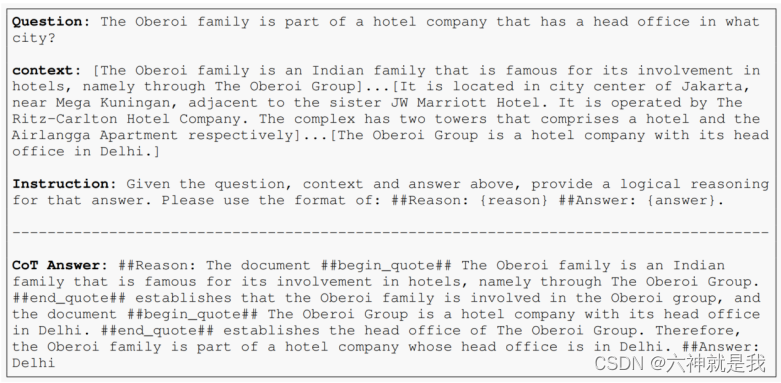
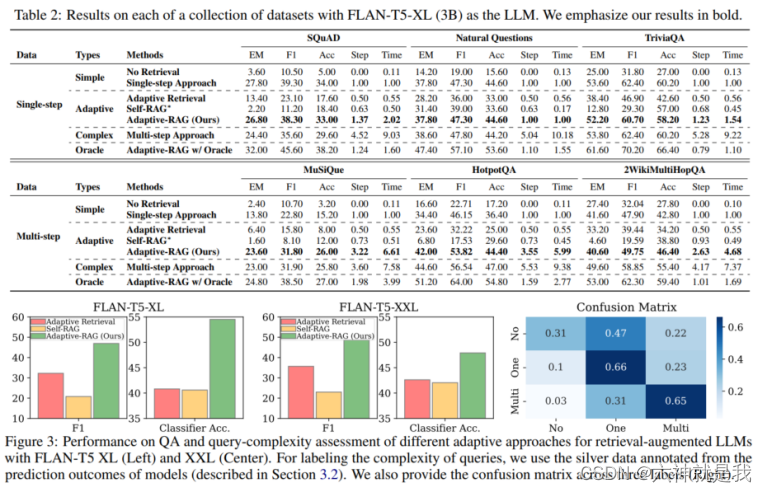
论文阅读:Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Abstract
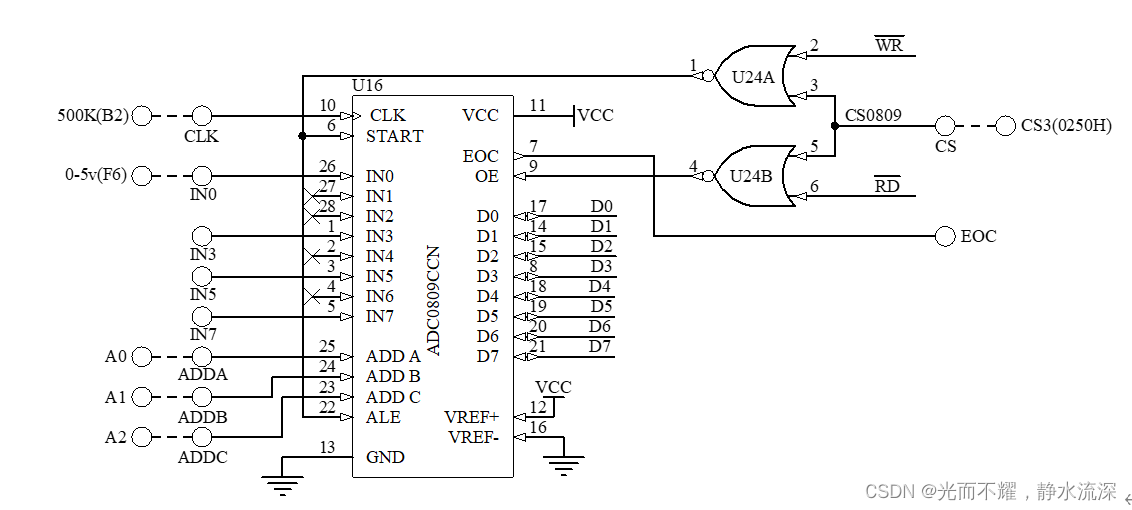
大多数的 Camera ISP 会将 RAW 图经过一系列的处理,变成 sRGB 图像,ISP 的处理中很多模块是非线性的操作,这些操作会破坏环境光照的线性关系,这对于一些希望获取环境光照线性关系的 CV 任务来说是不友好的,对于这类任务来说,线性的 RAW-RGB 图像来说更合适,不过,一般的 RAW-RGB 图像的 bit 位都是 12 或者 14 比特的,直接存储 RAW-RGB 图像比较费存储空间。为了解决这个问题,有几个 raw 重建的方法,是通过从 RAW-RGB 图像中提取特定的元数据,并嵌入 sRGB 图像中,这些元数据,最后可以用来参数化一个映射函数,这个映射函数可以将 sRGB 图像重映射回 RAW-RGB 图像。现有的 RAW 重建的方法都是基于简单的采样以及全局映射函数来实现。这篇文章提出了一种联合学习的方式,将采样策略与重建方法进行联合优化,最终得到的采样策略可以基于图像内容自适应地进行采样,从而可以得到更好的 RAW 重建结果。文章也提出了一种在线 fine-tuning 的方式进一步提升重建网络的效果。

De-rendering Framework

文章先对这个 RAW-RGB 图像的重建,进行了一个抽象的表述,假设 x \mathbf{x} x 与 y \mathbf{y} y 分别表示 sRGB 图像以及 RAW-RGB 图像,RAW-RGB 图像的重建问题,可以抽象为寻找一个映射函数,使得
y = f ( x ) \mathbf{y} = f(\mathbf{x}) y=f(x)
对于元数据的这类方法,映射关系通常基于一个小样本的采样来获得:
y = f ( x ; s y ) \mathbf{y} = f(\mathbf{x}; s_{\mathbf{y}}) y=f(x;sy)
这类采样,一般是基于事先设定好的规则,比如均匀采样等。这篇文章,希望能同时学习到采样函数以及映射函数,即:
y = f ( x ; s y = g ( x , y ) ) \mathbf{y} = f(\mathbf{x}; s_{\mathbf{y}} = g(\mathbf{x}, \mathbf{y}) ) y=f(x;sy=g(x,y))
其中, g ( x , y ) g(\mathbf{x}, \mathbf{y}) g(x,y) 是一个可学习的映射函数。
文章作者将 f , g f, g f,g 用两个 U-Net 的网络进行建模, 并且通过端到端的方式进行训练,在训练阶段,从 RAW-RGB 图像中提取 k % k\% k% 的像素点,采样网络输入一张 RAW-RGB 图像以及一张 sRGB 图像,输出一个二值的采样图,被采样点的位置上赋值为 1,为了更有效的计算采样点,采样网络也会学习将 RAW-RGB 图像分成多个超像素区域,每个采样点就从超像素区域通过 max-pooling 获得,而对于重建网络,输入的就是 sRGB 图像,采样的 RAW-RGB 图像点以及采样图,从而恢复出完整的 RAW-RGB 图像。测试阶段,包含两个阶段,第一阶段就是在拍摄的时候,利用采样网络 g g g 对 RAW-RGB 图像进行采样,同时 ISP 会输出一张 sRGB 图像;然后第二阶段就是需要 RAW-RGB 图像的时候, 通过重建网络 f f f 进行重建。

