文章目录
前言

Universal Evasion Attacks on Summarization Scoring(2211)
0、论文摘要
摘要的自动评分很重要,因为它指导摘要生成器的开发。评分也很复杂,因为它涉及多个方面,例如流畅性、语法,甚至与源文本的文本蕴涵。然而,总结评分尚未被视为机器学习任务来研究其准确性和鲁棒性。
在本研究中,我们将自动评分置于回归机器学习任务的背景下,并执行规避攻击以探索其鲁棒性。攻击系统从每个输入中预测一个非摘要字符串,这些非摘要字符串通过优秀的摘要器在最流行的指标上获得有竞争力的分数:ROUGE、METEOR 和 BERTScore。攻击系统还在 ROUGE-1 和 ROUGE-L 上“优于”最先进的摘要方法,并在 METEOR 上得分第二高。
此外,还观察到了 BERTScore 后门:简单的触发器可以比任何自动摘要方法得分更高。这项工作中的规避攻击表明当前评分系统在系统级别的鲁棒性较低。
我们希望我们对这些拟议攻击的强调将有助于总结分数的制定。
一、Introduction
1.1目标问题
一个长期存在的悖论一直困扰着自动摘要的任务。一方面,大约20年来,还没有任何自动评分可作为证明摘要质量的充分或必要条件,例如充分性、语法性、衔接性、保真度等。另一方面,同期研究更多地使用一个或多个自动评分来认可摘要器是最先进的。超过 90% 的语言生成神经模型工作选择自动评分作为主要基础,其中约一半仅依赖于自动评分(van der Lee et al., 2021)。然而,这些评分方法被发现不足(Novikova 等人,2017)、过于简单化(van der Lee 等人,2021)、难以解释(Sai 等人,2022)、与人类评估摘要的方式不一致(Rankel)等,2013;Böhm 等,2019),甚至相互矛盾(Gehrmann 等,2021;Bhandari 等,2020)。
为什么我们必须面对这个悖论?当前的工作可能并不表明通过自动评分评估的总结器实际上是无效的。然而,针对有缺陷的评估进行优化(Gehrmann et al., 2021; Peyrard et al., 2017),直接或间接地最终会损害自动摘要的发展(Narayan et al., 2018; Kryscinski et al., 2019; Paulus et al., 2019)。等,2018)。最可能的缺点之一是快捷学习(表面学习,Geirhos 等人,2020),其中总结模型可能无法生成具有更广泛接受的质量(例如充分性)的文本和真实性,而是令人愉悦的分数。在这里,我们引用并改编1 Geirhos 等人的假设故事。
“爱丽丝热爱文学。一直都是,也许永远都会。然而,此时此刻,她正在咒骂这个学科:在花了几周时间沉浸在莎士比亚的《暴风雨》的世界中之后,她现在面临着一些考试问题,这些问题(在她看来)既乏味又困难。“米兰公爵被致辞了多少次”……爱丽丝注意到坐在她面前的鲍勃似乎表现得很好。所有的人中,鲍勃都曾有过这样的经历。只是吹嘘他昨晚如何死记硬背了整本书的章节……”
根据 Geirhos 等人的说法,鲍勃可能会取得更好的成绩,因此被认为是比爱丽丝更好的学生,这是表面学习的一个例子。自动总结的情况也可能如此,我们最终可能会发现预期学习结果与实际学习结果之间存在显着差异(Paulus 等,2018)。为了避免误入歧途,确保目标正确非常重要。
1.2相关的尝试
