所有类型的异常。以下是一些常见的异常类型:
ZeroDivisionError: 除以零的异常。ValueError: 传入的参数类型正确但值不合适的异常。TypeError: 操作或函数调用的对象类型不合适的异常。IndexError: 索引超出序列范围的异常。KeyError: 字典中查找一个不存在的关键字的异常。
try:
# 可能发生异常的代码
num = int("abc")
except ValueError as ve:
# 处理值错误异常
print(f"ValueError: {
ve}")
except TypeError as te:
# 处理类型错误异常
print(f"TypeError: {
te}")
except Exception as e:
# 处理其他类型的异常
print(f"An error occurred: {
e}")
通过合理使用异常处理,可以使程序在面对错误时更加优雅和稳定,同时方便开发者定位和调试问题。
7. Python标准库的使用:
7.1 时间与日期操作:
datetime模块的使用- 时间格式化和解析
7.1 时间与日期操作
7.1.1 datetime 模块的使用
在 Python 中,datetime 模块提供了处理日期和时间的类和函数。使用这个模块,你可以轻松执行与时间相关的操作。
from datetime import datetime, timedelta
# 获取当前时间
current_time = datetime.now()
print("当前时间:", current_time)
# 创建指定日期时间
specified_time = datetime(2023, 1, 1, 12, 0, 0)
print("指定日期时间:", specified_time)
# 时间加减
next_week = current_time + timedelta(weeks=1)
print("一周后:", next_week)
# 时间格式化
formatted_time = current_time.strftime("%Y-%m-%d %H:%M:%S")
print("格式化时间:", formatted_time)
# 将字符串解析为时间对象
str_time = "2022-01-01 08:00:00"
parsed_time = datetime.strptime(str_time, "%Y-%m-%d %H:%M:%S")
print("解析时间:", parsed_time)
7.1.2 时间格式化和解析
strftime 方法可以将 datetime 对象格式化为字符串,指定格式字符串中的不同格式符可以表示不同的时间信息。
strptime 方法可以将字符串解析为 datetime 对象,同样需要提供格式字符串以告知解析器如何理解输入的字符串。
# 时间格式化
formatted_time = current_time.strftime("%Y-%m-%d %H:%M:%S")
print("格式化时间:", formatted_time)
# 将字符串解析为时间对象
str_time = "2022-01-01 08:00:00"
parsed_time = datetime.strptime(str_time, "%Y-%m-%d %H:%M:%S")
print("解析时间:", parsed_time)
以上是 datetime 模块的一些基本用法,通过这些功能,你可以更灵活地处理时间与日期相关的任务。
7.2 正则表达式:
re模块的基本使用
正则表达式是一种强大且灵活的字符串匹配工具,Python 中通过 re 模块提供了对正则表达式的支持。
以下是 re 模块的一些基本用法:
import re
# 使用 re.match() 匹配字符串的开头
pattern = re.compile(r'\d+')
result = pattern.match("123abc")
print(result.group()) # 输出匹配到的字符串
# 使用 re.search() 查找整个字符串中的匹配
result = re.search(r'\d+', "abc123def")
print(result.group())
# 使用 re.findall() 查找所有匹配的字符串
results = re.findall(r'\d+', "abc123def456")
print(results)
# 使用 re.finditer() 返回一个迭代器,包含所有匹配对象
iterator = re.finditer(r'\d+', "abc123def456")
for match in iterator:
print(match.group())
# 使用 re.sub() 替换字符串中的匹配项
new_string = re.sub(r'\d+', 'X', "abc123def456")
print(new_string)
7.3 常见内建函数:
Python 提供了许多内建函数,这些函数是内置在 Python 解释器中的,无需额外导入模块即可使用。以下是一些常见的内建函数:
len():返回对象的长度或元素个数。适用于字符串、列表、元组、字典等。
string_length = len("Hello, World!")
