目录
一、AlexNet
1、详细介绍
AlexNet是一种经典的卷积神经网络模型,由Alex Krizhevsky、Ilya Sutskever和Geoffrey E. Hinton于2012年提出。它是第一个在ImageNet比赛中获得冠军的深度神经网络模型,引领了深度学习在计算机视觉领域的发展。
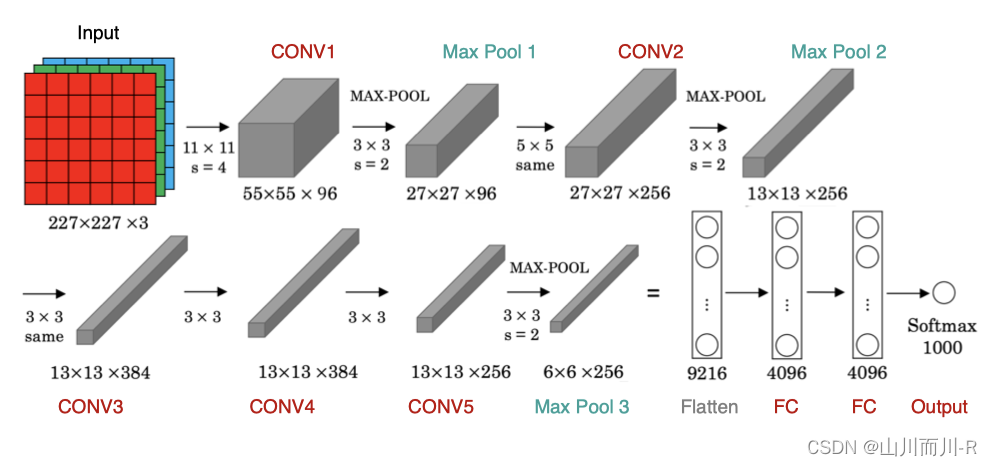
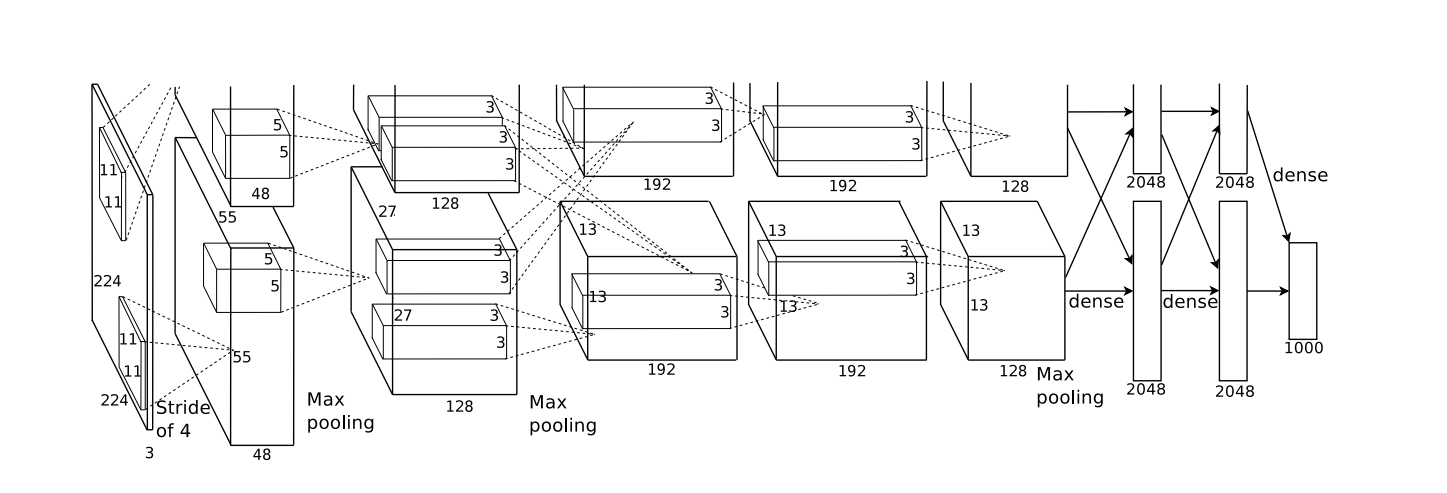
AlexNet的结构包含了8个图层,其中前5个是卷积层,后3个是全连接层。下面是对每个图层的详细介绍:
输入层(Input Layer):接受输入的图像,并进行预处理。ImageNet数据集的图像大小为224x224x3,即224个像素的高度、224个像素的宽度和3个颜色通道(RGB)。
卷积层1(Convolutional Layer 1):使用96个大小为11x11x3的卷积核对图像进行卷积操作,步长为4,不进行零填充(zero-padding)。这一层的目的是提取低级特征,例如边缘和纹理等。
