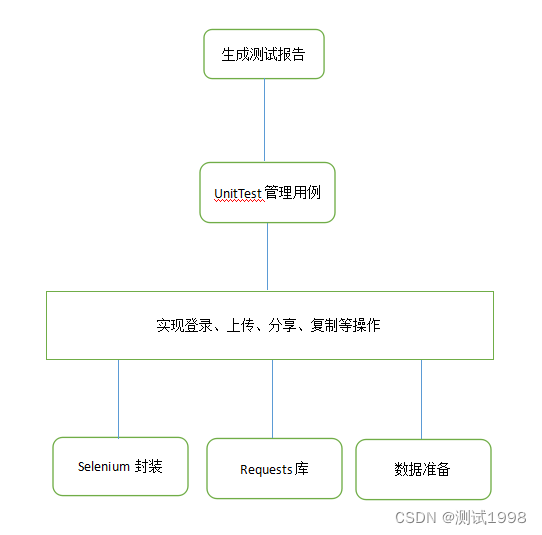
问题一:配送服务是否存在问题
import os
import pandas as pd
inport numpy as np
import matplotlib.pylot as plt
plt.rcParams['font.sans_serif'] = 'SimHei'
##设置中文显示
数据清洗
data = pd.read_excel('',encoding = 'gbk')
data.info()
通过info可以看出,包括10列数据,名字,数据量,格式等,可以得出:
1.订单号,货品交货情况,数量:存在缺失值,但是确实量不大,可以删除
2,订单行,对分析无关紧要,可以考虑删除
3,销售金额格式不对(万元|元,逗号问题),数据类型需要转换成int|float
#删除重复记录
data.drop_duplicates(keep='first',inplace=True)
#删除缺失值(na,删除待有na的整行数据,axis=0,how='any’默认值)
data.dropna(axis=0,how='any',inplace=True)
#删除订单行
data.drop(columns=['订单行'],inplace=True,axis=1)
异常值处理
data.describe()
describe () 函数可以查看数据的基本情况,包括:count 非空值数、mean 平均值、std 标准差、max 最大值、min 最小值、(25%、50%、75%)分位数等。
#销售金额==0,采用删除方法,因为数据量很小
data = data[data['销售金额']!=0]
data.describe()
数据规整
data['销售时间'] = pd.to_datetime(data['销售时间'])
data['月份'] = data['销售时间'].apply(lambda x:x.month) #把月份取出来
data
第三步 核心 数据分析
解决问题
1,配送服务是否存在问题
从月份维度 (操作起来就是分组然后算这个率那个率)
以月份分组,计算按时交货率
data1 = data.groupby[['','']].size().unstack()
data1['按时交货率']=data1['']/(data1['']+data1[''])
#从按时交货率来看,第四极季度低于第三季度,猜测可能是气候原因造成
那么str.strip()就是把这个字符串头和尾的空格,以及位于头尾的\n \t之类给删掉。
从销售区域维度
data1 = data.groupby[['','']].size().unstack()
data1['按时交货率']=data1['']/(data1['']+data1[''])
print(data1.sort_values(by ='按时交货率',ascending = False))
#西北地区存在突出的延时交货问题,需要解决
货品维度
data1 = data.groupby[['货品','货品交货状况']].size().unstack()
data1['按时交货率']=data1['按时交货']/(data1['按时交货']+data1['晚交货'])
print(data1.sort_values(by ='按时交货率',ascending = False))
#货品4晚交货情况非常严重,其余货品的相对较好的
货品和销售区域结合
data1 = data.groupby[['货品','销售区域','货品交货状况']].size().unstack()
data1['按时交货率']=data1['按时交货']/(data1['按时交货']+data1['晚交货'])
print(data1.sort_values(by ='按时交货率',ascending = False))
#销售区域;最差在西北地区,货品有1和4,主要是货品4送货较晚导致
#货品:最差的货品2,主要送往华东和马来西亚,主要是马来西亚的送货较晚导致
问题二:是否存在尚有潜力的销售区域
月份维度
data1=data.groupby(['月份','货品'])['数量'].sum().unstack()
data1.plot(kind=;line;)
#货品2在10月和12月份,销量猛增,原因猜测有二:1.公司加大营销力度 2.开发了新的市场
不同区域
data1=data.groupby(['销售区域','货品'])['数量'].sum().unstack()
data1.plot(kind=;line;)
#从销售区域看,每种货品销售区域为1~3个,货品1有三个销售区域,货品2有两个销售区域,其余货品均有1个销售区域
月份和区域维度
data1 = data.groupby(['月份','销售区域','货品'])['数量'].sum().unstack()
data1['货品2']
#货品2在10月12月份销量猛增,原因主要发生在原有销售区域(华东)
#同样,分析出在7,8,9,11月份销售数量还有很大提升空间,可以适当加大营销力度
问题三:商品是否存在质量问题
data['货品用户反馈'] = data['货品用户反馈'].str.strip() #取出首位空格
data1=data.groupby(['货品','销售区域'])['货品用户反馈'].value_counts().unstack()
data1['拒货率'] = data1['拒货']/data1.sum(axis=1)
data1['返修率'] = data1['返修']/data1.sum(axis=1)
data1['质量合格率'] = data1['质量合格']/data1.sum(axis=1)
data.sort_values(['拒货','返修','质量合格',],ascending=False)
#货品3.6.5合格率均较高,返修率比较低,说明质量还可以
#货品1,2,3合格率较低,返修率较高,质量存在一定问题,需要改善
#货品2在马来西亚的拒货率最高,同时,在货品2在马来西亚的按时交货率也非常低