print(string_length) # 输出:13
max():返回可迭代对象中的最大值。
maximum_value = max(3, 1, 4, 1, 5, 9, 2)
print(maximum_value) # 输出:9
min():返回可迭代对象中的最小值。minimum_value = min(3, 1, 4, 1, 5, 9, 2) print(minimum_value) # 输出:1sum():返回可迭代对象中所有元素的总和。total_sum = sum([1, 2, 3, 4, 5]) print(total_sum) # 输出:15abs():返回数值的绝对值。absolute_value = abs(-10) print(absolute_value) # 输出:10round():四舍五入。rounded_value = round(3.14159, 2) print(rounded_value) # 输出:3.14sorted():对可迭代对象进行排序。sorted_list = sorted([3, 1, 4, 1, 5, 9, 2]) print(sorted_list) # 输出:[1, 1, 2, 3, 4, 5, 9]
8. 文件解析:
8.1 文件格式解析:
在 Python 中,有许多库可以用于解析不同格式的文件。以下是一些常见文件格式的解析方法:
JSON 文件解析
使用
json模块可以轻松解析 JSON 格式的数据。import json # 读取 JSON 文件 with open('data.json', 'r') as file: data = json.load(file) # 输出 JSON 数据 print(data)CSV 文件解析
对于 CSV 格式的文件,可以使用
csv模块。import csv # 读取 CSV 文件 with open('data.csv', 'r') as file: csv_reader = csv.reader(file) for row in csv_reader: print(row)XML 文件解析
使用
xml.etree.ElementTree模块来解析 XML 文件。import xml.etree.ElementTree as ET # 解析 XML 文件 tree = ET.parse('data.xml') root = tree.getroot() # 遍历 XML 数据 for element in root: print(element.tag, element.text)HTML 文件解析
对于 HTML 文件,可以使用
BeautifulSoup或lxml库来解析。from bs4 import BeautifulSoup # 使用 BeautifulSoup 解析 HTML with open('index.html', 'r') as file: soup = BeautifulSoup(file, 'html.parser') # 输出 HTML 数据 print(soup.prettify())
9. 虚拟环境和包管理:
9.1 虚拟环境:
virtualenv的使用- 虚拟环境的创建与激活
9.2 包管理:
pip 是 Python 的包管理工具,用于安装和管理第三方库。以下是一些常见的 pip 命令:
安装包
pip install package_name通过该命令可以安装指定的 Python 包。例如,要安装
requests库:pip install requests指定版本安装
如果需要安装特定版本的包,可以使用以下语法:
pip install package_name==version_number例如:
pip install requests==2.26.0升级包
若要升级已安装的包到最新版本,可以使用以下命令:
pip install --upgrade package_name例如:
pip install --upgrade requests卸载包
卸载已安装的包可以使用以下命令:
pip uninstall package_name例如:
pip uninstall requests查看已安装的包
若要查看已安装的所有包及其版本,可以运行以下命令:
pip list或者使用:
pip freeze以上命令列出了已安装包的名称及其版本信息。
10. 基本算法和数据结构:
10.1 基本排序算法:
10.1.1 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,它重复地遍历数组,比较相邻的两个元素,并按照升序或降序交换它们,直到整个数组有序。
算法步骤:
- 从第一个元素开始,依次比较相邻的两个元素,如果顺序不对,则交换它们。
- 对数组的所有元素重复上述步骤,直到没有再需要交换的元素,即数组有序。
示例代码:
def bubble_sort(arr): n = len(arr) # 遍历所有数组元素 for i in range(n): # 最后 i 个元素已经排好序,无需再比较 for j in range(0, n-i-1): # 如果元素大于下一个元素,则交换它们 if arr[j] > arr[j+1]: arr[j], arr[j+1] = arr[j+1], arr[j] # 示例 my_list = [64, 34, 25, 12, 22, 11, 90] bubble_sort(my_list) print("排序后的数组:", my_list)
10.1.2 插入排序(Insertion Sort)
插入排序是一种简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
算法步骤:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果已排序元素大于新元素,则将已排序元素移到下一位置。
