5安装本地源制作相关工具
(1)安装 yum-utils createrepo
yum install yum-utils createrepo

图 5-1 安装 yum-utils createrepo
注意: 在所有节点都要更新源,所以操作在三台虚拟机中都执行!(此处以hdp01 为例)
(2)清理无用软件包
yum clean all

图 5-2 yum clean all
(3)安装 makecache
yum makecache

图 5-3 安装 makecache
(4)安装 repo list
yum repolist
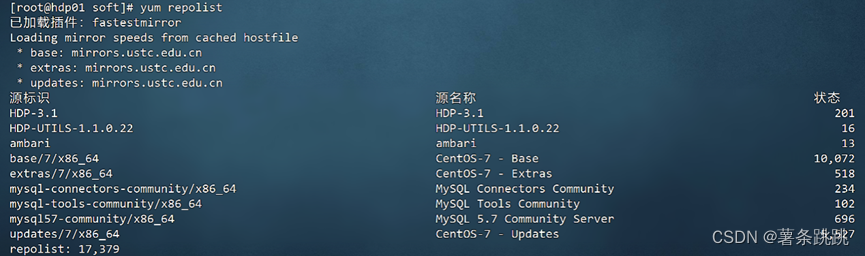
图 5-4 安装 repolist
6配置 yum 源
(1)将 Amber、HDP、HDP-UTILS 文件上传到 hdp01 ,并解压
(a)先在/var/www/html 目录下创建 ambari、hdp、hdp-utils 文件夹,并将
本地文件上传到/opt/soft,并查看是否上传成功
mkdir /var/www/html/ambari
mkdir /var/www/html/hdp
mkdir /var/www/html/hdp-utils

图 6-1 创建 ambari、hdp、hdp-utils 文件夹
cd /opt/soft
ls

图 6-2 将本地文件上传到/opt/soft,并查看是否上传成功
(b)解压文件
tar -zxvf /opt/soft/ambari-2.7.4.0-centos7.tar.gz -C /var/www
/html/ambari/
tar -zxvf /opt/soft/HDP-3.1.4.0-centos7-rpm.tar.gz -C /var/www
/html/hdp/
tar -zxvf /opt/soft/HDP-UTILS-1.1.0.22-centos7.tar.gz -C /var/www /html/hdp-utils/

图 6-3 解压 ambari-2.7.4.0-centos7.tar.gz

图 6-4 解压 HDP-3.1.4.0-centos7-rpm.tar.gz

图 6-5 解压 HDP-UTILS-1.1.0.22 -centos7.tar.gz
(2)配置 ambari 的 yum 源
vi /etc/yum.repos.d/ambari.repo
# 添加以下内容
[ambari]
name=ambari
baseurl=http://192.168.111.175/ambari/ambari/centos7/2.7.4.0-118/
gpgcheck=0

图 6-6 配置 ambari 的 yum 源
(3)配置 hdp 和 hdp-utils 的 yum 源
vi /etc/yum.repos.d/hdp.repo
# 添加以下内容
[HDP-3.1]
name=HDP-3.1
baseurl=http://192.168.111.175/hdp/HDP/centos7/3.1.4.0-315/ gpgcheck=0
[HDP-UTILS-1.1.0.22]
name=HDP-UTILS-1.1.0.22
baseurl=http://192.168.111.175/hdp-utils/HDP-UTILS/centos7
/1.1.0.22/
gpgcheck=0

图 6-7 配置 hdp 和 hdp-utils 的 yum 源
(4)验证
yum repolist
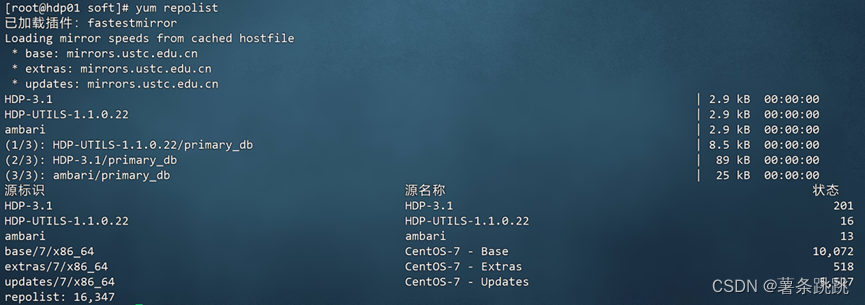
图 6-8 验证
(5)分发 yum 文件到 hdp02 和 hdp03
(a)# hdp02
scp /etc/yum.repos.d/ambari.repo hdp02:/etc/yum.repos.d/
scp /etc/yum.repos.d/hdp.repo hdp02:/etc/yum.repos.d/

图 6-9 分发 yum 文件到 hdp02
(b)# hdp03
scp /etc/yum.repos.d/ambari.repo hdp03:/etc/yum.repos.d/
scp /etc/yum.repos.d/hdp.repo hdp03:/etc/yum.repos.d/

