文章目录
本文大致分析了flink sql执行过程中的各个阶段的源码逻辑,这样可以在flink sql执行过程中, 能够定位到任务执行的某个阶段的代码大概分布在哪里,为更针对性的分析此阶段的细节逻辑打下基础,比如create 的逻辑是怎么执行的,select的逻辑是怎么生成的,优化逻辑都做了哪些,而这些是接下来的文章要分析的。
一. sql执行流程源码分析
SQL语句经过Calcite解析生成抽象语法树SQLNode,基于生成的SQLNode并结合flink Catalog完成校验生成一颗Operation树,接下来blink planner将Opearation树转为RelNode树然后进行优化,最后进行执行。如下流程流转图:
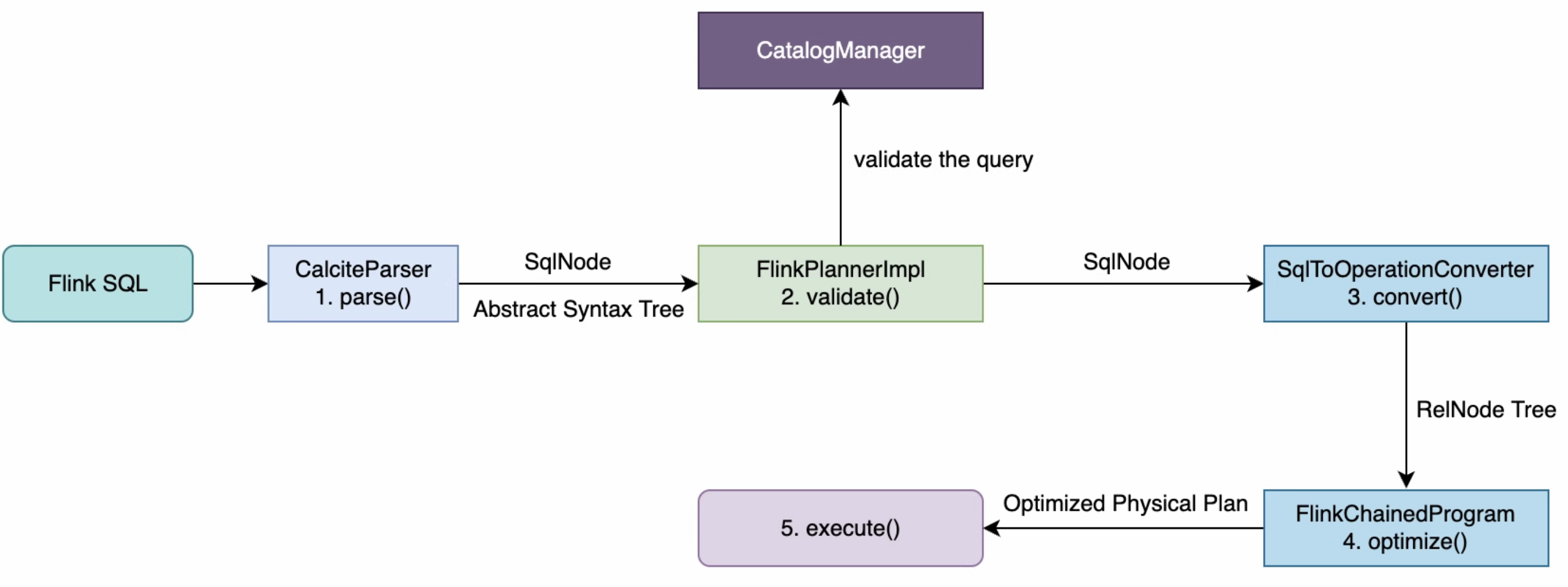
flink使用的是一款开源SQL解析工具Apache Calcite ,Calcite使用Java CC对sql语句进行了解析,转换为java/scala语言能够执行的逻辑。
Sql 的执行过程一般可以分为下图中的四个阶段,Calcite 同样也是这样:解析,校验,优化,执行:

1. Sql语句解析成语法树阶段(SQL - > SqlNode)
对于flink中解析sql为SqlNode对象的流程为:
TableEnvironmentImpl是sql执行的入口类,TableEnvironmentImpl中提供了excuteSql,SqlQuery等方法用来执行DDL、DML等sql- sql执行时会先对sql进行解析,
ParserImp是flink调用sql解析的实现类,ParserImpl#parse()方法中通过调用包装器对象CalciteParser#parse()方法创建并调用使用javacc生成的sql解析器- (FlinkSqlParserImpl)
parseSqlStmtEof方法完成sql解析,并返回SqlNode对象。
具体calciteParser 的动作之后更新

parse方法:负责将 SQL 查询字符串解析为抽象语法树(AST)
org.apache.flink.table.planner.delegation.ParserImpl
/**
* When parsing statement, it first uses {@link ExtendedParser} to parse statements. If {@link
* ExtendedParser} fails to parse statement, it uses the {@link CalciteParser} to parse statements.
