文章目录
Redis面试题
Redis 的基本数据结构有哪些,Redis 支持的数据结构和用途是什么?
Redis 支持的主要数据结构:
1、字符串 (String):
存储二进制安全的文本数据,如 JSON、XML、HTML。
常用命令:SET、GET、INCR、DECR。
2、哈希 (Hash):
存储对象,类似于关联数组。
用于存储、获取和删除字段。
常用命令:HSET、HGET、HMSET、HGETALL。
内部使用类似于开放地址法的哈希表来存储字段和值。
3、列表 (List):
存储有序的字符串元素。
支持从两端插入和删除元素。
常用命令:LPUSH、RPUSH、LPOP、RPOP。
Redis 使用双向链表实现列表,支持从两端插入和删除元素。
4、集合 (Set):
存储唯一的字符串元素。
支持集合运算,如并集、交集、差集。
常用命令:SADD、SREM、SMEMBERS、SINTER。
有序集合 (Sorted Set 或 Zset):
与集合类似,每个元素都关联一个分数。
用于实现排行榜、范围查询等。
常用命令:ZADD、ZREM、ZRANGE、ZSCORE。
Redis 使用简单的字节数组来表示位图,支持位运算。
5、位图 (Bitmap):
以位的形式存储的字符串。
支持位运算,适用于处理用户在线状态、统计等。
常用命令:SETBIT、GETBIT、BITCOUNT。
6、HyperLogLog:
用于估计基数(集合中不重复元素的数量)。
常用命令:PFADD、PFCOUNT、PFMERGE。
使用 HyperLogLog 算法估计基数,基于概率性算法。
地理空间索引 (Geospatial Index):
7、存储地理位置信息。
用于地理位置查询和计算两点之间的距离。
常用命令:GEOADD、GEODIST、GEORADIUS。
这些数据结构使 Redis 成为一款强大的内存数据库,适用于各种不同的应用场景,包括缓存、消息队列、计数器、实时排行榜等。
Redis 的数据淘汰策略有哪些?
这些淘汰策略可以通过 Redis 配置文件中的 maxmemory-policy 参数来配置。
No Eviction (noeviction): 当内存不足以执行新的写操作时,新写入的命令会报错。
All Keys Random (allkeys-random): 在所有键中随机选择要删除的键。
Volatitle Random (volatile-random): 在设置了过期时间的键中,随机选择要删除的键。
All Keys LRU (allkeys-lru): 在所有键中,选择最近最少使用的键进行删除。
Volatile LRU (volatile-lru): 在设置了过期时间的键中,选择最近最少使用的键进行删除。
All Keys LFU (allkeys-lfu): 在所有键中,选择最不经常使用的键进行删除。
Volatile LFU (volatile-lfu): 在设置了过期时间的键中,选择最不经常使用的键进行删除。
什么是 Redis 的持久化?有哪些方式?
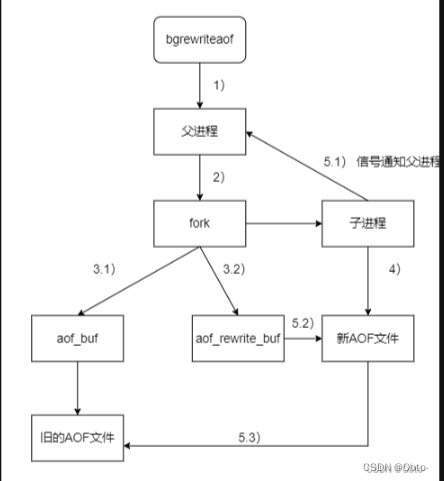
RDB(Redis DataBase): RDB 是一种快照的持久化方式。通过定期将内存中的数据快照保存到磁盘上的二进制文件中。这种方式适合用于数据备份和全量恢复,但会在保存快照的过程中阻塞 Redis。
优点: RDB 持久化方式适用于数据量大、可以容忍一定数据丢失的场景,因为是全量快照,可以节省磁盘空间。
缺点: RDB 在执行快照时,会导致 Redis 在一段时间内无法提供写服务。
配置方式:
save 900 1 # 在900秒(15分钟)内,如果有至少1个key发生变化,则进行快照
save 300 10 # 在300秒(5分钟)内,如果有至少10个key发生变化,则进行快照
save 60 10000 # 在60秒内,如果有至少10000个key发生变化,则进行快照
AOF(Append Only File): AOF 持久化方式记录每次写操作的命令,以追加的方式保存到磁盘上的文件。通过重放这些写命令,可以恢复数据。AOF 持久化方式更适用于需要高可用性和数据安全的场景。
优点: AOF 持久化方式对数据的丢失更为敏感,因为可以配置每秒同步一次数据到磁盘,保证数据的一致性。
缺点: AOF 文件相对于 RDB 文件通常会更大,因为它记录了每次写操作的详细命令。
配置方式:
appendonly yes # 开启AOF持久化
appendfilename "appendonly.aof" # AOF文件的名称
appendfsync everysec # 每秒钟同步一次数据到磁盘,可以设置为 always 或 no
在实际应用中,可以同时启用 RDB 和 AOF 持久化方式,以提高数据的安全性和灵活性。这种情况下,Redis 在启动时会先加载 AOF 文件,然后再根据需要恢复 RDB 文件中的数据。
Redis 的数据过期策略是怎样的?
