第六章 大模型的模型架构(英文版)
In the previous blog, I discussed the training data of LLMs and their data scheduling methods. This blog will focus on another important aspect of LLMs: model architecture. Due to the complexity and diversity of model architectures, I will be writing a bilingual blog. This version is in English, and a Chinese version has been released. The blog is based on datawhale files and a nice survey.
6.1 Typical Architectures
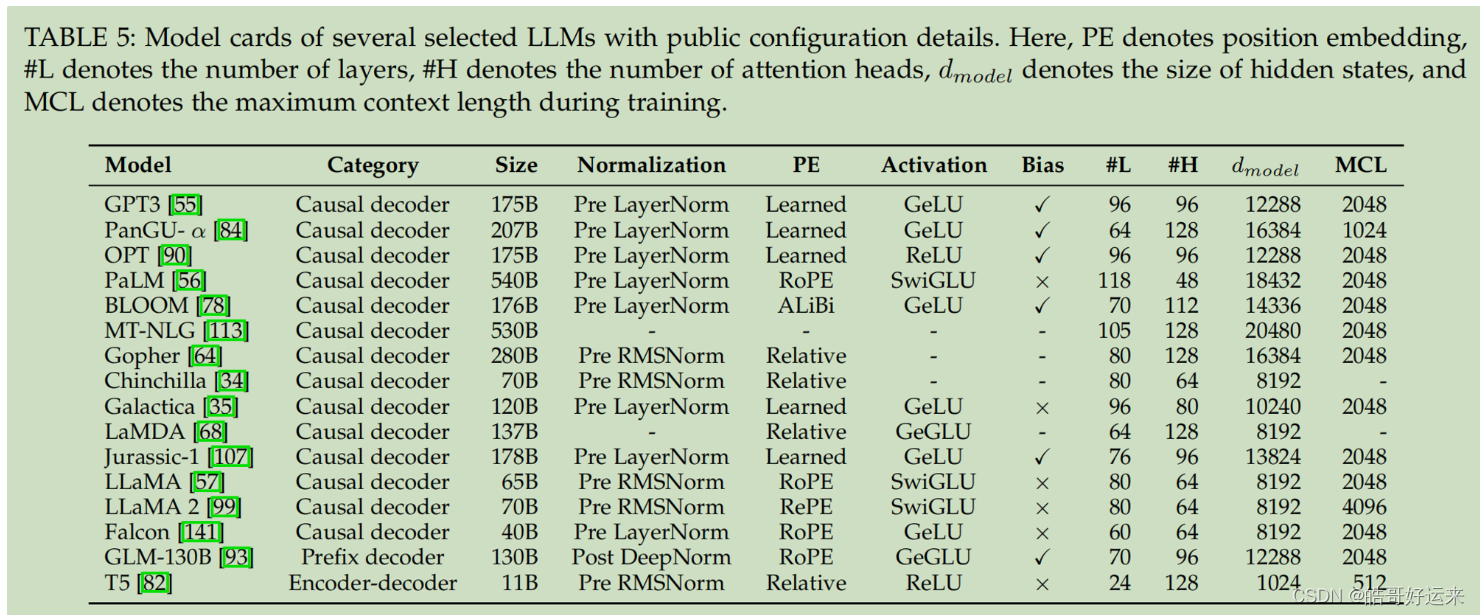
The Transformer architecture has become the dominant framework for creating a wide range of LLMs, enabling the scaling of language models to hundreds or thousands of billions of parameters. Broadly speaking, the prevalent architectures of current LLMs can be roughly classified into three main types: encoder-decoder, causal decoder, and prefix decoder. And a summary table can be seen in:
- Encoder-decoder Architecture. The original Transformer model is constructed using the encoder-decoder architecture, comprising two sets of Transformer blocks serving as the encoder and decoder, individually. The encoder utilizes stacked multi-head self-attention layers to encode the input sequence in order to produce its latent representations, while the decoder conducts cross-attention on these representations and autonomously generates the target sequence.
- Causal Decoder Architecture. The causal decoder architecture includes a unidirectional attention mask, ensuring that each input token can only attend to the tokens that precede it and itself. Both the input and output tokens are processed in a similar manner within the decoder. The GPT-series models serve as representative language models developed based on the causal-decoder architecture. Notably, GPT-3 has effectively showcased the efficacy of this architecture, demonstrating an impressive in-context learning capability of LLMs. Interestingly, GPT-1 and GPT-2 do not exhibit the same exceptional abilities as GPT-3, suggesting that scaling plays a crucial role in enhancing the model capacity of this architecture. When referring to a “decoder-only architecture”, it primarily denotes the causal decoder architecture in existing literature, unless otherwise specified.
