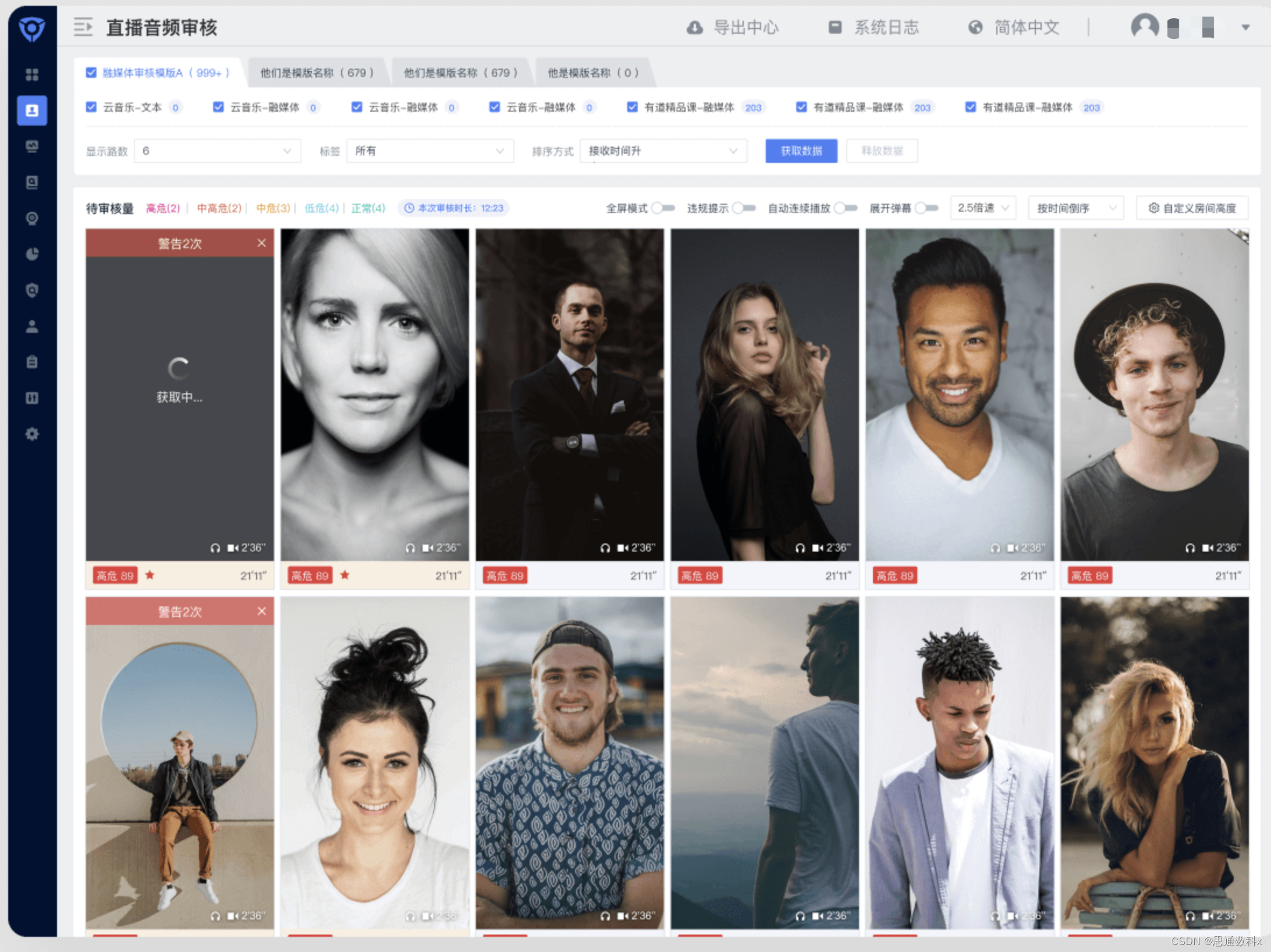
AI 视觉是为了让计算机利用摄像机来替代人眼对目标进行识别,跟踪并进一步完成一些更加复杂的图像处理。这一领域的学术研究已经存在了很长时间,但直到 20 世纪 70 年代后期,当计算机的性能提高到足以处理图片这样大规模的数据时,计算机视觉才得到了正式的关注和发展。
现在 AI 视觉已经在我们的生活中无处不在,从日常使用的二维码到人脸识别直至更专业的病理分析。AI 视觉的应用所渗透到的领域远比我们想象的更加广泛。虽然 AI 视觉的应用已经随处可见,但如果想要自己去开发一套属于自己的 AI 视觉应用,对于一个非专业领域的开发者还是非常复杂的,单从最基础的算法训练就要消耗掉大量的精力与时间。
EdgerOS 系统则内置了多种不同方向的 AI 引擎,使开发者可以实现快速实现 AI 视觉领域的开发,极大的降低了开发周期。开发者可以根据自己的需求对不同 AI 引擎进行组合达到自己想要的业务实现。本文将带领大家一起了解 EdgerOS 中常用的两款 AI 引擎。
FaceNN 是 EdgerOS 所提供的一个针对人脸识别的 AI 处理引擎,它可以从视频流或者图片中捕捉到人脸的具体位置,还可以根据人脸的特征来分析出对应人物的特征信息如:年龄、性别、情感等一些具体信息。
FaceNN 引擎封装在 “facenn” 模块中,可以通过以下方式来导入:
const facenn= require ( 'facenn ') ;
FaceNN 引擎提供了极简的接口,这使得开发者可以更加快速的实现关于人脸的 AI 处理,同时也降低了巨大的学习成本。
首先需要明确一下被识别的图像格式,目前 FaceNN 引擎支持如下格式:
类型
说明
facenn.PIX FMT RGB24
RGB24 pixel format
facenn.PIX FMT BGR2RGB24
BGR24 to RBG24 pixel format
facenn.PIXFMTGRAY2RGB24
Grayscale to RGB24 pixel format
facenn.PIX FMT RGBA2RGB24
RGBA to RGB24 pixel format
facenn.detect(videoBuf, attribute[, quick])
pixelFormat {Integer} 图像格式
返回信息:
regreCoord {Array} RegreCoord,非快速模式
landmark {Array} Landmark,非快速模式
facenn.detect 可以识别出一帧图像数据中的人脸个数以及人脸所在图像中的位置。
facenn.feature(videoBuf, attribute, faceInfo[, extra])
pixelFormat {Integer} 图像格式
extra {Object} 需要扩展的人脸信息 default: undefined
返回信息:
male {Boolean} 性别, 需要在扩展中选择
age {Integer} Age, 需要在扩展中选择
emotion {String} Emotion, 需要在扩展中选择
emotion 可分辨情绪包括: angry,disgust,fear,happy,sad,surprise,neutral
live {Number} 存活率,需要在扩展中选择
facenn.feature 可以识别出一张人像的具体信息,例如性别,情绪年龄等。
facenn.compare(faceKeys1, faceKeys2)
faceKey1 {Object} Face keys 1
faceKey2 {Object} Face keys 2
返回信息:
facenn.compare 可以比对出两张人脸信息的相似值。
接下来用一下两张图片来尝试使用 FaceNN 引擎,读取其中的特征信息:
const imagecodec = require ( 'imagecodec ') ;
const facenn = require ( 'facenn ') ;
