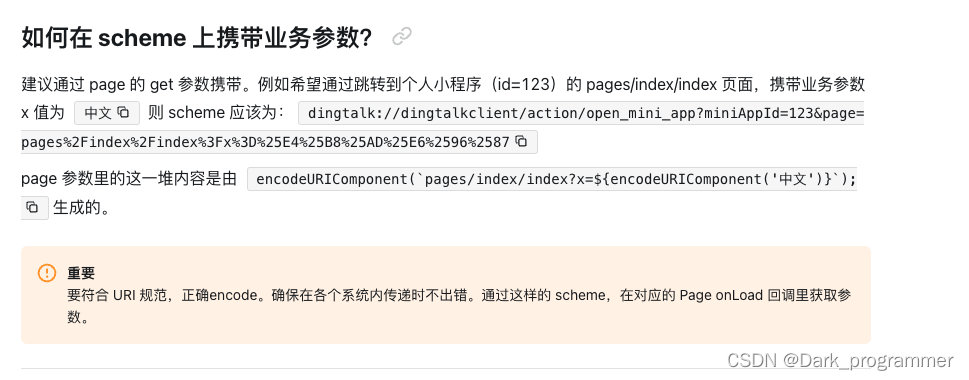
问题描述
今天采集一个网站爬虫的时候,网站a标签中都是使用的相对链接。我获取到链接后无法直接使用来作为下一次请求获取详情页面。
解决方法
为了将相对链接转换为绝对链接,我们可以使用 Python 的 urllib.parse 模块中的 urljoin 函数。这个函数可以将一个基础 URL(base URL)和一个相对 URL 合并成一个绝对 URL。
下面是一个示例代码,展示了如何使用 urljoin 函数将相对链接补充完整:
from urllib.parse import urljoin
# 页面完整链接
base_url = "https://zjjcmspublic.oss-cn-hangzhou-zwynet-d01-a.internet.cloud.zj.gov.cn/jcms_files/jcms1/web3077/site/flash/tjj/Reports1/2023%E6%B5%99%E6%B1%9F%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B4/indexcn.html"
# 获取到的相对链接
relative_url = "./cn/html/2-1 历年总户数和总人口数(年底数).html"
# 使用 urljoin 将相对链接转换为绝对链接
absolute_url = urljoin(base_url, relative_url)
print(absolute_url)运行这段代码后,absolute_url 变量将包含完整的 URL。这样你就可以使用这个完整的 URL 去获取你想要的数据了。