- Prefix Decoder Architecture. The prefix decoder architecture, also known as non-causal decoder, modifies the masking mechanism of causal decoders to allow for bidirectional attention over the prefix tokens and unidirectional attention only on generated tokens. Similar to the encoder-decoder architecture, prefix decoders can encode the prefix sequence bidirectionally and predict the output tokens in an autoregressive manner, sharing the same parameters during both encoding and decoding. Rather than training from scratch, a practical approach is to continuously train causal decoders and then convert them into prefix decoders to expedite convergence.
- Mixture-of-Experts. We can further extend the aforementioned three types of architectures through the mixture-of-experts (MoE) scaling, where a subset of neural network weights for each input are sparsely activated. The primary advantage of MoE is its flexible approach to scaling up the model parameter while maintaining a constant computational cost. It has been demonstrated that significant performance improvements can be achieved by increasing either the number of experts or the total parameter size. However, training large MoE models may encounter instability issues due to the complex, hard-switching nature of the routing operation. To address this, techniques such as selectively using high-precision tensors in the routing module or initializing the model with a smaller range have been introduced.
- Novel Architectures. Traditional Transformer architectures often face issues with quadratic computational complexity. Consequently, efficiency has become a crucial concern during both training and inference with lengthy inputs. To enhance efficiency, several studies are focused on developing new architectures for LLMs. These include parameterized state space models, long convolutions and Transformer-like architectures integrating recursive update mechanisms. The primary advantages of these new architectures are twofold.
- These models can recursively generate outputs similar to RNNs, meaning they only need to reference the preceding state during decoding. This enhances the efficiency of the decoding process by eliminating the need to revisit all previous states, as is required in conventional Transformers.
- These models possess the capability to parallelly encode an entire sentence, akin to Transformers. This is in contrast to conventional RNNs, which encode sentences token by token. Consequently, they can leverage GPU parallelism through techniques. These techniques enable models with these new architectures to be trained in a highly parallel and efficient manner.
6.2 Detailed Configuration
6.2.1 Normalization Techniques
The stability of training is a significant challenge for pre-training LLMs. Normalization is a widely used strategy to address this issue and stabilize the training of neural networks. In the original Transformer, LayerNorm is utilized. However, several advanced normalization techniques have been proposed as alternatives to LayerNorm, such as RMSNorm and DeepNorm.
- LayerNorm: Initially, BatchNorm was a commonly used normalization method, but it struggled with sequence data of varying lengths and small-batch data. Consequently, LayerNorm was introduced to perform layerwise normalization. It calculates the mean and variance over all activations per layer to recenter and rescale the activations.
- RMSNorm: RMSNorm was proposed to enhance the training speed of LayerNorm by rescaling the activations using only the root mean square (RMS) of the summed activations, instead of the mean and variance. Research has demonstrated its superiority in training speed and performance on Transformers.
- DeepNorm: Microsoft proposed DeepNorm to stabilize the training of deep Transformers. By using DeepNorm as residual connections, Transformers can be scaled up to 1,000 layers, showcasing the advantages of stability and good performance.
6.2.2 Normalization Position
In addition to the normalization method, the normalization position also plays a crucial role in LLMs. There are generally three choices for the normalization position: post-LN, pre-LN, and sandwich-LN.
- Post-LN: Post-LN is used in the original Transformer, positioned between residual blocks. However, existing work has found that training Transformers with post-LN tends to be unstable due to large gradients near the output layer. Consequently, post-LN is rarely employed in existing LLMs, except when combined with other strategies.
- Pre-LN: In contrast to post-LN, pre-LN is applied before each sub-layer, with an additional LN placed before the final prediction. Transformers with pre-LN are more stable during training compared to those with post-LN. However, they tend to perform worse than their post-LN counterparts. Despite this performance decrease, most LLMs still adopt pre-LN due to its training stability. One exception is that pre-LN has been found to be unstable in GLM when training models with more than 100B parameters.
- Sandwich-LN: Building on pre-LN, Sandwich-LN adds extra LN before the residual connections to mitigate value explosion issues in Transformer layer outputs. However, it has been observed that Sandwich-LN sometimes fails to stabilize the training of LLMs and may lead to training collapse.
6.2.3 Activation Functions
Properly setting activation functions in feed-forward networks is crucial for achieving good performance. GeLU activations are widely used in existing LLMs. Additionally, variants of GeLU activation have been utilized in the latest LLMs, especially the SwiGLU and GeGLU variants, which often achieve better performance in practice. However, compared to GeLU, they require additional parameters (about 50%) in the feed-forward networks.