- 重复步骤 3,直到找到已排序的元素小于或等于新元素的位置。
- 将新元素插入到找到的位置。
- 重复以上步骤,直到整个数组有序。
示例代码:
def insertion_sort(arr): for i in range(1, len(arr)): key = arr[i] j = i-1 # 将元素插入到已排序序列的正确位置 while j >= 0 and key < arr[j]: arr[j+1] = arr[j] j -= 1 arr[j+1] = key # 示例 my_list = [64, 34, 25, 12, 22, 11, 90] insertion_sort(my_list) print("排序后的数组:", my_list)
这两种排序算法都是基本的比较排序算法,它们简单易懂,但在处理大规模数据时效率较低。在实际应用中,更常用的是一些更为高效的排序算法,如快速排序、归并排序等。
10.2 基本搜索算法:
10.2.1 二分查找(Binary Search)
二分查找是一种在有序数组中查找目标值的高效算法。它的工作原理是不断将目标值与数组中间元素比较,从而减少搜索范围。
算法步骤:
- 将数组的第一个元素设置为左边界,将数组最后一个元素设置为右边界。
- 计算中间位置(左边界 + 右边界)/ 2。
- 比较中间位置的元素与目标值:
- 如果中间元素等于目标值,返回中间元素的索引。
- 如果中间元素大于目标值,将右边界移动到中间元素左侧。
- 如果中间元素小于目标值,将左边界移动到中间元素右侧。
- 重复上述步骤,直到找到目标值或左边界大于右边界。
示例代码:
def binary_search(arr, target): left, right = 0, len(arr) - 1 while left <= right: mid = (left + right) // 2 # 判断目标值与中间元素的关系 if arr[mid] == target: return mid # 目标值找到,返回索引 elif arr[mid] < target: left = mid + 1 # 在右侧继续搜索 else: right = mid - 1 # 在左侧继续搜索 return -1 # 目标值不在数组中 # 示例 my_list = [11, 22, 25, 34, 64, 90] target_value = 34 result = binary_search(my_list, target_value) print(f"目标值 { target_value} 在数组中的索引为 { result}")
二分查找是一种高效的搜索算法,但它要求数据是有序的。如果数据无序,可以选择其他搜索算法,如线性查找。
11. 常见的Python库:
11.1 请求库:
requests库的基本使用
11.2 数据处理库:
11.2.1 NumPy(Numerical Python)
NumPy 是 Python 中用于科学计算的一个重要库,它提供了一个强大的多维数组对象(numpy.ndarray)和用于处理这些数组的工具。以下是 NumPy 的一些基本用法:
创建数组:
import numpy as np # 创建一维数组 arr1 = np.array([1, 2, 3]) # 创建二维数组 arr2 = np.array([[1, 2, 3], [4, 5, 6]]) # 创建全零数组 zeros_arr = np.zeros((3, 3)) # 创建全一数组 ones_arr = np.ones((2, 2)) # 创建等差数组 linspace_arr = np.linspace(0, 1, 5) # 从 0 到 1 生成 5 个等差数列 # 创建随机数组 random_arr = np.random.rand(3, 3) # 3x3 的随机数组数组操作:
# 数组形状 shape = arr2.shape # (2, 3) # 数组维度 dim = arr2.ndim # 2 # 数组元素类型 dtype = arr2.dtype # int64 # 数组转置 transposed_arr = arr2.T # 数组索引和切片 element = arr2[0, 1] # 获取第一行第二列的元素 subarray = arr2[:, 1:3] # 获取所有行的第二到第三列的子数组
11.2.2 Pandas
Pandas 是基于 NumPy 构建的数据分析工具,提供了用于数据操作和分析的数据结构,主要有 Series 和 DataFrame。
Series:
Series 是一维标记数组,可以容纳任何数据类型。它包括数据和索引两部分。
import pandas as pd # 创建 Series s = pd.Series([1, 3, 5, np.nan, 6, 8]) # 指定索引的 Series s_with_index = pd.Series([1, 3, 5, np.nan, 6, 8], index=['a', 'b', 'c', 'd', 'e', 'f'])DataFrame:
DataFrame 是二维表格数据结构,可以容纳不同数据类型的列。DataFrame 可以看作是一组 Series 的集合。
# 创建 DataFrame df = pd.DataFrame({ 'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35], 'city': ['New York', 'San Francisco', 'Los Angeles'] }) # 从 CSV 文件读取数据 df_from_csv = pd.read_csv('data.csv') # 查看 DataFrame 的头部几行 head = df.head() # 筛选数据 filtered_data = df[df['age'] > 30] # 添加新列 df['salary'] = [50000, 60000, 70000]
12. 编码规范:
12.1 PEP 8编码规范:
- 代码缩进、空格、命名规范等
二、代码题
1.请编写符合该货车月折旧金额计算的代码逻辑。
from decimal import Decimal
def dec2str(dec):
return str(Decimal(dec).quantize(Decimal('0.00')))
def func(originalPrice, netResidualValueRate, totalWorkload, monthWork):
"""originalPrice:固定资产原价
netResidualValueRate:预计净残值率
totalWorkload:预计总工作量
monthWork:当月工作量
"""
# 创建变量unitDep接收单位工作量折旧额
unitDep = (originalPrice * (1 - netResidualValueRate)) / totalWorkload
# 创建变量depAmount接收本月折旧额
depAmount = unitDep * monthWork
return dec2str(depAmount)
print('本月折旧金额为', func(600000, 0.05, 500000, 4000))
2.请编写固定资产累计折旧金额计算的代码逻辑。
from decimal import Decimal
def dec2str(dec):
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量monthDep接收本月折旧金额,变量accumulatedDep接收累计折旧金额
def func(monthDep, accumulatedDep):
accumulatedDep += monthDep
return dec2str(accumulatedDep)
print('固定资产累计折旧金额为', func(5130, 456000))
3.采用比较运算符"<"判断甲方案是否可行。
# 变量x接收乙方案的标准差,变量y接收乙方案的期望值
def func(x, y):
# v1接收甲方案的标准离差率,v2接收乙方案的标准里差率,f接收比较两个方案的结果
v1 = 0.3
v2 = x / y
f = v1 < v2
return f
print(func(330, 1200))
4.如下图print()函数输出结果为“"固定资产"期末余额为20000元。”,那print()函数内应输入内容为?请写出该段代码。
print('"固定资产"期末余额为20000元。')
5.打印输出固定资产折旧表文件路径:C:\teacher\报表\固定资产折旧表
print(r'C:\teacher\报表\固定资产折旧表')
6.请编写代码用于清除字符串中的“#”及“,”
def func(str1): # str1表示字符串
###修改代码开始###
str1 = str1.replace('#', '').replace(',', '')
###修改代码结束###
return str1
print(func('银行存款为,10000元#'))
7.创建两个字典,d1接收不同概率质量问题维修费占比,d2接收A产品不同质量问题数量占比。编写计算A产品预计负债金额的代码逻辑。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
def func(revenue): # 变量接受销售收入
# 创建字典d1接收不同质量问题维修费占销售收入比重
d1 = {
'没有质量问题维修费占比': 0, '质量较小问题维修费占比': 0.01, '质量较大问题维修费占比': 0.02}
# 创建字典d2接收不同质量问题占销量比重
d2 = {
'没有质量问题数量占比': 0.8, '较小质量问题数量占比': 0.15, '较大质量问题数量占比': 0.05}
# 创建变量cost接收预计负债
cost = d1['没有质量问题维修费占比'] * d2['没有质量问题数量占比'] * revenue + \
d1['质量较小问题维修费占比'] * d2['较小质量问题数量占比'] * revenue + \
d1['质量较大问题维修费占比'] * d2['较大质量问题数量占比'] * revenue
return dec2str(cost)
print('销售A产品产生的预计负债是', func(20000))
这段代码会输出销售A产品产生的预计负债是 600.00,表示销售A产品的预计负债金额为600元。
8.请编写本月存货结存成本计算的代码逻辑。
通过将字符串类型的 number 和 unitPrice 转换为浮点数,计算存货结存成本并通过 dec2str 函数将其转换为字符串。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量number接收结存数量,变量unitPrice接收采购单价,注意这两个变量传入数据类型为字符串
def func(number, unitPrice):
# 创建变量cost接收本月存货结存成本
cost = float(number) * float(unitPrice)
return dec2str(cost)
print('本月存货结存成本=', func('56789', '56.98'))
这段代码会输出 本月存货结存成本= 3246721.22,表示本月存货结存成本为 3246721.22 元。
9.请编写财产租赁所得个税应纳税所得额计算的代码逻辑。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量income接收租金收入,变量deductibleItems接收准予扣除项目,变量cost接收修缮费用
