文章目录
前言
本文介绍了搭建 Kafka 集群的准备工作和使用 shell 脚本一键安装 Kafka 的步骤。首先,需要搭建集群和 ZooKeeper 集群作为 Kafka 的依赖。然后,通过复制和分发脚本,在集群中的各个节点上执行脚本来安装和配置 Kafka。最后,介绍了如何启动和停止 Kafka 集群。
一、安装准备
1. 搭建集群
点击链接查看集群搭建教程:配置集群免密登录
2. 搭建zookeeper集群
Kafka启动需要依赖Zookeeper。Zookeeper是一个开源的分布式协调服务,Kafka使用Zookeeper来管理集群的元数据和协调各个Broker之间的通信。
点击链接查看zookeeper安装配置教程:zookeeper安装与配置:使用shell脚本在centos上进行zookeeper自动化下载安装配置(集群搭建版)
3. kafka单机版
需要安装单机版的参考,不需要的请忽略
kafka单机版安装教程:Kafka安装与配置-shell脚本一键安装配置(单机版)
二、使用shell脚本一键安装
以下所有操作均在hadoop101节点
1. 复制脚本
首先,在hadoop101节点,将以下脚本内容复制并保存为/tmp/install_kafka_cluster.sh文件。
#!/bin/bash
node1=192.168.145.103
node2=192.168.145.104
node3=192.168.145.105
kfk_installDir="/opt/module/kafka"
kfk_kafka_version="2.2.1"
kfk_scala_version="2.11"
install_kafka() {
local installDir=$1
local kafka_version=$2
local scala_version=$3
local broker_id=$4
if [ -z "$(command -v wget)" ]; then
sudo yum install -y wget
echo "wget安装完成"
fi
if [ -z "$JAVA_HOME" ]; then
echo "JAVA_HOME未设置,请安装jdk1.8,设置Java环境变量再来执行此脚本"
exit 1
fi
if [ ! -d "${installDir}" ]; then
sudo mkdir -p "${installDir}"
if [ $? -eq 0 ]; then
echo "安装目录${installDir}已创建"
else
echo "请确保您有足够的权限来创建目录,请增加权限后再次执行"
exit 1
fi
fi
if [ ! -f /tmp/kafka_$scala_version-$kafka_version.tgz ]; then
wget https://archive.apache.org/dist/kafka/$kafka_version/kafka_$scala_version-$kafka_version.tgz -P /tmp/
if [ $? -eq 0 ]; then
echo "kafka_$scala_version-$kafka_version.tgz下载成功"
else
echo "kafka_$scala_version-$kafka_version.tgz下载失败,请重试或手动下载到/tmp目录下再次执行"
echo "下载地址:https://archive.apache.org/dist/kafka/$kafka_version/kafka_$scala_version-$kafka_version.tgz"
exit 1
fi
fi
if [ -d $installDir/kafka_$scala_version-$kafka_version ]; then
echo "$installDir/kafka_$scala_version-$kafka_version 已存在,正在删除..."
sudo rm -rf $installDir/kafka_$scala_version-$kafka_version
fi
tar -zxvf /tmp/kafka_$scala_version-$kafka_version.tgz -C $installDir
if [ $? -eq 0 ]; then
echo "/tmp/kafka_$scala_version-$kafka_version.tgz解压成功"
else
echo "/tmp/kafka_$scala_version-$kafka_version.tgz解压失败,请查看异常信息后重试"
exit 1
fi
#设置kafka环境变量
if [ -z "$KAFKA_HOME" ]; then
echo >> ~/.bashrc
echo '#KAFKA_HOME' >> ~/.bashrc
echo "export KAFKA_HOME=$installDir/kafka_$scala_version-$kafka_version" >> ~/.bashrc
echo 'export PATH=$PATH:$KAFKA_HOME/bin' >> ~/.bashrc
else
echo "KAFKA_HOME已有设置:$KAFKA_HOME"
fi
#设置kafka中zookeeper的快照目录