除了理解正确论证的重要性之外,我们还需要知道是什么导致了这些潜在有用的总结者的论证过程的谬误。目前存在三种并不相互排斥的主流猜测。 (1) 从提取摘要到抽象摘要的转变(Kryscinski et al., 2019)可能被低估了。例如,流行的评分ROUGE(Lin,2004)最初用于判断从文档中选择的句子的排名。由于句子完整性的限制,生成的摘要总是能够流畅且不失真,除非有时涉及回指。然而,当涉及到自由形式语言生成时,不再保证句子完整性,但仍继续使用该度量。 (2) 许多指标虽然在判断个体摘要方面存在缺陷,但在系统层面通常是有意义的(Reiter,2018;Gehrmann 等人,2021;Böhm 等人,2019)。换句话说,人们可能认为很少有摘要系统能够始终输出质量差但得分高的字符串。 (3) 研究人员尚未弄清楚人类如何解释或理解文本(van der Lee et al., 2021; Gehrmann et al., 2021; Schluter, 2017),因此关于 1We 的决定强调了适应。摘要的准确程度因人而异,更不用说自动评分了。事实上,自动评分更多的是一个自然语言理解(NLU)任务,一个远未解决的任务。从这个角度来看,自动评分本身就具有相当的挑战性。
尽管如此,当前的工作并不是提倡(当然也不是贬低)人类评价。相反,我们认为自动评分本身不仅仅是自动摘要的子模块,而且自动评分是一个独立的系统,需要研究其自身的准确性和鲁棒性。主要原因是 NLU 显然需要表征摘要质量,例如,通过语义相似性来确定充分性(Morris,2020),或通过文本蕴涵(Dagan 等人,2006)来确定保真度。此外,摘要评分类似于自动论文评分(AES),这是一项已有 50 年历史的任务,用于衡量书面文本的语法性、衔接性、相关性等(Ke 和 Ng,2019)。此外,自动评分的最新进展也很好地支持了这一论点。自动评分正在逐渐从测量 N-gram 重叠的成熟指标(BLEU (Papineni et al., 2002)、ROUGE (Lin, 2004)、METEOR (Banerjee and Lavie, 2005) 等)过渡到旨在衡量 N-gram 重叠的新兴指标。通过预训练的神经模型计算语义相似度(BERTScore (Zhang et al., 2019b)、MoverScore (Zhao et al., 2019)、BLEURT (Sellam et al., 2020) 等)这些新兴分数表现出两个特征:独立的机器学习系统通常具有:一是某些可以针对人类认知进行微调;另一个是他们仍然有改进的空间,仍然需要学习如何匹配人类的评分。
机器学习系统可能会受到攻击。攻击有助于提高其通用性、鲁棒性和可解释性。特别是,逃避攻击是进一步暴露当前自动评分系统弱点的直观方式。规避攻击是对抗性攻击的母任务,其目的是使系统无法正确识别输入,因此需要防御某些暴露的漏洞。
1.3本文贡献
在这项工作中,我们试图回答这样一个问题:当前代表性的自动评分系统在系统层面真的运行良好吗?说它们在系统层面工作得不好有多难?
总之,我们的贡献如下:
我们是第一个将自动摘要评分视为 NLU 回归任务并进行规避攻击的人。
• 我们是第一个对NLP 回归模型进行通用、有针对性的攻击的公司。
• 我们的规避攻击表明,同时欺骗三个最流行的自动评分系统并不困难。 • 所提出的攻击可以直接应用于测试新兴的评分系统。
二.相关工作
三.本文方法
通用规避攻击