图 6-10 分发 yum 文件到 hdp03
7安装 Ambari 集群
注意:只在第一个节点 hdp01 上执行
(1)安装 ambari-server
yum -y install ambari-server
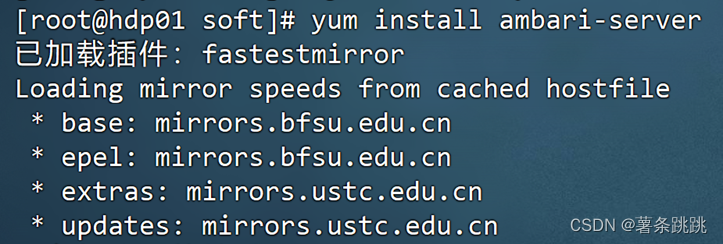
图 7-1 安装 ambari-server
8初始化与配置 Ambari
注意:只在第一个节点 hdp01 上执行
ambari-server setup
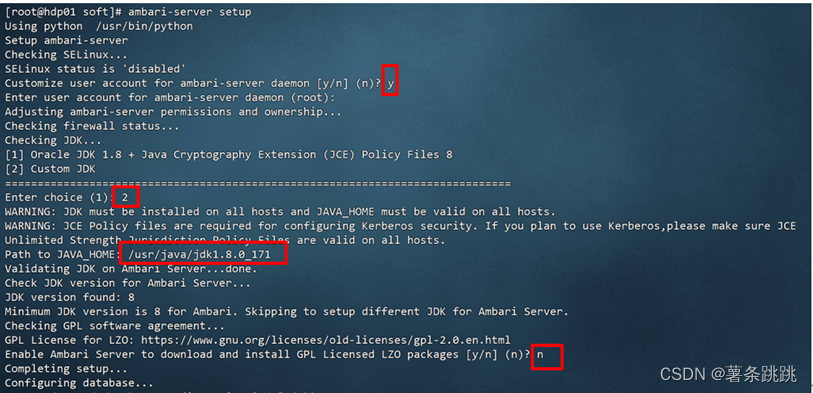
图 8-1 初始化与配置 Ambari(部分)
# JAVA_HOME:/usr/java/jdk1.8.0_171
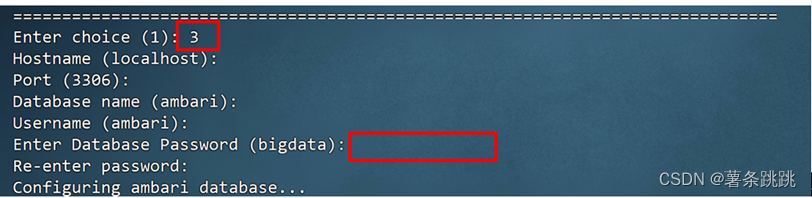
图 8-2 初始化与配置 Ambari(部分)
# 数据库密码为:Ambari-123
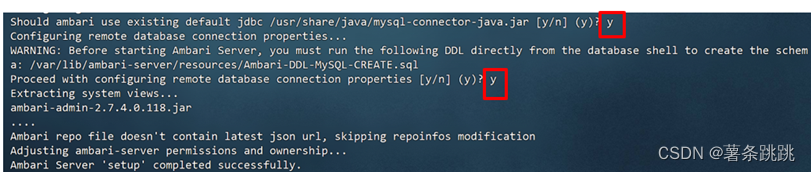
图 8-3 初始化与配置 Ambari(部分)
9初始化数据库
mysql>use ambari;
mysql>source /var/lib/ambari-server/resources/Ambari-DDL-MySQL- CREATE.sql
mysql>exit;

图 9-1 初始化数据库
10启动 Ambari
ambari-server start
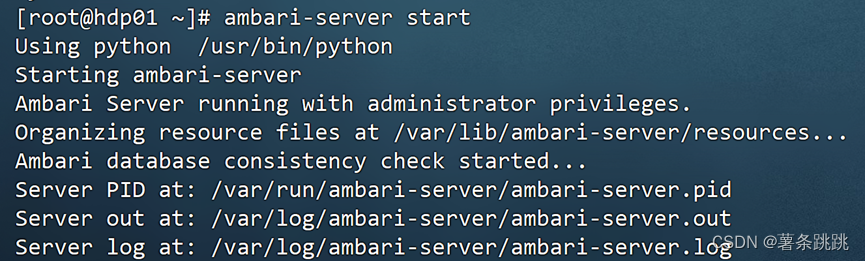
图 10-1 启动 Ambari
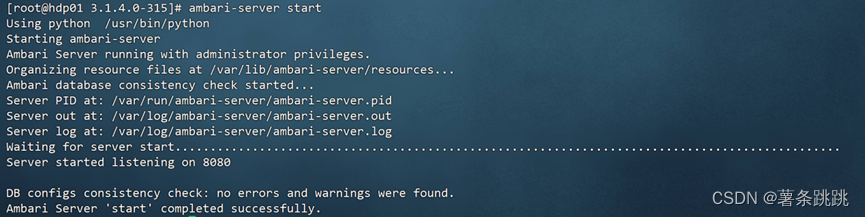
图 10-2 Ambari 启动成功
# 看到 Ambari Server‘start’completed successfully,即表示 Ambari
启动成功。
11HDP集群部署
11.1 登陆 Web 页面并登录账户
浏览器输入http://192.168.111.175:8080/