Redis 中的数据过期策略主要通过设置过期时间(TTL,Time To Live)来实现。每个键可以关联一个过期时间,一旦过期时间到达,该键就会被自动删除。
以下是 Redis 中常用的数据过期策略:
定时删除: Redis 使用定时任务来检查键是否过期。在每个键的过期时间到达时,Redis 将自动删除该键。
惰性删除: 在获取键的时候,Redis 会检查该键是否过期,如果过期则删除。这种方式确保只有在需要时才会执行删除操作。
定期删除: Redis 会随机抽取一些已过期的键,然后删除它们。通过定期执行这个过期键的删除操作,可以分担惰性删除的负担。
在使用 Redis 时,可以通过以下命令设置键的过期时间:
EXPIRE key seconds:设置键的过期时间,单位为秒。
PEXPIRE key milliseconds:设置键的过期时间,单位为毫秒。
TTL key:获取键的剩余过期时间,单位为秒。
PTTL key:获取键的剩余过期时间,单位为毫秒。
PERSIST key:移除键的过期时间,使其永久有效。
例如,可以使用以下命令设置键 “mykey” 的过期时间为 60 秒:
EXPIRE mykey 60
或者设置键 “mykey” 的过期时间为 100 毫秒:
PEXPIRE mykey 100
在编程中,可以通过 Redis 客户端提供的 API 来设置和查询键的过期时间。
Redis 的主从复制是什么?怎样配置主从复制?
Redis 主从复制(Replication)是一种数据同步机制,用于在不同的 Redis 服务器之间保持数据一致性。在主从复制中,一个 Redis 服务器充当主服务器(master),而其他 Redis 服务器则充当从服务器(slave)。主服务器负责处理写操作,而从服务器负责复制主服务器上的数据,以确保从服务器上的数据与主服务器上的数据保持一致。
配置主从复制的步骤如下:
打开主服务器: 在主服务器上,打开 Redis 配置文件(通常是 redis.conf),找到并修改以下配置项:
1、 打开主服务器
bind 127.0.0.1
默认情况下,Redis 主服务器是打开的,因此通常无需修改。
2、配置主服务器认证(可选): 如果主服务器启用了认证,需要在配置文件中添加认证信息:
requirepass your_master_password
3、配置从服务器: 在从服务器上,打开 Redis 配置文件,找到并修改以下配置项:
replicaof 127.0.0.1 6379
将 IP 地址和端口号设置为主服务器的地址和端口号。
4、配置从服务器认证(可选): 如果主服务器启用了认证,需要在从服务器配置文件中添加认证信息:
masterauth your_master_password
5、重启服务器: 保存修改后的配置文件,并重启主服务器和从服务器。
6、检查主从连接: 在 Redis 命令行或客户端中,可以使用以下命令检查主从连接:
INFO replication
如果配置正确,输出中应该包含 “role:master” 和 “role:slave”。
主从复制的配置可以在运行时进行,也可以在配置文件中进行。上述步骤仅提供了基本的配置示例,实际情况中还可以根据需要调整其他配置项。主从复制提供了高可用性和负载均衡的解决方案,同时提高了系统的可扩展性。
Redis 事务是什么?它的 ACID 属性如何?
