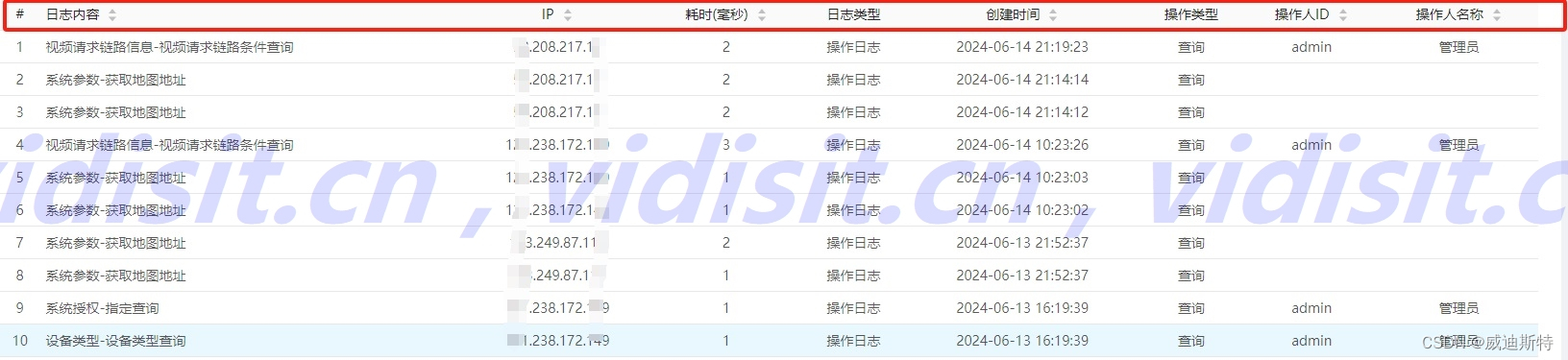
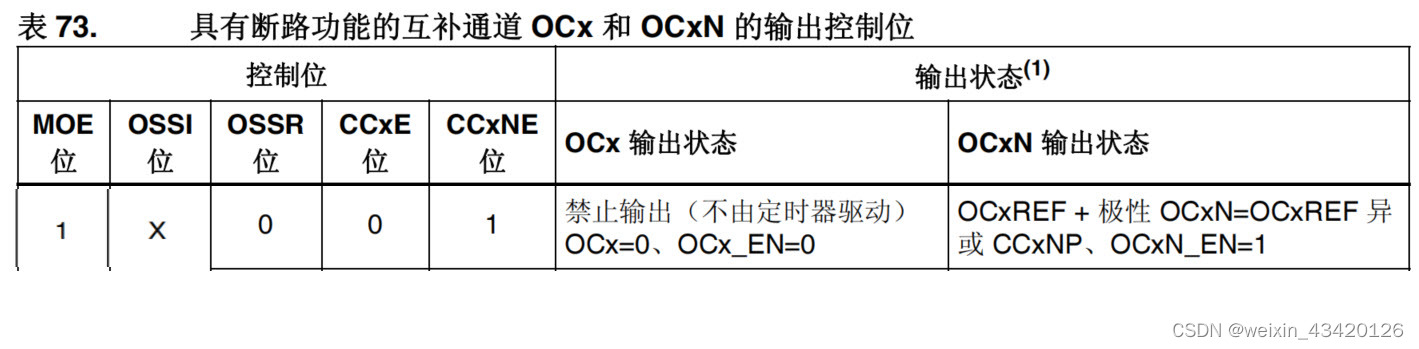
之前由于运维需求,需要对一个大日志文件按照日期进行划分,将每天的日志写入一个单独的文件中。
刚开始接到这个需求后,我浏览了一遍日志文件,发现里面只有11月17号到11月22号的日志,天数不多,可以尝试手动划分。但一看行数,好几万行,这得拖到什么时候,手指都按麻了。。。
于是我有了一个最初的思路:将文件放到linux系统中,利用cat+grep命令匹配行并输出到指定文件中。由于涉及的天数很少,我很快完成了操作;
1)命令行:cat+grep
# 11月17号的日志
cat message.log | grep 'Nov 17' > Nov_17.log
# 后续日志命令类似
...
