| Paper | GitHub | |
|---|---|---|
| miniGPT4 | https://arxiv.org/abs/2304.10592 | https://github.com/Vision-CAIR/MiniGPT-4 |
| miniGPT4-v2 | https://arxiv.org/abs/2310.09478 | https://github.com/Vision-CAIR/MiniGPT-4 |
文章目录
MiniGPT4
motivation
GPT4的多模态能力在早先的多模态方法中很少看到,例如从手稿生成网页、梗图描述等。但GPT4并没有公开技术细节,MiniGPT4这篇文章对如何实现GPT4的多模态能力进行探索。
核心思想
作者认为增强多模态模型的生成能力一定要利用大语言模型的知识库。因此也是采用“对齐”的思路来训练一个投影层将预训练好的LLM和视觉模型链接在一起。简单的概括:通过投影层来将图片的特征转化为LLM能够理解的token,剩下的就和LLM做的一样了。
这篇文章的思路和BLIP2高度相似。
method
架构部分
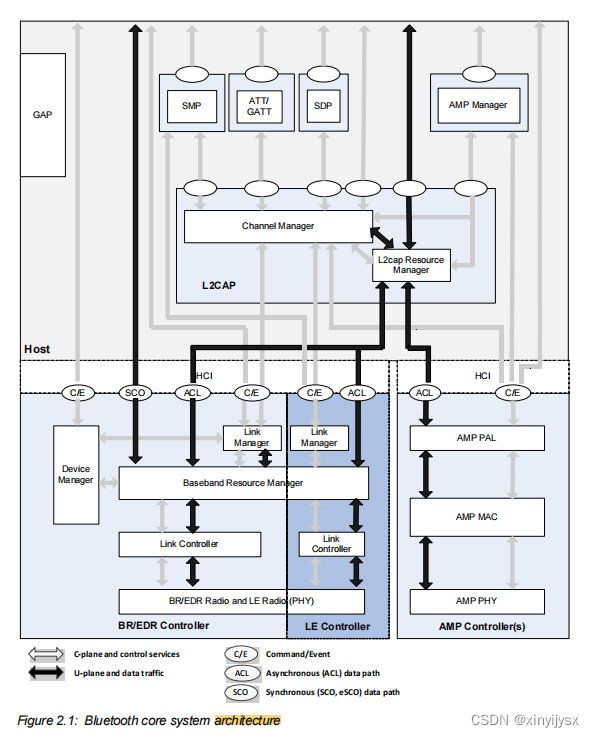
整体架构如下所示:

image encode采用的是预训练的Vit和QFormer(QFormer的详细实现可见我写的BLIP系列小结文档,里面有详细解释)
LLM采用的是Vicunna。
对齐层采用的是线性层。
image encoder与LLM都不参与训练,仅训练对齐层的参数。从上述架构可见:miniGPT4的输入是:图片和文本,输出是文本序列。
训练部分
作者用了two-stage的训练方法(现在多模态论文大多用多阶段训练的思路)。
First pretraining stage
这个部分的训练需要大规模的图文对数据集。通过优化投影层的参数,将image encoder提取的图片特征转变成LLM能够理解的样子。
详细信息如下:
| information | |
|---|---|
| 数据集 | Conceptual Caption,SUB,LAION |
| 训练iteration | 20000个train step,batch size=256 |
| 训练成本 | 4张A100(80GB)训练了10小时 |
| 训练目标函数 | next token predict |
通过这一阶段的训练,minigpt4已经能够做一些图片问答、推理等任务,但作者观察到模型有时会有答非所问、"鬼打墙"等现象。因此需要第二阶段的微调。
Second-stage finetuning
这一阶段的微调需要准备指令集数据集。如何准备指令集微调数据集取决于想要让模型做什么问题。下面来看作者如何构造指令集微调数据集。
作者从Conceptual Caption数据集随机挑选5000图片。用stage1的模型来生成详细的图片描述。所用的pormpt如下:ImageFeature是上面提到的soft visual token。
###Human: <Img><ImageFeature></Img>Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
如果生成的结果不到80个token,会增加额外的prompt ###Human: Continue ###Assistant:,以确保图片描述尽可能的详细。但是用这种自动生成的方法构建的描述可能存在语法错误、重复等情况,作者用ChatGPT对生成的描述进行改写:ChatGPT的prompt如下:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences.
Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
为了避免生成caption答非所问的情况,作者还对生成的每一个图文对进行了人工check,以此保证数据集的质量。清洗后获得了总计3500个图文对。
最后用这清洗得到的数据集对模型进行了进一步的微调。
虽然作者主要构建了image caption的数据。我们训练自己的多模态模型的时候,可以根据需要构建自己的instruction数据集。
【例如:open set检测】
prompt:###Human: . 请返回图中所有任务的坐标,返回格式以json输出,模版如:{person1: [xmin, ymin, xmax, ymax]},其中坐标做了归一化处理 ###Assistant:
label:{person1: [0.14, 0.24, 0.45, 0.65], person2: [0.11, 0.]…}
【例如:表格信息抽取】
prompt:###Human: . 请抽取表格中的所有3元组 ###Assistant:
label:[(分类1, 分类2,value), (分类1, 分类2, value), …]
总结来说就是把任务的统一建模成sequence-to-sequence的架构。这样就能联合起来一起训练。相当于同一种统一的架构做多任务学习。
小结
这篇文章总体思路和BLIP类似,没有太多创新。构造数据集的方式可以借鉴一二。
MiniGPT4-v2
这篇是miniGPT4的原作者对minigpt4的一次更新。因为作者加入Meta,对训练的算力和数据都提升一大档次。
核心思想
对多模态模型进行指令集微调,通过不同的instruction来实现不同的任务。深入理解这篇文章需要理解以下两个问题:
- 如何设计多个视觉任务instruction模板
- 如何设计训练策略,使得模型具备良好的多任务能力。
method
模型架构
模型架构与v1类似。都是一个image encoder + LLM+ projection layer。有所区别的是:v2中LLM也参与参数更新。

