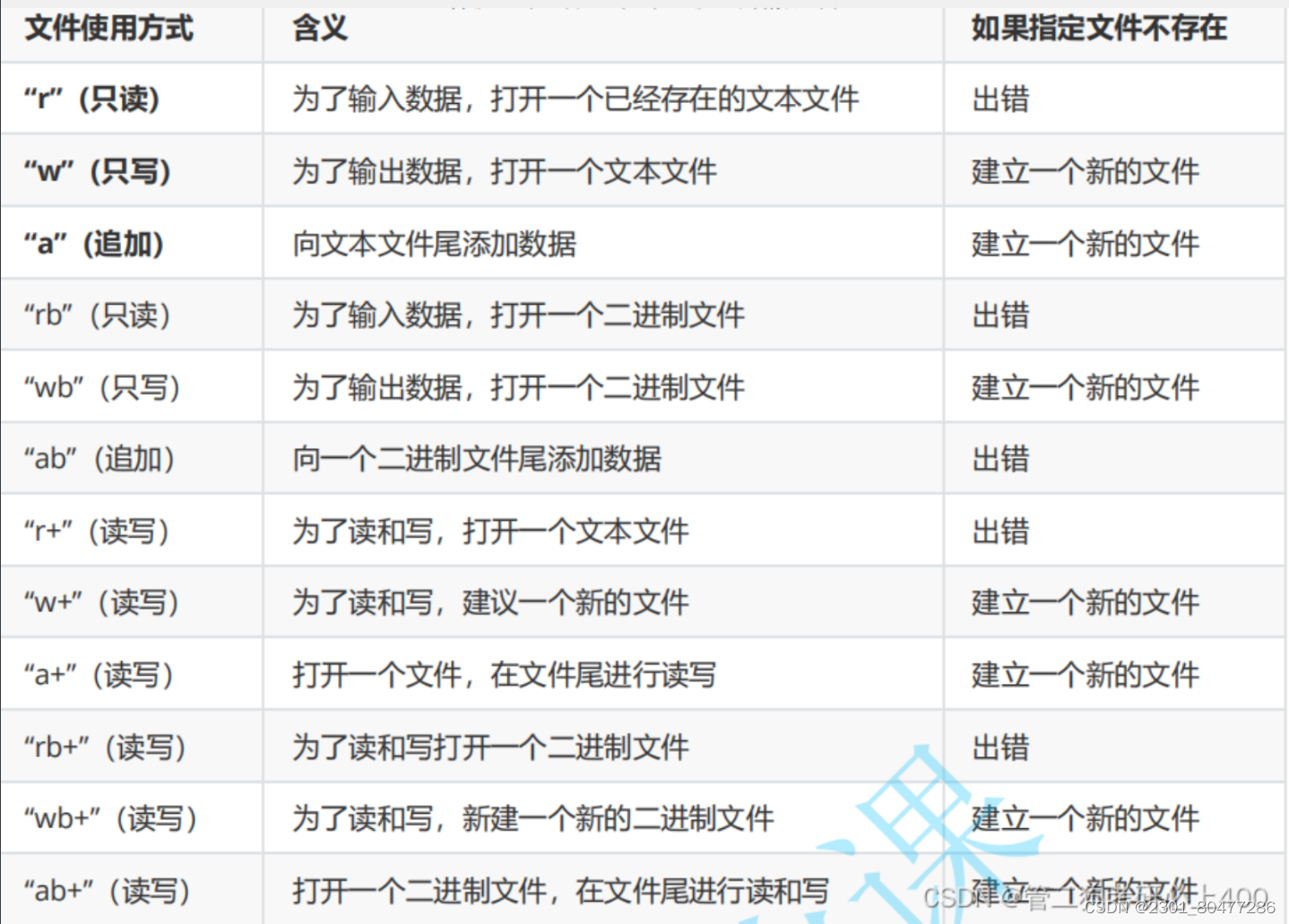
Python爬虫实战演练主要包括以下几个步骤:
1. 分析目标网站:查看目标网站的URL结构,确定需要爬取的数据在哪个页面,以及数据所在的HTML标签。
2. 导入所需库:使用requests库来发送HTTP请求,获取网页内容;使用BeautifulSoup库来解析网页内容,提取所需数据。
3. 编写代码:根据分析结果,编写Python代码来实现爬虫功能。
以下是一个简单的Python爬虫实战演练示例,以爬取豆瓣电影Top250电影名称为例:
```python
import requests
from bs4 import BeautifulSoup
# 目标网站URL
url = "https://movie.douban.com/top250"
# 发送HTTP请求,获取网页内容
response = requests.get(url)
content = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(content, "html.parser")
# 提取电影名称
movie_names = soup.find_all("div", class_="hd")[0].find_all("span")[1:26]
for movie in movie_names:
print(movie.text)
```
运行上述代码,将会输出豆瓣电影Top250的电影名称。




















![系统学习Python——装饰器:函数装饰器-[装饰器状态保持方案:外层作用域和全局变量]](https://img-blog.csdnimg.cn/direct/4d039baa65ad441e9f2d18c246a0ee33.png)