我们为个人评分系统开发了通用规避攻击,并确保组合攻击者可以同时欺骗 ROUGE、METEOR 和 BERTScore。它由两部分组成,ROUGE 上的白盒攻击者和 BERTScore 上基于遗传算法的黑盒通用触发搜索算法。 METEOR 可以直接被 ROUGE 设计的攻击者攻击。连接黑盒和白盒攻击者的输出字符串会产生唯一的通用规避攻击字符串。
3.1 问题表述
总结就是条件生成。执行此条件生成的系统 σ 接受输入文本 (a) 并输出文本 (s ^),即 s ^ = σ(a)。在单引用场景中,有一个黄金参考序列 sref。摘要评分系统 γ 计算序列 s ^ 和 sref 之间的“接近度”。为了使评分系统足以证明一个好的总结者是正确的,应始终避免以下条件:γ(σfar bad(a), sref) > γ(σbetter(a), sref)。 (1)确实,满足上述条件就是我们的攻击任务。在本节中,我们将详细介绍如何找到合适的 σfar bad。
3.2 对 ROUGE 和 METEOR 的白盒输入不可知攻击
一般来说,攻击 ROUGE 或 METEOR 只能通过白盒设置来完成,因为即使是最新手的攻击者(开发人员)也会理解这两个公式如何计算两个字符串之间的重叠。我们选择使用最明显的不良系统输出(断句)来进行 ROUGE 游戏,这样就不需要额外的人工评估。相比之下,对于其他游戏方法,例如强化学习(Paulus et al., 2018),即使取得了高分,仍然需要人类评估来衡量文本质量有多差。我们利用令牌分类神经模型和简单的基于规则的排序的混合方法(我们将其称为 σROUGE),因为我们知道 ROUGE 通过硬 N 元语法重叠来比较每对序列 (s1, s2)。在袋代数中,从集合代数(Bertossi et al., 2018)扩展而来,ROUGE 的两个流行变体:ROUGE-N (RN(n, s1, s2), n ∈ Z+) 和 ROUGEL(RL(s1, s2))计算如下:

哪里|·|表示袋的大小,∩表示袋交集,N-grams的袋计算如下:
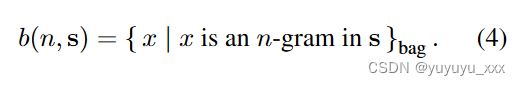
在我们的混合方法中,第一步是神经模型尝试在给定任何输入 a 和相应的目标 sref 的情况下预测目标的词袋 b(1, sref)。然后,预测包中的单词根据它们在输入 a 中的出现情况进行排序。形式上,神经模型 (φ) 的训练为:
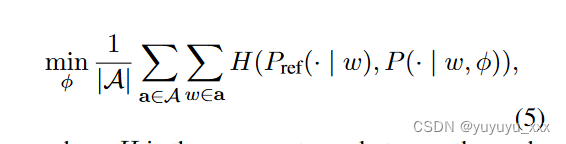
其中 H 是参考字数的概率分布和预测字数的概率分布之间的交叉熵。一种近似是模型尝试预测 b(1, sref) ∩ b(1, a)。根据经验,参考摘要中的四分之三的单词可以在其相应的输入文本中找到。
引用输入文本 (a) 和预测词袋 ( ˆ W ) 来构建序列非常简单,如算法 1 所示。

算法1使用显着词来突出显示a中最长的连续显着子序列,直到W^W中的词被耗尽,或者当每个连续显着序列少于三个词时(C = 3)。
3.3BERTcore 上的黑盒通用触发器搜索
单独为 BERTScore 找到一个更差的 σ 来满足条件 1 是很容易的。单个点(“.”)是所有字符串的模仿者,仿佛是开发者留下的“后门”。我们注意到,在 BERTScore3 的默认设置下,与任何自然句子相比,使用单个点平均可以达到 0.892 左右。这个数字“优于”所有现有的摘要器,使得输出一个点成为一个足够好的 σ 更糟糕的实例。这个例子非常有趣,因为它突出了许多漏洞被忽视的程度,尽管它不能直接与 ROUGE 的攻击者结合起来。