简介
CompletableFuture相比于Java8的并行流,对于处理并发的IO密集型任务有着得天独厚的优势:
- 在流式编程下,支持构建任务流时即可执行任务。
- CompletableFuture任务支持提交到自定义线程池,调优方便。
本文所有案例都会基于这样的一个需求,某网站有多个商家,用户会在不同的店铺查看同一件商品,只要用户在提供给商店对应的产品名称,商店就会返回对应产品的最终价格。
该需求有几个注意点:
- 每次到一家商店查询时,同一时间只能查询一个商品。
- 允许用户同一时间在系统里查询多个商店的一个商品。
- 查询的商品售价是需要耗时的,平均500ms-2500ms不等。
- 为了更直观了解代码性能,我们的例子用户每次会去家左右的店铺分别查询一件商品。

这里介绍一下,这些功能所要用到的类,首先是商家类,核心方法getPrice会根据用户传入的产品名称返回售价,代码执行时会休眠一段时间返回用户产品最终价格。
/**
* 商店
*/
public class Shop {
private final String name;
private final Random random;
public Shop(String name) {
this.name = name;
random = new Random(name.charAt(0) * name.charAt(1) * name.charAt(2));
}
/**
* 传入产品名称返回对应价格和折扣代码
* @param product 产品名称
* @return
*/
public String getPrice(String product) {
double price = calculatePrice(product);
Discount.Code code = Discount.Code.values()[random.nextInt(Discount.Code.values().length)];
return name + ":" + price + ":" + code;
}
/**
* 获取商品价格
* @param product
* @return
*/
public double calculatePrice(String product) {
try {
TimeUnit.MILLISECONDS.sleep(RandomUtil.randomInt(500,2500));
} catch (InterruptedException e) {
e.printStackTrace();
}
return (int)(random.nextDouble() * product.charAt(0) + product.charAt(1));
}
public String getName() {
return name;
}
}
同时我们也给出了18个商家的列表。
private final static List<Shop> shops = Arrays.asList(new Shop("Nike"),
new Shop("Apple"),
new Shop("Coca-Cola"),
new Shop("Amazon"),
new Shop("Samsung"),
new Shop("McDonald's"),
new Shop("Mercedes-Benz"),
new Shop("Google"),
new Shop("Louis Vuitton"),
new Shop("Chanel"),
new Shop("Gucci"),
new Shop("Adidas"),
new Shop("Pepsi"),
new Shop("Ford"),
new Shop("Microsoft"),
new Shop("Rolex"),
new Shop("Ferrari"),
new Shop("IKEA")
);
实现
顺序流
第一版我们先用顺序流实现改需求,代码很简单用stream遍历商家并调用getPrice获得结果,最终存到List中。
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<String> resultList = shops.stream()
.map(shop -> shop.getName() + " price is " + shop.getPrice("Air Jordan"))
.collect(Collectors.toList());
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + (end - begin)+"ms");
}
最终输出结果如下,可以看到用了快30s。
