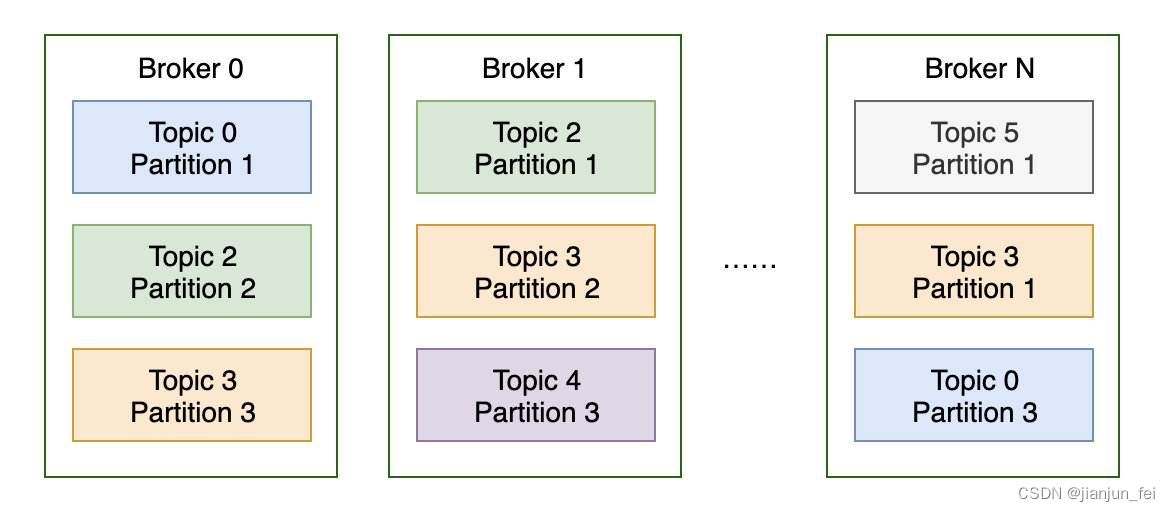
kafka在zookeeper数据结构
controller选举
客户端同时往zookeeper写入, 第一个写入成功(临时节点), 成为leader, 当leader挂掉, 临时节点被移除, 监听机制监听下线,重新竞争leader, 客户端也能监听最新leader
leader partition自平衡
leader不均匀时, 造成某个节点压力过大, 达到阈值时, 会触发自平衡, 均匀分配leader, 默认头节点
partition故障恢复机制
Leo: 每个Partition的最后一个Offset
HW: 一组Partiton中最小的LEO
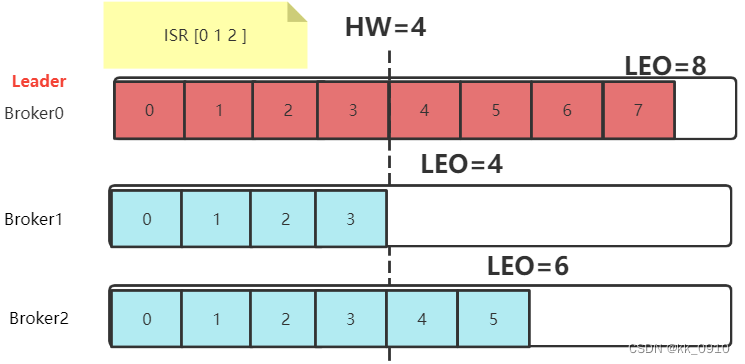
HW一致性保障
当Leader切换时, 可能产生HW不一致 ,Kafka设计Epoch保证HW一致性