图 11-1 登陆 Web 页面并登录账户
# 默认管理员账目: admin
默认管理员密码: admin
11.2 安装 Hadoop 集群

图 11-2 安装 Hadoop 集群
# 点击 Launch Install Wizard
11.3 命名集群
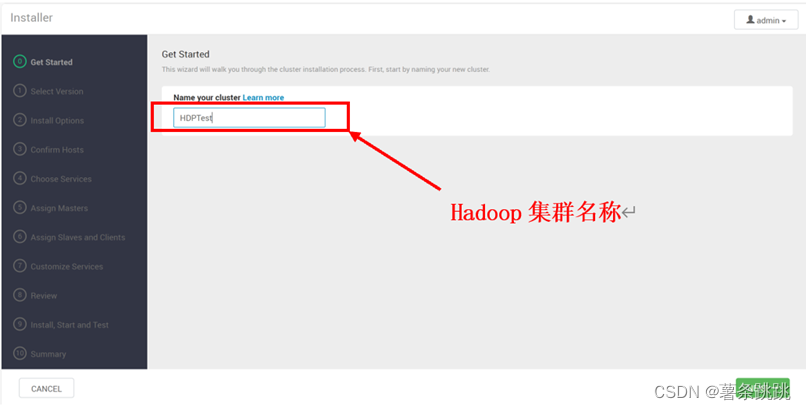
图 11-3 命名集群
# 本集群名为 HDPTest
11.4 选择用于安装 Hadoop 集群的包组和存储库

图 11-4 选择用于安装 Hadoop 集群的包组
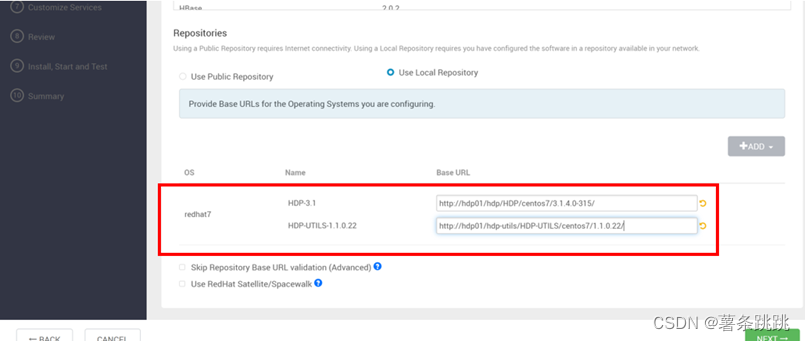
图 11-5 选择用于安装 Hadoop 集群的存储库
# 因为Redhat7是centos7 所对应的版本信息,所以选择redhat
填写刚才配置的repo文件中的地址,如下:
HDP-3.1:http://hdp01/hdp/HDP/centos7/3.1.4.0-315/
HDP-UTILS-1.1.0.2:http://hdp01/hdp-utils/HDP-UTILS/centos7 /1.1.0.22/
11.5 注册主机并确认
(1)填写主机地址
注意:三台主机的地址都需要填写,且必须使用完全合格域名
# hdp01.bigdata.com
hdp02.bigdata.com
hdp03.bigdata.com
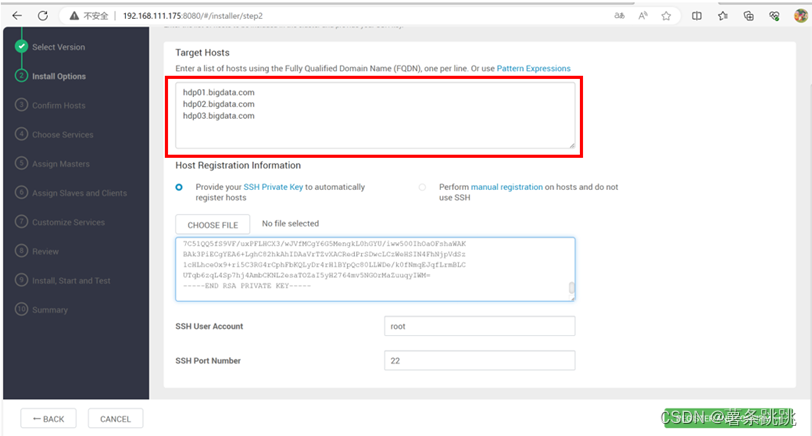
图 11-6 填写主机地址
(2)填写主节点的 id_rsa 文件
(a)查看 hdp01 的 id_rsa.pub
cat /root/.ssh/id_rsa

图 11-7 查看 hdp01 的 id_rsa.pub
(b)将查看到的 id_rsa.pub 填入
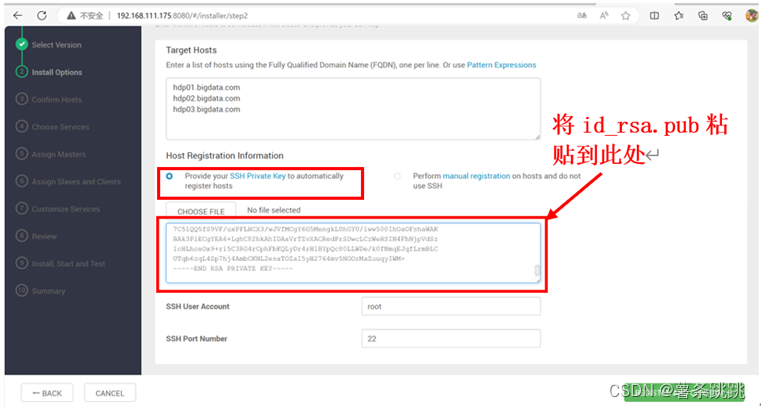
图 11-8 将查看到的 id_rsa.pub 填入
11.6 安装 Ambari-server