Redis 事务是一组命令的集合,可以通过 MULTI 和 EXEC 指令来包裹。在 MULTI 开始和 EXEC 结束之间的所有命令都会被作为一个事务进行执行。Redis 事务提供了一种保证一系列命令原子执行的机制,要么全部执行,要么全部不执行。
事务的 ACID 特性如下:
原子性(Atomicity): Redis 事务是原子性的,所有事务中的命令要么全部执行成功,要么全部失败。如果事务中的任何命令在执行期间发生错误,事务将会被回滚,之前的命令对数据的更改都不会生效。
一致性(Consistency): Redis 事务的一致性是通过在 MULTI 和 EXEC 之间的执行过程中,其他客户端不能对被操作的数据进行读或写来保证的。在事务执行期间,Redis 不会中断其他客户端的操作,以确保一致性。
隔离性(Isolation): Redis 事务提供了隔离性,确保一个事务的执行不会受到其他事务的影响。即使在执行事务的过程中,其他客户端也不能读到未提交的事务的更改。
持久性(Durability): Redis 事务的持久性取决于 Redis 的持久化配置。如果 Redis 启用了持久化,那么在 EXEC 执行之后,事务所做的更改将会被写入到持久化文件中,从而保证了数据的持久性。
使用示例:
MULTI
SET key1 "Hello"
GET key1
INCR counter
EXEC
上述示例中,MULTI 开始了一个事务,接着执行了三个命令(SET、GET、INCR),最后通过 EXEC 执行事务。如果执行期间没有错误,那么事务中的所有更改都将生效,否则将回滚。
Redis 的发布订阅(Pub/Sub)是什么?
Redis 的发布订阅(Pub/Sub)是一种消息传递模式,用于实现消息的发布者和订阅者之间的通信。在这个模式中,有一个消息的发布者(publisher)向一个或多个订阅者(subscriber)发送消息,订阅者对感兴趣的消息进行订阅,从而在消息发布者发送相应消息时得到通知。
基本的 Pub/Sub 架构包含以下几个组成部分:
发布者(Publisher): 发布者负责发布消息,也就是将消息发送到指定的频道(channel)。
订阅者(Subscriber): 订阅者可以订阅一个或多个频道,接收发布者发送到这些频道的消息。
频道(Channel): 频道是消息的通道,消息发布者将消息发送到一个或多个频道,而订阅者则订阅其中一个或多个频道,以接收发布者发送到这些频道的消息。
下面是 Redis Pub/Sub 的基本操作:
PUBLISH: 发布者通过 PUBLISH 命令将消息发送到指定的频道。
PUBLISH channel message
SUBSCRIBE: 订阅者通过 SUBSCRIBE 命令订阅一个或多个频道。
SUBSCRIBE channel
订阅多个频道:
SUBSCRIBE channel1 channel2 …
UNSUBSCRIBE: 订阅者通过 UNSUBSCRIBE 命令取消对一个或多个频道的订阅。
UNSUBSCRIBE channel
取消订阅多个频道:
UNSUBSCRIBE channel1 channel2 …
PSUBSCRIBE: 订阅者通过 PSUBSCRIBE 命令使用通配符订阅一个或多个模式。
PSUBSCRIBE pattern
PUNSUBSCRIBE: 订阅者通过 PUNSUBSCRIBE 命令取消对一个或多个模式的订阅。
PUNSUBSCRIBE pattern
使用通配符取消订阅多个模式:
PUNSUBSCRIBE pattern1 pattern2 …
Redis 的发布订阅模式使得消息的发布者和订阅者能够实现解耦,提高了系统的可扩展性和灵活性。
Redis 使用场景有哪些?
缓存: Redis 常被用作缓存系统,存储热点数据,加速读取速度,减轻后端数据库负担。
会话缓存: 将用户会话数据存储在 Redis 中,提高访问速度,同时支持分布式环境下的会话管理。
消息队列: Redis 的发布订阅模式和列表结构常被用作消息队列,实现异步通信,解耦系统组件。
实时统计: 通过 Redis 的计数器和有序集合等数据结构,可以方便地进行实时统计和排名。
分布式锁: 利用 Redis 的 SETNX(set if not exists)指令,可以实现简单的分布式锁机制。
地理位置服务: Redis 的地理位置数据类型(Geo)支持存储和查询地理位置信息,用于构建地理位置服务。
在线应用排名: 利用有序集合存储用户的得分信息,实现在线应用的排名功能。
任务队列: 使用列表数据结构,实现任务队列,将需要异步执行的任务放入队列中。
配置管理: Redis 的数据持久化特性和快速读取速度,使其适用于配置信息的存储和管理。
分布式缓存: 在分布式系统中,通过多节点部署 Redis,实现分布式缓存,提高系统的扩展性和性能。
实时聊天: 利用 Redis 的发布订阅机制,实现实时聊天系统。
限流器和计数器: 利用 Redis 的计数器和有序集合,可以实现限流和计数器等功能。
为什么 Redis 是单线程的?
