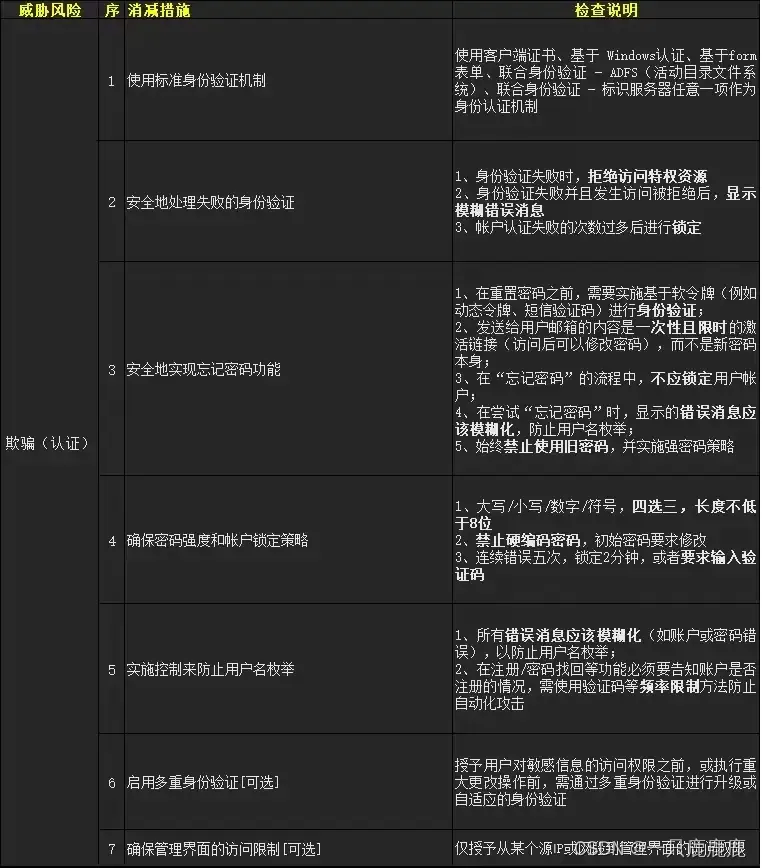
第四章 机器学习
三、数据预处理
1. 数据预处理的目的
去除无效数据、不规范数据、错误数据
补齐缺失值
对数据范围、量纲、格式、类型进行统一化处理,更容易进行后续计算
2. 预处理方法
2.1 标准化(均值移除)
让样本矩阵中的每一列的平均值为 0,标准差为 1。如有三个数 a, b, c,则平均值为:
m = ( a + b + c ) / 3 a ′ = a − m b ′ = b − m c ′ = c − m m = (a + b + c) / 3 \\ a' = a - m \\ b' = b - m \\ c' = c - m m=(a+b+c)/3a′=a−mb′=b−mc′=c−m
预处理后的平均值为 0:
( a ′ + b ′ + c ′ ) / 3 = ( ( a + b + c ) − 3 m ) / 3 = 0 (a' + b' + c') / 3 =( (a + b + c) - 3m) / 3 = 0 (a′+b′+c′)/3=((a+b+c)−3m)/3=0
预处理后的标准差:
s = s q r t ( ( ( a − m ) 2 + ( b − m ) 2 + ( c − m ) 2 ) / 3 ) s = sqrt(((a - m)^2 + (b - m)^2 + (c - m)^2)/3) s=sqrt(((a−m)2+(b−m)2+(c−m)2)/3)
a ′ ′ = a / s a'' = a / s a′′=a/s
b ′ ′ = b / s b'' = b / s b′′=b/s
c ′ ′ = c / s c'' = c / s c′′=c/s
s ′ ′ = s q r t ( ( ( a ′ / s ) 2 + ( b ′ / s ) 2 + ( c ′ / s ) 2 ) / 3 ) s'' = sqrt(((a' / s)^2 + (b' / s) ^ 2 + (c' / s) ^ 2) / 3) s′′=sqrt(((a′/s)2+(b′/s)2+(c′/s)2)/3)
= s q r t ( ( a ′ 2 + b ′ 2 + c ′ 2 ) / ( 3 ∗ s 2 ) ) =sqrt((a'^2 + b'^2 + c'^2) / (3 *s ^2)) =sqrt((a′2+b′2+c′2)/(3∗s2))
= 1 =1 =1
标准差:又称均方差,是离均差平方的算术平均数的平方根,用 σ 表示 ,标准差能反映一个数据集的离散程度。
代码示例:
# 数据预处理之:均值移除示例
import numpy as np
import sklearn.preprocessing as sp
# 样本数据
raw_samples = np.array([
[3.0, -1.0, 2.0],
[0.0, 4.0, 3.0],
[1.0, -4.0, 2.0]
])
print(raw_samples)
print(raw_samples.mean(axis=0)) # 求每列的平均值
print(raw_samples.std(axis=0)) # 求每列标准差
std_samples = raw_samples.copy() # 复制样本数据
for col in std_samples.T: # 遍历每列
col_mean = col.mean() # 计算平均数
col_std = col.std() # 求标准差
col -= col_mean # 减平均值
col /= col_std # 除标准差
print(std_samples)
print(std_samples.mean(axis=0))
print(std_samples.std(axis=0))
"""
[[ 3. -1. 2.]