sed -i "s|^dataDir=.*|dataDir=$installDir/kafka_$scala_version-$kafka_version/zookeeper|" "$installDir/kafka_$scala_version-$kafka_version/config/zookeeper.properties"
if [ $? -eq 0 ]; then
echo "kafka中zookeeper的快照目录设置成功"
else
echo "kafka中zookeeper的快照目录设置失败,请查看异常信息后重试"
exit 1
fi
#修改kafka配置文件
ip_addr=$(ip addr | grep 'inet ' | awk '{print $2}'| tail -n 1 | grep -oP '\d+\.\d+\.\d+\.\d+')
sed -i "s|broker.id=0|broker.id=$broker_id|" "$installDir/kafka_$scala_version-$kafka_version/config/server.properties"
sed -i "s|#listeners=PLAINTEXT://:9092|listeners=PLAINTEXT://$ip_addr:9092|" "$installDir/kafka_$scala_version-$kafka_version/config/server.properties"
sed -i "s|log.dirs=/tmp/kafka-logs|log.dirs=$installDir/kafka_$scala_version-$kafka_version/kafka-logs/$(hostname)|" "$installDir/kafka_$scala_version-$kafka_version/config/server.properties"
sed -i "s|zookeeper.connect=localhost:2181|zookeeper.connect=$ip_addr:2181|" "$installDir/kafka_$scala_version-$kafka_version/config/server.properties"
sed -i "s|#advertised.listeners=PLAINTEXT://your.host.name:9092|advertised.listeners=PLAINTEXT://$ip_addr:9092|" "$installDir/kafka_$scala_version-$kafka_version/config/server.properties"
if [ $? -eq 0 ]; then
echo "kafka配置文件修改成功"
else
echo "kafka配置文件修改失败,请查看异常信息后重试"
exit 1
fi
echo "kafka下载、安装、配置成功"
}
ip_addr=$(ip addr | grep 'inet ' | awk '{print $2}'| tail -n 1 | grep -oP '\d+\.\d+\.\d+\.\d+')
hostname=$(hostname)
if [[ "$node1" == "$ip_addr" || "$node1" == "$hostname" ]]; then
install_kafka "$kfk_installDir" "$kfk_kafka_version" "$kfk_scala_version" 1
elif [[ "$node2" == "$ip_addr" || "$node2" == "$hostname" ]]; then
install_kafka "$kfk_installDir" "$kfk_kafka_version" "$kfk_scala_version" 2
elif [[ "$node3" == "$ip_addr" || "$node3" == "$hostname" ]]; then
install_kafka "$kfk_installDir" "$kfk_kafka_version" "$kfk_scala_version" 3
fi
exit 0
2. 增加执行权限
在终端中执行以下命令,为脚本添加执行权限。
chmod a+x /tmp/install_kafka_cluster.sh
3. 分发脚本
点击链接查看scp命令介绍及其使用:linux常用命令-find命令与scp命令详解(超详细)
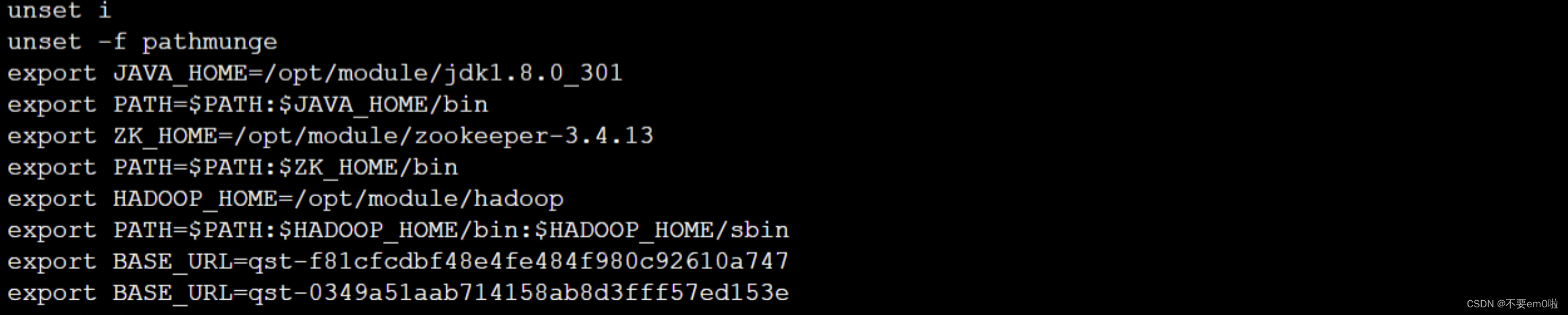
使用scp命令把/tmp/install_kafka_cluster.sh脚本分发到hadoop102和hadoop103节点的/tmp目录下。
scp /tmp/install_kafka_cluster.sh hadoop102:/tmp
scp /tmp/install_kafka_cluster.sh hadoop103:/tmp
如下图:

4. 执行脚本
执行以下命令,运行脚本开始下载、安装和配置Kafka。
首先在hadoop101执行,再使用远程连接命令让hadoop102和hadoop103节点执行。
/tmp/install_kafka_cluster.sh
请等待hadoop101安装配置完成,如有异常会有提示。
ssh hadoop102 /tmp/install_kafka_cluster.sh
