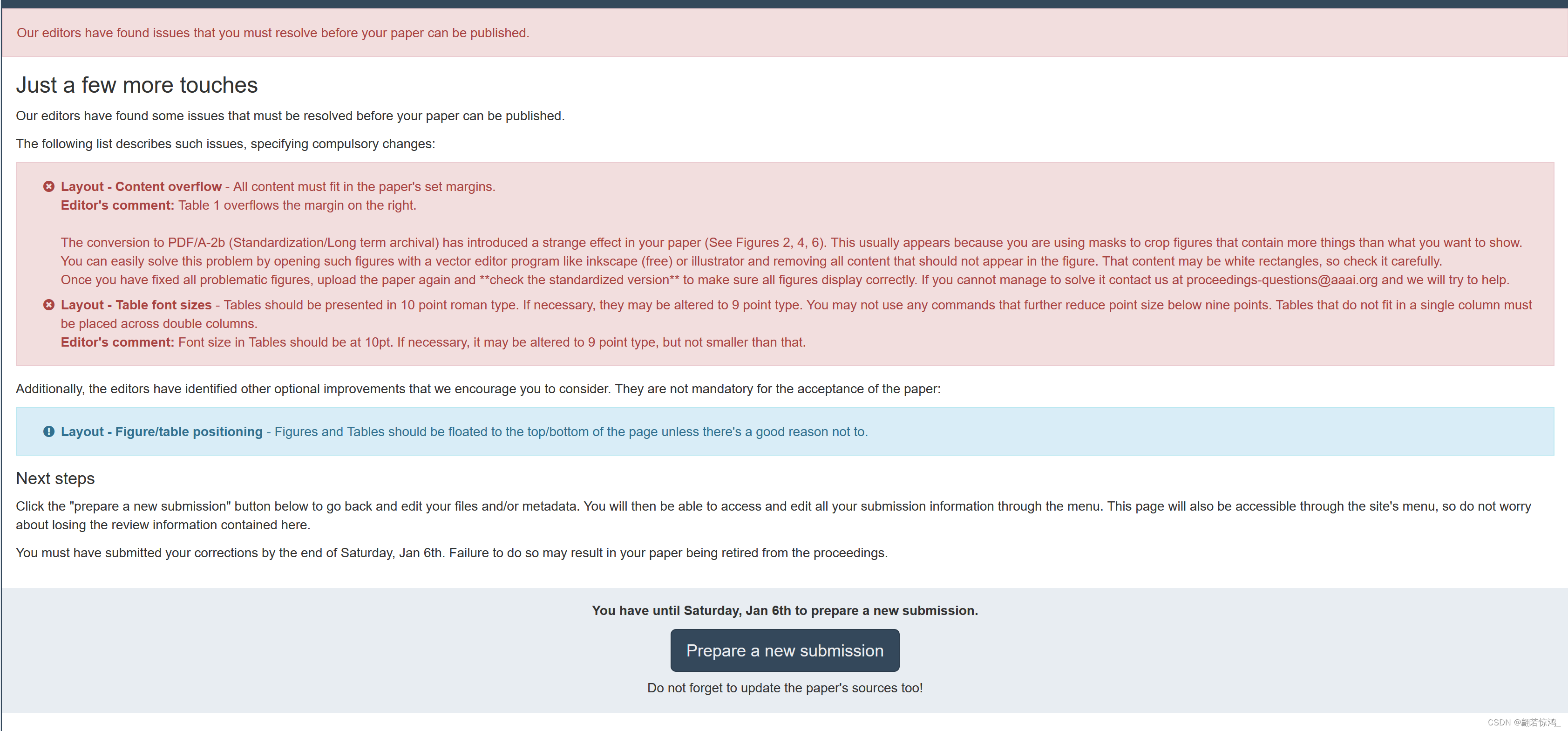
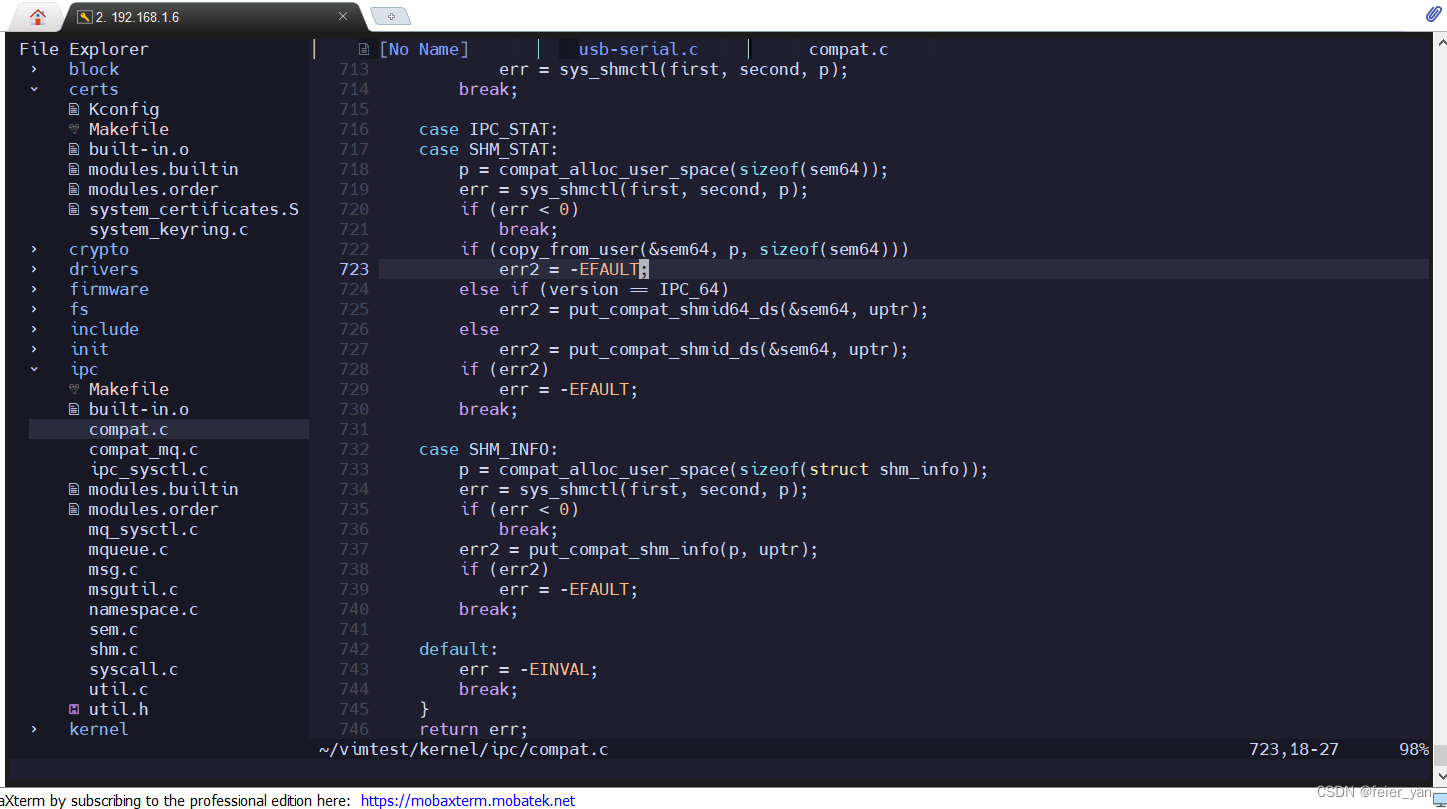
错误代码:
tokenizer = AutoTokenizer.from_pretrained("philschmid/bart-large-cnn-samsum")
model = AutoModelForSeq2SeqLM.from_pretrained("philschmid/bart-large-cnn-samsum")
model.eval()
model.to("cuda")
loss = 0
for i in range(len(self.dataset)):
batch = tokenizer([self.dataset[i]["source"]], return_tensors="pt", padding=True).to("cuda")
labels = tokenizer([self.dataset[i]["target"]], return_tensors="pt", padding=True).to("cuda")
print(batch)
outputs = model(**batch, labels=labels)
print(outputs.loss.item())
报错内容:
Traceback (most recent call last):
File "D:\anaconda\envs\supTextDebug\lib\site-packages\transformers\tokenization_utils_base.py", line 266, in __getattr__
return self.data[item]
KeyError: 'new_zeros'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\supTextDebug\supTextDebugCode\textDebugger.py", line 360, in <module>
debugger.run_baselines()
File "E:\supTextDebug\supTextDebugCode\textDebugger.py", line 299, in run_baselines
loss.get_loss()
File "E:\supTextDebug\supTextDebugCode\lossbased.py", line 26, in get_loss
outputs = model(**batch, labels=labels)
File "D:\anaconda\envs\supTextDebug\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\anaconda\envs\supTextDebug\lib\site-packages\transformers\models\bart\modeling_bart.py", line 1724, in forward