激活函数1(Activation Function 1):在卷积层之后,通过ReLU(线性整流函数)激活函数处理卷积层的输出。ReLU函数将所有负值变为零,保留正值不变。这一步帮助网络更好地拟合数据。
池化层1(Pooling Layer 1):使用大小为3x3的最大池化操作,步长为2。这一步有助于减小特征图的尺寸,并且在一定程度上保留重要的特征。
卷积层2(Convolutional Layer 2):使用256个大小为5x5x48的卷积核对特征图进行卷积操作,步长为1,零填充。这一层进一步提取高级特征。
激活函数2(Activation Function 2):同样使用ReLU函数对卷积层输出进行激活。
池化层2(Pooling Layer 2):同样使用大小为3x3的最大池化操作,步长为2。这一步继续减小特征图的尺寸。
卷积层3(Convolutional Layer 3):使用384个大小为3x3x256的卷积核对特征图进行卷积操作,步长为1,零填充。这一层进一步提取高级特征。
激活函数3(Activation Function 3):同样使用ReLU函数对卷积层输出进行激活。
卷积层4(Convolutional Layer 4):使用384个大小为3x3x192的卷积核对特征图进行卷积操作,步长为1,零填充。这一层继续提取高级特征。
激活函数4(Activation Function 4):同样使用ReLU函数对卷积层输出进行激活。
卷积层5(Convolutional Layer 5):使用256个大小为3x3x192的卷积核对特征图进行卷积操作,步长为1,零填充。这一层继续提取高级特征。
激活函数5(Activation Function 5):同样使用ReLU函数对卷积层输出进行激活。
池化层3(Pooling Layer 3):同样使用大小为3x3的最大池化操作,步长为2。这一步再次减小特征图的尺寸。
全连接层1(Fully Connected Layer 1):有4096个神经元,将池化层输出的特征图展平为一个向量,并通过该层进行分类。
全连接层2(Fully Connected Layer 2):有4096个神经元,同样用于分类。
