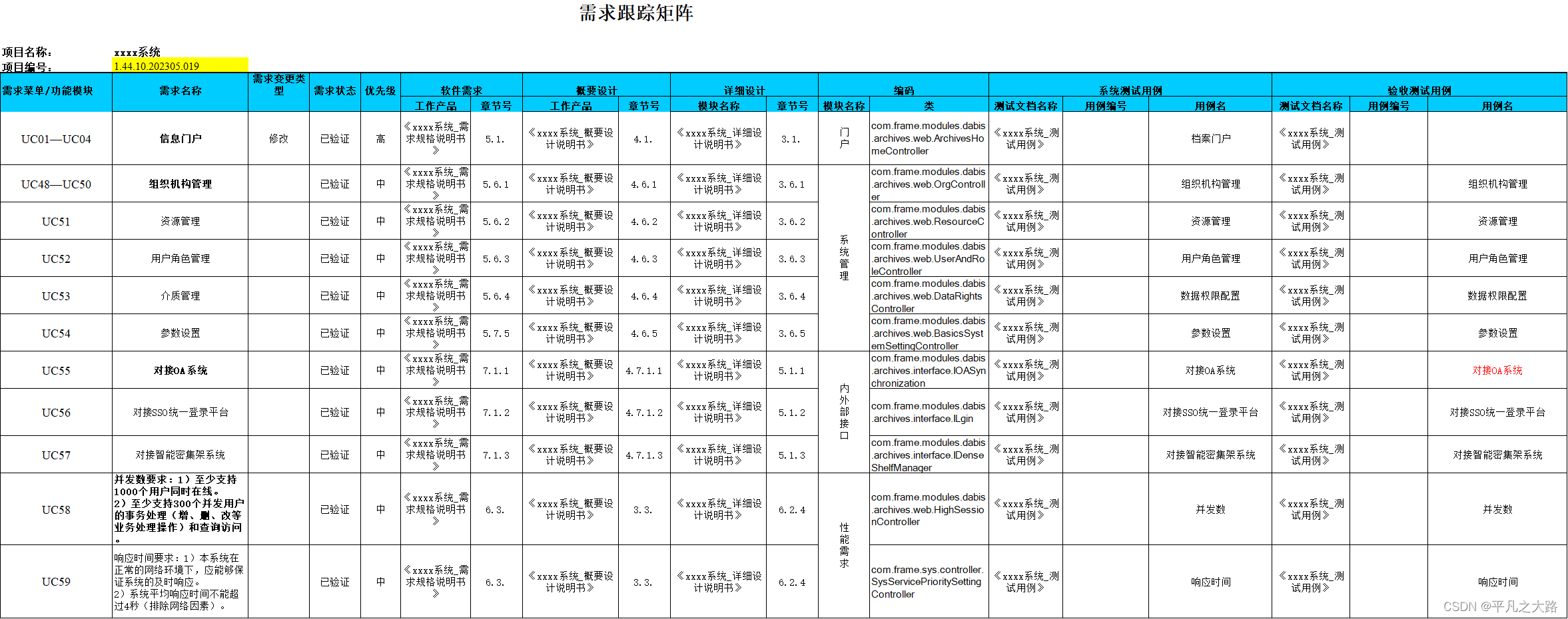
spark-sql读写同一张表,报错Cannot overwrite a path that is also being read from
1. 增加checkpoint,设置检查点阻断血缘关系
sparkSession.sparkContext.setCheckpointDir("/tmp/spark/job/OrderOnlineSparkJob")
val oldOneIdTagSql = "select one_id,tag from aaa "
val oldOneIdTagDf = sparkSession.sql(oldOneIdTagSql).checkpoint()
2. 清理checkpoint产生的文件
2.1 更改配置文件开启checkpoint文件清理
spark.cleaner.referenceTracking.cleanCheckpoints = true
2.2 可以通过getCheckpointDir.get方式读取到checkpoint的文件地址。从而自定义清理操作
val checkPointFile = sparkSession.sparkContext.getCheckpointDir.get
HdfsUtils.delete(fileSystem,checkPointFile,true)