decoder_input_ids = shift_tokens_right(
File "D:\anaconda\envs\supTextDebug\lib\site-packages\transformers\models\bart\modeling_bart.py", line 104, in shift_tokens_right
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
File "D:\anaconda\envs\supTextDebug\lib\site-packages\transformers\tokenization_utils_base.py", line 268, in __getattr__
raise AttributeError
AttributeError
解决方案:
错误行:outputs = model(**batch, labels=labels)
直接使用模型的forward方法,而不是将所有参数传递给 model:
tokenizer = AutoTokenizer.from_pretrained("philschmid/bart-large-cnn-samsum")
model = AutoModelForSeq2SeqLM.from_pretrained("philschmid/bart-large-cnn-samsum")
model.eval()
model.to("cuda")
loss = 0
for i in range(len(self.dataset)):
batch = tokenizer([self.dataset[i]["source"]], return_tensors="pt", padding=True).to("cuda")
labels = tokenizer([self.dataset[i]["target"]], return_tensors="pt", padding=True).to("cuda")
print(batch)
outputs = model(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"], labels=labels["input_ids"])
print(outputs.loss.item())































![sql注入中的异或注入--sql注入加强版(盲注)[极客大挑战 2019]FinalSQL](https://img-blog.csdnimg.cn/direct/cc2abf09f65e4496b955dca6863b0c04.png)