输出层(Output Layer):有1000个神经元,代表了ImageNet数据集的1000个类别。通过Softmax函数将全连接层2的输出转化为概率分布,得到最终的分类结果。
AlexNet通过使用多个卷积层和全连接层,以及采用ReLU激活函数和池化操作,能够在ImageNet数据集上取得非常好的分类性能,标志着深度学习在计算机视觉领域的重要突破。
notes:
- 首次将深度卷积神经网络用在图像分类上
- 首次利用GPU进行网络加速训练
- 使用了ReLu激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数,Sigmoid激活函数求导复杂并且网络比较深的时候会引起梯度消失
- 使用了LRN局部响应归一化
- 在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合
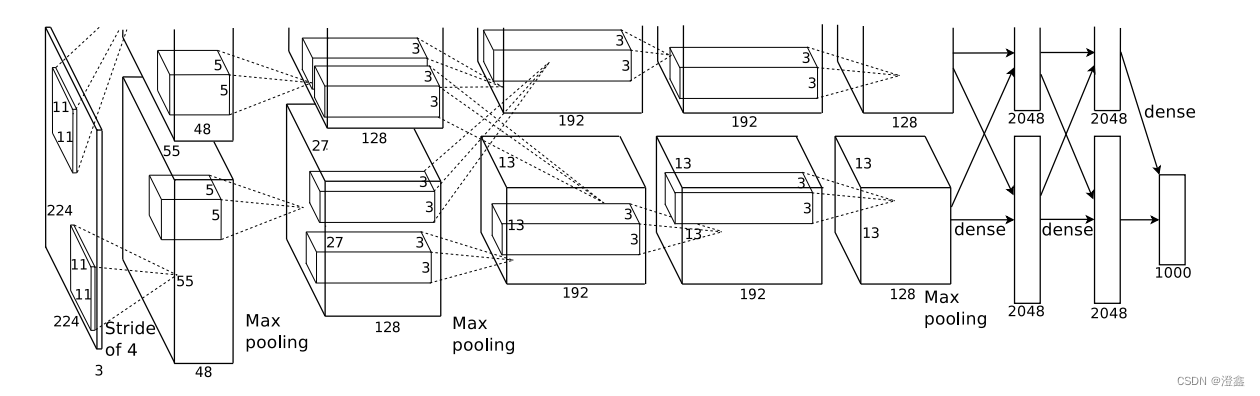
2、网络框架
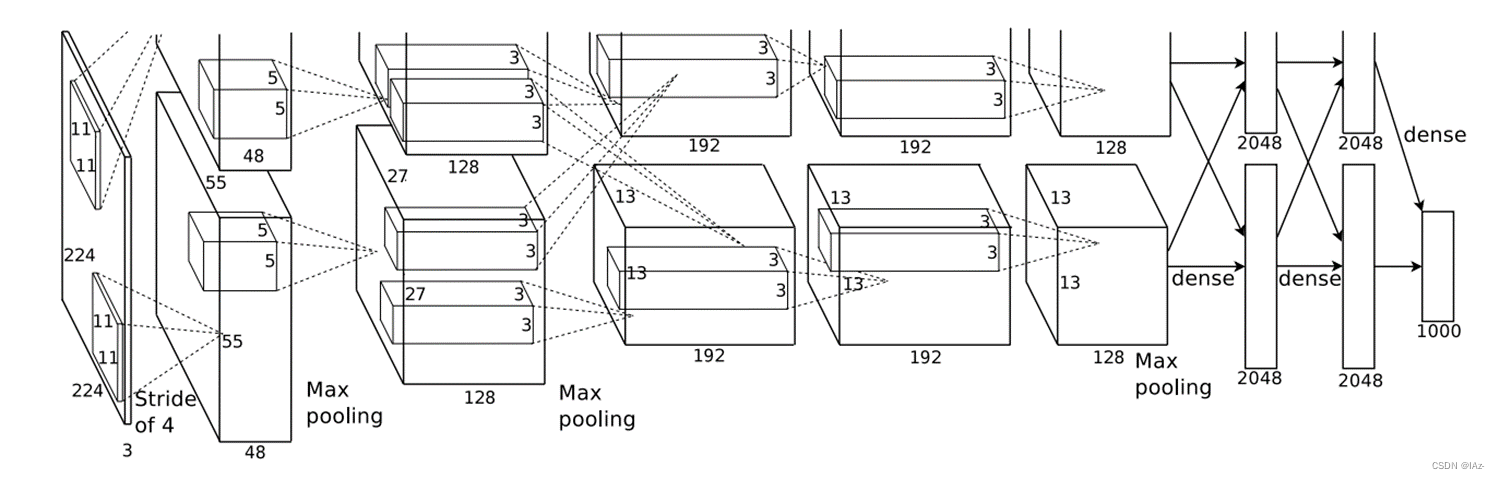
上图框架因为作者使用了两块GPU并行计算,完全相同只需要看一条路径。
