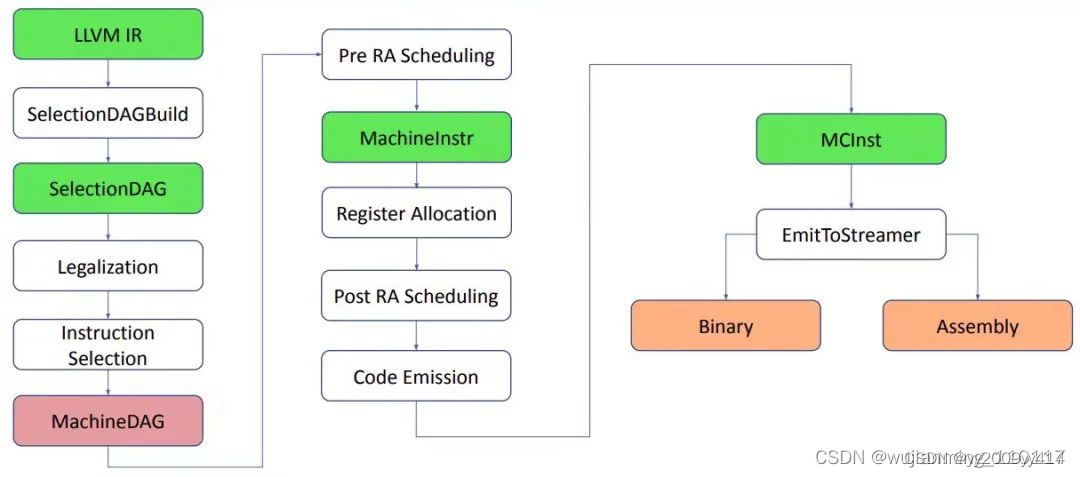
匹配模式
每个目标都有个叫<Target_Name>DAGToDAGISel的SelectionDAGISel子类.它通过实现子类的Select方法来选指.
如SPARC中的SparcDAGToDAGISel::Select()(见lib/Target/Sparc/SparcISelDAGToDAG.cpp文件).接收要匹配的SDNode参数,返回代表物理指令的SDNode值;否则出错.
Select()方法允许两种方式来匹配物理指令.最直接方式是调用从TableGen模式产生的匹配代码,如下面列表中的步骤一.
然而,模式可能表达不够清楚,就不能处理一些指令的奇怪行为.此时,必须在``中实现自定义的C++匹配逻辑,如下面列表中的步骤二.
下面详细介绍这两个方式:
1,Select()方法调用SelectCode().TableGen为每个目标生成SelectCode()方法,在此代码中,TableGen还生成映射ISD和<Target>ISD为物理指令节点的MatcherTable.
该匹配器表是从.td文件(一般为<Target>InstrInfo.td)中的指令定义生成的.SelectCode()方法以调用目标无关的,用目标匹配器表匹配节点的SelectCodeCommon()结束.
TableGen有一个专门的选指后端,用来生成这些方法和表:
$ cd <llvm_source>/lib/Target/Sparc
$ llvm-tblgen -gen-dag-isel Sparc.td -I ../../../include
对每个目标,在生成<build_dir>/lib/Target/<Target>/<Target>GenDAGISel.inc名字的C++文件中有相同输出;
如,对SPARC中,可在<build_dir>/lib/Target/Sparc/SparcGenDAGISel.inc文件中获得这些方法和表.
2,在SelectCode调用前,Select()方法中提供自定义匹配代码.如,i32节点的ISD::MULHU执行两个i32的乘,产生一个i64结果,并返回高i32部分.
在32位SPARC上,SP::UMULrr乘法指令,在要求SP::RDY指令读它的Y特殊寄存器中返回高位部分.TableGen无法表达该逻辑,但是可用下面代码解决:
case ISD::MULHU: {
SDValue MulLHS = N->getOperand(0);
SDValue MulRHS = N->getOperand(1);
SDNode *Mul = CurDAG->getMachineNode(SP::UMULrr, dl, MVT::i32, MVT::Glue, MulLHS, MulRHS);
return CurDAG->SelectNodeTo(N, SP::RDY, MVT::i32, SDValue(Mul, 1));
}
这里,N是待匹配的SDNode参数,这里,N等于ISD::MULHU.因为在该case语句前,已仔细检查,这里生成SPARC相关的操作码来替换ISD::MULHU.
为此,调用CurDAG->getMachineNode()用SP::UMULrr物理指令创建节点.
