《博主简介》
小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
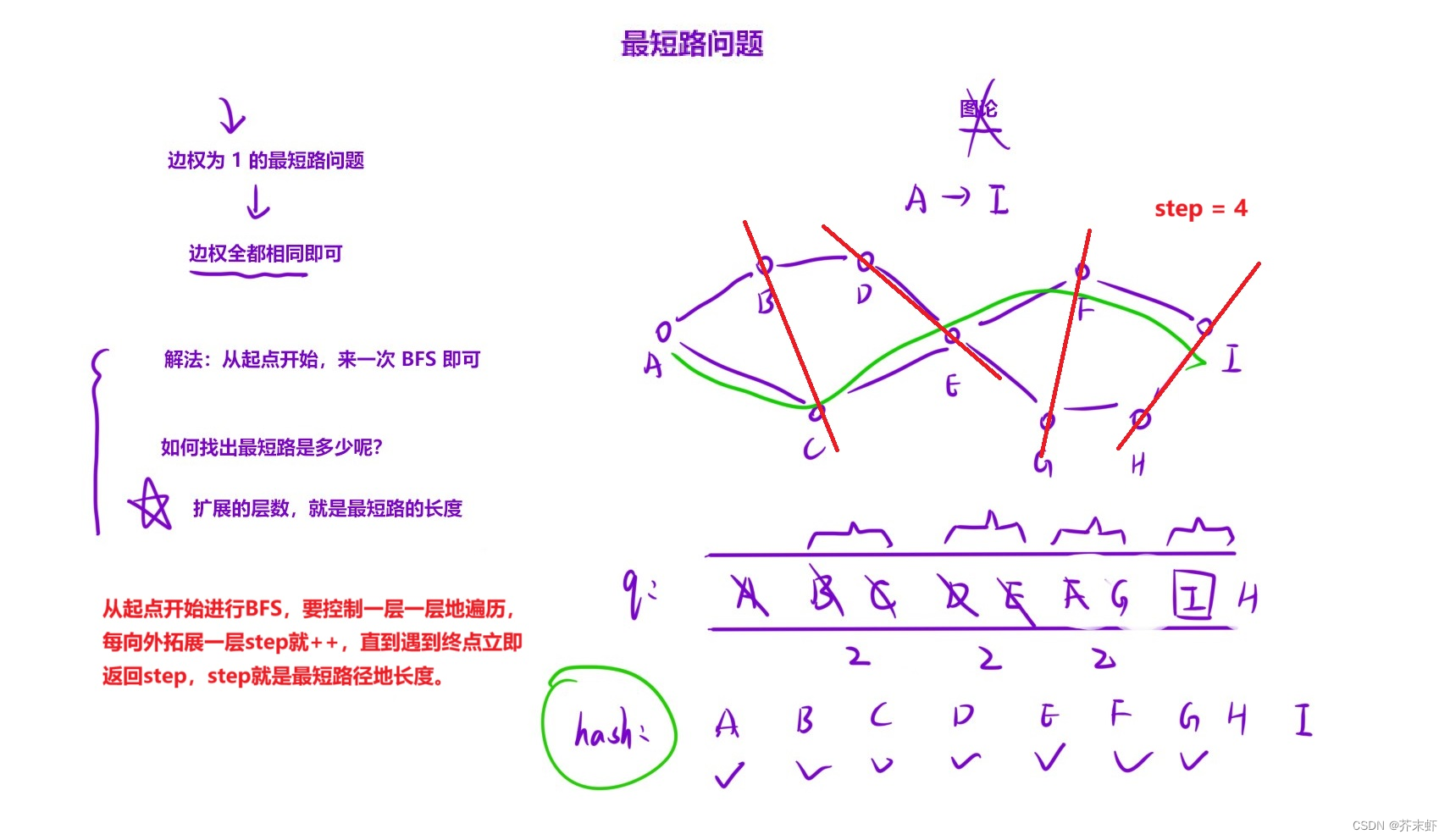
一般涉及到最小层数问题,要想到BFS。只要找到第一个符合条件的就是最小层数。
单词接龙