6.2.4 Position Embeddings
As the self-attention modules in Transformers are permutation equivariant, position embeddings (PE) are employed to inject absolute or relative position information for modeling sequences.
Absolute Position Embedding: In the original Transformer, absolute position embeddings are used. At the bottoms of the encoder and the decoder, the absolute positional embeddings are added to the input embeddings. There are two variants of absolute position embeddings proposed in the original Transformer, namely sinusoidal and learned position embeddings, with the latter being commonly used in existing pre-trained language models.
Relative Position Embedding: Unlike absolute position embeddings, relative positional embeddings are generated based on the offsets between keys and queries. A popular variant of relative PE was introduced in Transformer-XL. The calculation of attention scores between keys and queries has been modified to introduce learnable embeddings corresponding to relative positions.
Rotary Position Embedding (RoPE): It involves setting specific rotatory matrices based on the absolute position of each key or query. The scores between keys and queries can be computed with relative position information. RoPE combines each consecutive pair of elements in query and key vectors as a dimension, resulting in d 2 \frac{d}{2} 2d dimensions for an original d-length embedding. For each dimension i ∈ { 1 , . . . , d 2 } i \in \{1,...,\frac{d}{2}\} i∈{ 1,...,2d}, the pair of involved elements will rotate based on the rotation angle t ⋅ θ i t·\theta_i t⋅θi, where t t t denotes the position index and θ i \theta_i θi is the basis in the dimension. Following sinusoidal position embeddings, RoPE defines the basis θ i \theta_i θi as an exponentiation of the base b (set to 10000 by default):
Θ = { θ i = b − 2 ( i − 1 ) / d ∣ i ∈ { 1 , 2 , … , d / 2 } } \Theta = \{\theta_i = b^{-2(i-1)/d}|i\in \{1,2,\dots,d/2\}\} Θ={ θi=b−2(i−1)/d∣i∈{ 1,2,…,d/2}}
Furthermore, a recent study defines the distance required to rotate one cycle (2π) for each dimension as wavelength:
λ i = 2 π b 2 ( i − 1 ) / d = 2 π / θ i \lambda_i = 2 \pi b^{2(i-1)/d}= 2\pi/\theta_i λi=2πb2(i−1)/d=2π/θi
Because of its outstanding performance and long-term decay property, RoPE has been widely embraced in the latest LLMs. Building upon RoPE, xPos enhances the translation invariance and length extrapolation of the Transformer. At each dimension of the rotation angle vector, xPos introduces a special exponential decay that diminishes as the basis grows, thereby mitigating the instability during training as the distance increases.
Due to its importance and hard-understanding, a nice blog illustrates it well (Warning: NEED GOOD MATH): https://zhuanlan.zhihu.com/p/647109286.
ALiBi: It is designed to enhance the extrapolation capability of the Transformer. Similar to relative position embedding, it biases attention scores using a penalty based on the distances between keys and queries. Unlike relative positional embedding methods, the penalty scores in ALiBi are predefined without any trainable parameters. Empirical results have demonstrated that ALiBi outperforms several popular position embedding methods, particularly on longer sequences. Furthermore, it has been shown that ALiBi can also enhance training stability in BLOOM.
6.2.5 Attention Mechanism
The attention mechanism is a crucial element of the Transformer, enabling tokens across the sequence to interact and compute representations of the input and output sequences.
- Full Attention: In the original Transformer, the attention mechanism operates in a pairwise manner, considering the relationships between all token pairs in a sequence. It employs scaled dot-product attention, where the hidden states are transformed into queries, keys, and values. Additionally, the Transformer utilizes multi-head attention, projecting the queries, keys, and values with different projections in different heads. The concatenation of the output of each head is taken as the final output.
- Sparse Attention: The quadratic computational complexity of full attention becomes burdensome when dealing with long sequences. Consequently, various efficient Transformer variants have been proposed to reduce the computational complexity of the attention mechanism. For example, locally banded sparse attention, such as Factorized Attention, has been adopted in GPT-3. Instead of attending to the entire sequence, each query can only attend to a subset of tokens based on their positions.
- Multi-Query/Grouped-Query Attention: Multi-query attention refers to the attention variant where different heads share the same linear transformation matrices on the keys and values. It achieves higher inference speed with only a minor sacrifice in model quality. Representative models with multi-query attention include PaLM and StarCoder. To strike a balance between multi-query attention and multi-head attention, grouped-query attention (GQA) has been explored. In GQA, heads are assigned to different groups, and those belonging to the same group share the same transformation matrices. Notably, GQA has been adopted and empirically tested in the recently released LLaMA 2 model.