执行结束,执行结果:["Nike price is Nike:112.0:GOLD","Apple price is Apple:135.0:DIAMOND","Coca-Cola price is Coca-Cola:111.0:DIAMOND","Amazon price is Amazon:155.0:GOLD","Samsung price is Samsung:165.0:SILVER","McDonald's price is McDonald's:164.0:PLATINUM","Mercedes-Benz price is Mercedes-Benz:111.0:DIAMOND","Google price is Google:121.0:NONE","Louis Vuitton price is Louis Vuitton:168.0:PLATINUM","Chanel price is Chanel:131.0:NONE","Gucci price is Gucci:132.0:SILVER","Adidas price is Adidas:133.0:PLATINUM","Pepsi price is Pepsi:158.0:SILVER","Ford price is Ford:113.0:PLATINUM","Microsoft price is Microsoft:156.0:GOLD","Rolex price is Rolex:126.0:GOLD","Ferrari price is Ferrari:163.0:DIAMOND","IKEA price is IKEA:150.0:NONE"] 执行耗时:27409ms
并行流
对此我们采用并行流尝试以多线程的形式执行任务,所以我们将stream改为parallelStream。
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<String> resultList = shops.parallelStream()
.map(shop -> shop.getName() + " price is " + shop.getPrice("Air Jordan"))
.collect(Collectors.toList());
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + ((end - begin)/1000)+"s");
}
可以看到耗时仅仅5s,这里补充一下笔者的机器信息,笔者的CPU是6核的,所以并行流执行时会有6个线程在同时工作。
执行结束,执行结果:["Nike price is Nike:112.0:GOLD","Apple price is Apple:135.0:DIAMOND","Coca-Cola price is Coca-Cola:111.0:DIAMOND","Amazon price is Amazon:155.0:GOLD","Samsung price is Samsung:165.0:SILVER","McDonald's price is McDonald's:164.0:PLATINUM","Mercedes-Benz price is Mercedes-Benz:111.0:DIAMOND","Google price is Google:121.0:NONE","Louis Vuitton price is Louis Vuitton:168.0:PLATINUM","Chanel price is Chanel:131.0:NONE","Gucci price is Gucci:132.0:SILVER","Adidas price is Adidas:133.0:PLATINUM","Pepsi price is Pepsi:158.0:SILVER","Ford price is Ford:113.0:PLATINUM","Microsoft price is Microsoft:156.0:GOLD","Rolex price is Rolex:126.0:GOLD","Ferrari price is Ferrari:163.0:DIAMOND","IKEA price is IKEA:150.0:NONE"] 执行耗时:5077ms
使用CompletableFuture执行异步多查询任务
我们给出了CompletableFuture执行多IO查询任务的代码示例,可以看到代码的执行流程大致为:
- 遍历商家。
- 提交异步查询任务。
- 调用join(),注意这里的join和CompletableFuture的get方法作用是一样的,都是阻塞获取查询结果,唯一的区别就是join方法签名没有抛异常,所以无需try-catch处理。
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<String> resultList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is "
+ shop.getPrice("Air Jordan")))//CompletableFuture提交价格查询任务
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + (end - begin) + "ms");
}
可以看到执行结果为31s,查询效率还不如顺序流。