function facennHandel ( imagePath, imagePath2) {
const image1 = imagecodec. decode ( imagePath, imagecodec. COMPONENTS_RGB )
const imageInfo1 = imagecodec. info ( imagePath)
const videoAttrFacenn = {
width: imageInfo1. width, height: imageInfo1. height, pixelFormat: facenn. PIX_FMT_RGB24 }
const faceInfos = facenn. detect ( image1. buffer, videoAttrFacenn) ;
const facennFeature = facenn. feature ( image1. buffer, videoAttrFacenn, faceInfos[ 0 ] , {
male: true ,
age: true ,
emotion: true ,
live: true
} )
console. log ( `image1. png male: ${
facennFeature. male} age: ${
facennFeature. age} emotion: ${
facennFeature. emotion} live: ${
facennFeature. live} `)
const image2 = imagecodec. decode ( imagePath2, imagecodec. COMPONENTS_RGB )
const imageInfo2 = imagecodec. info ( imagePath2)
const videoAttrFacenn2 = {
width: imageInfo2. width, height: imageInfo2. height, pixelFormat: facenn. PIX_FMT_RGB24 }
const faceInfos2 = facenn. detect ( image2. buffer, videoAttrFacenn2) ;
const facennFeature2 = facenn. feature ( image2. buffer, videoAttrFacenn2, faceInfos2[ 0 ] , {
male: true ,
age: true ,
emotion: true ,
live: true
} )
console. log ( `image2. png male: ${
facennFeature2. male} age: ${
facennFeature2. age} emotion: ${
facennFeature2. emotion} live: ${
facennFeature2. live} `)
const compareNum = facenn. compare ( facennFeature. keys, facennFeature2. keys)
console. log ( compareNum)
}
facennHandel ( '/ image/ image1. png', '/ image/ image2. png')
ThingNN 是 EdgerOS 可以从视频流或者图片中捕捉到具体事物,分别标记事务所在图片中的具体位置。
ThingNN 引擎封装在 “thingnn” 模块中,可以通过以下方式来导入:
const facenn= require ( 'thingnn ') ;
同样也需要明确一下被识别的图像格式,目前 ThingNN 引擎支持如下格式:
类型
说明
thingnn.PIX FMT_ RGB24
RGB24 pixel format
thingnn.PIX_FMT_BGR2RGB24
BGR24 to RBG24 pixel format
thingnn.PIX FMT GRAY2RGB24