直观上,也可能有各种巧妙的方法来攻击 BERTScore,例如为每个字符串添加前缀(Wallace 等人,2019 年;Song 等人,2021 年)。然而,我们在这里选择开发一个系统,可以输出(其中一个)最明显的坏字符串(乱码)以获得高分。 BERTScore 通常被归类为未经训练的神经评分(Sai 等人,2022)。换句话说,其前向计算的一部分(例如,贪婪匹配)是基于规则的,而其余部分(例如,将每个标记嵌入到序列中)则不是。因此,很难合理地“设计”攻击。梯度方法(白盒)或离散优化(黑盒)是优选的。同样,虽然让 BERTScore 生成软预测(Jauregi Unanue 等人,2021)可能会允许攻击白盒设置,我们发现黑盒优化就足够了。受到 BERTScore 中单点后门的启发,我们假设我们可以仅使用非字母数字标记来形成更长的包罗万象的模拟器。这样的模拟器有两个好处:首先,它需要一个小的拟合集,这对于回归模型的有针对性的攻击很重要。我们将看到,一旦模拟器被优化以适合一个自然句子,它也可以模拟几乎任何其他自然句子。需要拟合才能像样模仿的自然句子总数通常少于十个。另一个好处是使用非字母数字令牌不会影响 ROUGE。遗传算法(GA,Holland,2012)用于离散优化所提出的非字母数字字符串。遗传算法是一种受自然选择过程启发的基于搜索的优化技术。遗传算法首先初始化一组候选解决方案,并迭代地使它们朝着更好的解决方案前进。在每次迭代中,GA 使用适应度函数来评估每个候选的质量。高质量的候选人可能会被选择并交叉以产生下一组候选人。新的候选者会发生变异,以确保搜索空间的多样性和更好的探索。将 GA 应用于攻击已显示出在最大化某个分类标签的概率(Alzantot 等人,2018)或两个文本序列之间的语义相似性(Maheshwary 等人,2021)方面的有效性和效率。我们的单一适应度函数如下: ˆsemu = arg min s ˆ −B(s ˆ, sref), (6) 其中 B 代表 BERTScore。至于终止,我们要么使用 -0.88 的阈值,要么使用最多 2000 次迭代。为了使 ˆsemu 适合一组自然句子,我们在每次终止后计算该组中每个句子的 BERTScore。然后我们选择一个合适的 sref 来适合下一轮。我们总是选择具有最低 BERTScore 和当前阶段优化的 ˆsemu 的自然句子(在有限集合中)。然后,我们重复此过程,直到该字符串获得的平均 BERTScore 高于许多信誉良好的摘要者。最后,为了同时游戏 ROUGE 和 BERTScore,我们将 ˆsemu 和输入无关的 σROUGE(a) 连接起来。如果我们将 ˆsemu 中的标记数量设置为大于 512(BERT 的最大序列长度),则 σROUGE(a) 将不会影响 ˆsemu 的有效性,从技术上讲,我们对两者进行博弈。此外,这个串联的字符串也可以玩 METEOR。
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
白盒设置,我们发现黑盒优化就足够了。受到 BERTScore 中单点后门的启发,我们假设我们可以仅使用非字母数字标记来形成更长的包罗万象的模拟器。这样的模拟器有两个好处:首先,它需要一个小的拟合集,这对于回归模型的有针对性的攻击很重要。我们将看到,一旦模拟器被优化以适合一个自然句子,它也可以模拟几乎任何其他自然句子。需要拟合才能像样模仿的自然句子总数通常少于十个。另一个好处是使用非字母数字令牌不会影响 ROUGE。遗传算法(GA,Holland,2012)用于离散优化所提出的非字母数字字符串。