执行结束,执行结果:["Nike price is Nike:112.0:GOLD","Apple price is Apple:135.0:DIAMOND","Coca-Cola price is Coca-Cola:111.0:DIAMOND","Amazon price is Amazon:155.0:GOLD","Samsung price is Samsung:165.0:SILVER","McDonald's price is McDonald's:164.0:PLATINUM","Mercedes-Benz price is Mercedes-Benz:111.0:DIAMOND","Google price is Google:121.0:NONE","Louis Vuitton price is Louis Vuitton:168.0:PLATINUM","Chanel price is Chanel:131.0:NONE","Gucci price is Gucci:132.0:SILVER","Adidas price is Adidas:133.0:PLATINUM","Pepsi price is Pepsi:158.0:SILVER","Ford price is Ford:113.0:PLATINUM","Microsoft price is Microsoft:156.0:GOLD","Rolex price is Rolex:126.0:GOLD","Ferrari price is Ferrari:163.0:DIAMOND","IKEA price is IKEA:150.0:NONE"] 执行耗时:31097ms
原因很简单,我们本次的流操作执行会构成下面这样一张图,可以看到查询价格的操作是有耗时的,随后我们又调用了join方法使得流的后续步骤被阻塞,最终CompletableFuture用的和顺序流一样。
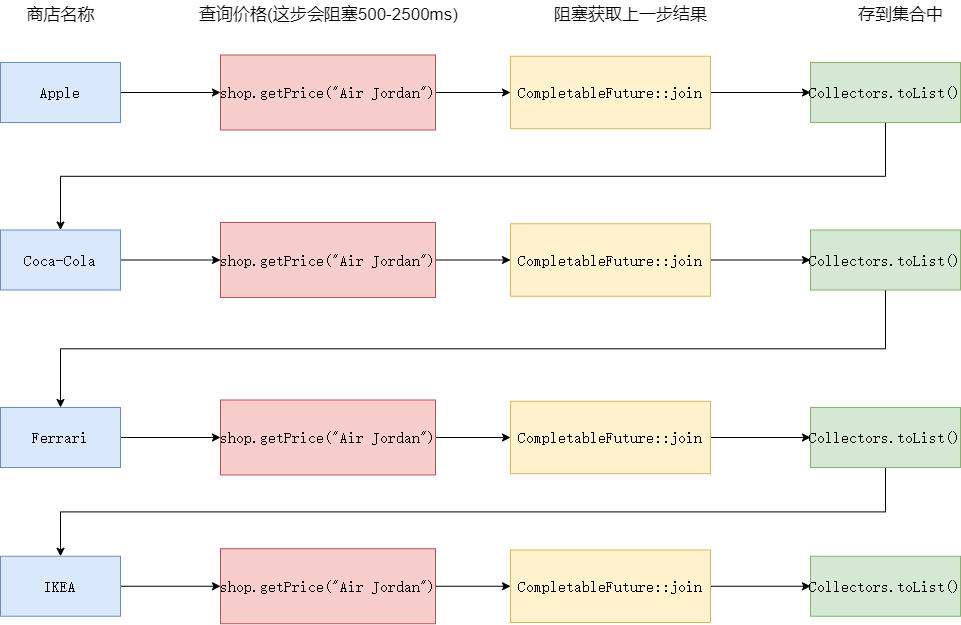
分解流优化使用CompletableFuture
上述我们提到过,之所以慢是因为join阻塞了流的操作,所以提升效率的方式就是不要让join阻塞流的操作。所以笔者将流拆成了两个。
如下图,第一个流负责提交任务,即遍历每一个商家并将查询价格的任务提交出去,期间不阻塞,最终会生成一个CompletableFuture的List。
紧接着我们遍历上一个流生成的List<CompletableFuture>,调用join方法阻塞获取结果,因为上一个流操作提交任务时不阻塞,所以每个任务一提交时就可能已经在执行了,所以join方法获取结果的耗时也会相对短一些。
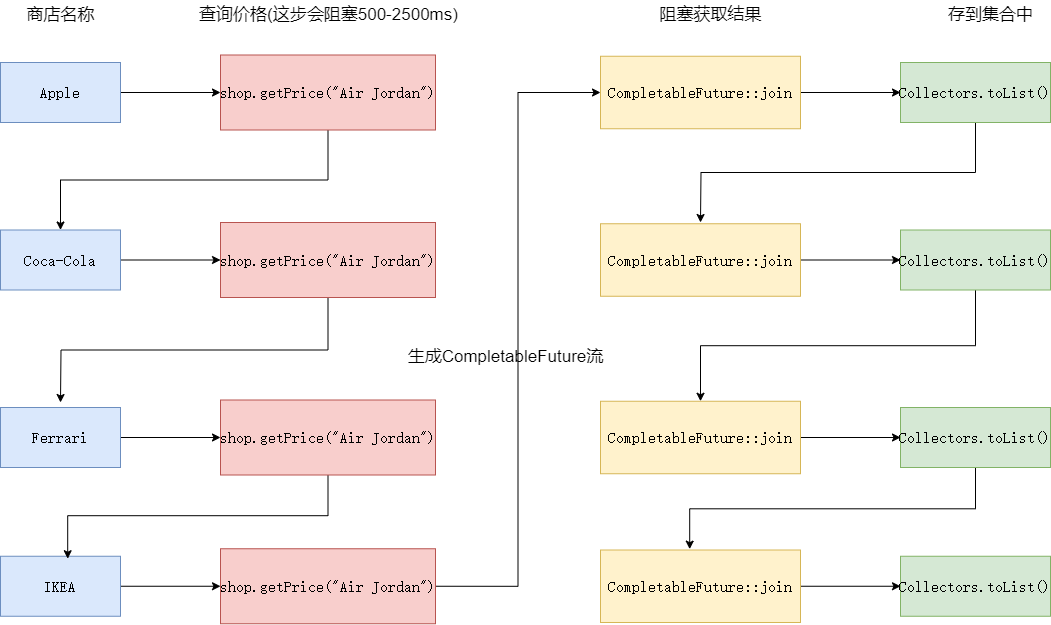
所以我们的代码最后改造成了这样:
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<CompletableFuture<String>> completableFutureList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice("Air Jordan")))
.collect(Collectors.toList());//CompletableFuture提交价格查询任务
List<String> resultList = completableFutureList.stream()
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + (end - begin) + "ms");
}
执行结果如下,可以看到代码耗时差不多也是5s和并行流差不多,原因很简单,线程池默认用6个,对于IO密集型任务来说显然是不够的。
执行结束,执行结果:["Nike price is Nike:112.0:GOLD","Apple price is Apple:135.0:DIAMOND","Coca-Cola price is Coca-Cola:111.0:DIAMOND","Amazon price is Amazon:155.0:GOLD","Samsung price is Samsung:165.0:SILVER","McDonald's price is McDonald's:164.0:PLATINUM","Mercedes-Benz price is Mercedes-Benz:111.0:DIAMOND","Google price is Google:121.0:NONE","Louis Vuitton price is Louis Vuitton:168.0:PLATINUM","Chanel price is Chanel:131.0:NONE","Gucci price is Gucci:132.0:SILVER","Adidas price is Adidas:133.0:PLATINUM","Pepsi price is Pepsi:158.0:SILVER","Ford price is Ford:113.0:PLATINUM","Microsoft price is Microsoft:156.0:GOLD","Rolex price is Rolex:126.0:GOLD","Ferrari price is Ferrari:163.0:DIAMOND","IKEA price is IKEA:150.0:NONE"] 执行耗时:5633ms