def func(income, deductibleItems, cost):
# 设置变量taxableIncome接收应纳税所得额
if income <= 4000:
taxableIncome = income - deductibleItems - cost - 800
elif income > 4000:
taxableIncome = (income - deductibleItems - cost) * (1 - 0.2)
return dec2str(taxableIncome)
print(func(6000, 0, 1000))
10.请编写可以判断期末存货成本计量金额的代码逻辑
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量inventoryCost接收存货成本,变量netRealizableValue接收可变现净值
def func(inventoryCost, netRealizableValue):
# if条件判断开始,cost接收期末计量存货成本
if inventoryCost > netRealizableValue:
cost = netRealizableValue
else:
cost = inventoryCost
return dec2str(cost)
print('期末存货成本计量金额为', func(600000, 956000))
这段代码会输出 '956000.00',表示期末存货成本计量金额为 956,000 元。
11.请编写工资薪金个税计算的代码逻辑
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量taxableIncome接收全年应纳税所得额
def func(taxableIncome):
# 创建变量personalIncomeTax接收应纳个税金额
if taxableIncome <= 0:
personalIncomeTax = 0
elif taxableIncome <= 36000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.03')
elif taxableIncome <= 144000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.1') - Decimal('2520')
elif taxableIncome <= 300000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.2') - Decimal('16920')
elif taxableIncome <= 420000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.25') - Decimal('31920')
elif taxableIncome <= 660000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.3') - Decimal('52920')
elif taxableIncome <= 960000:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.35') - Decimal('85920')
else:
personalIncomeTax = Decimal(taxableIncome) * Decimal('0.45') - Decimal('181920')
return dec2str(personalIncomeTax)
print(func(360000))
这段代码会输出 '17160.00',表示全年应纳税所得额为 360,000 元时的应纳个税金额。
12.编写判断是否获得面试机会的代码逻辑,输出结果分别以下两种情况:
- ‘恭喜,你已获得我公司的面试机会’
- ‘抱歉,你未达到要求’
# 变量age接收年龄,subject接收专业,collede接收学院
def func(age, subject, college):
# if条件语句判断,通过逻辑运算符筛选条件是否符合,变量result接收结果
if (age > 25 and subject == '会计专业') or (college == '重点' and subject == '会计专业') or (age > 25 and college == '重点'):
result = '恭喜,你已获得我公司的面试机会'
# 不符合else语句
else:
result = '抱歉,你未达到要求'
return result
print(func(25, '会计专业', '非重点'))
这段代码会输出 '抱歉,你未达到要求',因为年龄为 25,专业是 ‘会计专业’,学院不是 ‘重点’,不满足任何一个获得面试机会的条件。
13.写出2021年4月1日至2022年12月31日税收优惠期间小规模纳税人应缴增值税金额的编程代码逻辑。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# 变量sales接收销售额
def func(sales):
# 设置变量VAT_payable接收应纳增值税
if sales > 450000:
VAT_payable = sales * 0.03
else:
VAT_payable = 0
return dec2str(VAT_payable)
print('该小规模纳税人第二季度应纳增值税为', func(470000))
这段代码根据销售额判断应纳增值税,如果销售额超过 450,000,按 3% 计算增值税;否则,增值税为 0。你的例子中销售额为 470,000,所以应纳增值税为 470,000 * 0.03 = 14,100 元。