Redis 之所以采用单线程模型,主要是为了简化设计、提高性能和确保一致性。以下是一些关键的原因:
避免竞争条件: 单线程模型避免了多线程之间的竞争条件,简化了并发控制。在单线程模型下,不需要考虑锁的问题,避免了复杂的线程同步和锁竞争。
原子操作: Redis 提供了许多原子性的操作,单线程可以确保这些操作的原子性,而不需要担心多线程下的并发问题。例如,使用 Redis 的事务和 Lua 脚本,可以实现一系列操作的原子执行。
避免上下文切换: 单线程避免了多线程之间的上下文切换开销。在多线程环境中,线程切换可能会引入额外的开销,而单线程模型下不存在这个问题。
内存和 CPU 缓存友好: 单线程模型更容易利用 CPU 缓存,因为线程切换会导致 CPU 缓存的失效,而 Redis 单线程避免了这种情况,有利于提高 CPU 缓存的命中率。
IO 密集型操作: Redis 主要是 IO 密集型操作,例如读取和写入数据到内存。在这种情况下,单线程的性能往往足够,并不会成为瓶颈。
简化设计和维护: 单线程模型使得 Redis 的设计更为简单,易于维护和理解。这也符合 Redis 的初衷,即提供一个快速、简单、可靠的内存数据库。
需要注意的是,虽然 Redis 的主要线程是单线程的,但 Redis 还使用了一些多线程的技术来处理后台任务,例如持久化和复制。这使得 Redis 能够在保持简单性和性能的同时,处理一些耗时的操作。
什么是 Redis 分布式锁?如何实现分布式锁?
Redis 分布式锁是一种用于在分布式系统中实现互斥访问的机制。它可以确保在多个节点上的不同进程或线程之间,同一时刻只有一个能够持有锁并执行关键代码,从而避免资源竞争和数据一致性问题。
实现分布式锁的一般步骤如下:
获取锁: 当一个节点(进程或线程)需要执行关键代码时,它尝试在 Redis 中获取一个分布式锁。
释放锁: 在关键代码执行完成后,节点释放锁,使其他节点能够获取并执行关键代码。
在 Redis 中,实现分布式锁的方式主要有两种:基于 SETNX 命令和基于 Redlock 算法。
基于 SETNX 命令的实现
public class RedisDistributedLock {
private Jedis jedis;
private String lockKey;
public RedisDistributedLock(Jedis jedis, String lockKey) {
this.jedis = jedis;
this.lockKey = lockKey;
}
public boolean tryLock() {
Long result = jedis.setnx(lockKey, "locked");
return result == 1;
}
public void unlock() {
jedis.del(lockKey);
}
}
在上述实现中,tryLock 方法尝试通过 SETNX 命令在 Redis 中设置一个键值对,如果设置成功(返回值为1),则表示获取到锁。unlock 方法通过 DEL 命令删除锁。
基于 Redlock 算法的实现
Redlock 算法是一个由 Redis 官方提出的分布式锁算法,它使用多个独立的 Redis 节点来实现更为可靠的分布式锁。实现 Redlock 算法需要多个 Redis 节点的支持,通常是一个 Redis 集群。
使用 Java 客户端实现 Redlock 算法,例如使用 Redisson:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://127.0.0.1:7001", "redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);
RRedLock redLock = redisson.getRedLock("lockKey1", "lockKey2", "lockKey3");
redLock.lock();
try {
// 执行关键代码
} finally {
redLock.unlock();
}
在上述实现中,通过 Redisson 创建了一个支持 Redlock 算法的锁对象 RRedLock,然后使用 lock 和 unlock 方法实现锁的获取和释放。
选择哪种方式实现分布式锁取决于具体的场景和需求。基于 SETNX 的简单实现适用于单机或简单的分布式环境,而 Redlock 算法更适用于复杂的分布式系统。
Redis 的主从同步过程是怎样的?
Redis 的持久化机制有哪些优缺点?
