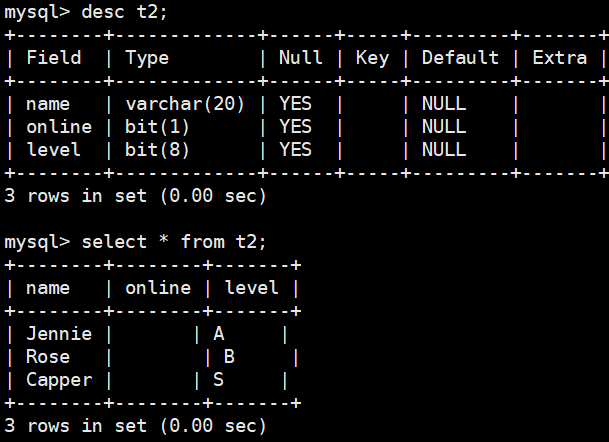
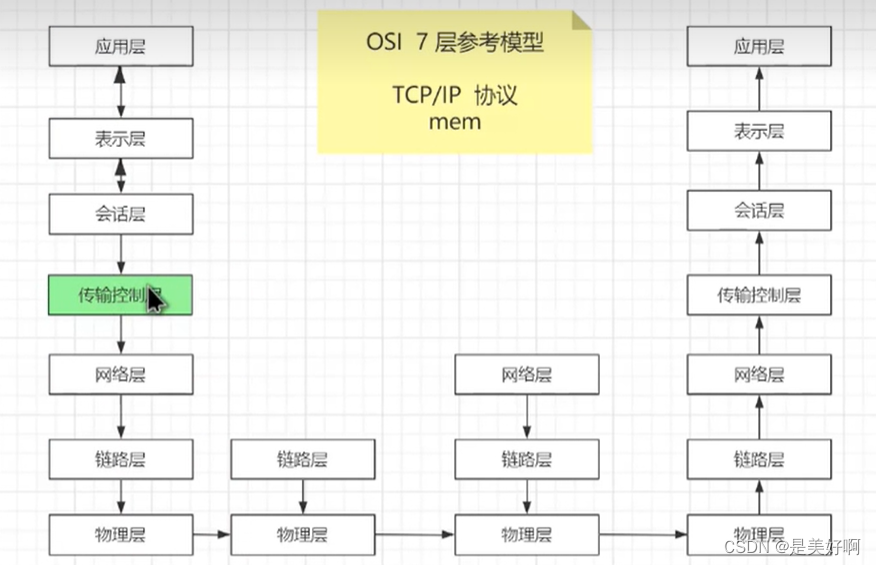
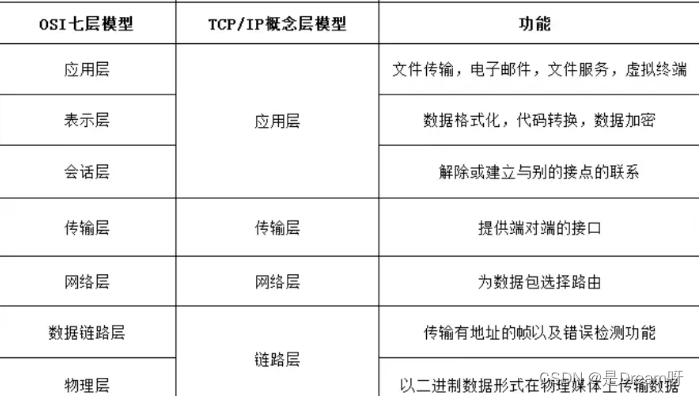
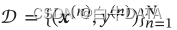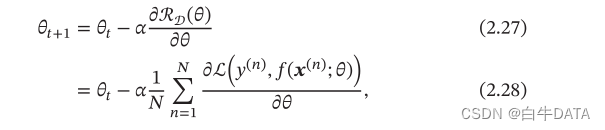机器学习三个基本要素:模型、学习准则、优化算法。
模型
对于一个机器学习任务,首先要确定其输入空间x 和输出空间y。不同机器学习任务的主要区别在于输出空间不同。在二分类问题中y ={+1 ,−1},在C 分类问题中y ={1 ,2 , ⋯ ,C},而在回归问题中y =R。
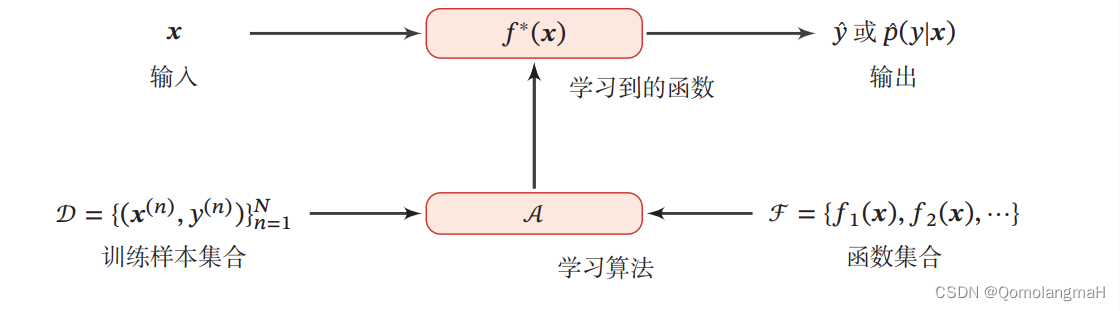
输入空间 x 和输出空间y 构成了一个样本空间。对于样本空间中的样本(𝒙 ,y ) ∈ X×Y,假定 x 和 u 之间的关系可以通过一个未知的真实映射函数y=𝑔(x) 或真实条件概率分布p(𝑦|x )来描述。机器学习的目标是找到一个模型来近似真实映射函数𝑔(x)或真实条件概率分布p(𝑦|x)。
由于我们不知道真实的映射函数𝑔(x)或条件概率分布p(𝑦|x)的具体形式,因而只能根据经验来假设一个函数集合ℱ,称为假设空间(Hypothesis Space),然后通过观测其在训练集 D 上的特性,从中选择一个理想的假设(Hypothesis)f *∈ ℱ。
假设空间ℱ 通常为一个参数化的函数族
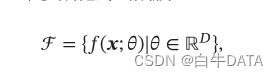
其中𝑓(x;θ)是参数为θ 的函数,也称为模型(Model),D 为参数的数量。
常见的假设空间可以分为线性和非线性两种,对应的模型 f 也分别称为线性模型和非线性模型。
线性模型
线性模型的假设空间为一个参数化的线性函数族,即
![]()
其中参数θ 包含了权重向量ω和偏置b.
非线性模型
广义的非线性模型可以写为多个非线性基函数𝜙(x)的线性组合
![]()
其中𝜙(x)=[𝜙1(𝒙) ,𝜙2(𝒙) , ⋯ ,𝜙k(𝒙)]^T 为K 个非线性基函数组成的向量,参数 θ包含了权重向量ω和偏置b。
如果𝜙(x)本身为可学习的基函数,比如
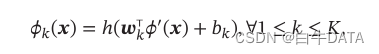
其中 ℎ(⋅) 为非线性函数,𝜙′(𝒙 为另一组基函数,ωk 和 bk为可学习的参数,则𝑓(x;θ)就等价于神经网络模型。