接着,用CurDAG->SelectNodeTo(),创建一个SP::RDY指令节点,并将指向ISD::MULHU的结果的所有use(引用)改变为指向SP::RDY的结果.
前面的C++代码片是lib/Target/Sparc/SparcISelDAGToDAG.cpp中的代码的简化版本.
可视化选指过程
多个llc的选项,可在不同的选指过程可视化SelectionDAG.如果使用了任意一个这些选项,llc类似前面,生成一个.dot图,但是要用dot程序来显示它,或用dotty编辑它.可在www.graphviz.org的Graphviz包中找到它们.
下图按执行顺序列举了每个选项:
llc选项 |
过程 |
|---|---|
-view-dag-combine1-dags |
DAG合并1之前 |
-view-legalize-types-dags |
合法化类型前 |
-view-dag-combine-lt-dags |
合法化类型2后,组合DAG前 |
-view-legalize-dags |
合法化前 |
-view-dag-combine2-dags |
组合DAG2前 |
-view-isel-dags |
选指前 |
-view-sched-dags |
选指后,调度指令前 |
快速选指
LLVM还支持可选的快速选指(FastISelclass,在<llvm_source>/lib/CodeGen/SelectionDAG/FastISel.cpp文件).
快速选指目标是以损失代码质量为代价,快速生成代码,它适合-O0优化级编译.通过省略复杂的合并和降级逻辑,提速编译.
对简单操作,可用TableGen描述,但更复杂的指令匹配需要目标相关代码来处理.
注意,-O0管线编译还用到了快速但次优化的分配寄存器器和调度器,以代码质量换取编译速度.
调度
选指之后,SelectionDAG结构有代表处理器直接支持它们的物理指令的节点.下个阶段是在SelectionDAG节点(SDNode)上工作的前分配寄存器调度器.
有几个不同的待选调度器,它们都是ScheduleDAGSDNodes的子类(见<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGSDNodes.cpp文件).
在llc工具中,可通过-pre-RA-sched=<scheduler>选项选择调度器类型.可能的<scheduler>值如下:
1,list-ilp,list-hybrid,source,和list-burr:这些选项指定由ScheduleDAGRRListclass实现(见<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGRRList.cpp文件)的列表调度算法.
2,fast:ScheduleDAGFastclass(<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGFast.cpp)实现了个次优但快速的调度器.
3,view-td:一个由ScheduleDAGVLIWclass实现(见文件<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGVLIW.cpp)的VLIW相关的调度器.
default选项为目标选择预定义的最佳调度器,而linearize选项不调度.可获得的调度器可使用指令行程表和风险识别器信息,来更好调度指令.
注意,生成代码中有三个不同调度器:两个在分配寄存器之前,一个在分配寄存器后.第一个在SelectionDAG节点上工作,而其它两个在机器指令上工作.
指令行程表
有些目标提供了表示指令延迟和硬件管线信息的指令行程表.在调度策略时,调度器用这些属性来最大化吞吐量,避免性能受损.
在每个目标目录中的一般叫<Target>Schedule.td(如X86Schedule.td)的TableGen文件中保存这些信息.
如下在<llvm_source>/include/llvm/Target/TargetItinerary.td,LLVM提供了ProcessorItineraries的TableGen类:
class ProcessorItineraries<list<FuncUnit> fu, list<ByPass> bp,
list<InstrItinData> iid> {
...
}
目标可能为一个芯片或处理器族定义处理器行程表.要描述它们,目标必须提供(FuncUnit)函数单元列表,管线支路(ByPass),和(InstrItinData)指令行程数据.
如,如下,在<llvm_source>/lib/Target/ARM/ARMScheduleA8.td中,为ARMCortexA8指令的行程表.
def CortexA8Itineraries : ProcessorItineraries<
[A8_Pipe0, A8_Pipe1, A8_LSPipe, A8_NPipe, A8_NLSPipe],
[], [
...
InstrItinData<IIC_iALUi ,[InstrStage<1, [A8_Pipe0, A8_Pipe1]>], [2, 2]>,
...
]>;
这里,没有看到(ByPass)支路.但看到了该处理器的(A8_Pipe0,A8_Pipe1等)函数单元列表,及IIC_iALUi类型的指令行程数据.
该类型是形如reg=reg+immediate的二元运算指令的类,如ADDri和SUBri指令.
如InstrStage<1,[A8_Pipe0,A8_Pipe1]定义的那样,这些指令花一个机器时钟周期,以完成A8_Pipe0和A8_Pipe1函数单元.