14.写出计算存款每年年末终值的编程代码。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
# P接收现值(本金),i接收利率,n接收期限(年)。
def func(P, i, n):
list1 = [] # 空列表list1存放每年终值计算结果
# 变量F接收终值,调用dec2str()函数对F保留2位小数
for k in range(1, n+1):
F = P * (1 + i) ** k
list1.append(dec2str(F))
return list1
print('各年末的终值依次为', func(10000, 0.08, 5))
这段代码通过循环计算每年的终值,然后将结果添加到列表 list1 中。在你的例子中,现值(本金)为 10,000,利率为 0.08,期限为 5 年,计算了每年年末的终值。你可以根据需要修改参数来尝试不同的输入。
15.写出计算各部门分摊的水电总费用的编程代码,金额保留2位小数。计算结果放在字典D3。
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
def func(x, y, z):
"""
x: 管理部门分摊系数
y: 销售部门分摊系数
z: 生产部门分摊系数
"""
# 创建字典
D1 = {
'管理部门': x, '销售部门': y, '生产部门': z}
D2 = {
'5月水电费': 10000, '6月水电费': 8000, '7月水电费': 9500}
D3 = {
} # 用于接收各部门应分摊的水电费,调用dec2str()函数对水电费保留两位小数
# for循环取key
for key1 in D1:
cost = 0 # 5-7月费用合计
for key2 in D2:
cost1 = D1[key1] * D2[key2] # 各月费用
cost += cost1
D3[key1] = dec2str(cost)
return D3
print('各部门应分摊的水电费用分别为', func(0.2, 0.3, 0.5))
该代码计算了各部门应分摊的水电费用,结果以字典形式返回。你可以根据需要修改系数和费用数据。
16.请编写计算到期日终值的代码
from decimal import Decimal
def dec2str(dec): # 浮点数保留两位数字转字符串
return str(Decimal(dec).quantize(Decimal('0.00')))
def func(P, i, n):
# 变量F接收终值
F = P * (1 + i) ** n
return dec2str(F)
print('到期日终值是', func(10000, 0.08, 5))
该代码计算了到期日的终值,其中 P 表示现值(本金金额),i 表示复利年利率,n 表示存款期。你可以根据需要修改这些参数。
17.先读取Excel中的"年终奖金发放表"为df,根据df筛选姓名、年终奖金,个税三列。
import pandas as pd
def proc():
# 读取Excel表格
df = pd.read_excel('https://keyun-oss.acctedu.com/app/bigdata/basics/nzjj.xlsx', sheet_name='年终奖金发放表')
# 筛选姓名、年终奖金、个税三列
df1 = df[['姓名', '年终奖金', '个税']]
return df1
df = proc()
print(df)
18.根据读取的df,筛选综合管理部门年终奖金超过10000元的员工。
import pandas as pd
def proc():
# 读取Excel表格
df = pd.read_excel('https://keyun-oss.acctedu.com/app/bigdata/basics/nzjj.xlsx', sheet_name='年终奖金发放表')
# 筛选综合管理部门年终奖金超过10000元的员工
df2 = df[(df['一级部门'] == '综合管理部') & (df['年终奖金'] > 10000)]
return df2
df = proc()
print(df)
这段代码使用了 Pandas 的 DataFrame 功能,通过条件筛选找到综合管理部门年终奖金超过10000元的员工。
19.根据读取的df,筛选战略规划部门年终奖金明细情况。注:筛选区间行索引为(0:5),列索引为(‘姓名’:‘实发年终奖金’)。
import pandas as pd
def proc():
# 读取Excel表格
df = pd.read_excel('https://keyun-oss.acctedu.com/app/bigdata/basics/nzjj.xlsx', sheet_name='年终奖金发放表')
# 筛选战略规划部门年终奖金明细情况
df3 = df.loc[0:5, '姓名':'实发年终奖金']
return df3
df = proc()
print(df)
这段代码使用了 Pandas 的 DataFrame 功能,通过 loc 方法在指定的行索引范围和列索引范围内筛选出战略规划部门年终奖金明细情况。
20.读取Excel中的"年终奖金发放表",新增一列"考核情况",该列的数据为:如果年终奖金超过一万则显示为“考核优秀”,否则显示为“考核合格”;再新增一列“年假奖励”,该列的数据为:如果考核情况是“考核优秀”则显示“奖励年假3天”,否则显示“奖励年假1天”。
import pandas as pd
def proc():
# 读取Excel表格
df = pd.read_excel('https://keyun-oss.acctedu.com/app/bigdata/basics/nzjj.xlsx', sheet_name='年终奖金发放表')