基于内容的元数据采样方式,就是想基于图像内容找到最合适的图像采样点。为了实现这个目的,文章作者提出了一种基于 superpixel 的方式,将图像分成若干个 superpixel 区域,然后每个 superpixel 区域进行采样。通过这种方式,可以将 RAW-RGB 图像分成很多个分割区域,每个区域选择最具代表性的采样点。
文章中的采样网络是直接从 RAW-RGB 图像中进行采样,如下图所示,首先将 RAW-RGB 图像分成若干个均匀分布的网格,网络会预测相关分数 q c ( p ) q_c(\mathbf{p}) qc(p),表示每个像素 p \mathbf{p} p 属于网格 c c c 的概率有多大,为了计算效率, 文章中只选择了一个 9 邻域的网格来计算相关分数。相关性图通过如下的 loss 来学习获得:
L S = α ∑ p ∥ x ( p ) − x ^ ( p ) ∥ 2 2 + ( 1 − α ) ∑ p ∥ y ( p ) − y ^ ( p ) ∥ 2 2 + m 2 S 2 ∑ p ∥ p − p ^ ∥ 2 2 (1) L_S = \alpha \sum_{\mathbf{p}} \left \| \mathbf{x}(\mathbf{p}) - \hat{\mathbf{x}}(\mathbf{p}) \right \|_{2}^{2} + (1-\alpha) \sum_{\mathbf{p}} \left \| \mathbf{y}(\mathbf{p}) - \hat{\mathbf{y}}(\mathbf{p}) \right \|_{2}^{2} + \frac{m^2}{S^2} \sum_{\mathbf{p}} \left \| \mathbf{p} - \hat{\mathbf{p}} \right \|_{2}^{2} \tag{1} LS=αp∑∥x(p)−x^(p)∥22+(1−α)p∑∥y(p)−y^(p)∥22+S2m2p∑∥p−p^∥22(1)
其中, x ^ ( p ) \hat{\mathbf{x}}(\mathbf{p}) x^(p) 是 x ( p ) \mathbf{x}(\mathbf{p}) x(p) 重建之后的 RGB 值,其表达式如下所示:
u c = ∑ p ∈ N c x ( p ) ⋅ q c ( p ) ∑ p ∈ N c q c ( p ) , x ^ ( p ) = ∑ c u c ⋅ q c ( p ) (2) \mathbf{u}_c = \frac{\sum_{\mathbf{p} \in \mathcal{N}_c} \mathbf{x}(\mathbf{p}) \cdot q_c(\mathbf{p}) }{\sum_{\mathbf{p} \in \mathcal{N}_c} q_c(\mathbf{p})}, \quad \hat{\mathbf{x}}(\mathbf{p}) = \sum_c \mathbf{u}_c \cdot q_c(\mathbf{p}) \tag{2} uc=∑p∈Ncqc(p)∑p∈Ncx(p)⋅qc(p),x^(p)=c∑uc⋅qc(p)(2)
