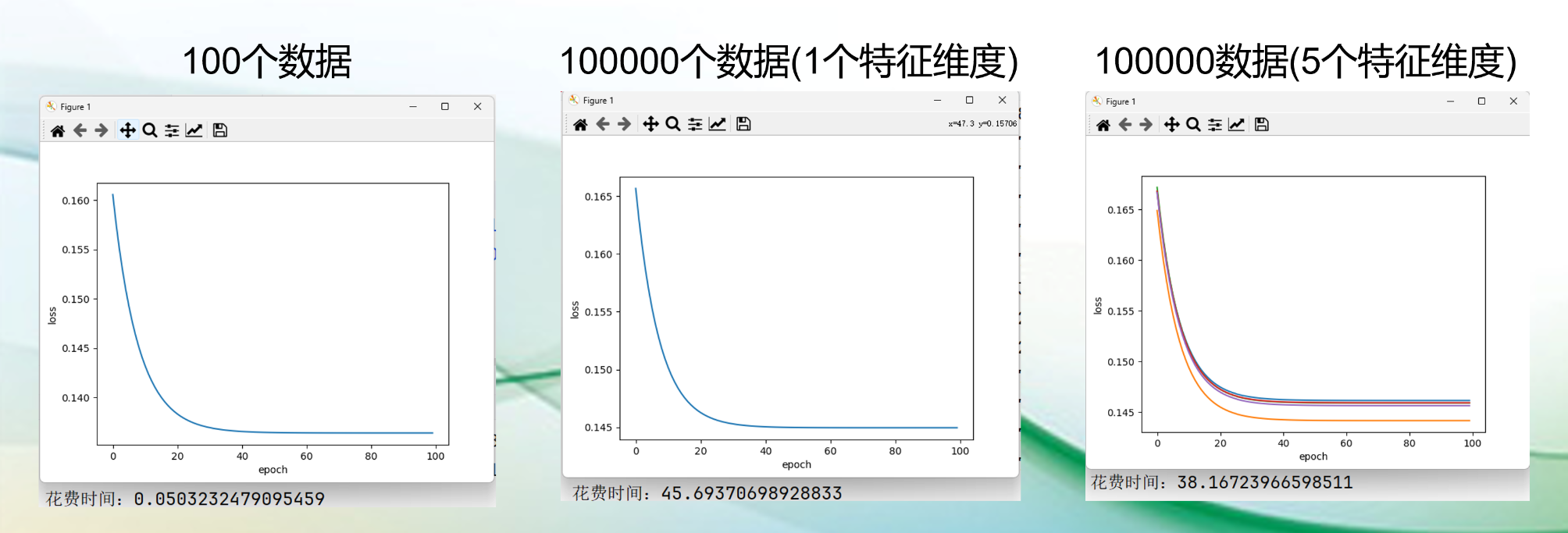
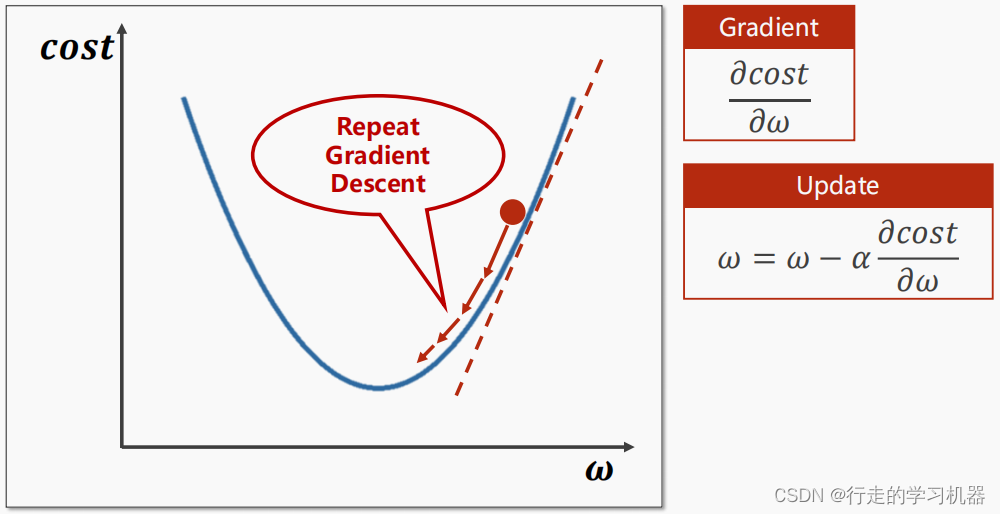
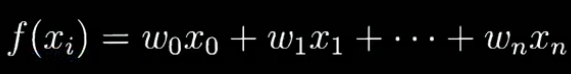Optimizer 优化
学习率 l e a r n i n g r a t e : α 学习率learning\;rate: \alpha 学习率learningrate:α
防止除 0 的截断参数 : ϵ 防止除0的截断参数: \epsilon 防止除0的截断参数:ϵ
t 时刻的参数 : W t t\;时刻的参数: W_{t} t时刻的参数:Wt
t 时刻的梯度: g t t\;时刻的梯度:g_{t} t时刻的梯度:gt
t 时刻的神经网络 : f ( x ; W t ) t\;时刻的神经网络: f(x;W_{t}) t时刻的神经网络:f(x;Wt)
t 时刻的梯度 g t 的一阶动量 : m t t\;时刻的梯度g_{t}的一阶动量: m_{t} t时刻的梯度gt的一阶动量:mt
t 时刻的梯度 g t 的二阶动量 : v t t\;时刻的梯度g_{t}的二阶动量: v_{t} t时刻的梯度gt的二阶动量:vt
一阶动量历史权重 : β 1 一阶动量历史权重: \beta_{1} 一阶动量历史权重:β1
二阶动量历史权重 : β 2 二阶动量历史权重: \beta_{2} 二阶动量历史权重:β2
权重衰减项权重: λ 权重衰减项权重:\lambda 权重衰减项权重:λ
1 SGD
SGD(Stochastic Gradient Descent)随机梯度下降算法,在深度学习中是一个最基础的优化算法,相比于传统凸优化所使用的梯度下降算法GD,SGD是在一个mini-batch中进行的。
公式如下:
g t = ∇ f ( x ; W t − 1 ) g_{t}=\nabla f(x;W_{t-1}) gt=∇f(x;Wt−1) W t = W t − 1 − α g t W_{t}=W_{t-1}-\alpha g_{t} Wt=Wt−1−αgt
即计算一个mini-batch中的损失函数的梯度,之后根据学习率进行更新,SGD可能存在的问题是,更新幅度与梯度线性相关,一方面网络不同层之间参数数值分布可能很不一致,这导致学习率的选择困难,不同层之间的更新速度不一致;另一方面,不利于摆脱局部极小值,SGD对于局部极小值的摆脱能力来源于Stochastic,即mini-batch中的样本随机,而非GD的全局选择,给予了一定的摆脱能力。
2 mSGD
mSGD(Moving Average SGD)是SGD的改进算法,在SGD的基础上引入了动量,从而平滑了参数的更新,并且给予了一定摆脱局部极小值的能力。
公式如下:
g t = ∇ f ( x ; W t − 1 ) g_{t}=\nabla f(x;W_{t-1}) gt=∇f(x;Wt−1) m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t=\beta_{1}m_{t-1}+(1-\beta_{1})g_{t} mt=β1mt−1+(1−β1)gt W t = W t − 1 − α m t W_{t}=W_{t-1}-\alpha m_{t} Wt=Wt−1−αmt
即使参数到达了一个局部最小值点,由于动量 m t m_{t} mt的存在,类似于惯性,优化参数会冲过一部分的局部极小值或者鞍点。
3 AdaGrad
AdaGrad(Adaptive Gradient)算法是一种自适应学习率的算法,其根据历史梯度平方和的大小,动态调整学习率,使得学习率逐渐下降。
公式如下:
g t = ∇ f ( x ; W t − 1 ) g_{t}=\nabla f(x;W_{t-1}) gt=∇f(x;Wt−1) W t = W t − 1 − α g t ∑ i = 1 t g i 2 + ϵ W_{t}=W_{t-1}-\alpha \frac{g_{t}}{\sqrt{\sum_{i=1}^t g_{i}^2}+\epsilon} Wt=Wt−1−α∑i=1tgi2+ϵgt
AdaGrad根据过往的梯度平方和动态调整学习率,其优点是学习率自适应,缺点是学习率单调下降,且受极易历史极端梯度大小影响,可能导致后续学习率过小,无法跳出局部极小值。
4 RMSProp
RMSProp(Root Mean Square Propagation)算法是对AdaGrad的改进,引入momentum,使得学习率下降更加平滑,不易受到极端梯度的影响。
公式如下:
g t = ∇ f ( x ; W t − 1 ) g_{t}=\nabla f(x;W_{t-1}) gt=∇f(x;Wt−1) v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_{2}v_{t-1}+(1-\beta_{2})g_{t}^2 vt=β2vt−1+(1−β2)gt2 W t = W t − 1 − α g t v t + ϵ W_{t}=W_{t-1}-\alpha \frac{g_{t}}{\sqrt{v_{t}}+\epsilon} Wt=Wt−1−αvt+ϵgt
RMSRrop改进了AdaGrad,也为Adamting算法提供了基础。
5 Adam
Adam(Adaptive Momentum)算法身上明显沿用了RMSProp和mSGD的优点,同时结合了动量与自适应学习率,其同时使用了一阶动量和二阶动量,使得Adam算法在收敛速度上优于RMSProp,且具有较好的自适应性。
且针对,一阶动量和二阶动量的初始化问题,若初始化为0,则需要很长时间才能累计达到一个基本的学习率,因此Adam算法采用了一个随时间变化的补偿项,使得一阶动量在刚开始时具有更大的值,且在后期逐渐衰减。
公式如下:
g t = ∇ f ( x ; W t − 1 ) g_{t}=\nabla f(x;W_{t-1}) gt=∇f(x;Wt−1) m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t=\beta_1m_{t-1}+(1-\beta_1)g_{t} mt=β1mt−1+(1−β1)gt v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_2v_{t-1}+(1-\beta_2)g_{t}^2 vt=β2vt−1+(1−β2)gt2 m t ^ = m t 1 − β 1 t \hat{m_t}=\frac{m_t}{1-\beta_1^t} mt^=1−β1tmt v t ^ = v t 1 − β 2 t \hat{v_t}=\frac{v_t}{1-\beta_2^t} vt^=1−β2tvt W t = W t − 1 − α m t ^ v t ^ + ϵ W_{t}=W_{t-1}-\alpha \frac{\hat{m_t}}{\sqrt{\hat{v_t}}+\epsilon} Wt=Wt−1−αvt^+ϵmt^
可以看到Adam同时采用了一阶动量和二阶动量,并且采用了 1 1 + β t \frac{1}{1+\beta^t} 1+βt1的形式对于动量进行补偿,从而有着极强的自适应能力,是如今最常用的优化算法之一。
6 AdamW
AdamW算法是对Adam算法的纠错,其引入了权重衰减(weight decay),在过往的Adam算法中,面对有着正则项的损失函数时,往往对于正则项的处理为第一步 g t g_t gt中:
A d a m 处理 ( 错误 ) : g t = ∇ f ( x ; W t − 1 ) + 2 λ W t − 1 Adam处理(错误):g_{t}=\nabla f(x;W_{t-1})+2\lambda W_{t-1} Adam处理(错误):gt=∇f(x;Wt−1)+2λWt−1
而AdamW算法中,修正了这一错误,将正则项在最后一步权重更新时进行处理,即weight decay不参与动量计算,公式为:
W t = W t − 1 − α ( m t ^ v t ^ + ϵ + 2 λ W t − 1 ) W_{t}=W_{t-1}-\alpha (\frac{\hat{m_t}}{\sqrt{\hat{v_t}}+\epsilon}+2\lambda W_{t-1}) Wt=Wt−1−α(vt^+ϵmt^+2λWt−1)
7 总结
以上就是最常用的优化器SGD、mSGD、AdaGrad、RMSProp、Adam、AdamW的总结,其中AdamW算法是Adam算法的改进,SGD在CNN中还有不错的发挥,但在Transformer中却效果一般,如今Adam和AdamW算法在Transformer模型中有着更为广泛的应用,如Llama、OPT、GPT等,即使还有一些新的如Lion等优化器,但大体上了解以上优化器就足够了。