目录
1. 什么是决策树?
决策树分类的思想类似于找对象。
想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女孩决定是否见男孩的一个过程,就像一个树形结构,只不过是反正的树, 数学上或者机器学习里的树,根在最上方
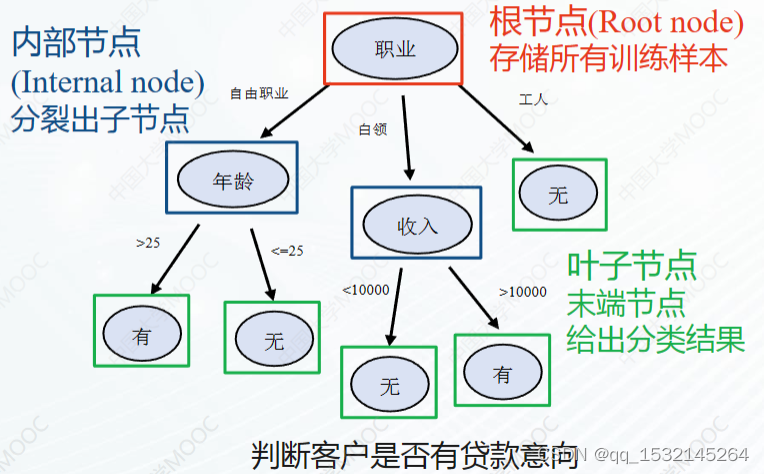
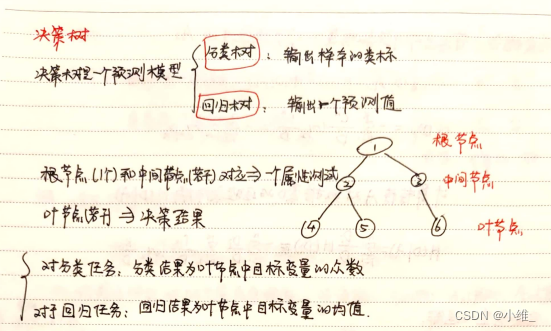
最上方的为树的根节点,下面的都是子节点
像下图的橙色的部分,下面在没有往下的结点的叫叶子节点
如果一颗树每个节点下面最多只有两个节点就属于二叉树
下图的就是一个非二叉树( 到收入下面有三个节点)
上图完整表达了这个女孩决定是否见一个约会对象的策略,
其中绿色节点表示判断条件,
橙色节点表示决策结果,
箭头表示在一个判断条件在不同情况下的决策路径,
图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,
如果将所有条件量化,则就变成真正的决策树了。
有了上面直观的认识,我们可以正式定义决策树了:决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节
点,将叶子节点存放的类别作为决策结果可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支
生物学以及商业等诸多领域。决策树的主要优势就在于数据形式非常容易理解。决策树算法能够读取数据集合,构建类似于上面的决策树,决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。专家系统中经常使用决策树,而且决策树给出结果往往可以匹敌在当前领域具有几十年工作经验的人类专家
2. 决策树的原理
2.1 如何构建决策树?
首先,例如上方的图,我们可以分析到,我们要先选择 判断条件,
例如有些女孩找男朋友的第一个条件考虑年龄而有的考虑收入有的还考虑长相等等,所以这就是构造决策树的第一个关键的点:判断条件的顺序,
有了判断条件之后,怎么判断这个节点的分裂,例如,年龄这个判断条件,是按照30岁分还是按照什么分,符合这个条件是一个节点,不符合这个判断条件的是另外一个节点,这就是构造决策树的第二个关键的点:节点分裂的界限或者说节点分裂的定义和分类
构造决策树关键步骤是分裂属性,所谓分裂属性就是在某个节点处,按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能的“纯”,尽可能“纯” 就是尽量让一个分裂子集中待分类项属于同一类别
2.2 构建决策树的数据算法
2.2.1 信息熵
有了刚说的两个关键点,对于这个两个关键点的选择就有点困难,所以需要具体的算法来做
建决策树的数据算法有很多
ID3算法
C4.5算法
CART算法
.....