Grayscale to RGB24 pixel format
thingnn.PIX FMT RGBA2RGB24
RGBA to RGB24 pixel format
接下来看看 ThingNN 接口提供了那些接口:
thingnn.detect(videoBuf, attribute)
pixelFormat {Integer} 图像格式
返回信息:
className{Array} Face keys
prob{Boolean} 性别, 需要在扩展中选择
目前 ThingNN 模块所支持可识别的类型都有:
background, aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor
thingnn.detect 可以获取到图片中事物的类别以及所在图像中的位置。
thingnn.identify(videoBuf, attribute, thingInfo)
pixelFormat {Integer} 图像格式
返回信息:具体事物的名称,thingnn.identify 可以获取到具体 thinginfo 的类型名称。
以下图为例子作为演示:
const imagecodec = require ( 'imagecodec ') ;
const facenn = require ( 'facenn ') ;
function licplatennHandel ( imagePath) {
const imageInfo = imagecodec. info ( imagePath)
const imageBuf= imagecodec. decode ( imagePath, imagecodec. COMPONENTS_RGB ) . buffer
let videoAttrThingnn = {
width: imageInfo. width, height: imageInfo. height, pixelFormat: thingnn. PIX_FMT_BGR24 }
const thingInfos = thingnn. detect ( imageBuf, videoAttrThingnn) ;
thingInfos. forEach ( ( thingInfo, index) => {
const thingName = thingnn. identify ( imageBuf, videoAttrThingnn, thingInfo) ;
console. log ( index, thingInfo. className, thingName)
} )
}
licplatennHandel ( '/ image/ dog. png')
FaceNN 模块在单独使用时是处理视频流中的人脸信息的,现在假设我们的场景是一个智能门锁,首先需要录入人脸信息,添加为合法的开锁用户,门锁摄像头再捕获视频流检测出人脸信息进行核对,校验通过则打开门锁。在录入人脸信息的时候,需要将多张人脸照片处理成流信息提供给 FanceNN 模块进行解析,ImageCodec 模块刚好就可以胜任此工作。
ImageCodec 模块提供了对多种图像格式进行编码和解码方法,包括:PNG,JPG,BMP,TGA,HDR,接下来具体看一下,如何通过 ImageCodec 处理图片数据。
const imagecodec = require ( 'imagecodec ')
在对图片进行解码的时候需要区别处理带通道的 PNG 图片,ImageCodec 模块上的 decode 方法支持传入第二个可选参数:
imagecodec.decode(path[, opt]):
const image = imagecodec. decode ( '. / test. png', {
components: imagecodec. COMPONENTS_RGB_ALPHA } )
opt 的配置选项 components 可以指定以下值来区别处理不同格式的图片:
定义
值
描述
imagecodec.COMPONENTS_DEFAULT
0
使用图片的默认值