经卷积后的矩阵尺寸大小计算公式为:
其中输入图片大小,卷积核大小
,步长S,填充的像素数量P。

二、网络详解
1、首次使用ReLu激活函数
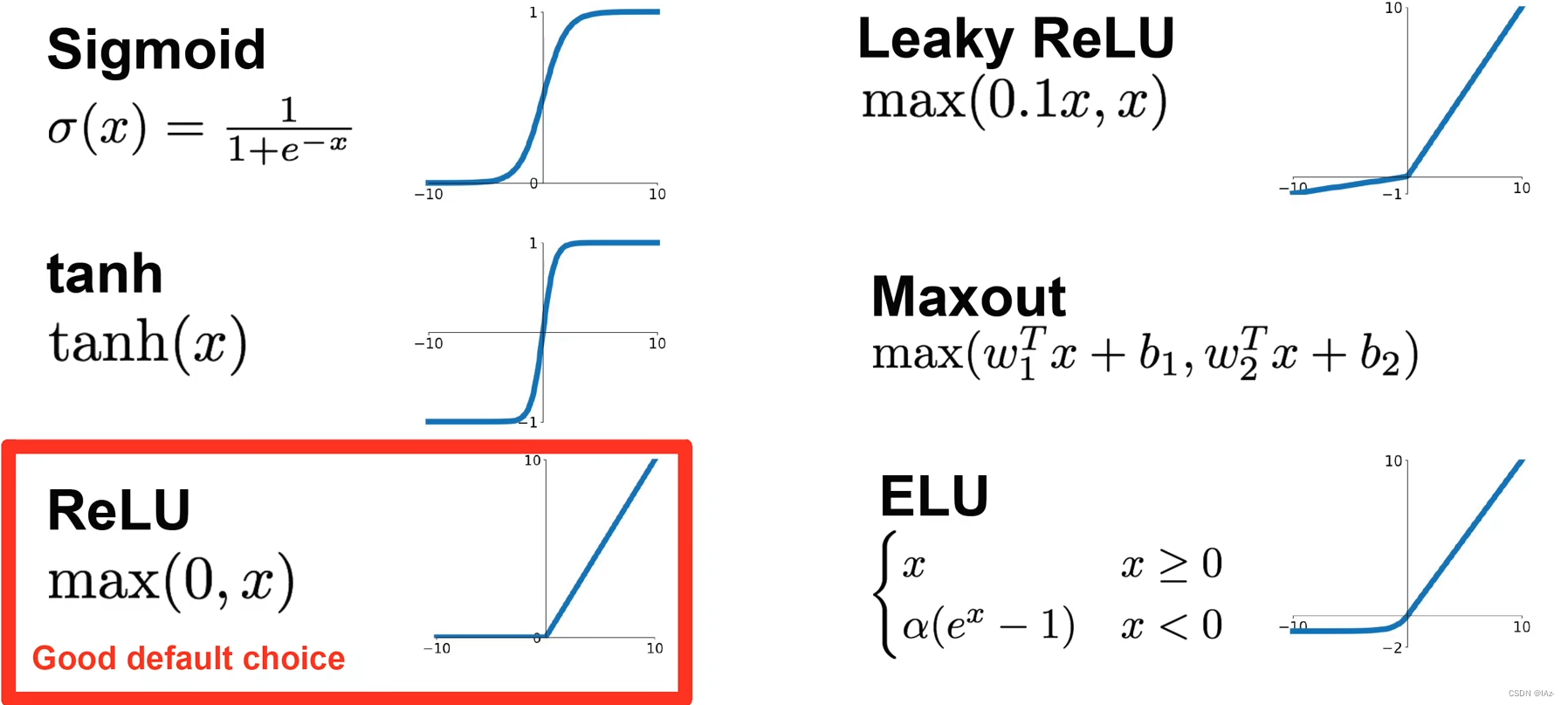
激活函数必须是非线性的,非线性的激活函数给神经网络模型引入了非线性,才能解决非线性的问题。传统的Sigmoid激活函数和Tanh都是饱和激活函数,输入的x过小或者过大就会被局限在一个很小的区域内,不能再进行变化,也就是梯度消失问题。
ReLu激活函数在x<0时全部置0,x>0时等于x,而且易于求导。只要输出大于0就可以回传梯度,可以大大加快学习速度。
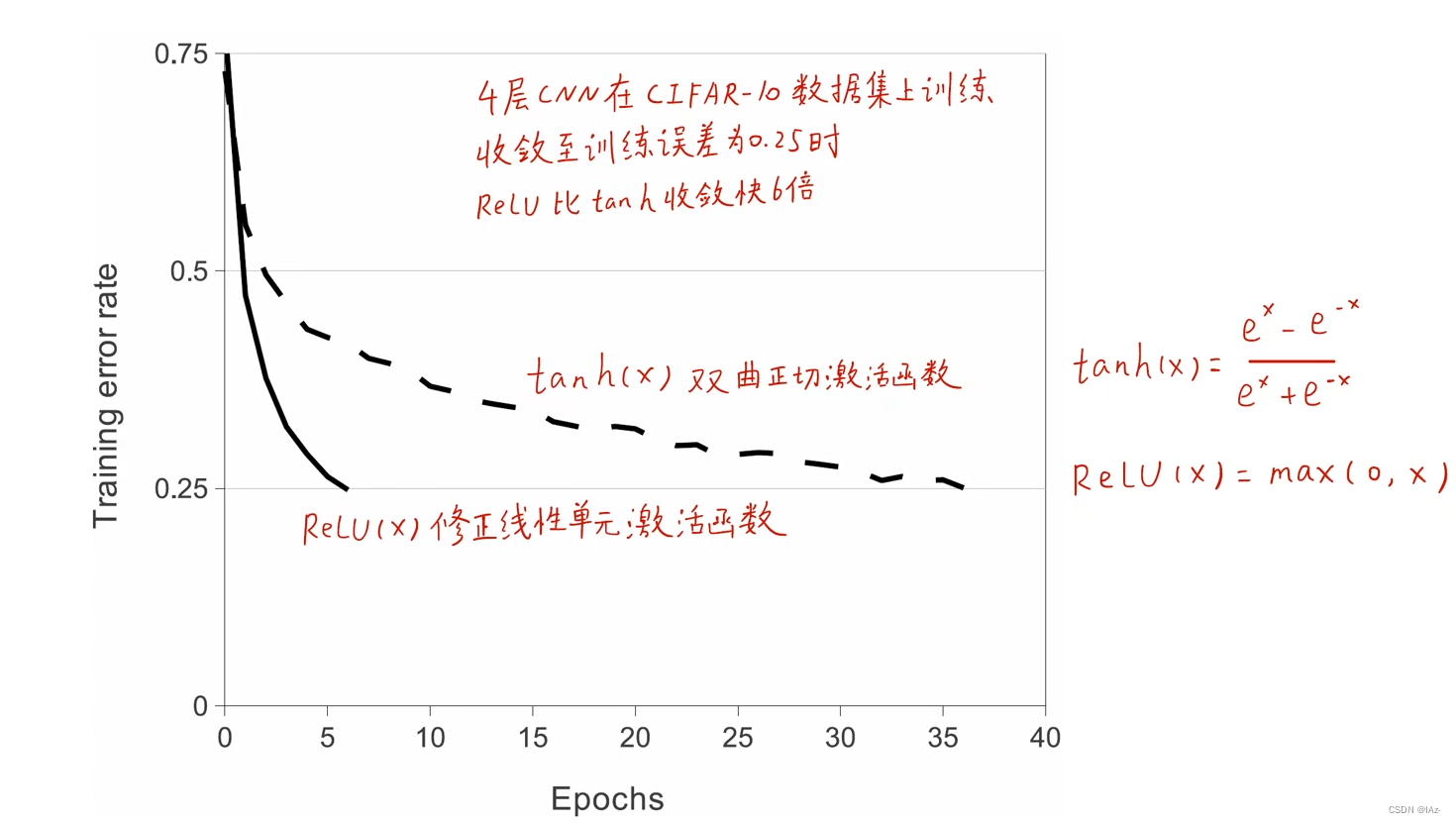
使用ReLu激活函数比使用Tanh激活函数会快6倍。
2、模型基本结构与双GPU实现
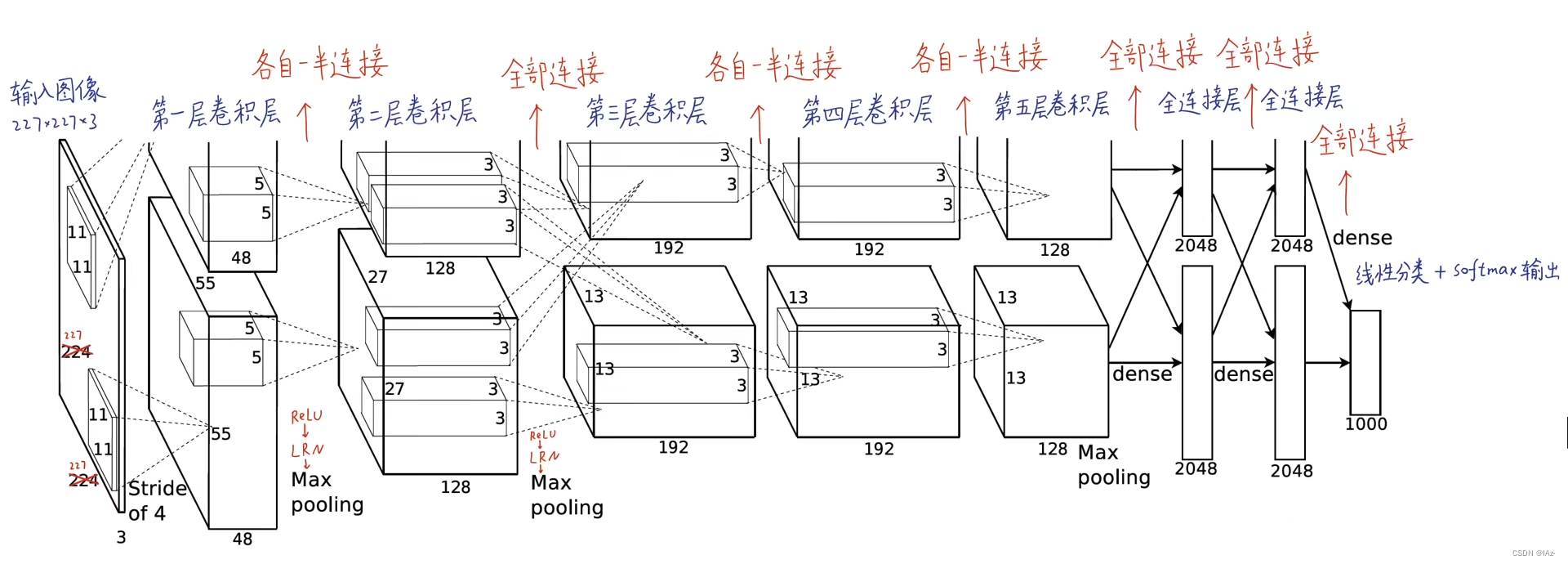
在2012年时受限于硬件算力发展,Alex将模型并行放在了双GPU上,每个GPU各自拥有一半神经元,这两个GPU只在部分层有显存读取和通信。