指令集微调模版
作者设计的多任务指令集模板如下:
[INST] <Img> < ImageFeature> </Img> [Task Identifier] Instruction [/INST]
[INST]指令集的起始,相当于扮演User<Img> < ImageFeature> </Img>这个部分与v1一致,是对齐后的visual soft token[Task Identifier]是任务标记符。不同任务的标记如下:(PS:REC全称为:referring expression comprehension,REG全称为:referring expression generation)

Instruction是常规的prompt,即你想要做的事。
3阶段训练范式
(一)Stage1: 预训练阶段
在这个阶段用next tokne prediction的训练目标在大规模的数据集上训练模型。将image encoder得到的image feature对齐成LLM能理解的soft visual token。
训练成本:8张A100训练了90个小时。(40,000个step,batch size为96)
(二)Stage2 多任务训练阶段
在这个阶段将用更为细粒度的数据集(fine-grained)来微调模型。并且在训练过程中对不同任务的数据进行均衡采样。
训练成本:4张A100训练20小时。(50,000个step,batch size64)
(三)Stage3 多任务指令集微调阶段
在这个阶段同时用了stage2的数据及其它指令集微调数据集。(采样时,会降低stage2数据集的采样率)。
训练成本:4张A100训练了7小时。(35,000个step,batch size 24)
在各个阶段所用到的数据集如下表所示