接着,[2,2]列表表示发射指令后每个操作数读取或定义所用的时钟周期.此处,(index0)目标寄存器和(index1)源寄存器都在2个时钟周期后可用.
检测风险
风险识别器用处理器指令行程表信息计算风险.ScheduleHazardRecognizer类为风险识别器实现提供了接口,而它的子类实现了LLVM默认的记分风险识别器(见<llvm_source>/lib/CodeGen/ScoreboardHazardRecognizer.cpp文件).
允许目标提供自己的识别器.这是必需的,因为TableGen可能无法表达具体约束,这时必须提供自定义实现.
如,ARM和PowerPC都提供了ScoreboardHazardRecognizer子类.
调度单元
在分配寄存器前后,运行调度器.然而,只有前者可使用SDNode指令表示,而后者使用MachineInstr类.
为了兼顾SDNode和MachineInstr,SUnit类(见文件<llvm_source>/include/llvm/CodeGen/ScheduleDAG.h)调度指令时按单元抽象了底层指令表示.llc工具可用-view-sunit-dags选项输出调度单元.
机器指令
在在<llvm_source>/include/llvm/CodeGen/MachineInstr.h定义的MachineInstr类(简称MI)给出的指令表示上分配寄存器.
在调度指令后,会运行转换SDNode格式为MachineInstr格式的InstrEmitter趟.如名,该表示比IR指令更接近实际目标指令.
与SDNode格式及其DAG形式不同,MI格式是程序的三地址表示,即为指令序列而不是DAG,这让编译器可高效地表达具体调度决定,即决定每个指令的顺序.
每个MI有一个(opcode)操作码数字和几个操作数,操作码只对具体后端有意义.
用llc的-print-machineinstrs选项,可输出所有注册的趟之后的机器指令,或用-print-machineinstrs=<趟名>选项输出指定趟后的机器指令.
从LLVM源码中查找这些趟的名字.为此,进入LLVM源码目录,运行grep查找趟注册名字时常用到的宏:
$ grep -r INITIALIZE_PASS_BEGIN * CodeGen/
PHIElimination.cpp:INITIALIZE_PASS_BEGIN(PHIElimination, "phi-node-elimination"
(...)
如,看下面sum.bc的每个趟之后的SPARC机器指令:
$ llc -march=sparc -print-machineinstrs sum.bc
Function Live Ins: %I0 in %vreg0, %I1 in %vreg1
BB#0: derived from LLVM BB %entry Live Ins: %I0 %I1
%vreg1<def> = COPY %I1; IntRegs: %vreg1
%vreg0<def> = COPY %I0; IntRegs: %vreg0
%vreg2<def> = ADDrr %vreg1, %vreg0; IntRegs: %vreg2, %vreg1, %vreg0
%I0<def> = COPY %vreg2; IntRegs: %vreg2
RETL 8, %I0<imp-use>
MI包含指令的重要元信息:它存储使用和定义的寄存器,区分寄存器和内存操作数(及其它类型),存储指令类型(分支,返回,调用,结束等),预测运算是否可交换,等等.
在像MI此种低级层次,保存这些信息很重要,因为在InstrEmitter后,发射代码前,运行的趟,要根据这些字段来分析.
分配寄存器
分配寄存器基本任务是,转换无限数量的虚寄存器为有限的物理寄存器.因为目标的物理寄存器数量有限,会把有些虚寄存器调度到内存位置,即spill槽.
然而,甚至在分配寄存器前,有些MI代码可能已用到了物理寄存器.当机器指令要写结果到指定的寄存器,或ABI要求时,就会这样.
对此,分配寄存器器承认先前分配行为,在此基础上,分配其余物理寄存器给剩余虚寄存器.
LLVM分配寄存器器的另一个重要任务是解构IR的SSA形式.直到此时,机器指令可能还包含从原始LLVMIR复制而来,且为了支持SSA形式而必需的phi指令.
如此,可方便地在SSA之上,实现机器相关优化.然而,传统的转换phi指令为普通指令方法,是用复制指令替换它们.
这样,因为会赋值寄存器并消除冗余的复制操作,不能在分配寄存器后解构SSA.
LLVM有四种可在llc中通过-regalloc=<regalloc_name>选项选择的分配寄存器方法.
可选的<regalloc_name>有:pbqp,greedy,basic,和fast.
