LLMs 在各种任务上展现出令人惊叹的能力,但是庞大的模型尺寸和对算力的巨大需求对模型的部署也提出了挑战。目前 4-bit 的 PTQ 权重量化在 LLMs 上已经取得了一些成绩,相对 FP16 内存占用减少近 75%,但是在精度上仍有较大的损失。我们在论文《SmoothQuant+:Smooth LLM Weight Quantization and Acceleration in 4-bit》中,提出了 SmoothQuant+,一种无需训练的、精度无损的、通用高效的 4-bit 权重 PTQ 量化方法。基于权重量化的误差被激活的离群点所放大这一事实,SmoothQuant+ 在量化之前按通道平滑激活的离群点(outliers),同时为了数学上的等效性调整对应的权重,然后再对线性层的权重进行 group-wise 4-bit 量化。我们把 SmoothQuant+ 融入了 vLLM 框架,一个先进的专门为 LLMs 开发的高吞吐量推理引擎,并为其配置了高效的 W4A16 CUDA 计算核,使得 vLLM 能够无缝支持 SmoothQuant+ 4-bit 量化。我们证明了通过 SmoothQuant+,Code Llama-34B 模型能够在一个A100 40GB GPU 上完成量化、部署,在精度无损的同时,吞吐量是双卡 A100 40GB 部署的 FP16 模型的 1.9-4.0 倍,Latency Per Token 只有双卡 A100 40GB 部署的 FP16 模型的 68%。这是我们所知的最好的 4-bit 权重量化。

论文地址:
https://arxiv.org/abs/2312.03788。
下面让我们来看看这篇论文吧。
量化前,先 Smooth LLMs
当 LLMs 的模型参数量超过 6.7B 的时候,激活中会成片地出现大幅值的离群点(outliers),它们会导致量化误差增大,精度下降。针对这个问题,LLM.int8() 采用了混合精度分解计算的方式(离群点和其对应的权重使用 FP16 计算,其他量化成 INT8 后计算)。这些激活上的离群点会出现在几乎所有的 token 上但是局限于隐层维度上的固定的 channel 中;给定一个 token,不同 channels 间的方差会很大,但是对于不同的 token,相同 channel 内的方差很小。考虑到激活中的这些离群点通常是其他激活值的 100 倍,这使得激活量化变得困难。于是 SmoothQuant 提出了一种数学上等价的 per-channel scaling transformation,目的是可以平滑不同 channel 的激活和其对应的权重,使得模型对量化更加友好。我们观察到,权重的幅度分布均匀,按道理应该容易量化,可是无论是 GPTQ 还是 AWQ,OWQ,在进行 4-bit 权重量化时,都有较大的精度损失。同时我们也观察到激活中的离群点总是出现在一小部分固定的 channels 中。如果一个 channel 有一个异常点,它持续地出现在所有 token 中。这些离群点的幅度往往是其他激活幅度的100倍。量化损失的计算公式如下:
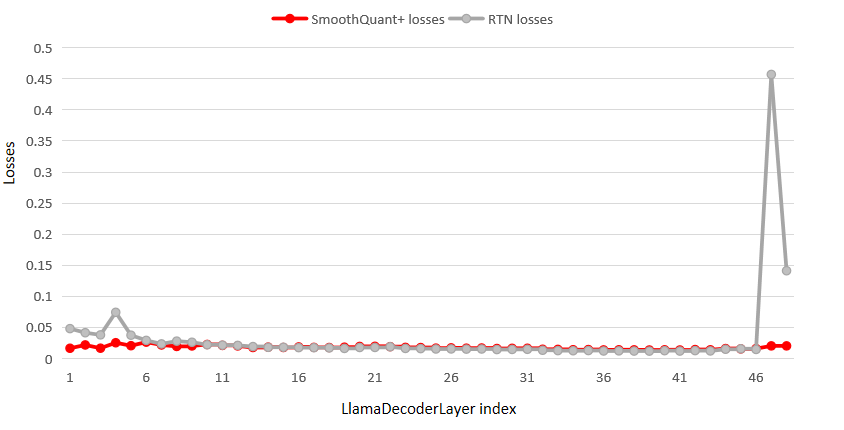
从公式可以看出,量化损失不仅和权重有关,和激活也有关,他们是相乘的关系。我们认为权重量化的误差被激活的离群点放大了,通过平滑激活离群点,同时对应调整权重,能够大大降低量化误差。下图是对 Code Llama-7B 的每一个 LlamaDecoderLayer 单独量化的量化损失对比。从图中可以看出,模型在量化前使用 smooth 技术能削平损失的尖峰,显著减小量化损失。