Result
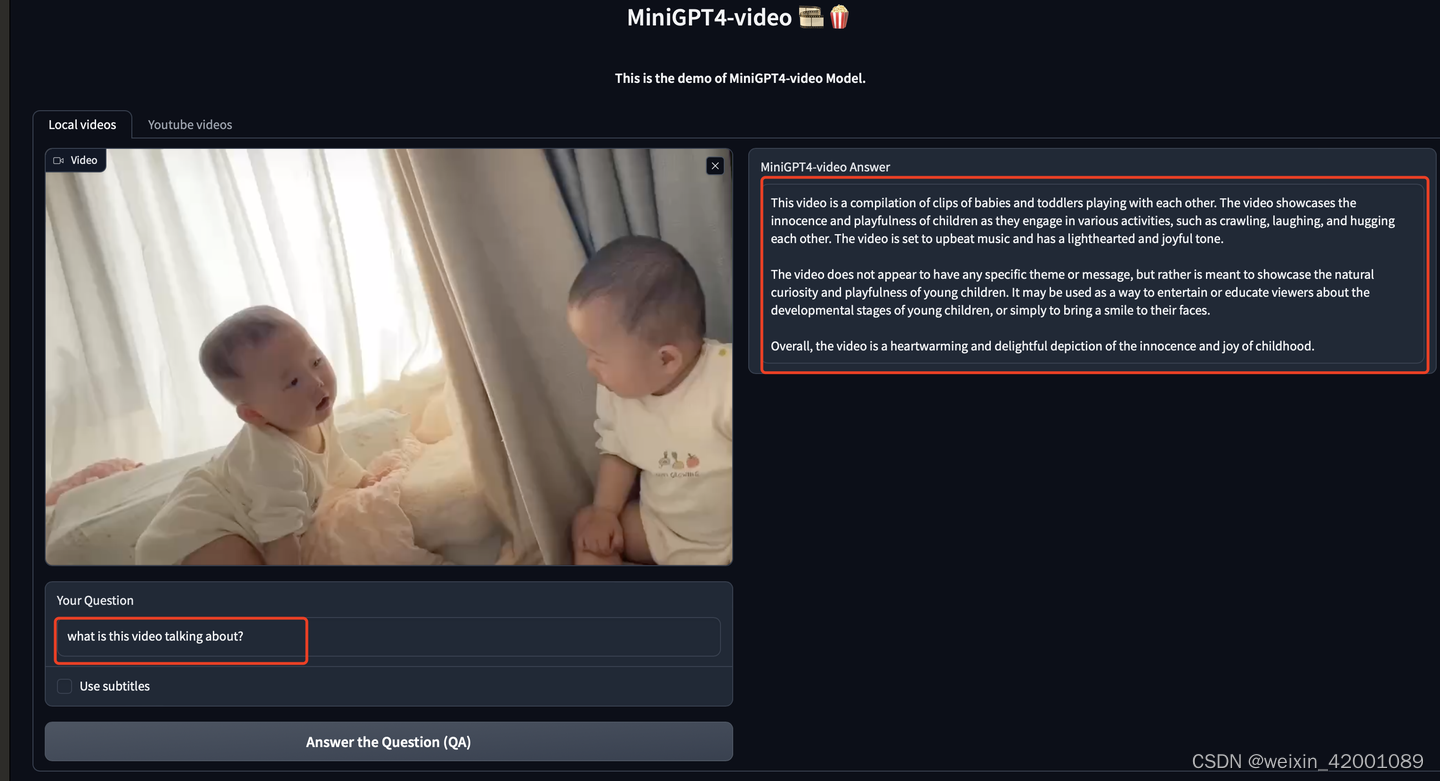
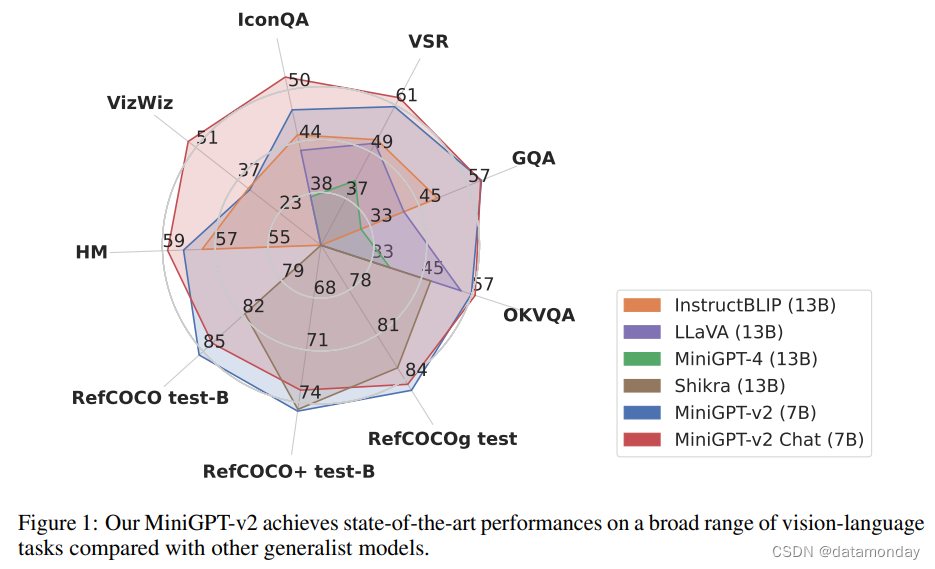
下图展示了miniGPT4-v2所具备的多模态能力

小结
这篇文章相当于对v1进行了一个拓展。用了更丰富的指令集数据集、微调更多的训练参数、用了更多的GPU training hours,使minigpt支持更为丰富的多模态能力。






















![[每周一更]-(第76期):Go源码阅读与分析的方式](https://img-blog.csdnimg.cn/direct/8dc0a8cc00dd417496b2d9778712bccb.jpeg#pic_center)