* 先使用ExtendedParser进行解析如果解析失败了使用CalciteParser进行解析
* @param statement input statement.
* @return parsed operations.
*/
@Override
public List<Operation> parse(String statement) {
//两种解析实例
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
//ExtendedParser解析
Optional<Operation> command = EXTENDED_PARSER.parse(statement);
if (command.isPresent()) {
return Collections.singletonList(command.get());
}
//CalciteParser解析
//解析为sqlNode
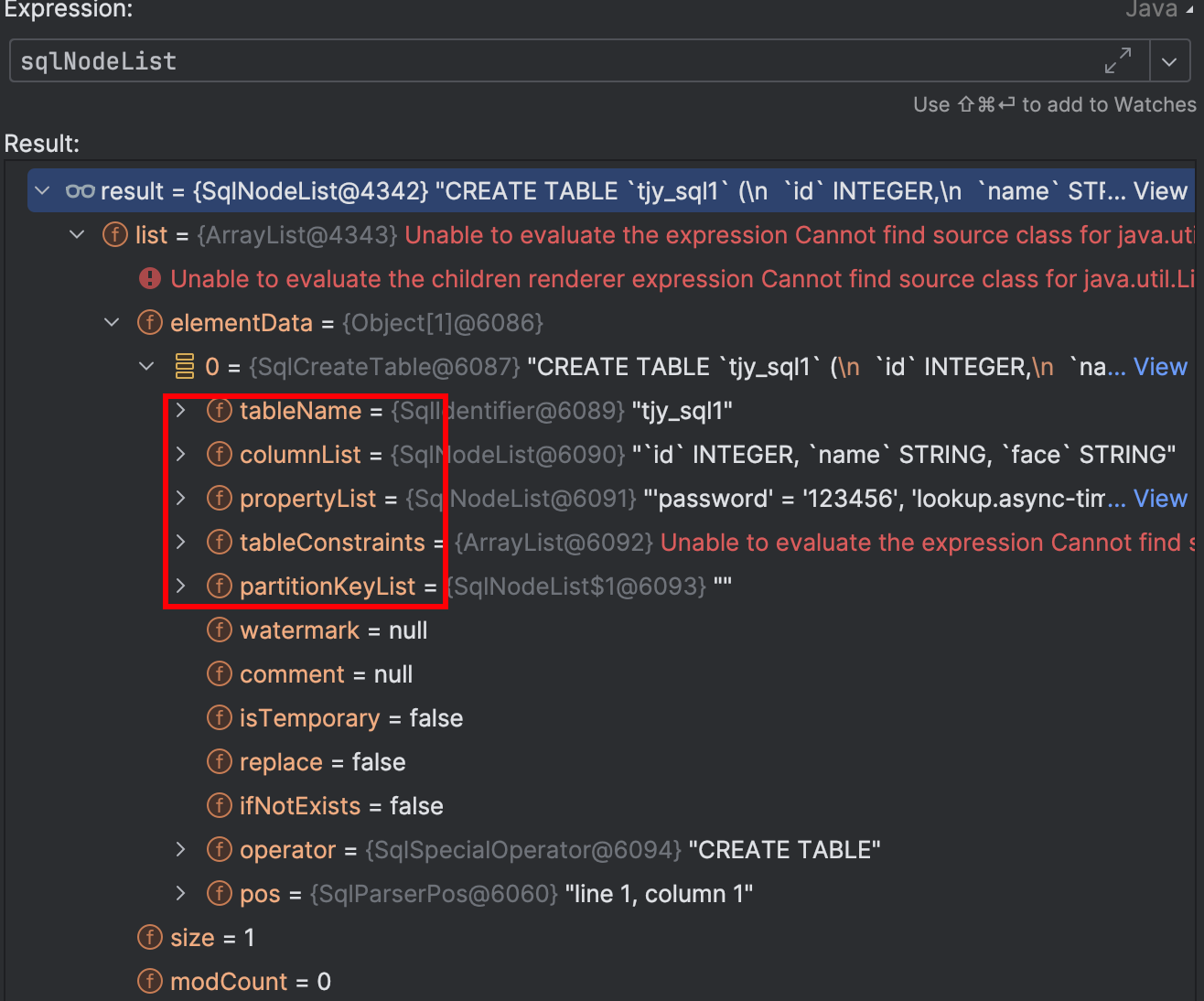
SqlNodeList sqlNodeList = parser.parseSqlList(statement);
List<SqlNode> parsed = sqlNodeList.getList();
Preconditions.checkArgument(parsed.size() == 1, "only single statement supported");
return Collections.singletonList(
//解析为SOperation
SqlToOperationConverter.convert(planner, catalogManager, parsed.get(0))
.orElseThrow(() -> new TableException("Unsupported query: " + statement)));
}
将sql语句解析成sqlNode。
对应的表名、列名、with属性参数、主键、唯一键、分区键、水印、表注释、表操作(create table、alter table、drop table。。。)都放到SqlNode对象的对应属性中,SqlNode是一个树形结构也就是AST。
2. SqlNode 验证(SqlNode – >Operation)
经过上面的第一步,会生成一个 SqlNode 对象,它是一个未经验证的抽象语法树,下面就进入了一个语法检查阶段,语法检查前需要知道元数据信息,这个检查会包括表名、字段名、函数名、数据类型的检查。
- sql解析完成后执行sql校验,flink sql中增加了SqlNode转换为Operation的过程,sql校验是这个过程中完成。
- 在SqlToOperationConvertver#convert()方法中完成这个转换,之后通过FlinkPlannerImpl#validate()方法对表、函数、字段等完成校验并基于生成的validated SqlNode生成对应的Operation。

接着进入到SqlToOperationConverter.convert方法中
/**
* This is the main entrance for executing all kinds of DDL/DML {@code SqlNode}s, different
* SqlNode will have it's implementation in the #convert(type) method whose 'type' argument is
* subclass of {@code SqlNode}.