CompletableFuture使用自定义线程池
《Java并发编程实战》一书中,Brian Goetz和合著者们为线程池大小的优化提供了不少中肯的建议。这非常重要,如果线程池中线程的数量过多,最终它们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。反之,如果线程的数目过少,正如你的应用所面临的 情况,处理器的一些核可能就无法充分利用。BrianGoetz建议,线程池大小与处理器的利用率 之比可以使用下面的公式进行估算:
N(threads) = N(CPU)* U(CPU) * (1+ W/C)
其中: N(CPU)是处理器的核的数目,可以通过 Runtime.getRuntime().available Processors() 得到。U(CPU)是期望的 CPU利用率(该值应该介于 0和 1之间) W/C是等待时间与计算时间的比率。
我们的CPU核心数为6,我们希望的CPU利用率为1,而等待时间按照这种的计算应该是1250ms而计算时间可以忽略不计,所以W/C差不多可以换算为1000。
最终我们计算结果为:
N(threads) = N(CPU)* U(CPU) * (1+ W/C)
= 6*1*1000
=6000
很明显6000个线程非常不合理,所以我们使用了和商店数差不多的线程数,所以我们将线程设置为18(这也是个大概的数字,具体情况还需要经过压测进行增减)。
最终代码写成这样。
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(20,
20,
1,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNamePrefix("threadPool-%d").build());
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<CompletableFuture<String>> completableFutureList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice("Air Jordan"), threadPool))
.collect(Collectors.toList());//CompletableFuture提交价格查询任务
List<String> resultList = completableFutureList.stream()
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + (end - begin) + "ms");
threadPool.shutdownNow();
}
输出结果如下,可以看到查询效率有了质的飞跃。
执行结束,执行结果:["Nike price is Nike:112.0:GOLD","Apple price is Apple:135.0:DIAMOND","Coca-Cola price is Coca-Cola:111.0:DIAMOND","Amazon price is Amazon:155.0:GOLD","Samsung price is Samsung:165.0:SILVER","McDonald's price is McDonald's:164.0:PLATINUM","Mercedes-Benz price is Mercedes-Benz:111.0:DIAMOND","Google price is Google:121.0:NONE","Louis Vuitton price is Louis Vuitton:168.0:PLATINUM","Chanel price is Chanel:131.0:NONE","Gucci price is Gucci:132.0:SILVER","Adidas price is Adidas:133.0:PLATINUM","Pepsi price is Pepsi:158.0:SILVER","Ford price is Ford:113.0:PLATINUM","Microsoft price is Microsoft:156.0:GOLD","Rolex price is Rolex:126.0:GOLD","Ferrari price is Ferrari:163.0:DIAMOND","IKEA price is IKEA:150.0:NONE"] 执行耗时:1893ms
并行流一定比CompletableFuture烂吗?
如果是计算密集型的任务,使用stream是最佳姿势,因为密集型需要一直计算,加多少个线程都无济于事,使用stream简单使用了。
而对于io密集型的任务,例如上文这种大量查询都需要干等的任务,使用CompletableFuture是最佳姿势了,通过自定义线程创建比cpu核心数更多的线程来提高工作效率才是较好的解决方案