遗传算法是一种受自然选择过程启发的基于搜索的优化技术。遗传算法首先初始化一组候选解决方案,并迭代地使它们朝着更好的解决方案前进。在每次迭代中,GA 使用适应度函数来评估每个候选的质量。高质量的候选人可能会被选择并交叉以产生下一组候选人。新的候选者会发生变异,以确保搜索空间的多样性和更好的探索。将 GA 应用于攻击已显示出在最大化某个分类标签的概率(Alzantot 等人,2018)或两个文本序列之间的语义相似性(Maheshwary 等人,2021)方面的有效性和效率。我们的单一适应度函数如下: ˆsemu = arg min s ˆ −B(s ˆ, sref), (6) 其中 B 代表 BERTScore。至于终止,我们要么使用 -0.88 的阈值,要么使用最多 2000 次迭代。为了使 ˆsemu 适合一组自然句子,我们在每次终止后计算该组中每个句子的 BERTScore。然后我们选择一个合适的 sref 来适合下一轮。我们总是选择具有最低 BERTScore 和当前阶段优化的 ˆsemu 的自然句子(在有限集合中)。然后,我们重复此过程,直到该字符串获得的平均 BERTScore 高于许多信誉良好的摘要者。最后,为了同时游戏 ROUGE 和 BERTScore,我们将 ˆsemu 和输入无关的 σROUGE(a) 连接起来。如果我们将 ˆsemu 中的标记数量设置为大于 512(BERT 的最大序列长度),则 σROUGE(a) 将不会影响 ˆsemu 的有效性,从技术上讲,我们对两者进行博弈。此外,这个串联的字符串也可以玩 METEOR。
4.4评估指标
4.5 实验结果
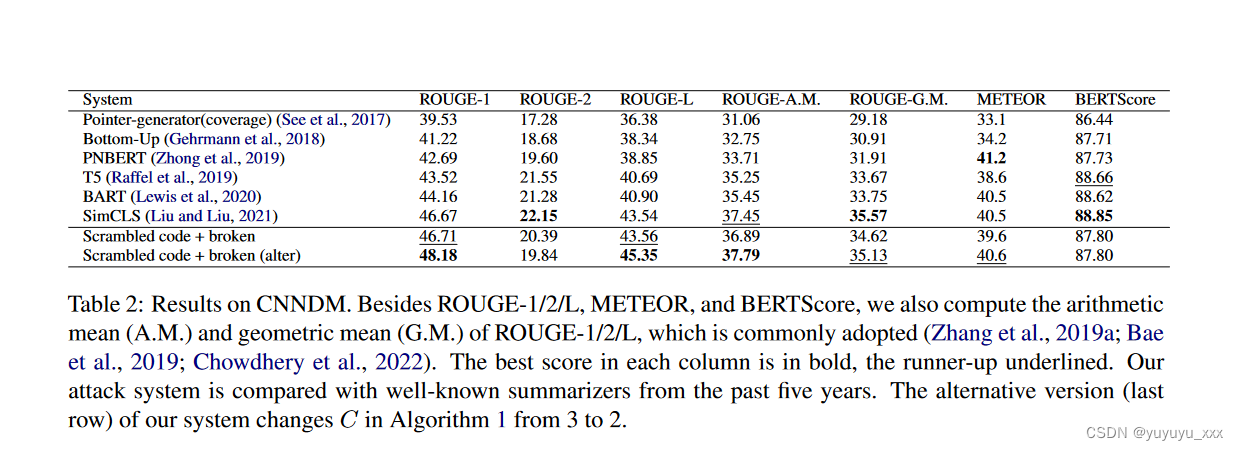
至于ROUGE-2和BERTScore,威胁模型的得分高于其他基于BERT的摘要算法4。总体而言,我们通过对 ROUGE5、METEOR 和 BERTScore 上的三个相对排名进行平均来对系统进行排名;我们的威胁模型获得亚军 (2.7),紧随 SimCLS (1.7) 并领先于 BART (3.3)。这表明,在系统级别,即使是主流指标的组合在证明摘要器的卓越性方面也是值得怀疑的。这些结果揭示了流行指标的稳健性较低,以及某些模型如何通过较差的摘要获得高分。例如,我们的威胁模型能够使用通用但轻量级的模型来掌握 ROUGE-1/2/L 的本质,这比总结算法需要更少的运行时间。模型和词序的训练策略很简单。毫不奇怪,它的输出文本与人类可理解的“摘要”并不相似(表 1)。
五 总结
我们在此回答这个问题:很容易创建一个使用更差的文本在 ROUGE、METEOR 和 BERTScore 上同时获得高分的威胁系统。在这项工作中,我们将自动评分视为回归机器学习任务,并进行规避攻击以探测其鲁棒性或可靠性。我们的攻击者的分数与顶级摘要器竞争,实际上输出非摘要字符串。这进一步表明,当前的主流评分系统并不是支持摘要者合理性的充分条件,因为它们忽略了计算句子邻近度所需的语言信息。无论有意还是无意,针对有缺陷的分数进行优化可能会妨碍算法进行良好的总结。现有总结算法的实际有效性不受此影响,因为它们中的大多数都优化了最大似然估计。根据暴露的漏洞,有必要对衡量摘要质量和句子相似性的评分系统进行仔细修复。
局限
我们只攻击了摘要文献中已经采用的三种最广泛采用的评分方案。然而,还有像 BLEURT (Sellam et al., 2020) 这样的新兴评分方案,我们将在未来的工作中进行研究。