1,pbqp:按分区布尔二次规划问题映射分配寄存器.一个PBQP解决方法用来把该问题的结果映射回寄存器.
2,greedy:高效全局(函数级)分配寄存器实现,支持活区间分割及最小化挤出(spill).生动的解释.
3,basic:提供扩展接口的简单分配器.
因此,它为开发新的分配寄存器器提供基础,用作分配寄存器效率的基线.
4,fast:该分配器是局部的(每基本块级),它尽量在寄存器中保存值并重用它们.
把默认分配器映射为四种方法之一,根据当前优化级(-O选项)来选择.
虽然不管选择何种算法,都在单一趟中实现分配器,但是它仍依赖组成分配器框架的其它分析.
分配器框架用到一些趟,这里介绍寄存器合并器和寄存器覆盖.
寄存器合并器
寄存器合并器(coalescer)通过结合中间值(interval)去除冗余的(COPY)复制指令.RegisterCoalescer类实现了为机器函数趟的该合并(见lib/CodeGen/RegisterCoalescer.cpp).
机器函数趟类似IR趟,它在每个函数之上运行,只是处理的不是IR指令,而是MachineInstr指令.
合并时,joinAllIntervals()遍历复制指令列表.joinCopy()方法从机器复制指令创建CoalescerPair实例,并在可能时合并掉复制指令.
中间值(interval)表示程序中的从产生时开始,最终使用为结束的开始和结束的一对点.
看看,在sum.bc位码示例上运行合并器会怎样.
用llc中的regalloc调试选项来查看合并器的调试输出:
$ llc -march=sparc -debug-only=regalloc sum.bc 2>&1 | head -n30
Computing live-in reg-units in ABI blocks.
0B BB#0 I0#0 I1#0
********* INTERVALS **********
I0 [0B,32r:0) [112r,128r:1) 0@0B-phi 1@112r
I1 [0B,16r:0) 0@0B-phi
%vreg0 [32r,48r:0) 0@32r
%vreg1 [16r,96r:0) 0@16r
%vreg2 [80r,96r:0) 0@80r
%vreg3 [96r,112r:0) 0@96r
RegMasks:
********** MACHINEINSTRS **********
# Machine code for function sum: Post SSA
Frame Objects:
fi#0: size=4, align=4, at location[SP]
fi#1: size=4, align=4, at location[SP]
Function Live Ins: $I0 in $vreg0, $I1 in %vreg1
0B BB#0: derived from LLVM BB %entry
Live Ins: %I0 %I1
16B %vreg1<def> = COPY %I1<kill>; IntRegs:%vreg1
32B %vreg0<def> = COPY %I0<kill>; IntRegs:%vreg0
48B STri <fi#0>, 0, %vreg0<kill>; mem:ST4[%a.addr]
IntRegs:%vreg0
64B STri <fi#1>, 0, %vreg1; mem:ST4[%b.addr] IntRegs:$vreg1
80B %vreg2<def> = LDri <fi#0>, 0; mem:LD4[%a.addr]
IntRegs:%vreg2
96B %vreg3<def> = ADDrr %vreg2<kill>, %vreg1<kill>;
IntRegs:%vreg3,%vreg2,%vreg1
112B %I0<def> = COPY %vreg3<kill>; IntRegs:%vreg3
128B RETL 8, %I0<imp-use,kill>
# End machine code for function sum.
注意,可用-debug-only选项,对指定的LLVM趟或组件开启内部调试消息.为了找出要调试的组件,可在LLVM源码目录中运行grep -r "DEBUG_TYPE" *.
DEBUG_TYPE定义激活当前文件调试消息的令牌选项,如在分配寄存器的实现文件中有:
#define DEBUG_TYPE "regalloc"
注意,用2>&1重定向了打印调试信息的标准错误输出到标准输出.然后,用head-n30重定向标准输出(包含调试信息),只打印前面的30行.
这样,控制了显示在终端上的信息量.
先看看**MACHINEINSTRS**输出.这打印了寄存器合并器输入的所有机器指令,如果在phi节点消除趟后,用-print-machine-insts=phi-node-elimination选项输出(在合并器运行前的)机器指令,也会得到相同的内容.
然而,合并器调试器的输出,用索引信息对每条(如0B,16B,32B等)增强机器指令.需要正确解释中间值(interval).
这些索引也叫槽索引,给每个活区间(liverange)赋予不同数字.B字母对应基本块(block),用于活区间进入或离开基本块边界.