* 转换DDL,DML(select比如?)sqlnode的主入口,不同的SqlNode有不同的convert实现。
*
*/
public static Optional<Operation> convert(
FlinkPlannerImpl flinkPlanner, CatalogManager catalogManager, SqlNode sqlNode) {
//1.进行校验
final SqlNode validated = flinkPlanner.validate(sqlNode);
//2.转换为Operation
return convertValidatedSqlNode(flinkPlanner, catalogManager, validated);
}
//将校验过的sqlnode转换为Operation
private static Optional<Operation> convertValidatedSqlNode(
FlinkPlannerImpl flinkPlanner, CatalogManager catalogManager, SqlNode validated) {
SqlToOperationConverter converter =
new SqlToOperationConverter(flinkPlanner, catalogManager);
。。。
else if (validated instanceof RichSqlInsert) {
return Optional.of(converter.convertSqlInsert((RichSqlInsert) validated));
} else if (validated.getKind().belongsTo(SqlKind.QUERY)) {
return Optional.of(converter.convertSqlQuery(validated));
但其实converter.convertSqlQuery包含了createSqlToRelConverter逻辑,即创建了SqlToRelConverter实例,用于转换RelNode。这里源码暂不展示。
3. 语义分析(Operation - > RelNode)
接着将 SqlNode 转换成 RelNode/RexNode,也就是生成相应的逻辑计划(Logical Plan),也就是最初版本的逻辑计划(Logical Plan)。
其中Operation中包含了RelNode的converter
源码见:org.apache.flink.table.planner.delegation.PlannerBase
/** Converts a relational tree of [[ModifyOperation]] into a Calcite relational expression.
将ModifyOperation转换为Calcite relational expression即RelNode
*/
@VisibleForTesting
private[flink] def translateToRel(modifyOperation: ModifyOperation): RelNode = {
val dataTypeFactory = catalogManager.getDataTypeFactory
modifyOperation match {
case s: UnregisteredSinkModifyOperation[_] =>
//relBuilder:
val input = createRelBuilder.queryOperation(s.getChild).build()
val sinkSchema = s.getSink.getTableSchema
//校验relnode的 查询schema和sink schema是否一致,以及是否需要执行cast
// validate query schema and sink schema, and apply cast if possible
val query = validateSchemaAndApplyImplicitCast(
input,
catalogManager.getSchemaResolver.resolve(sinkSchema.toSchema),
null,
dataTypeFactory,
getTypeFactory)
LogicalLegacySink.create(
query,
s.getSink,
"UnregisteredSink",
ConnectorCatalogTable.sink(s.getSink, !isStreamingMode))
....