[ 0. 4. 3.]
[ 1. -4. 2.]]
[ 1.33333333 -0.33333333 2.33333333]
[1.24721913 3.29983165 0.47140452]
[[ 1.33630621 -0.20203051 -0.70710678]
[-1.06904497 1.31319831 1.41421356]
[-0.26726124 -1.1111678 -0.70710678]]
[ 5.55111512e-17 0.00000000e+00 -2.96059473e-16]
[1. 1. 1.]
"""
也可以通过 sklearn 提供 sp.scale 函数实现同样的功能,如下面代码所示:
std_samples = sp.scale(raw_samples) # 求标准移除
print(std_samples)
print(std_samples.mean(axis=0))
print(std_samples.std(axis=0))
"""
[[ 1.33630621 -0.20203051 -0.70710678]
[-1.06904497 1.31319831 1.41421356]
[-0.26726124 -1.1111678 -0.70710678]]
[ 5.55111512e-17 0.00000000e+00 -2.96059473e-16]
[1. 1. 1.]
"""
2.2 范围缩放
将样本矩阵中的每一列最小值和最大值设定为相同的区间,统一各特征值的范围.如有 a, b, c 三个数,其中 b 为最小值,c 为最大值,则:
a ′ = a − b a' = a - b a′=a−b
b ′ = b − b b' = b - b b′=b−b
c ′ = c − b c' = c - b c′=c−b
缩放计算方式如下公式所示:
a ′ ′ = a ′ / c ′ a'' = a' / c' a′′=a′/c′
b ′ ′ = b ′ / c ′ b'' = b' / c' b′′=b′/c′
c ′ ′ = c ′ / c ′ c'' = c' / c' c′′=c′/c′
计算完成后,最小值为 0,最大值为 1。以下是一个范围缩放的示例。
# 数据预处理之:范围缩放
import numpy as np
import sklearn.preprocessing as sp
# 样本数据
raw_samples = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]]).astype("float64")
# print(raw_samples)
mms_samples = raw_samples.copy() # 复制样本数据
for col in mms_samples.T:
col_min = col.min()
col_max = col.max()
col -= col_min
col /= (col_max - col_min)
print(mms_samples)
"""
[[0. 0. 0. ]
[0.5 0.5 0.5]
[1. 1. 1. ]]
"""
也可以通过 sklearn 提供的对象实现同样的功能,如下面代码所示:
# 根据给定范围创建一个范围缩放器对象
mms = sp.MinMaxScaler(feature_range=(0, 1))# 定义对象(修改范围观察现象)
# 使用范围缩放器实现特征值范围缩放
mms_samples = mms.fit_transform(raw_samples) # 缩放
print(mms_samples)
"""
[[0. 0. 0. ]
[0.5 0.5 0.5]
[1. 1. 1. ]]
"""
执行结果:
[[0. 0. 0. ]
[0.5 0.5 0.5]
[1. 1. 1. ]]
[[0. 0. 0. ]
[0.5 0.5 0.5]
[1. 1. 1. ]]
3. 归一化 Normalize
反映样本所占比率。
用每个样本的每个特征值,除以该样本各个特征值绝对值之和。
变换后的样本矩阵,每个样本的特征值绝对值之和为 1。
例如如下反映编程语言热度的样本中,2018 年也 2017 年比较,Python 开发人员数量减少了 2 万,但是所占比率确上升了:
| 年份 | Python(万人) | Java(万人) | PHP(万人) |
|---|---|---|---|
| 2017 | 10 | 20 | 5 |
| 2018 | 8 | 10 | 1 |
归一化预处理示例代码如下所示:
# 数据预处理之:归一化
import numpy as np
import sklearn.preprocessing as sp
# 样本数据
raw_samples = np.array([
[10.0, 20.0, 5.0],
[8.0, 10.0, 1.0]
])
print(raw_samples)
nor_samples = raw_samples.copy() # 复制样本数据
for row in nor_samples:
row /= abs(row).sum() # 先对行求绝对值,再求和,再除以绝对值之和
print(nor_samples) # 打印结果
"""
[[10. 20. 5.]
[ 8. 10. 1.]]