此例中,用索引加B打印指令,因为这是默认槽(槽).在中间值中,有个不同表示寄存器的r字母槽,来指示普通寄存器的使用或定义.
阅读机器指令序列,已知道了分配寄存器器父趟(多个小趟的组合)的重要内容:%vreg0,%vreg1,%vreg2,%vreg3都是虚寄存器,要为它们分配物理寄存器.
因此,除了%I0和%I1外,最多用4个已在使用的物理寄存器.按ABI调用约定,要求在这些寄存器中保存函数参数.
因为在合并寄存器前,运行活变量分析趟,代码也标注了活变量信息,表示在哪定义和干掉每个寄存器,这样可清楚哪些寄存器相互冲突,及可同时使用哪些寄存器,并需要在不同物理寄存器中保存.
另一方面,合并器不依赖分配寄存器器结果,它只是查找寄存器副本.
并从寄存器到寄存器的复制,合并器会试用目标寄存器的中间值结合源寄存器,与索引16和32的复制一样,让它们在相同物理寄存器中,从而消除复制指令.
接着是从合并寄存器所依赖的另一个分析的***INTERVALS***消息:由lib/CodeGen/LiveIntervalAnalysis.cpp实现的活中间值分析(不同于活变量分析).
合并器要知道每个虚寄存器所要活的中间值,这样才能发现可合并哪些中间值.如,可从输出中看到,按[32r:48r:0)确定%vreg0虚寄存器的中间值.
即,在32处定义,在48处干掉的该半开放的%vreg0中间值.48r后面的0数字是显示在哪第一次定义该中间值的一个代码,意思是刚好在中间值后面打印:o:32r.
这样,0定义就在索引32位置.然而,如果中间值分裂,这可有效追踪原始定义.
最后,RegMasks显示了清理了冲突源头的很多寄存器的调用点.
因为没有调用该函数,所以没有RegMasks位置.
观察中间值,会发现:%I0寄存器的中间值是[0B,32r:0),%vreg0寄存器的中间值是[32r,48r:0),在32处,有一条复制%I0到%vreg0的复制指令.
这是合并前提:用[32r,48r:0)组合中间值[0B,32r:0),并赋值给%I0和%vreg0相同寄存器.
下面,打印其余调试输出,看看:
$ llc -match=sparc -debug-only=regalloc sum.bc
...
entry:
16B %vreg1<def> = COPY %I1;
IntRegs: %vreg1
考虑用%I1合并进%vreg1
可合并至保留寄存器
32B %vreg0<def> = COPY %I0;
IntRegs:%vreg0
考虑用%I0合并进%vreg0
可合并至保留寄存器
64B %I0<def> = COPY %vreg2;
IntRegs:%vreg2
考虑用%I0合并进%vreg2
可合并至保留寄存器
...
看到,如期合并器考虑用%I0结合%vreg0.然而,当有个如%I0寄存器是物理寄存器时,它实现了个特殊规则.
必须保留物理寄存器来合并它的中间值.即,不能分配物理寄存器给其它活区间,而%I0不是这样.
因此,合并器放弃了,它担心过早地把%I0赋值给这整个区间,最后收益不大,并交给分配寄存器器来决定.
因此,虽然结合虚寄存器和函数参数寄存器,sum.bc程序没有合并的机会,失败了,因为此阶段它只能用保留的虚寄存器,而非普通可分配的物理寄存器合并.
覆盖虚寄存器
分配寄存器趟为每个虚寄存器选择物理寄存器.随后,VirtRegMap保存映射虚寄存器到物理寄存器的分配寄存器结果.
接着,虚寄存器覆盖由在<llvm_source>/lib/CodeGen/VirtRegMap.cpp文件中实现的VirtRegRewriter类表示的趟,用VirtRegMap并用物理寄存器替换虚寄存器.
根据情况会生成spill代码.而且,会删除剩下的reg=COPY reg复制标识.
如,用-debug-only=regalloc选项分析分配器和重写器如何处理sum.bc.首先,greedy分配器输出如下文本:
...
assigning %vreg1 to %I1: I1
...
assigning %vreg0 to %I0: I0
...
assigning %vreg2 to %I0: I0
用%I1,%I0,%I0物理寄存器分别分配1,0,2虚寄存器.VirtRegMap输出相同内容,如下:
[%vreg0 -> %I0] IntRegs
[%vreg1 -> %I1] IntRegs
[%vreg2 -> %I0] IntRegs
然后,重写器用物理寄存器替换所有虚寄存器,并删除复制标识:
> %I1<def> = COPY %I1
删除复制标识
> %I0<def> = COPY %I0
删除复制标识
...