其中, u c \mathbf{u}_c uc 表示超像素区域中心的特征向量, N c \mathcal{N}_c Nc 表示网格 c c c 的 9 邻域内的所有像素集合, y ^ ( p ) , p \hat{\mathbf{y}}(\mathbf{p}), \mathbf{p} y^(p),p 都用类似的方法进行计算, m 和 S m 和 S m和S 表示权重参数。如果选择 % k \%k %k 的采样点,文章就将整个图像区域分成 % k \%k %k 个网格区域,然后每个网格区域选择似然估计最大的像素点作为采样点:
p c ∗ = arg max p ∈ N c q c ( p ) (3) \mathbf{p}^{*}_c = \argmax_{\mathbf{p} \in \mathcal{N}_c} q_c(\mathbf{p}) \tag{3} pc∗=p∈Ncargmaxqc(p)(3)
这些采样点,最后会形成一个二值化化的采样 mask m ( p ) \mathbf{m}(\mathbf{p}) m(p),然后用这个 mask 与 RAW-RGB 图像相乘,就能得到采样后的 RAW-RGB 值,这些值存下来作为元数据。
介绍完了采样,后面的重建就比较直观,将 RGB 图像 x \mathbf{x} x,采样后的 RAW-RGB 图像值 s y \mathbf{s}_y sy 以及 mask m \mathbf{m} m 串起来,一起输入重建网络,重建网络最后预测出一个完整的 RAW-RGB 图像,重建 loss 由下所示:
L R = ∑ p ∥ y ( p ) − y ^ ( p ) ∥ 1 L_{R} = \sum_{\mathbf{p}} \left \| \mathbf{y}(\mathbf{p}) - \hat{\mathbf{y}}(\mathbf{p}) \right \|_{1} LR=p∑∥y(p)−y^(p)∥1
其中, y ^ = f ( x , s y , m ) \hat{\mathbf{y}}=f(\mathbf{x}, \mathbf{s}_y, \mathbf{m}) y^=f(x,sy,m)
推理的时候,可以利用在线 finetune 的方式进一步提升重建效果,可以通过只对采样点处的像素进行重建损失的计算:
L O = ∑ p m ( p ) ∥ y ( p ) − y ^ ( p ) ∥ 1 L_{O} = \sum_{\mathbf{p}} \mathbf{m}(\mathbf{p}) \left \| \mathbf{y}(\mathbf{p}) - \hat{\mathbf{y}}(\mathbf{p}) \right \|_{1} LO=p∑m(p)∥y(p)−y^(p)∥1
文章中还利用了元学习的策略,进一步提升推理时候的重建效果:
L M = ∑ p ∥ y ~ θ ′ ( p ) − y ^ ( p ) ∥ 1 L_{M} = \sum_{\mathbf{p}} \left \| \tilde{\mathbf{y}}_{\theta'}(\mathbf{p}) - \hat{\mathbf{y}}(\mathbf{p}) \right \|_{1} LM=p∑∥y~θ′(p)−y^(p)∥1
最终的训练loss 是这几种 loss 的加权:
L T o t a l = L R + λ S L S + λ M L M L_{Total} = L_{R} + \lambda_{S}L_{S} + \lambda_{M}L_{M} LTotal=LR+λSLS+λMLM