这里触发创建relnode的调用逻辑,这里在之后statementSet.execute()后执行。
//执行flink sql的调用
。。。
//解析sql -> sqlnode
StatementSet statementSet = SqlParser.parseSql(job, jarUrlList, tableEnv);
//sqlnode->relnode
TableResult execute = statementSet.execute();
tableEnvironment.executeInternal(operations);
TableEnvironmentImpl.translate
PlannerBase.translate->translateToRel
4. 优化阶段(RelNode - > optimize - >Transformation )
即对逻辑计划优化,根据前面生成的逻辑计划按照相应的规则进行优化。
接着看tableEnvironment.executeInternal中的translate方法
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
beforeTranslation()
。。。
//转换为relnode并放到一个map中
val relNodes = modifyOperations.map(translateToRel)
//优化逻辑计划
val optimizedRelNodes = optimize(relNodes)
//生成execGraph:执行图
val execGraph = translateToExecNodeGraph(optimizedRelNodes, isCompiled = false)
//生成transformations DAG
val transformations = translateToPlan(execGraph)
afterTranslation()
transformations
}
Calcite 的核心所在,优化器进行优化的地方,如过滤条件的下压(push down),在进行 join 操作前,先进行 filter 操作,这样的话就不需要在 join 时进行全量 join,减少参与 join 的数据量等。
5. 生成ExecutionPlan并执行
最终的执行计划转为Graph图,下面的流程与真正的java代码流程就一致了。
在TableEnvironmentImpl.executeInternal中具体看executeInternal方法
TableEnvironmentImpl.executeInternal(
...
TableResultInternal result = executeInternal(transformations, sinkIdentifierNames);
...
)
private TableResultInternal executeInternal(
List<Transformation<?>> transformations, List<String> sinkIdentifierNames) {
。。。
//Translates the given transformations to a Pipeline.
//将transformations转换为pipeline
Pipeline pipeline =
execEnv.createPipeline(
transformations, tableConfig.getConfiguration(), defaultJobName);
try {
// 执行pipeline
//pipeline 其实就是StreamGraph
JobClient jobClient = execEnv.executeAsync(pipeline);
。。。
}
。。。
//执行后返回结果
return TableResult。。。
}
通过生成的Transformation对象调用 execEnv.createPipeline,生成pipeline,pipeline其实就StreamGraph便可以调用execEnv.executeAsync执行任务了。
二. 源码分析小结
上述描述了flink sql在内部执行过程进行的一些操作:
这里我们从执行sql tEnv.executeSql(stmt) 、statementSet.addInsertSql(sql); (parse、validate阶段)生成statementSet,然后执行statementSet.execute() (optimize、Execute阶段) 触发任务执行。
parse、validate阶段
通过执行以下代码触发
StatementSet statementSet = SqlParser.parseSql(job, jarUrlList, tableEnv);
statementSet.addInsertSql(sql);
tEnv.executeSql(stmt)
通过调用 tEnv.executeSql(stmt) 、statementSet.addInsertSql(sql); 进行每个sql的解析,校验,具体:
- Sql语句解析成语法树阶段(SQL - > SqlNode)
- SqlNode 验证(SqlNode – >Operation),其中Operation中包含着RelNode的convert实例,为转换逻辑计划做提前准备
optimize、Execute阶段
接着执行如下代码
//sqlnode->relnode->优化->pipeline(StreamGraph)-> 执行并返回结果
TableResult execute = statementSet.execute();
//调用链:
tableEnvironment.executeInternal(operations);
TableEnvironmentImpl.translate
PlannerBase.translate->translateToRel
经历如下几个过程:
sqlnode->relnode->优化->pipeline(StreamGraph)-> 执行并返回结果
这里我们主要看executeInternal的逻辑
public TableResultInternal executeInternal(List<ModifyOperation> operations) {
List<ModifyOperation> mapOperations = new ArrayList<>();
for (ModifyOperation modify : operations) {
//1.先执行CTAS sql语句, 并放到mapOperations中进行translate操作
// execute CREATE TABLE first for CTAS statements
if (modify instanceof CreateTableASOperation) {
CreateTableASOperation ctasOperation = (CreateTableASOperation) modify;
executeInternal(ctasOperation.getCreateTableOperation());
mapOperations.add(ctasOperation.toSinkModifyOperation(catalogManager));
} else {
//2. 将其他非CTAS sqlnode放到mapOperations,进行translate操作
mapOperations.add(modify);
}
}
//translate主要的逻辑是:将所有的sqlNodes转换为relNodes,为初始的逻辑计划,然后优化逻辑计划,
//接着翻译 ExecNodeGraph 为 Transformation DAG.
List<Transformation<?>> transformations = translate(mapOperations);
List<String> sinkIdentifierNames = extractSinkIdentifierNames(mapOperations);
// transformations转换为pipeline,最终执行pipeline即StreamGraph,然后返回结果
TableResultInternal result = executeInternal(transformations, sinkIdentifierNames);
if (tableConfig.get(TABLE_DML_SYNC)) {
try {
result.await();
} catch (InterruptedException | ExecutionException e) {
result.getJobClient().ifPresent(JobClient::cancel);
throw new TableException("Fail to wait execution finish.", e);
}
}
return result;
}




















![[足式机器人]Part4 南科大高等机器人控制课 Ch08 Rigid Body Dynamics](https://img-blog.csdnimg.cn/direct/fb1b92de2d7e4804b8b0834d964ab443.png)