Redis 的持久化机制有两种:RDB(Redis DataBase)和 AOF(Append Only File)。它们各有优缺点,适用于不同的使用场景。
RDB 持久化
优点:
性能好: RDB 持久化是通过将内存中的数据以二进制格式写入磁盘的方式,因此相对来说写入速度较快。
紧凑: RDB 文件是二进制格式,相对于 AOF 文件,文件体积较小。
缺点:
不实时: RDB 是定期持久化,不是实时的。如果在持久化之间发生宕机,可能会有数据丢失。
适用于快照: RDB 持久化适合用于备份和恢复,但不适用于对数据的实时性要求较高的场景。
AOF 持久化
优点:
实时性: AOF 持久化是实时记录每一次写命令,因此在发生宕机时,可以较好地保证数据的实时性和完整性。
可读性强: AOF 文件是以文本方式记录的,相对于 RDB 文件更容易读懂和修复。
缺点:
文件较大: 相对于 RDB 文件,AOF 文件通常较大,因为它记录了每一次写命令。
恢复速度较慢: 恢复数据时,AOF 恢复的速度较 RDB 恢复的速度慢。
选择持久化方式的因素:
数据实时性要求: 如果对数据实时性要求较高,可以选择 AOF 持久化;如果可以接受一定程度的数据丢失,可以选择 RDB 持久化。
数据恢复速度: 如果对数据恢复速度有要求,可以选择 RDB 持久化;如果可以接受较慢的恢复速度,可以选择 AOF 持久化。
文件大小: 如果对文件大小有要求,可以选择 RDB 持久化;如果可以接受较大的文件,可以选择 AOF 持久化。
可读性: 如果希望持久化文件易读懂,可以选择 AOF 持久化。
Redis 如何处理并发访问?
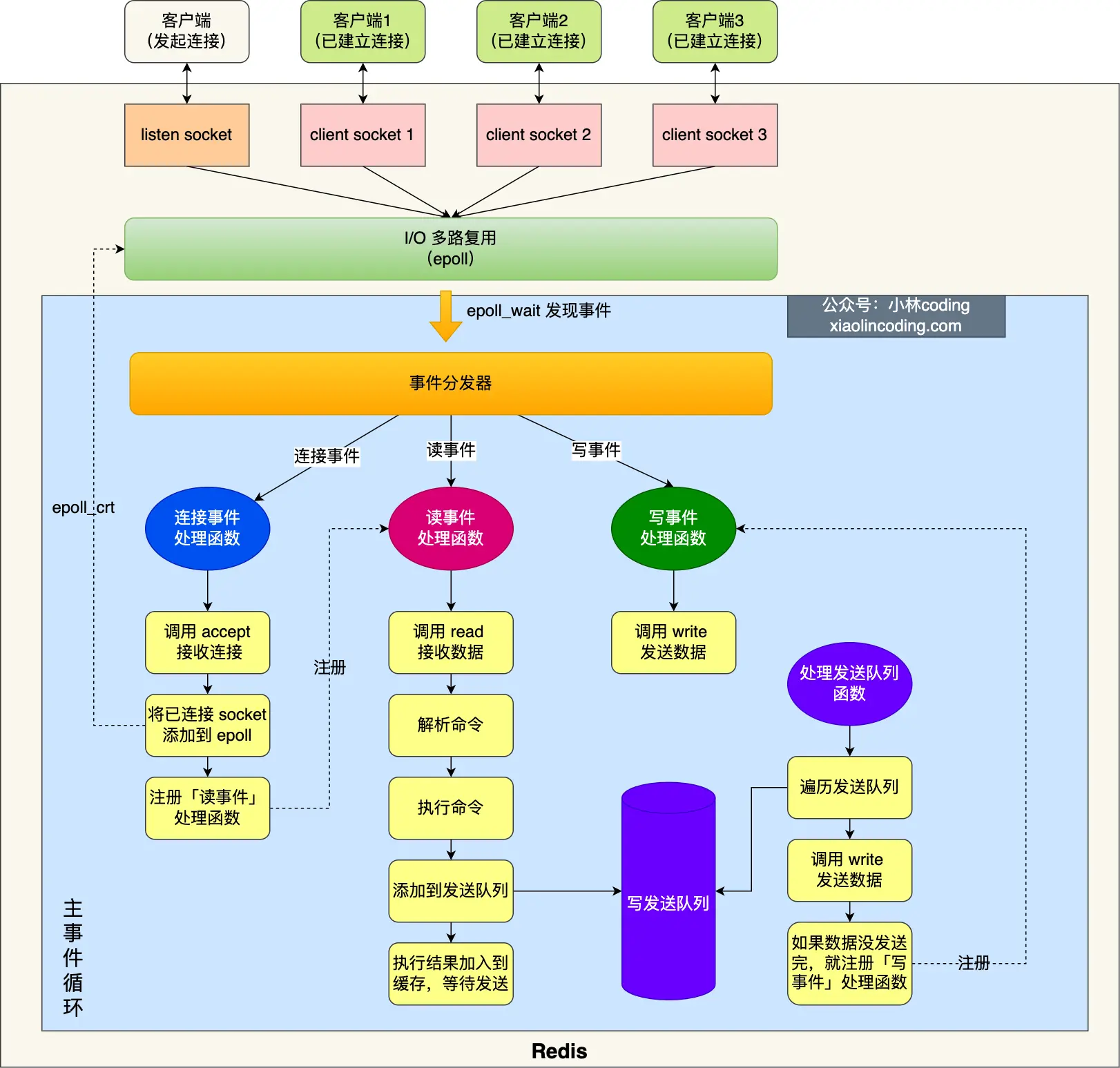