可见,尽管合并器无法去除这些复制,但是分配寄存器器可如期为两个活区间赋值相同寄存器,并删除复制操作.
最终,极大地简化了sum结果函数的机器指令:
0B BB#0: derived from LLVM BB
%entry
Live Ins: %I0 %I1
48B %I0<def> = ADDrr %I1<kill>, %I0<kill>
80B RETL 8, %I0<imp-use>
注意,删除了复制指令,没有虚寄存器.
注意,仅当LLVM按debug模式编译(配置时设置-disable-optimized)后,才能使用llc程序的-debug或-debug-only=<name>选项.
编译器中,分配寄存器和调度指令是天生的敌人.分配寄存器要求尽量让活区间短一点,减少冲突图的边的数目,以减少必要寄存器的数目,以避免挤出(spill).
因而,分配寄存器器喜欢串行排列指令(让指令紧跟在其依赖指令的后面),这样代码所用的寄存器就相对较少.
而调度指令却相反:为了提升指令级的并行,需要尽量地让很多无关而并行的运算保持活动,要用很多寄存器保存中间值,增加活区间之间的冲突数.
设计有效算法来协同调度指令和分配寄存器,是个开放课题.
勾挂目标
合并时,要顺利合并,虚寄存器要来自兼容的寄存器类.生成代码从抽象方法取得的目标相关的描述中获得这类信息.
分配器可从TargetRegisterInfo的子类(如X86GenRegisterInfo)获得寄存器的包括是否为保留,父寄存器分类,是物理还是虚的所有寄存器信息.
<Target>InstrInfo类是另一个提供分配寄存器器要求的目标相关信息的数据结构,一些示例:
1,<Target>InstrInfo的isLoadFromStackSlot()和isStoreToStackSlot()方法,用来挤出生成代码时,判断机器指令是否访问栈槽内存.
2,此外,用storeRegToStackSlot()和loadRegFromStackSlot()方法,生成访问栈槽的目标相关的内存访问指令.
3,在覆盖寄存器后,可能保留COPY指令,因为没有合并掉它们,且不是同一个复制.此时,copyPhysReg()方法,必要时甚至在不同寄存器分类间,用来生成目标相关的寄存器复制.
SparcInstrInfo::copyPhysReg()中示例如下:
if (SP::IntRegsRegClass.contains(DestReg, SrcReg))
BuildMI(MBB, I, DL, get(SP::ORrr), DestReg).addReg(SP::G0)
.addReg(SrcReg, getKillRegState(KillSrc));
...
生成代码中,到处可见生成机器指令的BuildMI()方法.本例中,用SP::ORrr指令来复制一个CPU寄存器到另一个CPU寄存器.
片头和片尾
完整函数都需要片头(prologue)和片尾(epilogue).前者在函数的开始处安装栈帧及保存被调的寄存器,而后者在函数返回前清理栈帧.
在sum.bc示例中,为SPARC编译时,插入片头和片尾后,机器指令如下:
%06<def> = SAVEri %06, -96
%I0<def> = ADDrr %I1<kill>, %I0<kill>
%G0<def> = RESTORErr %G0, %G0
RETL 8, %I0<imp-use>
此例中,SAVEri指令是片头,RESTORErr是片尾,来执行栈帧相关的安装和清理.片头和片尾的生成是目标相关的,由<Target>FrameLowering::emitPrologue()和<Target>FrameLowering::emitEpilogue()方法定义(见<llvm_source>/lib/Target/<Target>/<Target>FrameLowering.cpp文件).
帧索引
在生成代码时,LLVM用到一个虚栈帧,用帧索引引用栈元素.插入片头会分配栈帧,给出充足的目标相关信息,让生成代码可用实际的(目标相关)栈引用替换索引虚帧.
<Target>RegisterInfo类的eliminateFrameIndex()方法通过对包含栈引用(一般为load和store)的所有机器指令,把每个帧索引转换为实际的栈偏移,实现了上述替换.
需要额外的栈偏移算术运算时,也会生成额外指令.见<llvm_source>/lib/Target/<Target>/<Target>RegisterInfo.cpp文件.
理解机器代码框架
机器代码(简称MC)类包含整个低级操作函数和指令的框架.对比其它后端组件,这是新设计的帮助创建基于LLVM的汇编器和反汇编器的框架.