图 11-9 安装 Ambari-server
# 看到进度条进程全变为绿色,即表示安装注册成功
11.7 选择必要的文件系统与所需服务
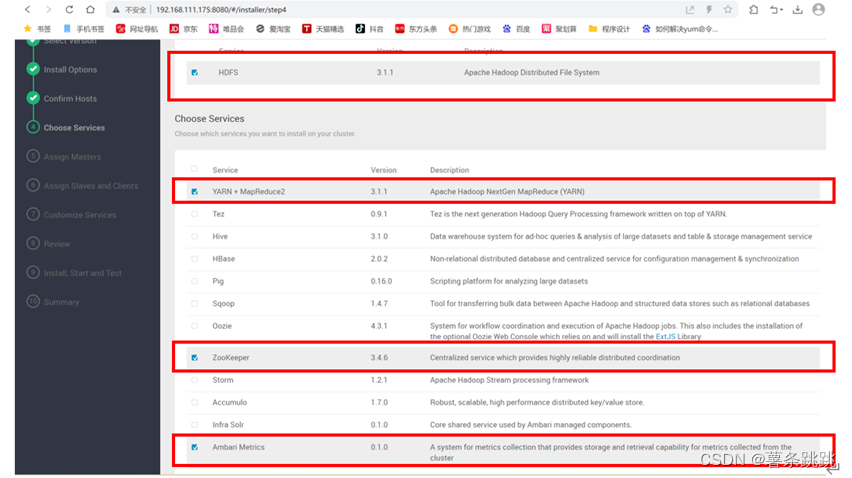
图 11-10 选择必要的文件系统与所需服务
# 选择必要的 HDFS 文件系统: HDFS
选择所需服务: YARN+MAPREDUCE,ZooKeeper,Ambari Metrics 服务
11.8 选择主机客户端
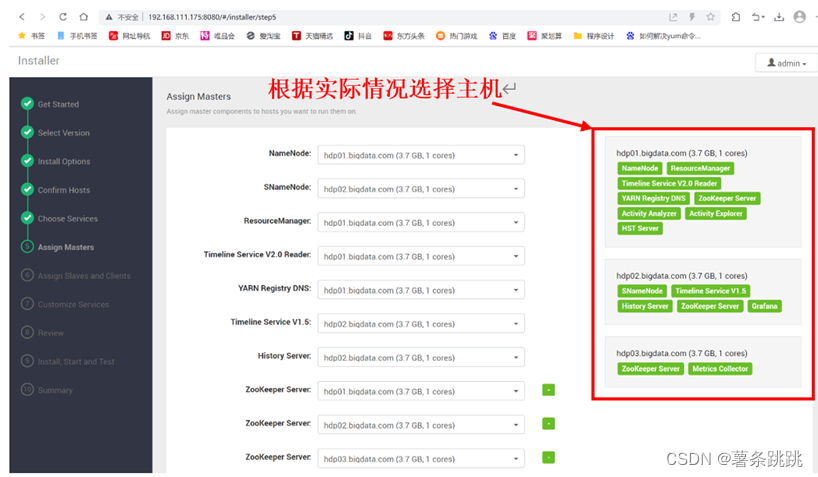
图 11-11 选择主机客户端
11.9 选择从机客户端