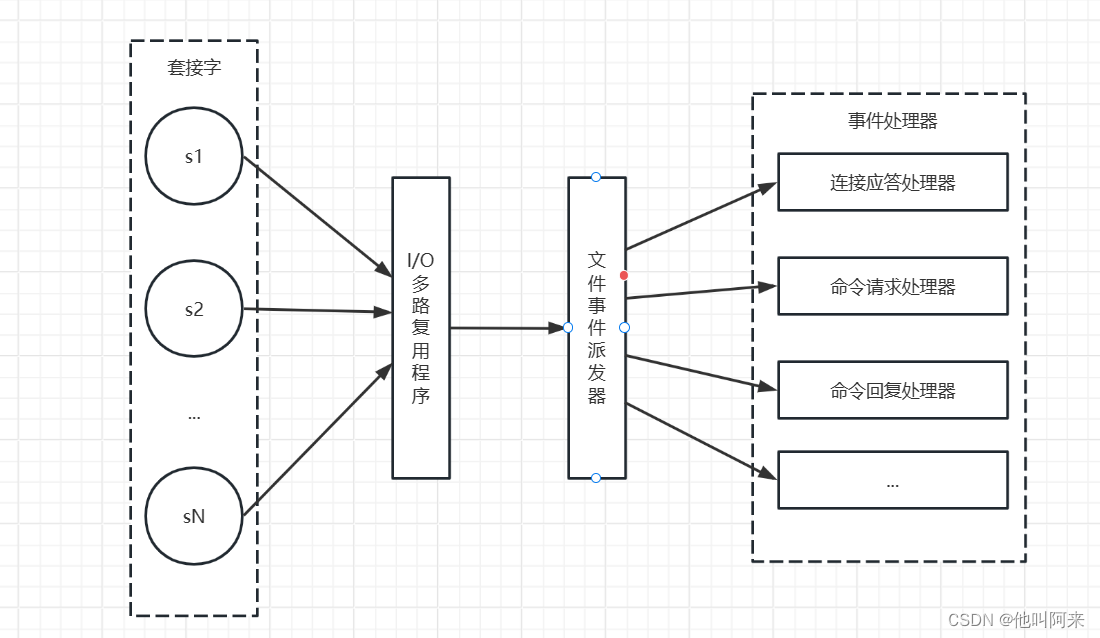
Redis 是单线程的,但是它采用了多路复用的机制,能够有效处理并发访问。下面是 Redis 处理并发访问的主要方式:
事件驱动模型: Redis 使用事件驱动模型,通过监听套接字上的事件来处理请求。它使用一个单独的 I/O 多路复用程序,通常是 epoll 或者 select,来监听多个套接字上的事件。这使得 Redis 能够在单线程上同时处理多个客户端的请求。
非阻塞 I/O: Redis 使用非阻塞 I/O 操作。在处理一个客户端请求时,如果需要等待某个操作完成(比如从磁盘加载数据),Redis 不会阻塞整个进程,而是将控制权交还给事件循环,继续处理其他事件。一旦等待的操作完成,再回来处理之前挂起的请求。
原子性操作: Redis 提供了很多原子性的操作,这意味着这些操作是不可中断的,可以在单个请求中完成。例如,通过 MULTI/EXEC 操作可以实现事务,而不必担心其他客户端的干扰。
单一操作的原子性: 即使 Redis 是单线程的,但它的每个命令在执行时都是原子性的。这就意味着,即使是复杂的命令,Redis 也会确保它在执行时是不可分割的,不会被其他命令插入。
快速的内存访问: Redis 将数据存储在内存中,并通过高效的数据结构和算法来处理数据,因此能够快速响应读取和写入请求。
总的来说,虽然 Redis 是单线程的,但它通过事件驱动、非阻塞 I/O、原子性操作以及快速的内存访问等方式,实现了在单线程下对并发访问的高效处理。这种设计使得 Redis 在许多场景下都能够达到很高的性能。Redis 怎么防止缓存雪崩和缓存击穿?