# 单向BFS class Solution: def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int: queue = [(beginWord, 1)] word_list = [ chr(ord('a') + i) for i in range(27)] wordList = set(wordList) n = len(beginWord) while queue: word, step = queue.pop(0) if word == endWord: return step for i in range(n): for c in word_list: tmp = word[:i] + c + word[i+1:] if tmp in wordList: wordList.remove(tmp) queue.append((tmp, step + 1)) return 0 # 双向BFS class Solution: def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int: # 双向BFS word_set = set(wordList) if len(word_set) == 0 or endWord not in word_set: return 0 if beginWord in word_set: word_set.remove(beginWord) visited = set() visited.add(beginWord) visited.add(endWord) begin_visited = set() begin_visited.add(beginWord) end_visited = set() end_visited.add(endWord) word_len = len(beginWord) step = 1 # 简化成 while begin_visited 亦可 while begin_visited and end_visited: if len(begin_visited) > len(end_visited): begin_visited, end_visited = end_visited, begin_visited next_level_visited = set() for word in begin_visited: word_list = list(word) for j in range(word_len): origin_char = word_list[j] for k in range(26): word_list[j] = chr(ord('a') + k) next_word = ''.join(word_list) if next_word in word_set: if next_word in end_visited: return step + 1 if next_word not in visited: next_level_visited.add(next_word) visited.add(next_word) word_list[j] = origin_char begin_visited = next_level_visited step += 1 return 0 |
单词接龙2

单向遍历 class Solution: def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]: tree, words, n = collections.defaultdict(set), set(wordList), len(beginWord) if endWord not in wordList: return [] # found为是否找到最短路径的标识默认False # q存储当前层的单词, nq存储下一层的单词 # tree[x]会记录单词x所有相邻节点的单词,即可能到达最终结果的路径 found, q, nq = False, { beginWord}, set() while q and not found: # 当找到路径或者队列中没有元素时结束 words -= set(q) # 从words列表中去除当前层的单词,避免重复使用 for x in q: # 遍历当前层的所有单词 for y in [x[:i]+c+x[i+1:] for i in range(n) for c in 'qwertyuiopasdfghjklzxcvbnm']: # 改变当前单词的每一个字符 if y in words: # 只关心在words集合中的单词 if y == endWord: # 如果找到了,将found置为True,不会再继续寻找下一层. found = True else: nq.add(y) # 准备下一层的单词集合 tree[x].add(y) # 记录x单词满足条件的下一个路径 q, nq = nq, set() # 重新复制q与nq, q为下一次循环需遍历的单词集合,nq置为空 def bt(x): # 递归,在tree中寻找满足条件的路径 # for y in tree[x] 遍历当前单词的相邻节点 return [[x]] if x == endWord else [[x] + rest for y in tree[x] for rest in bt(y)] if found == False: return [] return bt(beginWord) # 双向遍历 class Solution: def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]: # 双向BFS tree, words, n = collections.defaultdict(set), set(wordList), len(beginWord) if endWord not in wordList: return [] found, bq, eq, nq, rev = False, { beginWord}, { endWord}, set(), False while bq and not found: words -= set(bq) for x in bq: for y in [x[:i]+c+x[i+1:] for i in range(n) for c in 'qwertyuiopasdfghjklzxcvbnm']: if y in words: if y in eq: found = True else: nq.add(y) tree[y].add(x) if rev else tree[x].add(y) bq, nq = nq, set() if len(bq) > len(eq): bq, eq, rev = eq, bq, not rev def bt(x): return [[x]] if x == endWord else [[x] + rest for y in tree[x] for rest in bt(y)] return bt(beginWord) |
最小基因变化
class Solution: def minMutation(self, start: str, end: str, bank: List[str]) -> int: #BFS possible_dict = { "A": "CGT", "C": "AGT", "G": "ACT", "T": "ACG" } queue=[(start,0)] while queue: # 广度优先遍历模板 (word, step)=queue.pop(0) if word ==end: return step
for i, c in enumerate(word): for p in possible_dict[c]: # 从第0个位置开始匹配新的字符串 temp=word[:i]+p+word[i+1:] # 在bank里面就处理(set中in操作复杂度是0(1)) if temp in bank: # 从bank里移除,避免重复计数 bank.remove(temp) # 加入队列,步数加1 queue.append((temp,step+1)) return -1 |
二进制矩阵中的最短路径

class Solution: def shortestPathBinaryMatrix(self, grid: List[List[int]]) -> int: # BFS n = len(grid) if grid[n-1][n-1] == 1 or grid[0][0] == 1: return -1 queue = [(0,0)] length = 1 visited = set() visited.add((0,0)) while queue: cur_nums = len(queue) for i in range(cur_nums): i,j = queue.pop(0) if i == n-1 and j == n-1: return length for ni,nj in [(i-1,j-1),(i-1,j),(i-1,j+1),(i,j-1),(i,j+1),(i+1,j-1),(i+1,j),(i+1,j+1)]: if 0<= ni < n and 0<= nj < n and (ni,nj) not in visited and grid[ni][nj] == 0: visited.add((ni,nj)) queue.append((ni,nj)) length += 1 return -1 |
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
欢迎关注下方GZH:阿旭算法与机器学习,共同学习交流~




















![[python]用python获取EXCEL文件内容并保存到DBC](https://img-blog.csdnimg.cn/7ddd480aac8447b59c56eb11fe4c0067.png)