imagecodec.COMPONENTS_GREY
1
单字节灰度图像
imagecodec.COMPONENTS_GREY_ALPHA
2
带有 Alpha 通道的灰度图像
imagecodec.COMPONENTS_RGB
3
三字节 RGB 图像
imagecodec.COMPONENTS_RGB_ALPHA
4
带有 Alpha 通道的 RGB 图像
如何判断一个图片的格式,我们知道计算机实际并不是根据后缀来判断文件类型的,事实上,有个东西叫魔法数字(Magic Number),它是某一类型的文件的头一个或几个字节的内容,可以根据这个来判断传入的图片文件是什么类型的:
const fs = require ( 'fs ')
const imagecodec = require ( 'imagecodec ')
const imageBuffer = fs. readFile ( '. / human. jpg')
let type = ''
const arr = ( new Uint8Array ( picture) ) . subarray ( 0 , 4 )
const headerString = arr. reduce ( ( acc, cur) => acc+ cur. toString ( 16 ) , '')
switch ( headerString) {
case "89504e47" :
type = "png" ;
break
case "47494638" :
type = "gif" ;
break
case "ffd8ffe0" :
case "ffd8ffe1" :
case "ffd8ffe2" :
type = "jpg"
break
default:
console. log ( '[ mime- type ] not png/ gif/ jpg. ')
break
}
将图片文件的前 4 个字节(4 个字节的长度已经足够判断出图片的类型了)拿出来进行判断,一般拍照上传的照片是 JPG 或 PNG,所以这里只需要判断出图片是否是带有 ALPHA 通道的图片即可。
上面判断出图片类型之后,就可以通过 decode 方法解码图片文件:
const bitmap = imagecodec. decode ( picture, {
components: type == = 'png ' ? imagecodec. COMPONENTS_RGB_ALPHA : imagecodec. COMPONENTS_RGB
} )
decode解析得到的 bitmap 为一个图像像素对象,它包含 width,height,components,buffer 4个属性,也正是 FaceNN 所需要的内容。
const facenn = require ( 'facenn ')
const faces = facenn. detect ( bitmap. buffer, {
width: bitmap. width,
height: bitmap. height,
pixelFormat: type == = 'png ' ? facenn. PIX_FMT_RGBA2RGB24 : facenn. PIX_FMT_RGB24
} , true )
此时得到的 faces 内容就是识别之后的人脸特征信息,从图片中获取面部信息的功能就完成。
这个功能已经封装成一个 jsre 包上传到了 npm 仓库,可以通过以下方式进行安装和使用:
npm install @ edgeros/ ofii
const getFaceFeature = require ( '@ edgeros/ ofii')
const imageBuffer = fs. readFile ( '. / hunman. png')
const keys = getFaceFeature ( imageBuffer)
在不同的场景中我们需要对图片进行编码解码,来配合完成更加复杂的功能和服务。EdgerOS 在网络应用,人工智能等场景提供了丰富的接口,能够极大简化开发流程。