各层参数数量和运算次数:

3、局部响应归一化(LRN)
局部响应归一化(Local Response Normalization,LRN)是一种在卷积神经网络中常用的归一化操作。它的主要作用是增强模型的泛化能力和稳定性。
LRN操作是在卷积层后的激活函数之前应用的。它基于局部区域内的活跃度进行归一化,以调整神经元的响应程度。具体来说,对于卷积层的输出特征图中的每个位置,LRN操作将该位置的激活值除以它的局部邻域的平方和。这种归一化操作可以通过以下公式表示:
其中,
LRN操作的主要目的是增强对比度,即通过抑制较大的响应值和增强较小的响应值,使得相邻神经元之间的响应差异更加明显。这有助于提高模型对于局部模式的感知能力,并且增强了鲁棒性和泛化能力。
需要注意的是,LRN操作主要在早期的卷积网络中使用,如AlexNet和GoogLeNet等,在后续的一些网络结构中逐渐被更加有效的归一化方法如批归一化(Batch Normalization)所取代。批归一化通过对每个小批次的数据进行归一化,实现了更好的效果和稳定性。因此,尽管LRN是一种常用的操作,但在现代的深度学习模型中已经较少使用。
notes:
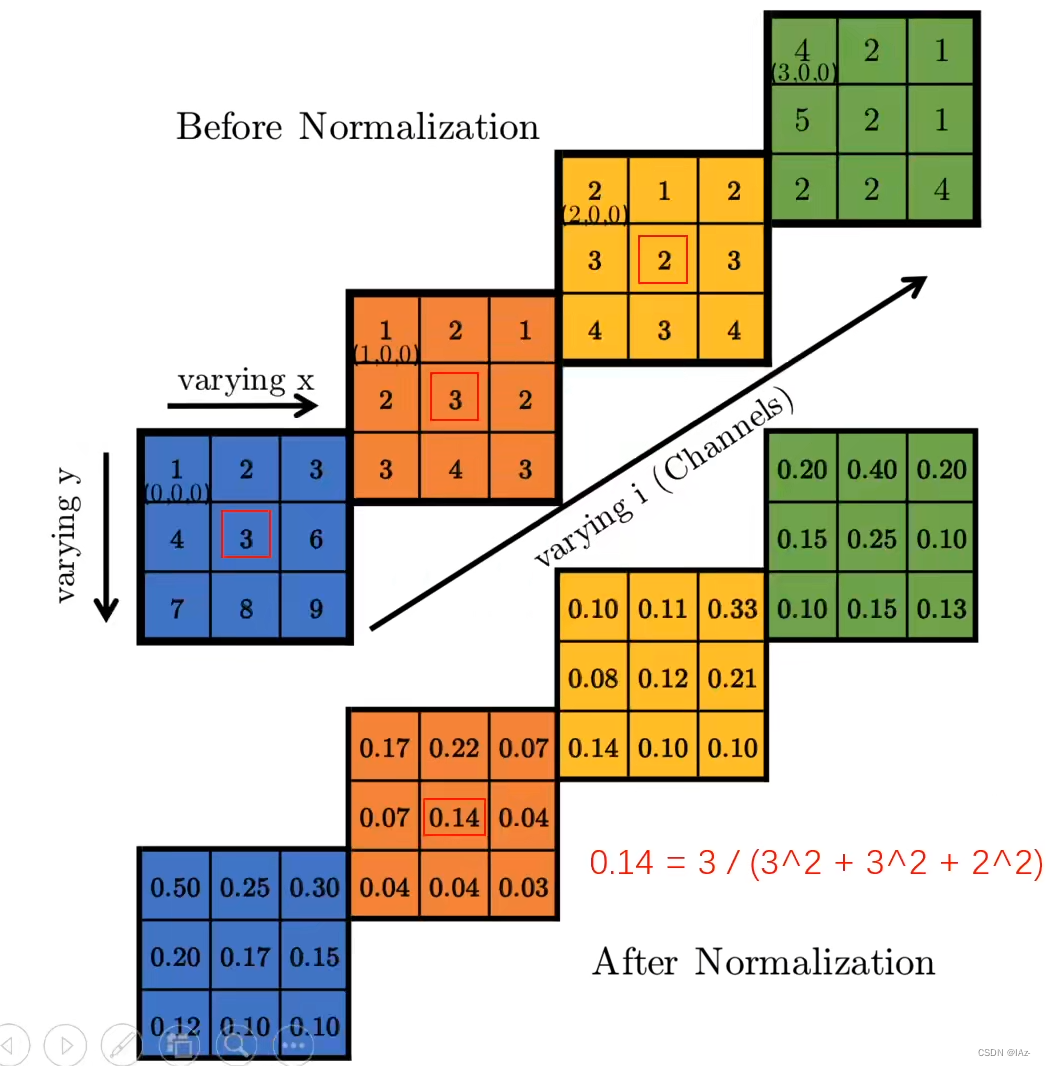
每个色块代表不同通道维度的特征图,通过将不同通道的特征图叠在一起,某一像元的值通过与相邻通道同一位置的像元值进行计算得到局部响应归一化的值。
同一位置不同通道中不需要太高激活的神经元,同一位置有太高激活值就会压制其他通道的同一位置的值,起到侧向抑制的效果。
4、重叠池化(Overlapping Pooling)
最大池化的窗口在滑动的时候,每个窗口之间是不会重叠的,AlexNet提出,如果池化步长小于窗口尺寸大小,也就是窗口之间会有重叠的时候,可以防止过拟合。

事实证明后续并没有广为采用,AlexNet为以后的网络设计进行了探索。
5、数据增强
AlexNet是个较为庞大深层的模型,参数量多,有过拟合的风险。
- 水平翻转
- 随机裁剪、平移变换
- 颜色、光照变换(PCA主成分分析,求出RGB3x3协方差矩阵的特征值特征向量,对颜色在主成分上加了个随机的变换)
扩充训练集防止过拟合。
6、Dropout