# 新增“考核情况”列
df['考核情况'] = df['年终奖金'].map(lambda x: '考核优秀' if x > 10000 else '考核合格')
# 新增“年假奖励”列
df['年假奖励'] = df['考核情况'].map({
'考核优秀': '奖励年假3天', '考核合格': '奖励年假1天'})
return df
df = proc()
print(df)
在这段代码中,使用了 Pandas 的 map 方法来根据条件对列进行映射,并新增了两列“考核情况”和“年假奖励”。
21.根据以上资料创建DataFrame,并新增一列计算每年净资产收益率。(注:净资产收益率=营业净利率 * 总资产周转率 * 权益乘数)
import pandas as pd
def proc():
# 创建DataFrame
data = {
'时间': ['2018', '2019', '2020'],
'营业净利率': [0.12, 0.08, 0.1],
'总资产周转率': [0.6, 0.3, 0.48],
'权益乘数': [1.8, 2, 1.9]}
df = pd.DataFrame(data)
# 计算每年净资产收益率,DataFrame.prod():累计运算
df['净资产收益率'] = df[['营业净利率', '总资产周转率', '权益乘数']].apply(lambda x: x.prod(), axis=1)
return df
df = proc()
print(df)
这段代码创建了一个包含时间、营业净利率、总资产周转率、权益乘数和净资产收益率的 DataFrame。其中,使用了 apply 方法和 lambda 函数来计算每一行的净资产收益率。
22.读取工资明细表,sheet_name=‘工资结算明细表’,将工资明细表按一级部门进行分组,并统计各组“应付工资”列的平均值、合计值、最小值、最大值.
import pandas as pd
# 读取工资明细表
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/gzmxb.xls', sheet_name='工资结算明细表')
def proc():
# 使用groupby函数进行分组,再通过agg函数聚合计算
df1 = df.groupby('一级部门').agg({
'应付工资': ['mean', 'sum', 'min', 'max']})
return df1
df = proc()
print(df)
这段代码通过 groupby 函数按照一级部门进行分组,然后使用 agg 函数对每个分组中的“应付工资”列进行平均值、合计值、最小值、最大值的统计。
23.读取年终奖金表,sheet_name=‘年终奖金发放表’,将年终奖金发放表按一级部门进行分组,并统计年终奖金的合计数,个税的合计数,实发年终奖金的最大值,最小值与合计数。
import pandas as pd
# 读取年终奖金发放表
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/nzjj.xlsx', sheet_name='年终奖金发放表')
def proc():
# 使用groupby函数分组,再使用agg函数聚合计算
df2 = df.groupby('一级部门').agg({
'年终奖金': 'sum', '个税': 'sum', '实发年终奖金': ['max', 'min', 'sum']})
return df2
df = proc()
print(df)
这段代码通过 groupby 函数按照一级部门进行分组,然后使用 agg 函数对每个分组中的“年终奖金”、“个税”、“实发年终奖金”列进行合计、最大值、最小值的统计。
24.读取表格,按照产品进行分组求和,不以组标签为索引对象。
import pandas as pd
# 读取商品进销存表
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/spjxc.xls')
def proc():
# 使用groupby函数按产品分组求和
df1 = df.groupby('产品', as_index=False).sum()
return df1
df = proc()
print(df)
这段代码会输出每个产品的各项数据的总和,并且不会将产品列作为索引。
25.根据读取商品进销存表,按照日期分组,求每天商品结存数的最大值、最小值与合计数。
import pandas as pd
# 读取商品进销存表
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/spjxc.xls')
def proc():
# 使用groupby函数按日期分组,再通过agg函数聚合计算
df2 = df.groupby('日期').agg({
'结存': ['sum', 'max', 'min']})
return df2
df = proc()
print(df)
这段代码会输出每天商品结存数的最大值、最小值和合计数。
26.读取以上数据报表,并使用Pyecharts绘制成本费用柱状图,成本费用项目依次包括:制造成本、销售费用、管理费用、财务费用(按照该顺序添加y轴数据)。图形要求如下:
1、初始化配置:图表画布宽度为800px,高度为500px,主题风格为LIGHT。
2、全局配置:标题为“费用对比图”,标题居中,离容器上侧的距离为5%;图例组件离容器右侧的距离为2%、离容器上侧的距离为3%,图例列表的布局为垂直朝向。
3、系列配置:生成的柱状图不显示数字标签。
