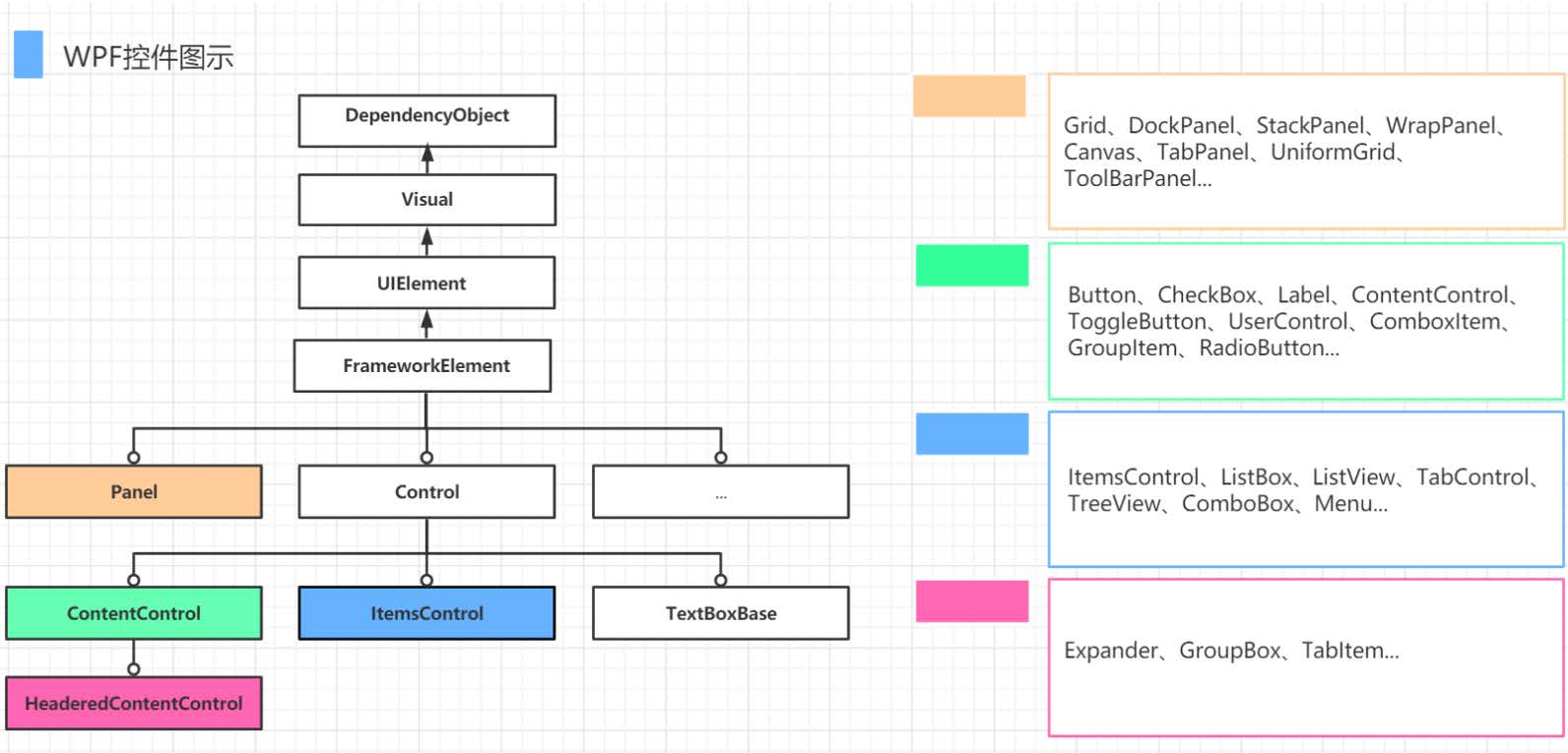
目录

前言
Python爬虫的反扒技术有很多,包括请求头伪装、IP代理、验证码识别、限制访问频率等。在面对反爬虫措施时,我们可以采取一些应对策略,这篇文章将详细介绍这些技术及应对方法。
一、请求头伪装
在爬取网页数据时,我们可以通过修改请求头信息来伪装成浏览器发送的请求。以下是一段示例代码:
import requests
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
在上述代码中,我们通过修改User-Agent字段来伪装成Chrome浏览器发送的请求。当网站检测到爬虫时,往往会通过User-Agent字段判断请求的来源,因此我们修改User-Agent字段能够有效地绕过反爬虫措施。
二、IP代理
当我们使用爬虫程序访问同一个网站的频率过高时,往往会被网站封禁IP地址。为了避免被封禁,我们可以使用IP代理来隐藏真实的IP地址。以下是一段示例代码:
import requests
url = 'https://www.baidu.com'
proxies = {
'http': 'http://127.0.0.1:8888',
'https': 'https://127.0.0.1:8888'
}
response = requests.get(url, proxies=proxies)在上述代码中,我们通过设置proxies参数来使用IP代理进行请求。这样,我们每次请求时都会使用不同的IP地址,从而避免被网站封禁。
三、验证码识别
有些网站为了防止爬虫程序访问,会在关键位置设置验证码。为了自动化地绕过验证码,我们可以使用验证码识别技术。以下是一段示例代码:
import requests
from PIL import Image
from pytesseract import image_to_string
url = 'https://www.baidu.com/captcha'
response = requests.get(url)
with open('captcha.jpg', 'wb') as f:
f.write(response.content)
image = Image.open('captcha.jpg')
captcha = image_to_string(image)在上述代码中,我们首先下载验证码图片,然后使用PIL库读取图片,并使用pytesseract库对图片进行识别,最终得到验证码。
四、限制访问频率
有些网站会对频繁访问进行限制,比如设置访问速率限制或访问次数限制。为了避免被限制,我们可以采用以下策略:
1.设置访问延时
在每次请求之间添加适当的延时,模拟人类用户的操作。可以使用`time.sleep()`函数来实现延时。
import requests
import time
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
time.sleep(3) # 延时3秒2.使用多线程或分布式爬虫
将爬虫程序分散到多台机器上或使用多个线程并发执行,从而分散访问压力。
以上是一些常见的反扒技术及应对方法,然而,并不是所有网站都会使用这些技术,因此在实际应用中需要根据具体情况进行选择。此外,需要注意的是,我们在爬取网站数据时要遵守法律法规和网站的相关规定,不要对网站造成不必要的影响。
总结
Python爬虫的反扒技术包括请求头伪装、IP代理、验证码识别和限制访问频率等。这些技术能够帮助我们绕过网站的反爬虫措施,从而顺利地获取所需数据。然而,在实际应用中,我们需要根据具体情况选择合适的技术,并遵守相关法律法规和网站规定。






















](https://img-blog.csdnimg.cn/direct/3d14f35460f34b4c874ea3f9d28bd727.png)