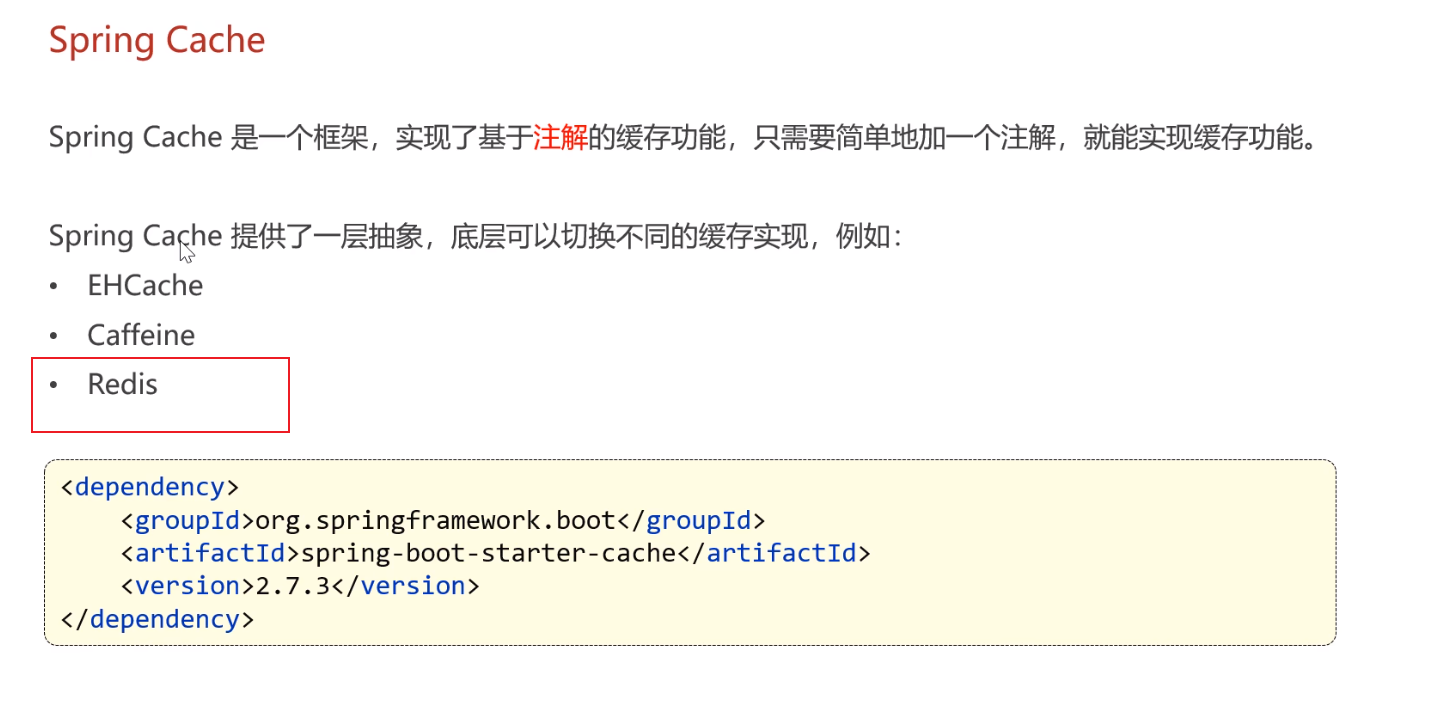
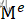在 Apache Spark 中,DataFrame 的 cache 方法用于将 DataFrame 的计算结果缓存到内存中,以便在后续的操作中能够更快地访问这些数据。这对于在多个阶段使用相同的 DataFrame 数据时是非常有用的,可以避免重复计算。
cache用法
具体来说,cache 方法执行以下操作:
- 将 DataFrame 的计算结果缓存到 Spark 集群的内存中。
- 用新的 DataFrame 代替原始的 DataFrame,新的 DataFrame 从缓存中读取数据,而不是重新计算。
以下是一个简单的示例:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DataFrameCache").getOrCreate()
// 假设 df 是你的 DataFrame
val df = spark.read.format("csv").load("your_data.csv")
// 缓存 DataFrame 的计算结果到内存中
df.cache()
// 使用缓存后的 DataFrame 进行多次操作
val result1 = df.filter("some_condition").groupBy("column").agg("agg_column" -> "sum")
val result2 = df.filter("another_condition").groupBy("column").agg("agg_column" -> "avg")
result1.show()
result2.show()
在上述代码中,df.cache() 将 DataFrame df 的计算结果缓存到内存中。之后,我们可以在后续的操作中使用 result1 和 result2,Spark 将尽可能使用缓存中的数据,而不是重新计算。
需要注意的是,缓存操作可能会导致额外的内存开销,因此需要谨慎使用,特别是当数据量较大时。
可以使用 unpersist() 方法来手动释放缓存,
或者在不再需要缓存时调用 df.unpersist() 来释放资源。
SparkOutOfMemoryError解决
在 Spark 中,使用 cache 方法将数据缓存到内存中可能会导致 SparkOutOfMemoryError 错误,尤其是在数据量较大、集群资源不足或者缓存的数据量超过可用内存时。这是因为缓存大量数据可能会导致内存不足,从而触发 OutOfMemory 错误。
为了避免这种情况,可以考虑以下几点:
合理分配资源: 在 Spark 应用程序中,确保为每个任务分配的资源是合理的。这包括 executor 内存、CPU 核心数等。过度分配资源可能导致内存不足。
合理使用缓存: 考虑缓存的数据量和内存资源之间的平衡。不要缓存超出可用内存的数据量。如果数据量很大,可以考虑使用
StorageLevel参数来调整缓存级别,例如使用MEMORY_ONLY_SER或MEMORY_ONLY_SER_2,这将以序列化的形式存储数据,减少内存占用。及时释放缓存: 当不再需要缓存的数据时,及时使用