图 11-12 选择从机客户端
11.10 Ambari 基础参数配置
(1)填写用户名及密码
# Username:admin
Password:admin
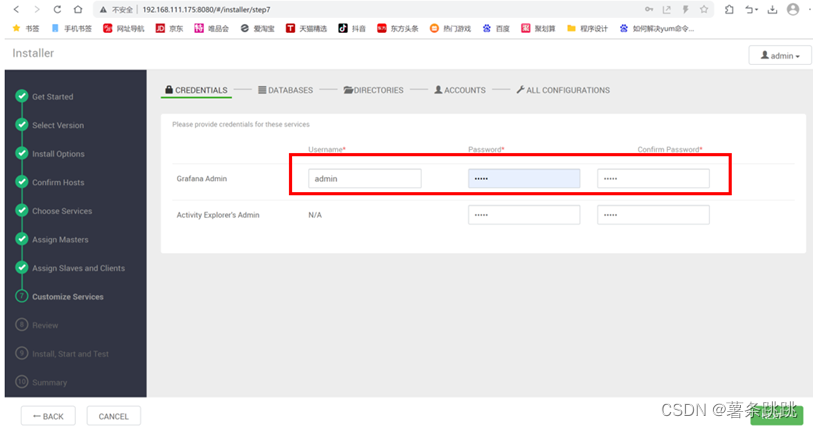
图 11-13 填写用户名及密码
(2)填写配置信息有关路径
# 通常情况下保持默认即可
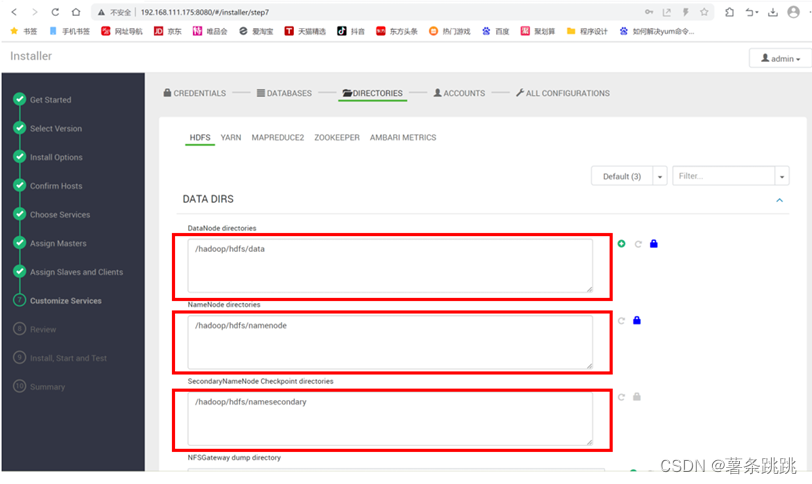
图 11-14 填写配置信息有关路径
(3)填写相关账户用户名信息
# 通常情况下保持默认即可
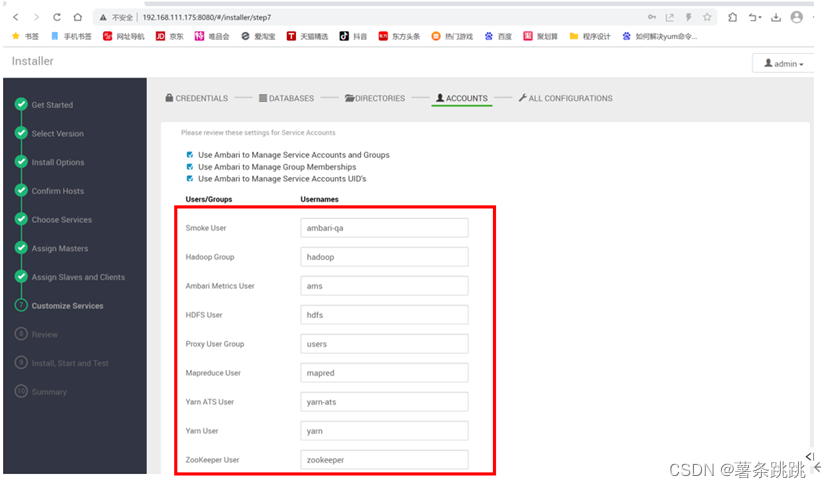
图 11-15 填写相关账户用户名信息
(4)最终确认相关信息
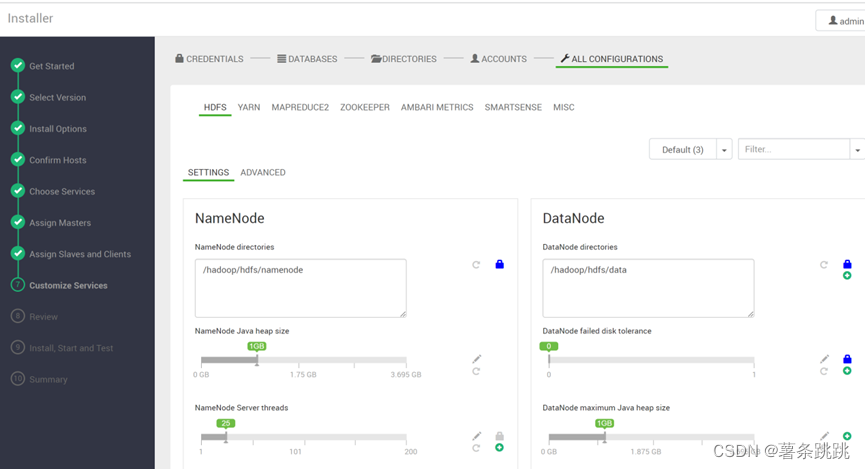
图 11-16 最终确认相关信息
11.11 检查相关信息并确定部署
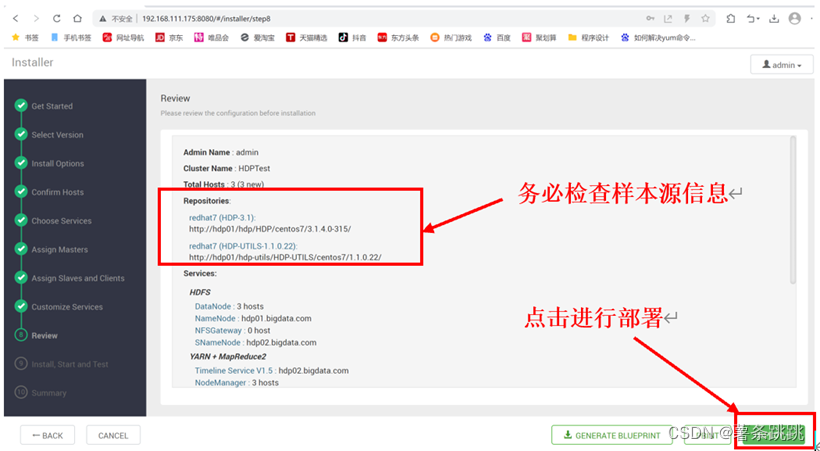
图 11-17 检查相关信息并确定部署
11.12 安装与启动服务
注意:服务安装时间相对较长,需要耐心等待