Redis 如何实现分布式?
Redis 的分布式实现主要通过以下几个机制:
分区(Sharding): Redis 将数据分为多个数据分片,每个分片可以存在于不同的服务器上。每个分片都是独立的,可以在不同的节点上运行。这样就将整个数据集分散存储在多个节点上,提高了系统的横向扩展性。
主从复制: Redis 支持主从复制机制,一个 Redis 主节点可以有多个从节点。主节点负责处理写操作,从节点复制主节点的数据,并负责读操作。这提高了系统的可用性和读性能。
哨兵(Sentinel): Redis 哨兵用于监控 Redis 实例的状态,当主节点宕机时,哨兵可以自动将一个从节点升级为主节点,保证系统的高可用性。哨兵还可以监控节点的健康状况,以及在需要时自动进行故障转移。
集群模式: Redis 集群模式通过将数据划分为多个槽(slot),每个槽可以分配给不同的节点。集群模式使用分区的方式,将数据分散存储在多个节点上,提高了系统的可伸缩性和容错性。
数据复制和同步: 在分布式环境中,Redis 主节点可以将数据同步到从节点,实现数据的备份和容灾。从节点可以接收来自主节点的写操作,也可以用于读操作,提高了系统的可用性和性能。
客户端分片: 客户端可以直接对多个 Redis 节点进行分片读写操作。客户端根据数据的键值对选择合适的节点进行读写,这种方式称为客户端分片,它需要客户端自己来处理数据的分发和聚合。
这些机制结合起来,使得 Redis 能够在分布式环境中高效地存储和处理数据。分区、主从复制、哨兵、集群模式等特性使得 Redis 具备了良好的横向扩展性、高可用性和容错性
Redis 集群有哪些优势和不足?
Redis 集群有一些优势和不足,下面分别列举:
优势:
高可用性: Redis 集群提供了数据分片和多节点复制,使得系统在部分节点宕机时仍然能够提供服务,提高了系统的可用性。
横向扩展: Redis 集群通过分片的方式,可以水平扩展,将数据分散存储在多个节点上,从而提高了系统的性能和容量。
自动故障转移: 集群中的 Sentinel 负责监控节点的健康状况,当主节点宕机时,可以自动将一个从节点升级为主节点,实现了自动的故障转移。
动态添加节点: 可以在运行时动态地添加或移除节点,而不需要停机,这使得集群的维护更加灵活。
不足:
配置复杂: Redis 集群的配置和维护相对复杂,需要考虑节点分片、复制、哨兵等多个方面,对于初学者而言有一定的学习曲线。
单个命令跨分片操作困难: 由于 Redis 集群是基于分片的,当需要执行的操作涉及到多个分片时,就需要客户端自己进行数据的拆分和聚合,这对于一些复杂的操作可能会增加实现的难度。
CAP 理论: Redis 集群在设计上追求高可用性和分区容忍性,但在一些极端情况下可能会导致一些节点之间的数据不一致,不满足强一致性。
网络开销: 节点之间的通信会带来一定的网络开销,尤其是在进行数据同步和复制时,可能会影响性能。
总体来说,Redis 集群在高可用性和横向扩展性方面有很多优势,但也需要在配置和维护上付出一些代价。选择是否使用 Redis 集群要根据具体的应用场景和需求来进行权衡。





















![[C#]使用ONNXRuntime部署一种用于边缘检测的轻量级密集卷积神经网络LDC](https://img-blog.csdnimg.cn/direct/23727b17a40148a7805f525757c22b7e.jpeg)