请等待hadoop102安装配置完成,如有异常会有提示。
ssh hadoop103 /tmp/install_kafka_cluster.sh
请等待hadoop103安装配置完成,如有异常会有提示。
成功如下图所示:

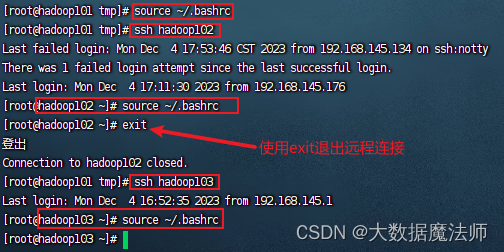
5. 加载用户环境变量
执行以下命令,加载用户环境变量,首先在hadoop101执行,再使用远程连接命令让hadoop102和hadoop103节点执行。
source ~/.bashrc
ssh hadoop102
source ~/.bashrc
exit
ssh hadoop103
source ~/.bashrc
exit
如下图所示:
三、启动与停止
集群之间切换启动过于麻烦,在这里直接写一个脚本来启动集群。
kafka的启动依赖于zookeeper,所以要先启动zookeeper集群。zookeeper集群安装搭建步骤:zookeeper安装与配置:使用shell脚本在centos上进行zookeeper自动化下载安装配置(集群搭建版)
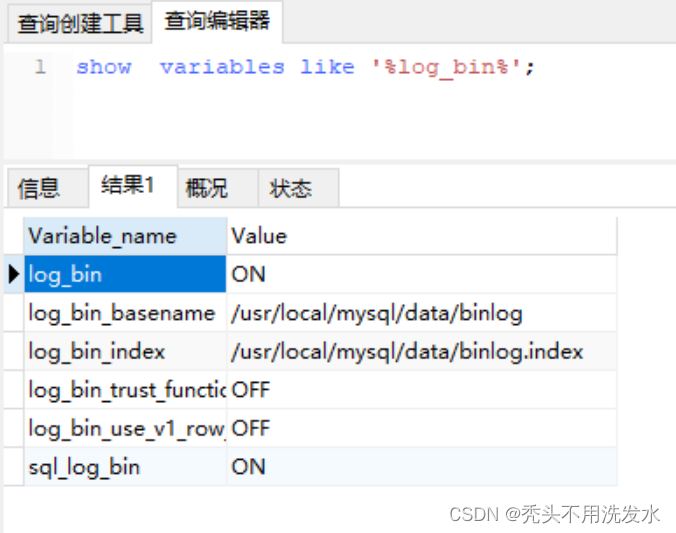
1. 启动/停止zookeeper集群
(1) 启动zookeeper集群
根据zookeeper集群搭建教程,安装搭建好zookeeper集群,并使用脚本启动好zookeeper集群,查看zookeeper集群状态是否启动成功,成功如下图所示:
zookeeper.sh start
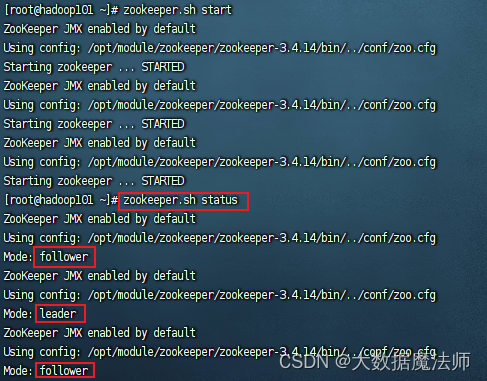
(2) 查看zookeeper集群状态
zookeeper.sh status
(3) 停止zookeeper集群
zookeeper.sh stop
(4) 重启zookeeper集群
zookeeper.sh restart
2. 启动/停止kafka集群
(1) 复制kafka集群启动脚本
将以下脚本内容复制并保存为~/bin/kafka.sh文件。把KAFKA_HOME改为自己的安装目录,把node1、node2、node3改为自己的ip地址或主机名。
#!/bin/bash
# 设置kafka安装目录
KAFKA_HOME="/opt/module/kafka/kafka_2.11-2.2.1"
# 集群节点
node1=192.168.145.103
node2=192.168.145.104
node3=192.168.145.105
# 启动kafka
start_kafka() {
ssh $node1 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
ssh $node2 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
ssh $node3 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
}
# 停止kafka
stop_kafka() {
ssh $node1 "$KAFKA_HOME/bin/kafka-server-stop.sh"
ssh $node2 "$KAFKA_HOME/bin/kafka-server-stop.sh"
ssh $node3 "$KAFKA_HOME/bin/kafka-server-stop.sh"
}
# 重启kafka
restart_kafka() {
ssh $node1 "$KAFKA_HOME/bin/kafka-server-stop.sh"
ssh $node2 "$KAFKA_HOME/bin/kafka-server-stop.sh"
ssh $node3 "$KAFKA_HOME/bin/kafka-server-stop.sh"
sleep 3
ssh $node1 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
ssh $node2 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
ssh $node3 "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
}
# 根据命令行参数执行相应操作
case "$1" in
start)
start_kafka
;;
stop)
stop_kafka
;;
restart)
restart_kafka
;;
*)
echo "Usage: $0 {start|stop|restart}"
exit 1
;;
esac
exit 0
(2) 增加执行权限
chmod a+x ~/bin/kafka.sh
(3) 启动kafka集群
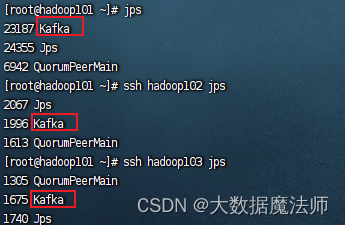
kafka.sh start
启动成功如下图所示:
(4) 停止kafka集群
kafka.sh stop
(5) 重启kafka集群
kafka.sh restart
总结
本文通过一键安装的方式,详细介绍了搭建 Kafka 集群的步骤。通过准备工作和执行 shell 脚本,用户可以快速搭建和配置 Kafka 集群。同时,还介绍了如何启动和停止 Kafka 集群。
希望本教程对您有所帮助!如有任何疑问或问题,请随时在评论区留言。感谢阅读!