# 引入pandas、图表类型、配置项、主题类型
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.render import NotebookRender
# 读取数据
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/yysr.xls')
# 数据转换:将DataFrame转换为Python数据类型列表
x = df['年度'].tolist()
y1 = df['制造成本'].tolist()
y2 = df['销售费用'].tolist()
y3 = df['管理费用'].tolist()
y4 = df['财务费用'].tolist()
# 初始化配置
bar1 = Bar(init_opts=opts.InitOpts(width='800px', height='500px', theme=ThemeType.LIGHT))
bar1.add_xaxis(x)
bar1.add_yaxis('制造成本', y1)
bar1.add_yaxis('销售费用', y2)
bar1.add_yaxis('管理费用', y3)
bar1.add_yaxis('财务费用', y4)
# 设置全局配置项
bar1.set_global_opts(
title_opts=opts.TitleOpts(title='费用对比图', pos_left='center', pos_top='5%'),
legend_opts=opts.LegendOpts(pos_right='2%', pos_top='3%', orient='vertical')
)
# 设置系列配置项
bar1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
# 渲染图表
render = NotebookRender()
render.render_chart_to_notebook(bar1)
27.计算全部成本、净利润。
全部成本=制造成本+销售费用+管理费用+财务费用
净利润=营业收入-全部成本+其他利润-所得税费用
使用Pyecharts绘制营业收入、净利润的折线图(添加y轴数据的顺序为营业收入、净利润),图形要求如下:
1、初始化配置:图表画布宽度为800px,高度为500px,主题风格为ESSOS。
2、全局配置:标题为“收入利润对比图”,标题组件居中显示;图例组件离容器顶部的距离为5%;设置显示工具箱。
3、系列配置:生成的折线图不显示数字标签,区域填充样式透明度为0.5。
# 引入pandas、图表类型、配置项、主题类型
import pandas as pd
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.render import NotebookRender
# 读取数据
df = pd.read_excel(r'https://keyun-oss.acctedu.com/app/bigdata/basics/yysr.xls', converters={
'年度': str})
# 计算
df['全部成本'] = df['制造成本'] + df['销售费用'] + df['管理费用'] + df['财务费用']
df['净利润'] = df['营业收入'] - df['全部成本'] + df['其他利润'] - df['所得税费用']
def proc():
# 数据转换:将DataFrame转换为Python数据类型列表
x = df['年度'].tolist()
y1 = df['营业收入'].tolist()
y2 = df['净利润'].tolist()
# 初始化配置
line1 = Line(init_opts=opts.InitOpts(width='800px', height='500px', theme=ThemeType.ESSOS))
line1.add_xaxis(x)
line1.add_yaxis('营业收入', y1)
line1.add_yaxis('净利润', y2)
# 设置全局配置项
line1.set_global_opts(
title_opts=opts.TitleOpts(title='收入与利润对比图', pos_left="center"),
legend_opts=opts.LegendOpts(pos_top='5%'),
toolbox_opts=opts.ToolboxOpts(is_show=True)
)
# 设置系列配置项
line1.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5)
)
return line1
# 创建 NotebookRender 的实例
render = NotebookRender()
# 渲染图表
render.render_chart_to_notebook(proc())
28.通过Pyecharts绘制饼图展示A子公司的负债及所有者权益结构,饼图的内半径为90,外半径为150;饼图的中心(圆心)坐标参数为:center=[“50%”,“50%”]。
from pyecharts.charts import Pie
def proc():
# pie 需要的数据格式
x_data = ['流动负债', '非流动负债', '所有者权益']
y_data = [30000, 30000, 40000]
# data 格式为 [(key1, value1), (key2, value2)]
data = list(zip(x_data, y_data))
# 绘制饼图
pie = Pie()
pie.add("", data, center=["50%", "50%"], radius=["90%", "150%"])
return pie
pie = proc()
# 展示图形
pie.render_notebook()