[[0.28571429 0.57142857 0.14285714]
[0.42105263 0.52631579 0.05263158]]
"""
在 sklearn 库中,可以调用 sp.normalize()函数进行归一化处理,函数原型为:
sp.normalize(原始样本, norm='l2')
# l1: l1范数,除以向量中各元素绝对值之和
# l2: l2范数,除以向量中各元素平方之和
使用 sklearn 库中归一化处理代码如下所指示:
nor_samples = sp.normalize(raw_samples, norm='l1')
print(nor_samples) # 打印结果
"""
[[0.28571429 0.57142857 0.14285714]
[0.42105263 0.52631579 0.05263158]]
"""
4. 二值化
根据一个事先给定的阈值,用 0 和 1 来表示特征值是否超过阈值.以下是实现二值化预处理的代码:
# 二值化
import numpy as np
import sklearn.preprocessing as sp
raw_samples = np.array([[65.5, 89.0, 73.0],
[55.0, 99.0, 98.5],
[45.0, 22.5, 60.0]])
bin_samples = raw_samples.copy() # 复制数组
# 生成掩码数组
mask1 = bin_samples < 60
mask2 = bin_samples >= 60
# 通过掩码进行二值化处理
bin_samples[mask1] = 0
bin_samples[mask2] = 1
print(bin_samples) # 打印结果
"""
[[1. 1. 1.]
[0. 1. 1.]
[0. 0. 1.]]
"""
同样,也可以利用 sklearn 库来处理:
bin = sp.Binarizer(threshold=59) # 创建二值化对象(注意边界值)
bin_samples = bin.transform(raw_samples) # 二值化预处理
print(bin_samples)
"""
[[1. 1. 1.]
[0. 1. 1.]
[0. 0. 1.]]
"""
二值化编码会导致信息损失,是不可逆的数值转换。如果进行可逆转换,则需要用到独热编码。
5. 独热编码
根据一个特征中不重复值的个数来建立一个由一个 1 和若干个 0 组成的序列,用来序列对所有的特征值进行编码。例如有如下样本:
[ 1 3 2 7 5 4 1 8 6 7 3 9 ] \left[ \begin{matrix} 1 & 3 & 2\\ 7 & 5 & 4\\ 1 & 8 & 6\\ 7 & 3 & 9\\ \end{matrix} \right] 171735832469
对于第一列,有两个值,1 使用 10 编码,7 使用 01 编码
对于第二列,有三个值,3 使用 100 编码,5 使用 010 编码,8 使用 001 编码
对于第三列,有四个值,2 使用 1000 编码,4 使用 0100 编码,6 使用 0010 编码,9 使用 0001 编码
编码字段,根据特征值的个数来进行编码,通过位置加以区分.通过独热编码后的结果为:
[ 10 100 1000 01 010 0100 10 001 0010 01 100 001 ] \left[ \begin{matrix} 10 & 100 & 1000\\ 01 & 010 & 0100\\ 10 & 001 & 0010\\ 01 & 100 & 001\\ \end{matrix} \right] 10011001100010001100100001000010001
使用 sklearn 库提供的功能进行独热编码的代码如下所示:
# 独热编码示例
import numpy as np
import sklearn.preprocessing as sp
raw_samples = np.array([[1, 3, 2],
[7, 5, 4],
[1, 8, 6],
[7, 3, 9]])
one_hot_encoder = sp.OneHotEncoder(
sparse=False, # 是否采用稀疏格式
dtype="int32",
categories="auto")# 自动编码
oh_samples = one_hot_encoder.fit_transform(raw_samples) # 执行独热编码
print(oh_samples)
print(one_hot_encoder.inverse_transform(oh_samples)) # 解码
执行结果:
[[1 0 1 0 0 1 0 0 0]
[0 1 0 1 0 0 1 0 0]
[1 0 0 0 1 0 0 1 0]
[0 1 1 0 0 0 0 0 1]]
[[1 3 2]
[7 5 4]
[1 8 6]
[7 3 9]]
6. 标签编码
根据字符串形式的特征值在特征序列中的位置,来为其指定一个数字标签,用于提供给基于数值算法的学习模型。
代码如下所示:
# 标签编码
import numpy as np
import sklearn.preprocessing as sp
raw_samples = np.array(['audi', 'ford', 'audi',
'bmw','ford', 'bmw'])
lb_encoder = sp.LabelEncoder() # 定义标签编码对象
lb_samples = lb_encoder.fit_transform(raw_samples) # 执行标签编码
print(lb_samples)
print(lb_encoder.inverse_transform(lb_samples)) # 逆向转换
执行结果:
[0 2 0 1 2 1]
['audi' 'ford' 'audi' 'bmw' 'ford' 'bmw']
四、练习
1. 判断以下哪个是回归问题,哪个是分类问题,哪个是聚类问题。
判断一封邮件是否为垃圾邮件(分类)
在图像上检测出人脸的位置(回归,预测 x,y,w,h 四个值,每个值都是连续的)
视频网站根据用户观看记录,找出喜欢看战争电影的用户(聚类)
2. 分类和聚类主要区别是什么?
- 分类是有监督学习,聚类是无监督学习
3. 判断以下哪些是数据降维问题
- 将 8*8 的矩阵缩小为 4*4 的矩阵(是)
- 将二维矩阵变形为一维向量(是)
- 将高次方程模型转换为低次方程模型(是)