图 11-18 安装与启动服务
# 观察 Status 状态栏,如全部变为绿色,即表示安装成功
# 绿色表示安装成功,且无错误
黄色表示安装成功,但有相关警告
红色表示安装失败,存在错误
11.13 查看安装过程相关总结
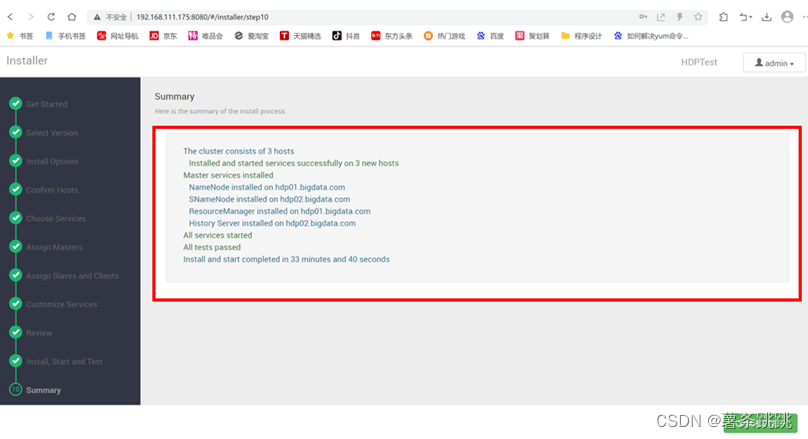
图 11-19 查看安装过程相关总结
11.14 进入 Ambari 界面并查看仪表盘
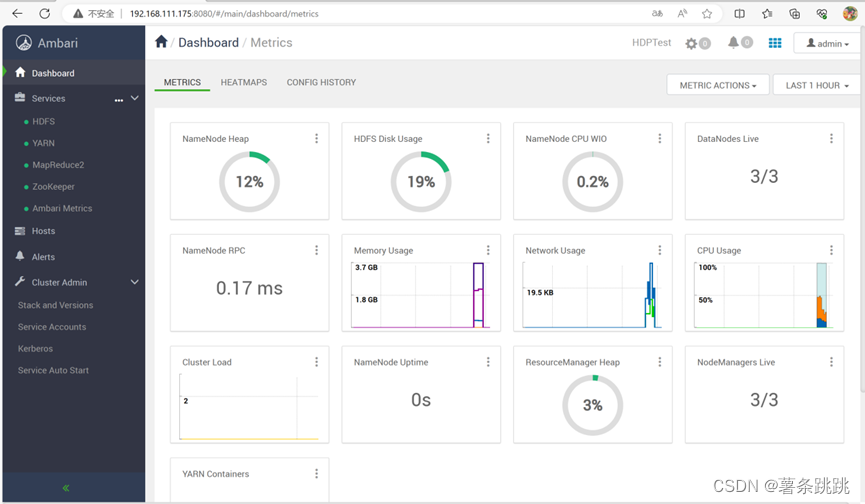
图 11-20 进入 Ambari 界面并查看仪表盘
12验证所有主机都已成功安装 HDFS 客户端
hd
# hdp01

图 12-1 验证 hdp01 已成功安装 HDFS 客户端
# hdp02

图 12-2 验证 hdp02 已成功安装 HDFS 客户端
# hdp03

图 12-3 验证 hdp03 已成功安装 HDFS 客户端
13验证 Hadoop 集群可用性
13.1 切换 HDFS 用户并建文件夹
(1)切换用户
su – hdfs
(2)在本地创建并编辑一个文本文件
vi test.txt
(3)查看文本文件
cat test.txt
(4)在 HDFS 创建文件夹并将本地文件上传至 HDFS
hdfs dfs -ls /
hdfs dfs -mkdir /input
hdfs dfs -put test.txt /input
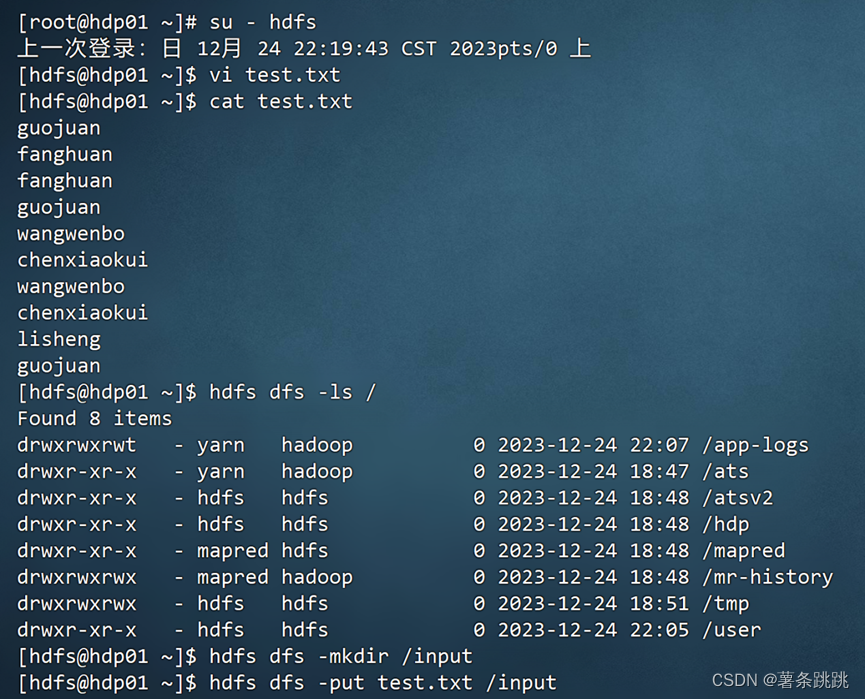
图 13-1 切换 HDFS 用户并建文件夹
13.2 WordCount 验证
(1)运行 MapReduce 并执行 WordCount
hadoop jar /usr/hdp/3.1.4.0-315/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /input /output