unpersist方法释放缓存。避免将不必要的数据一直保存在内存中。
// 缓存 DataFrame
df.cache()
// 使用缓存后的 DataFrame 进行操作
// 释放缓存
df.unpersist()
- 考虑使用硬盘存储: 如果数据量非常大,而内存不足以容纳所有数据,可以考虑使用硬盘存储,例如
DISK_ONLY或MEMORY_AND_DISK存储级别。
df.persist(StorageLevel.DISK_ONLY)
综合考虑这些因素,可以有效地管理内存资源,避免 SparkOutOfMemoryError 错误。
StorageLevel.DISK_ONLY 数据会保存到哪
使用 df.persist(StorageLevel.DISK_ONLY) 将 DataFrame 缓存到硬盘时,数据会被保存在 Spark 集群的本地文件系统上。这是指每个 Spark Executor 的本地文件系统,而不是你提交 Spark 应用程序的主节点或 HDFS。
具体来说:
本地文件系统: 对于每个 Executor,Spark 会在其本地文件系统上创建一个目录,称为存储目录(Storage Directory)。数据将被写入并存储在这个目录中。
Executor 的工作目录: 存储目录通常位于 Executor 的工作目录中。这是 Executor 专用的目录,用于存储缓存的数据和其他 Spark 相关的临时文件。
数据分布: 数据将被分布在集群中的多个 Executor 上,每个 Executor 存储其分配到的数据。
需要注意的是,这种存储方式是相对于内存缓存而言的,是一种牺牲速度来换取存储容量和持久性的做法。存储在硬盘上的数据在需要时可以从硬盘读取到内存中,但相对于内存缓存而言,读取速度会较慢。
当你使用 df.persist(StorageLevel.DISK_ONLY) 时,Spark 会根据需要将数据写入和读取出这些存储目录。因此,确保每个 Executor 的本地文件系统有足够的空间,以容纳缓存的数据。


![[mmu/<span style='color:red;'>cache</span>]-ARMV8<span style='color:red;'>的</span><span style='color:red;'>cache</span><span style='color:red;'>的</span>维护指令介绍](https://img-blog.csdnimg.cn/20201118154912892.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjEzNTA4Nw==,size_16,color_FFFFFF,t_70#pic_center)




















![[Angular] 笔记 11:可观察对象(Observable)](https://img-blog.csdnimg.cn/direct/931476d83da3448bb5ba7e12ff113b2b.png)