基于以上考虑,我们建议像 SmoothQuant 那样对激活进行 smooth,按通道除以 smoothing factor。为了保持线性层数学上的等价性,以相反的方式对权重进行对应调整:
其中, 表示激活的输入通道数。平滑时,选取合适的smoothing strength 至关重要。我们采用网格搜索的方法,在 0 和 1 之间以 0.05 为间隔,搜索使整个模型量化误差最小的 smoothing strength ,在此过程中,使用合适的小批量数据作为校准数据集。
在 vLLM 下进行 4-bit 权重量化
我们在 vLLM 上实现了高效的 4-bit group-wise 量化。实现方式如下:直接加载 smooth 后的 FP16 的模型到 vLLM 上。模型首先加载到内存中,然后在把模型从 CPU 迁移到 GPU 的过程中,对线性层权重进行 4-bit group-wise 量化,这样最终加载到 GPU 显存中的就是一个已对线性层的权重进行 4-bit 量化的模型。推理时,SmoothQuant+ 针对量化模型的线性层,使用了高效的 W4A16 CUDA kernel,对Code Llama-34B模型,单卡(A100 40GB )部署 4-bit 量化,无论是吞吐量还是延时,在性能上全面超越双卡部署 FP16 模型。
SmoothQuant+ 的精度与性能
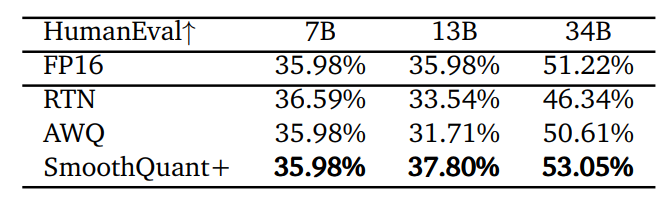
我们专注于研究 4-bit 权重量化对 Code Llama 系列模型的影响,因为它的模型结构与 LLaMA 类模型的结构大致相同,除了注意力层实现的时候,有微小的改变。后续代码生成能力较好的 WizardCoder 也是在 Code Llama 模型的基础上精调而成的。我们评估了 Code Llama 系列模型 在 FP16 下、RTN、AWQ、SmoothQuant+ 下的 Python 代码生成能力。SmoothQuant+ 在 HumanEval-Python 下,完美地实现了 4-bit 权重的无损量化,对Code Llama-34B 模型而言,精度不仅比 AWQ 高 2.44%,甚至比不量化的 FP16 模型还要高 1.83%。AWQ 在 vLLM 框架下,并不能实现 4-bit 权重的无损量化,如对于 Code Llama-13B 模型,AWQ 比 FP16 模型精度低 4.27%,即使是 34B 模型,精度也要低 0.61%。
在多语言上,SmoothQuant+ 也表现优秀,我们利用 BabelCode 进行多语言的评估。从下表可见,对于Code Llama-34B, SmoothQuant+ 在整体上比 FP16 的模型高了 0.6%,特别在 JAVA 上高了5.59%,在 Python 上高了3.05%。

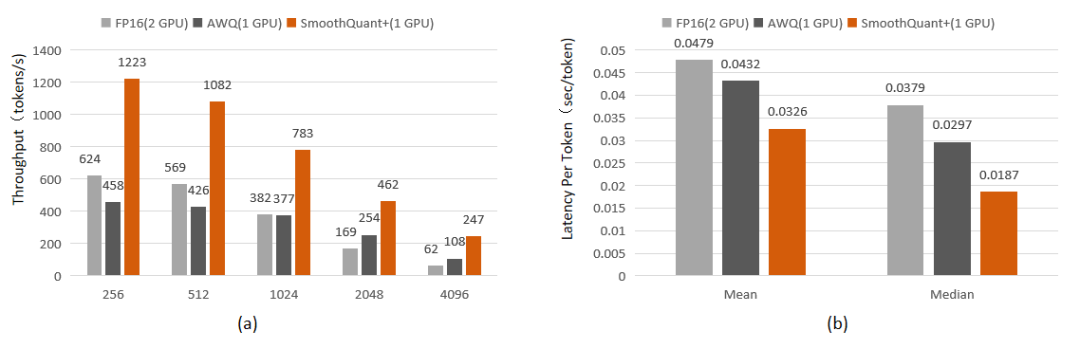