图 13-2 运行 MapReduce 并执行 WordCount
(2)查看 WordCount 运行结果
hdfs dfs -cat /output/part-r-00000
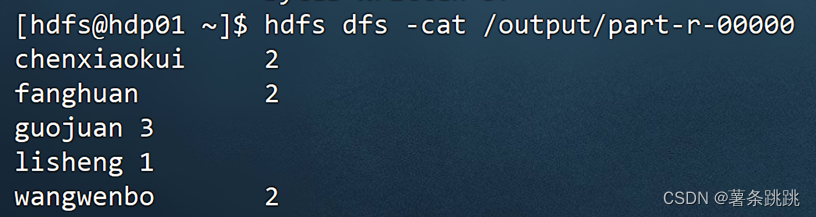
图 13-3 查看 WordCount 运行结果
14实际操作过程中遇到的错误及其解决方法
14.1 监听时间配置较短问题
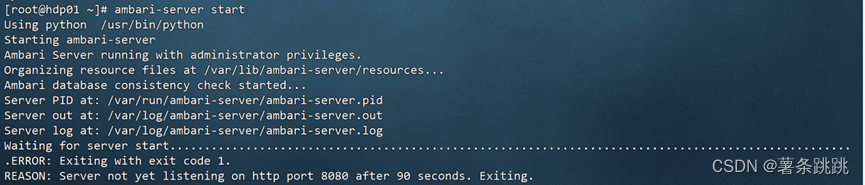
图 14-1 监听时间配置较短报错
报错提醒: Server not yet listening on http port 8080 after 50
seconds. Exiting
翻译:服务器在 50 秒后仍未侦听 http 端口 8080。正在退出。
解决方法:
(1)执行以下语句:
echo 'server.startup.web.timeout=120' >> /etc/ambari-server
/conf/ambari.properties
![]()
图 14-2 调整监听时间配置
(2)重新启动 Ambari-Server,发现启动成功
Ambari-server start
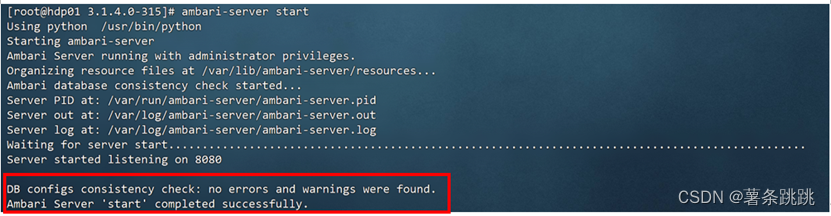
图 14-3 重新启动 Ambari-Server,发现启动成功
14.2 HDFS 界面安装 Ambari-Server 的检查过程发出警告
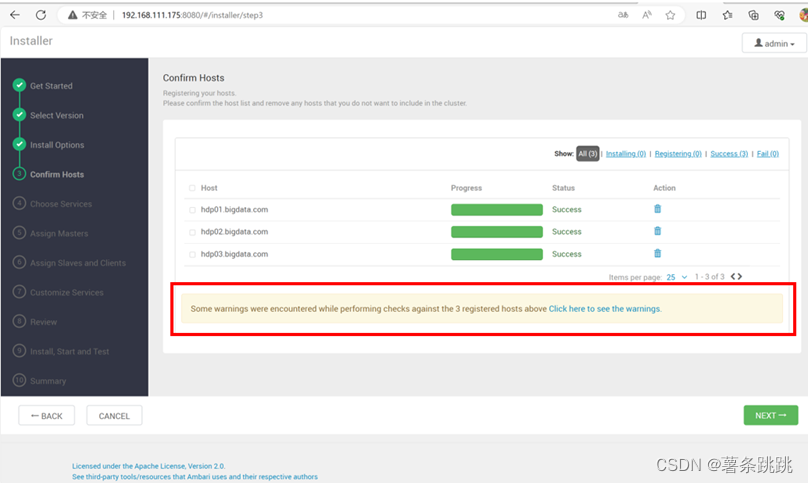
图 14-4 HDFS 界面安装 Ambari-Server 的检查过程发出警告
警告信息: Two hosts are not Chrond.
翻译:有两台主机未进行时间同步。
解决方法:
分别修改 hdp02 和 hdp03 的 ntp.conf 配置文件。
(1)注释以下语句:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst

图 14-5 在 ntp.conf 配置文件中注释相关语句
(2)添加以下语句:
(a)restrict 192.168.111.175 nomodify notrap noquery

图 14-6 在 ntp.conf 配置文件中添加相关语句(部分)
(b)server 192.168.111.175

图 14-7 在 ntp.conf 配置文件中添加相关语句(部分)
(3)重新安装 Ambari-server 后发现警告消失
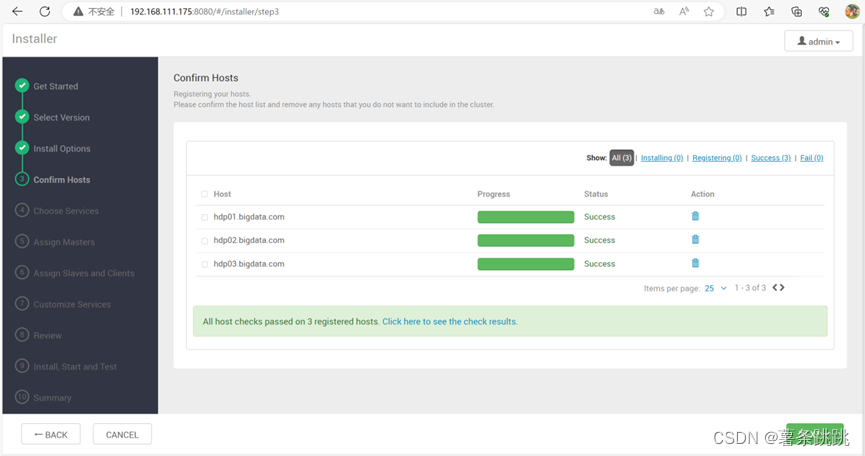
图 14-8 重新安装 Ambari-server 后发现警告消失
15结语
在本次进行基于Ambari的Hadoop集群部署实际操作过程中,本人在反复实 践中摸索,多次重新安装虚拟机,不断排查出错误与修改错误,最终得以成功完成本次实践课题。
Ambari安装实验是一个比较复杂的过程,本人在本次安装 Ambari 的过程中,总共重新部署了三次,总计耗费时间为二十余小时。对此,本人做出以下总结:
(1)在安装Ambari之前,我们需要对系统的硬件、软件、版本配置等有较清晰的了解,以便能够顺利且正确地成功安装系统 Ambari;
(2)在安装过程中,我们需根据不同的硬件环境,选择合适的安装方式,以确保系统的正确安装;
(3)在安装过程中,我们需要注意硬盘分区的正确性,以及安装的软件版
本的正确性,以确保系统的正常运行;
(4)在安装过程中,我们需要注意系统的安全性,以及系统的稳定性,以
确保系统的正常运行;
(5)由于此次对于 Ambari 的安装较为陌生, 所以我们应该在进行实际操作之前,初步确立可正确实施的实验方案,不能盲目地跟随网上教程;
(6)在填写相关路径时,应再三检查所填写的路径是否与实际所处路径一
致;
(7)在关闭虚拟机之前应该牢记将Ambari-Server服务停止;
(8)“学如融雪,行如春雷”,在安装Ambari的学习路径上, 我们需要耐心并灵活地处理相关错,不要惧怕困难,不要半途而废;
根据本文关于Ambari部署的内容,可知本文以使用VMware、Centos7系统为基础,以FinalShell为媒介工具,利用HDFS分布式文件系统和MapReduce计算框架,以及ApacheAmbari架构原理最终成功安装Ambari服务为线索成文。且本文以基于Ambari的Hadoop集群部署为例,通过列举出实践过程步骤和相关截图,以及列举出实践过程中的错误和解决方法,帮助本人进一步了解到使用Ambari系统的主要目的就是简化Hadoop生态集群的安装、配置,同时提高hadoop运维效率,以及对hadoop集群进行监控,也初步实践了大数据的采集与预处理、分析与可视化,大型软件的应用、维护与管理。
参考文献
[1] 天津滨海迅腾科技集团有限公司.大数据高可用环境搭建与运维[M].天津大学出版社,2019
[2] 黑马程序员.Hadoop大数据技术原理与应用[M].北京:清华大学出版社,2019.
[3] Tom White.Hadoop权威指南(中文版)[M].北京:清华大学出版社,2010.
[4] 李可,李昕.基于Hadoop生态集群管理系统Ambari 的研究与分析[J]. 软件, 2016,37(2): 93-97.
[5] 唐磊.基于Ambari的Hadoop集群部署实验的设计与实现[J]. 信息记录材料,2017,18(11):98-101.
[6] Apache Hadoop[EB/OL].https://hadoop.apache.org/
[7] Apache Ambari:http://ambari.apache.org/