- FlashAttention: In contrast to most existing approximate attention methods that trade off model quality to improve computing efficiency, FlashAttention aims to optimize the speed and memory consumption of attention modules on GPUs from an IO-aware perspective. The updated version, FlashAttention-2, further optimizes the work partitioning of GPU thread blocks and warps, resulting in around a 2× speedup compared to the original FlashAttention.
- PagedAttention: When deploying LLMs on servers, GPU memory is often occupied by cached attention key and value tensors (referred to as KV cache). This is primarily due to the varying input lengths, leading to fragmentation and over-reservation issues. Drawing inspiration from the classic paging technique in operating systems, PagedAttention has been introduced to enhance the memory efficiency and throughput of deployed LLMs. Specifically, PagedAttention partitions each sequence into subsequences, and the corresponding KV caches of these subsequences are allocated into non-contiguous physical blocks. This paging technique increases GPU utilization and enables efficient memory sharing during parallel sampling.
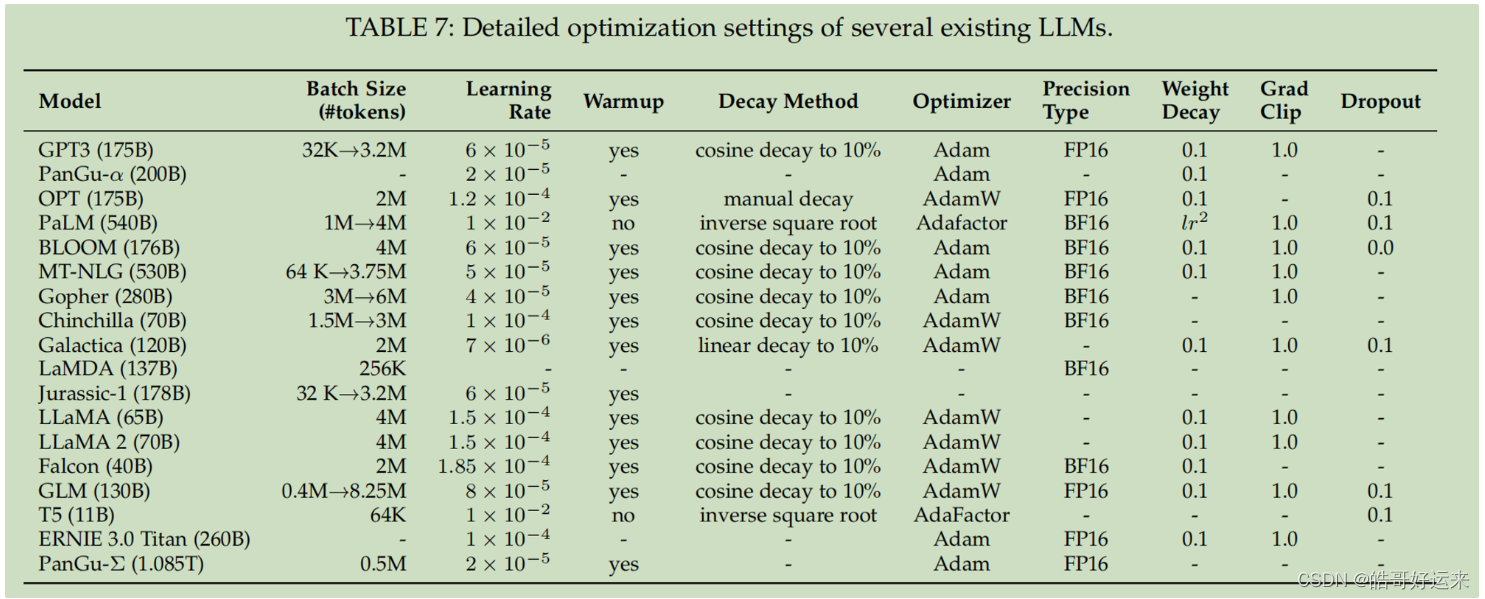
In summary, existing literature suggests the following detailed configurations for stronger generalization and training stability: choose pre-RMSNorm for layer normalization, and SwiGLU or GeGLU as the activation function. Additionally, it is recommended not to use LN immediately after embedding layers, as this may lead to performance degradation. Regarding position embeddings, RoPE or ALiBi is a better choice, especially for better performance on long sequences.

END

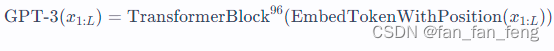

























![[笔记] linux 4.19 版本 Kbuild 编译流程解析](https://img-blog.csdnimg.cn/direct/15ff0bdf82fe4632ae460d56dedc73e3.png)