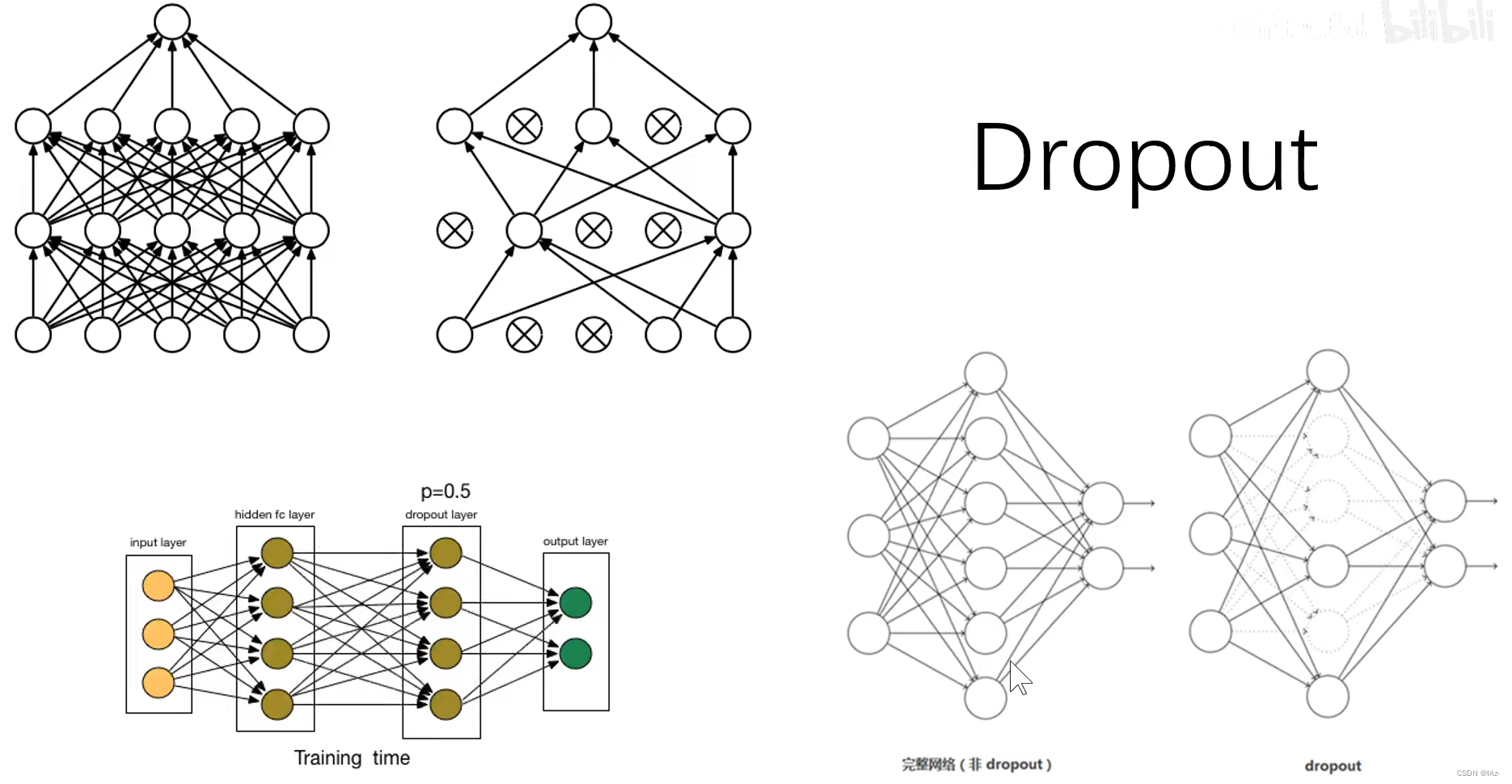
在训练每一步的时候,随机地关闭(输出为0)一些神经元,得不到反向传播也得不到训练,每一个神经元都有0.5的概率被关闭,在下一个batch的时候又重新随机关闭一部分神经元。
预测阶段保留所有神经元,预测结果乘以0.5
每一个神经元在每一轮batch中都有概率被关闭,每一次batch中启用的神经元都不相同,导致每一个神经元都要与不同神经元相协作,每一轮batch的训练时模型的状态都不相同,打破了神经元之间的联合依赖适应性,防止过拟合。
notes:
多个模型集成可以有效防止过拟合,但对于大型神经网络来说并不经济
Dropout为什么可以减少过拟合:
- 模型集成,P=0.5,意味着有
个共享权重的潜在网络
- 记忆随机抹去,不再强行记忆
- Dropout减少神经元之间的联合依赖性,每个神经元都充当重要角色
- 每个神经元都要与来自另一个随机网络结构的神经元协同工作
- 总可以找到一张图片,输入网络后这些神经元的输出就是Dropout之后的输出,有些神经元是关闭的,有些是正常的
- 稀疏性