我们使用泊松分布方式持续发送推理请求,通过设定不同的输入输出长度,统计模型在各种给定上下文长度下的极限吞吐量,见下图 (a),同时以线上环境真实访问流量作为测试数据进行模拟测试,用户请求的内容、请求间的间隔时长均和线上保持一致,统计单个 token 的时延,见下图 (b)。从图可以看出一个 NVIDIA A100 40GB 部署的 AWQ 不论是在吞吐量还是时延上,性能都弱于 2 个 NVIDIA A100-40G 部署的 FP16 模型。而 vLLM 实现的SmoothQuant+,可以把 CodeLlama-34B 模型部署在一个 NVIDIA A100 40GB 的GPU上,吞吐量是部署在 2 个 NVIDIA A100 40GB GPU上的FP16 模型的 1.9-4.0 倍,latency 只有其 68%。
SmoothQuant+ 与 SmoothQuant、AWQ
与 SmoothQuant+ 最接近的工作是 SmoothQuant 和 AWQ 。SmoothQuant+ 不论是精度还是生成模型的推理效率都优于 AWQ,见下表。精度上, 表示无损,推理效率上, 表示量化后在一个 A100 40GB 上部署的模型的吞吐量和时延要优于部署在 2 个 A100 40GB上的 FP16模型。SmoothQuant+ 采用了和 SmoothQuant 一样的对模型的激活和权重进行平滑的方式,但是出发点不同。SmoothQuant+ 在对 LLMs 的 4-bit 量化中,先 smooth 模型,再量化权重。在这个过程中,对激活不做量化,但是仍然要 smooth 激活,主要是因为 LLMs 中激活的离群点造成了较大量化误差,平滑激活能减小量化误差。SmoothQuant 在 smooth 模型后,需要根据不同的量化级别,对激活和权重都进行 8-bit 量化,其中权重只进行了per-tensor量化。我们认为 SmoothQuant+ 是对 SmoothQuant 的进一步扩展,是只对权重进行的 4-bit group-wise 量化。AWQ 和 SmoothQuant+ 一样进行4-bit权重量化,也对激活和权重进行了平滑,但平滑的目的不同造成了平滑的具体实现不同。AWQ 平滑激活的目的是保护权重中的 salient weights,在选择 importance factor 时,选用了平均值而非最大值。AWQ 在搜索超参时是按层进行的,设定的目标函数是指定层的量化误差最小。AWQ 在计算这个量化误差时,使用了未量化时每一层的输入作为激励,没有考虑前面层的量化对后面层的影响从而造成误差累积问题。我们认为这样按层搜索超参而不考虑误差累积是不合适的,这会造成最后模型量化精度的降低。而且按线性层搜索,随着模型规模的增大,线性层增多,搜索的时间会显著增加。SmoothQuant+ 是对整个模型进行搜索,搜索过程迅速,例如对于 Code Llama-34B 模型,搜索时间仅仅是 AWQ 的 1/5。

好了,有关 SmoothQuant+ 的介绍就到这里了。了解更多内容,请参考原论文。
期待大家继续支持和关注 Adlik 的 Github 仓库。


![[<span style='color:red;'>大</span><span style='color:red;'>模型</span>]<span style='color:red;'>大</span><span style='color:red;'>语言</span><span style='color:red;'>模型</span><span style='color:red;'>量化</span>方法对比:GPTQ、GGUF、AWQ](https://img-blog.csdnimg.cn/direct/8eca778e9ca24d0ab78412ae00555bbd.png)