之前,LLVM缺少一个整合汇编器,编译过程只能到达创建汇编文本文件,再生成汇编语言这一步,要依靠(汇编器和链接器)外部工具继续剩余编译工作.
MC指令
在MC框架中,机器代码指令(MCInst)替代了机器指令(MachineInstr).在<llvm_source>/include/llvm/MC/MCInst.h文件中定义的MCInst类,定义了指令的轻量表示.
对比MI(机器指令),MCInst记录较少的程序信息.如,不仅可由后端,还可由反汇编器根据二进制代码创建MCInst实例,注意反汇编器缺少指令环境信息.
事实上,它融入了汇编器的理念,也即,目的不是丰富的优化,而是组织指令来生成目标文件.
操作数可以是一个寄存器,立即数(整数或浮点数),式(表示为MCExpr),或另一个MCInstr实例.式来表示标签(label)计算和重定位.在生成代码阶段早期,就转换MI指令为MCInst实例.
发射代码
在后注册分配趟后,发射代码.从打印汇编(AsmPrinter)开始生成代码.
从MI指令到MCInst,接着到汇编或二进制指令步骤:
1,AsmPrinter是个,先生成函数头,然后遍历所有基本块,为进一步处理,每次发送一个MI指令到EmitInstruction()方法的机器函数趟.
每个目标会提供一个重载此方法的AsmPrinter子类.
2,<Target>AsmPrinter::EmitInstruction()方法按输入接收MI指令,并用MCInstLowering接口转换为MCInst实例,每个目标会提供该接口的子类,并自定义生成这些MCInst实例的代码.
3,此时,可生成汇编或二进制指令.MCStreamer类通过两个子类处理MCInst指令流,并按所选格式发射:MCAsmStreamer和MCObjectStreamer.
前者转换MCInst为汇编语言,而后者转换为二进制指令.
4,如果生成汇编指令,就会调用MCAsmStreamer::EmitInstruction(),并用目标相关的MCInstPrinter子类打印汇编指令到文件.
5,如果生成二进制指令,MCObjectStreamer::EmitInstruction()的特殊目标(target)和(object)目光相关的版本,就会调用LLVM目标代码汇编器.
6,汇编器会用可从MCInst实例分离的特化的MCCodeEmitter::EncodeInstruction()方法,按目标相关方式,编码和输出二进制指令数据块到文件.
此外,可用llc工具输出MCInst片段.如可用下面命令,编码MCInst进汇编注释:
$ llc sum.bc -march=x86-64 -show-mc-inst -o -
...
pushq %rbp ## <MCInst #2114 PUSH64r
## <MCOperand Reg: 107>>
...
然而,如果想要按汇编注释显示每条指令的二进制编码,就用下面的命令:
$ llc sum.bc -march=x86-64 -show-mc-encoding -o -
...
push %rbp ## encoding: [0x55]
...
llvm-mc工具,还可让你测试和使用MC框架.如,为了找特定指令的汇编编码,使用-show-encoding选项.下面是x86指令的一例:
$ echo "movq 48879(,%riz), %rax" | llvm-mc -triple=x86_64 --show-encoding
#encoding:
[0x48, 0x8b, 0x04, 0x25, 0xef, 0xbe, 0x00, 0x00]
该工具还提供了反汇编功能,如下:
$ echo "0x8d 0x4c 0x24 0x04" | llvm-mc --disassemble -triple=x86_64
leal 4(%rsp), %ecx
另外,-show-inst选项为汇编或反汇编指令,显示MCInst指令:
$ echo "0x8d 0x4c 0x24 0x04" | llvm-mc --disassemble --show-inst -triple=x86_64
leal 4(%rsp), %ecx # <MCInst #1105 LEA64_32r
# <MCOperand Reg:46>
# <MCOperand Reg:115>
# <MCOperand Imm:1>
# <MCOperand Reg:0>
# <MCOperand Imm:4>
# <MCOperand Reg:0>>
MC框架让LLVM可为经典目标文件阅读器提供可选择工具.如,目前默认编译LLVM会安装llvm-objdump和llvm-readobj工具.
两者都用到了MC反汇编库,实现了与GNUBinutils包中的等价物(objdump和readelf)类似功能.
编写你自己的机器趟
展示如何编写正好在生成代码前的自定义机器趟:统计每个函数有多少机器指令.不同于IR趟,你不能用opt工具运行该趟,或通过命令行加载并调度运行.