等等
这里面就牵扯了信息论中的信息熵 有关信息熵可参考(可以点开全部回答,然后搜索 阅读 ,或者自行查看 )
信息熵的数学公式:
2.2.2 ID3算法
ID3算法算的是信息增益
2.2.2.1 信息的定义
熵定义为信息的期望值,在明确这个概念之前,我们必须知道信息的定义,如果待分类的事务划分在多个分类之中,则符合X的信息定义为:
其中p(x)是选择该分类的概率
为了计算熵,我们需要计算所有类别所有可能的信息期望值,通过下面的公式得到:
其中n 是分类的数目
在决策树当中,设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi 表示第i个类别在整个训练元组出现的概率,可以用属于此类别元素的数量除以训练元组元素总数作为估计。
熵的实际意义表示是D中元组的类标号所需要的平均信息量
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
2.2.2.2 信息增益
ID3算法 利用 信息增益来决定优先使用哪个特征进行分裂
先用没有进行任何属性分类的时候,计算一个信息熵
再选其中的某一个特征进行分裂构造决策树,再计算一个信息熵,具体用哪个特征来计算,要看哪个特征计算出来的信息熵大,就用哪个,因为这样算出来的值越大相减之后就消除了原来数据里面最大的不确定性
这两个信息熵之间会有一个差值, 这两个信息熵之差,得到的值叫做信息增益
2.2.2.3 ID3算法举例
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂,
如下图假设训练集合包含10条数据,预测一下,社交网站上的账号是否真实的账号
根据日志密度,好友密度,是否使用真是头像等(这些都为特征)来预测
代表的含义: s 小,m中等,l 大
先完成构建决策树其中一个关键点:首先用那个特征进行分裂
计算思路:
1⃣️ 先计算没有使用任何特征对账号是否真实的计算的信息熵
2⃣️ 再算随便使用一个特征对账号是否真实的计算的信息熵
代码如下:(使用 jupyter notebook)
import pandas as pd import numpy as np# 计算图中的信息熵,确定一个分类的特征 # D 就是我们的原始数据 # 先计算未使用任何特征的进行分类的信息熵(所以只需关心账号是否真实这一列) # 账号是否真实: 有两种情况,分别为 yes no, yes数量为7(概率为0.7),no的数量为3(概率为0.3) # 根据信息熵公式: info_D = -(0.7 * np.log2(0.7) + 0.3 * np.log2(0.3)) info_D # 0.8812908992306927使用 日志密度 对账号是否真实的信息熵
使用公式# 使用 日志密度 对账号是否真实的信息熵 使用公式 # j 就是 3(因为日志密度有三种情况,s,l,m) # s 三个(0.3),对应账号是否真实列,2个no, 1个yes # l 三个(0.3), 对应账号是否真实列,0个no, 3个yes # m 四个(0.4), 对应账号是否真实列,1个no, 3个yes # s情况中对日志密度划分的信息熵 = s 的 概率 ✖️ s 中对账号是否真实的信息熵 = 0.3 * ((-1/3) * np.log2(1/2) + (-2/3) * np.log2(2/3)) # 同理 l = 0.3 * (-1 * log2(1)) # 同理 m = info_D_Log = 0.3 * ((-1/3) * np.log2(1/3) + (-2/3) * np.log2(2/3)) + 0.3 * (-1 * np.log2(1)) + 0.4 * ((-1/4) * np.log2(1/4) + (-3/4) * np.log2(3/4)) info_D_Log# 使用 日志密度 进行划分的信息增益 info_D - info_D_Log # 0.2812908992306927# 使用 好友密度 对账号是否真实的信息熵 # s 4个(0.4),对应账号是否真实列,3个no, 1个yes # m 4个(0.4), 对应账号是否真实列,0个no, 4个yes # l 2个(0.2), 对应账号是否真实列,0个no, 2个yes info_D_F = 0.4 * ((-3/4) * np.log2(3/4) + (-1/4) * np.log2(1/4)) + 0 + 0 info_D_F # 0.32451124978365314# 使用 好友密度 进行划分的信息增益 info_D - info_D_F # 0.5567796494470396# 使用 是否使用真实头像 对账号是否真实的信息熵 # no 5个 2个no,3个yes # yes 5个 1个no,4个yes info_D_H = 0.5 * ((-2/5) * np.log2(2/5) + (-3/5) * np.log2(3/5)) + 0.5 * ((-1/5) * np.log2(1/5) + (-4/5) * np.log2(4/5)) info_D_H # 0.8464393446710154# 使用 是否使用真实头像 进行划分的信息增益 info_D - info_D_H # 0.034851554559677256根据上述的运算结果,可以看到, 使用 好友密度 进行划分的信息增益 的 值最大 ,所以 我们就用好友密度这个特征来构建决策树
再完成构建决策树另外一个关键点:首先用那个特征进行分裂节点分裂的界限或者说节点分裂的定义和分类, 而这些我们不需要关心,ID3算法会帮我们做好,只要能确定出来用哪个特征即可
分裂属性分为三种不同的情况:
- 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
- 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
- 属性是连续值。此时确定一个值作为分裂点split_point,
按照>split_point和<=split_points生成两个分支。离散值即 例子中的 s,m,l,这种就是有三个划分,而连续值类似年龄这种连续值,29,30,31等
2.2.2.4 ID3算法优缺点
- 优点:简单、时间复杂度、时间复杂度都不高
- 缺点:数据中大量的离散型的数据,会对分裂造成误差
2.2.3 C4.5算法
因为ID3算法在对于离散型特征的处理不好,引入C4.5算法
C4.5算法,计算的是信息增益率
计算步骤:
- 先计算信息增益
- 再除以这个特征本身的信息熵
2.2.3.1 C4.5算法举例
信息增益,上面ID3算法已经计算出来,可以直接使用, 代码如下
2.2.4 CART算法
2.2.4.1 Gini指数(基尼指数)
由上面的内容我们已经知道,决策树的核心就是寻找纯净的划分,因此引入了纯度的概念。在属性选择上,我们是通过统计“不纯度”来做判断的,ID3 是基于信息增益做判断,C4.5 在 ID3 的基础上做了改进,提出了信息增益率的概念。实际上 CART 分类树与 C4.5 算法类似,只是属性选择的指标采用的是基尼指数。
基尼指数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。所以 CART 算法在构造分类树的时候,会选择基尼系数最小的属性作为属性的划分。
在决策树Cart算法中用Gini指数来衡量数据的不纯度或者不确定性
2.2.4.2 Cart算法 相关公式
在分类问题中,样本属于第 i 类的概率为
经过特征a分割之后集合D的不确定性,基尼指数越大,不确定性越大,因此我们需要寻找基尼指数越小的特征作为节点
2.2.4.3 Cart算法举例
3. 本文涉及的代码
https://download.csdn.net/download/wei18791957243/88660903
https://download.csdn.net/download/wei18791957243/88660903https://download.csdn.net/download/wei18791957243/88660904







1.决策树
2023-12-26 12:10:04 31 阅读



![[基本功]<span style='color:red;'>决策</span><span style='color:red;'>树</span>](https://img-blog.csdnimg.cn/img_convert/1d05ad496018d484774c8d8a2164d31a.webp?x-oss-process=image/format,png)