那么很自然地,我思考到:如果大日志文件中,涉及的天数很多呢,难道有几十上百天,我就要敲几十上百次命令吗?显然不可能,于是想到了使用脚本自动操作
2)脚本:逐行read追加写
#!/bin/bash
# 设置日志文件路径
log_file="messages.log"
# 设置输出目录
output_dir="logs"
# 创建输出目录
mkdir -p "$output_dir"
# 保存当前日期
current_date=""
# 读取日志文件的每一行
while IFS= read -r line
do
# 获取日期部分(前两个单词)
date=$(echo "$line" | awk '{print $1, $2}')
# 检查日期是否改变
if [ "$date" != "$current_date" ]; then
# 更新当前日期
current_date="$date"
# 将日期格式化为文件名中可接受的格式(替换空格为下划线)
file_name=$(echo "$date" | tr ' ' '_').log
# 创建新的日志文件
touch "$output_dir/$file_name"
fi
# 将日志行追加到对应的文件中
echo "$line" >> "$output_dir/$file_name"
done < "$log_file"
完成这一步后,我特地找了一个很大的日志文件(40w行)进行测试,发现过程很漫长,足足用了十几分钟,这可太慢了,想来是每次read进行IO操作浪费了不少时间,那么换个思路,将文件内容全部存入数组中,每次遍历去数组中读取内容,在必要的时候一次性将匹配的行全部写入目标文件。
3)脚本:写入数组进行操作,减少IO次数,匹配行号一次性写入
#!/bin/bash
# 设置日志文件路径
log_file="$1"
# 设置输出目录
output_dir="logs"
# 将文件写入数组中
mapfile -t file_arr < $log_file
# 开始行
start_line=1
# 结束行
end_line=1
# 创建输出目录
mkdir -p "$output_dir"
#保存当前日期
current_date=""
# 读取日志文件的每一行
for ((i=0; i<${#file_arr[@]}; i++)); do
echo 当前时间 $(date | awk '{print $4}')
# 获取日期部分(前两个单词)
date=$(echo ${
file_arr[i]} | awk '{print $1, $2}')
if [ "$date" != "$current_date" ]; then
if [ "$current_date" != "" ]; then
# 将日期格式化为文件名中可接受的格式(替换空格为下划线)
file_name=$(echo "$current_date" | tr ' ' '_').log
# 更新结束行
end_line=$i
# 将上一个日期的结果写入文件中
awk -v start=$start_line -v end=$end_line 'NR >= start && NR <= end' $log_file > ${output_dir}/${file_name}
# 更新起始行
start_line=$((i+1))
fi
current_date=$date
fi
if [ $((i+1)) == ${
#file_arr[@]} ]; then
# 最后一个日期的处理
file_name=$(echo "$current_date" | tr ' ' '_').log
awk -v start=$start_line -v end=$((i+1)) 'NR >= start && NR <= end' $log_file > ${output_dir}/${file_name}
fi
done
我信心满满地进行测试,但等了许久都不见完成。干脆每次循环输出一下当前时间,看看到底怎么回事。这一操作就跑了足足一个多小时,仔细观察终端的输出,发现程序每秒只执行了几十次循环,也不知道为啥如此慢。
我去咨询了一下GPT,说shell是解释型语言,执行效率相比编译型语言还是差一个档次。我用Java编写了同样的代码逻辑,并且是逐行输入,这下仅仅用了几秒钟,就完成了!不愧是高效的编程语言。
4) Java
public class Main {
private static String[] fileArr;
public static void main(String[] args) throws IOException {
String fileDir = "src/test/resources";
File file = new File(fileDir+"/messages.log");
BufferedReader br = new BufferedReader(new FileReader(file));
List<String> fileList = new ArrayList<>();
String line;
while ((line = br.readLine()) != null) {
fileList.add(line);
}
fileArr = fileList.toArray(new String[0]);
System.out.println(fileArr.length);
String curDate = "";
int startLine = 0;
int endLine = 0;
for (int i = 0; i < fileArr.length; i++) {
String date = fileArr[i].split(" ")[0] + fileArr[i].split(" ")[1];
if (!curDate.equals(date)) {
if (!"".equals(curDate)) {
endLine = i;
String fileName = fileDir+"/"+curDate+".log";
writeToFile(startLine, endLine, fileName);
startLine = i + 1;
}
// 更新日期
curDate = date;
}
// 最后的日期处理
if (i == fileArr.length - 1) {
String fileName = fileDir+"/"+curDate+".log";
writeToFile(startLine, i, fileName);
}
}
}
private static void writeToFile(int startLine, int endLine, String fileName) throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter(fileName));
for (int i = startLine; i <= endLine; i++) {
bw.write(fileArr[i]);
if (i == endLine){
System.out.println(fileArr[i]);
}
bw.newLine();
bw.flush();
}
}
}