由后端代码管理机器趟.因此,修改已有后端来运行并观察自定义趟,这里选择SPARC后端.
查找后端实现的TargetPassConfig子类.如果用grep,就会在SparcTargetMachine.cpp中找到它:
$ cd <llvmsource>/lib/Target/Sparc
$ vim SparcTargetMachine.cpp
# 使用你喜欢的编辑器
查看从TargetPassConfig继承的SparcPassConfig类,看到它覆盖(override)了addInstSelector()和addPreEmitPass(),但是如果想在其它地方添加趟,可覆盖其他很多方法.
见文档.在生成代码前运行该趟,因此在addPreEmitPass()中添加代码:
bool SparcPassConfig::addPreEmitPass() {
addPass(createSparcDelaySlotFillerPass(
getSparcTargetMachine()));
addPass(createMyCustomMachinePass());
}
上面代码中,高亮的行是额外添加的,它调用函数createMyCustomMachinePass()来添加该趟.然而,还未定义该函数.
用趟代码及该函数写新的源码文件.于是,创建叫MachineCountPass.cpp的文件,填写下面内容:
#define DEBUG_TYPE "machinecount"
#include "Sparc.h"
#include "llvm/Pass.h"
#include "llvm/CodeGen/MachineBasicBlock.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
class MachineCountPass : public MachineFunctionPass {
public:
static char ID;
MachineCountPass() : MachineFunctionPass(ID) {
}
virtual bool runOnMachineFunction(MachineFunction &MF) {
unsigned num_instr = 0;
for (MachineFunction::const_iterator I = MF.begin(), E = MF.end(); I != E; ++I) {
for (MachineBasicBlock::const_iterator BBI = I->begin(), BBE = I->end(); BBI != BBE; ++BBI) {
++num_instr;
}
}
errs() << "mcount --- " << MF.getName() << " has " << num_instr << " instructions.\n";
return false;
}
};
}
FunctionPass *llvm::createMyCustomMachinePass() {
return new MachineCountPass();
}
char MachineCountPass::ID = 0;
static RegisterPass<MachineCountPass> X("machinecount", "Machine Count Pass");
在第一行中,定义了DEBUG_TYPE宏,这样以后就可通过-debug-only=machinecount选项调试该Pass.然而,本例中,未用到调试输出.
剩余代码和前面为IRPass写的类似.不同之处如下:
1,在包含文件中,包含了定义提取MachineFunction信息及计数包含的机器指令的类的MachineBasicBlock.h,MachineFunction.h,MachineFunctionPass.h头文件.
因为声明createMyCustomMachinePass(),还包含了Sparc.h头文件.
2,创建了一个从MachineFunctionPass而不是从FunctionPass继承的类.
3,覆盖了runOnMachineFunction()而不是runOnFunction()方法.另外,方法实现也是相当不同的.遍历了当前MachineFunction中的所有MachineBasicBlock实例.
然后,对每个MachineBasicBlock,调用begin()/end()语句来计数所有机器指令.
4,定义了createMyCustomMachinePass()函数,在修改的SPARC后端文件中按生成代码前的趟,创建和添加该趟.
既然已定义了createMyCustomMachinePass()函数,就必须在头文件中声明它.编辑Sparc.h文件.在createSparcDelaySlotFillerPass()后面添加函数声明:
FunctionPass *createSparcISelDag(SparcTargetMachine &TM);
FunctionPass *createSparcDelaySlotFillerPass(TargetMachine &TM);
FunctionPass *createMyCustomMachinePass();
//最后1行.
下面用LLVM编译系统编译新的SPARC后端.
如果已有了配置项目的build目录,进入该目录,运行make以编译新的后端.接着,可安装包含修改了的SPARC后端的新的LLVM,或依你所愿,只是从你的build目录运行新的llc二进制程序,而不运行makeinstall:
$ cd <llvm-build>
$ make
$ Debug+Asserts/bin/llc -march=sparc sum.bc
mcount --- sum has 8 instructions.
如果想知道该趟在趟管道中的插入位置,输入下面命令:
$ Debug+Asserts/lib/llc -march=sparc sum.bc -debug-Pass=Structure
(...)
Branch Probability Basic Block Placement
SPARC Delay Slot Filler
Machine Count Pass
MachineDominator Tree Construction
Sparc Assembly Printer
mcount --- sum has 8 instructions.
可看到,恰好在SPARCDelaySlotFiller后,及生成代码的SparcAssemblyPrinter前调度该趟.