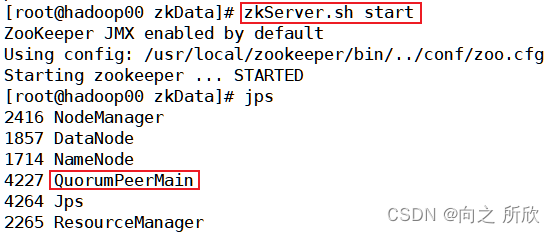
如果你正在处理接触大语言模型(LLM),大概率应该遇到过术语“tokens”, “tokenizer”,“tokenization”,“vectors” 以及 “word embeddings.” 。这些基础概念在自然语言处理 (NLP) 中非常重要,用于以各种方式表示和分析文本。
在这篇博文中,我们将深入探讨什么是token、向量和嵌入,并解释如何创建它们。
机器如何阅读和理解文本?
对于像 BERT 或 GPT 这样的NLP 模型,要理解语言,我们需要将书面文字表示为数字(因为计算机只能理解数字)。
Tokenization 是自然语言处理(NLP)的第一步。它涉及将文本划分为单独的单元,称为token。token可以是单词或标点符号。然后这些 token 被转换成向量(vector),它们是这些单词的数字表示。
为了赋予这些token明确的含义,我们需要在这些向量上训练深度学习模型(通常是Transformer模型)。这使得模型能够理解单词的含义以及不同单词间的联系。该目标是使 NLP 模型能够理解句子或文本中不同单词及其上下文的含义和语义。


如上图所示,单词“King”和“Man”的向量可能比较相似,“Queen”和“Woman”的向量也可能比较相似。这些向量还具有某些可用于训练语言模型的属性: 例如,你可以从“King”的向量中减去“Man”的向量,然后把结果向量和“Woman”的向量相加来得到“Queen”的向量。这些属性使模型能够理解单词的不同含义。
那么,NLP 模型如何确定哪些词彼此更相似呢?事实上, NLP 模型不使用单个数字来表示单词。而是经常使用 1,000 多个数字来表示一个单词。
这就是为什么它被称为“词向量(word vector)”。用数学术语来说,单个数字称为标量,数字列表称为向量。

词向量可以被认为是多维空间中的一个点,其中每个维度代表词的特定方面或特征。例如,“Queen”一词的词向量可能对表示“女性气质”和“皇室气质”的维度具有较高的值,而对表示“男性气质”的维度具有较低的值。将所有这些维度组合起来就构成了“Queen”的向量,这使得我们的模型能够理解该词的含义以及它与其他词的关系。
词向量中的维数通常称为“维数”。高维词向量具有多个维度,使其能够捕获单词的各种特征和细微差别。然而,这也意味着它需要更多的数据和计算来训练和使用。另一方面,低维词向量的维度较少,使其使用起来更简单、更高效,但可能会牺牲词义的一些丰富性和细节。
这个概念的类比可能是尝试使用不同的特征来描述一个对象。例如,您可以将球描述为圆形、有弹性且小。这些特征中的每一个都可以被视为单词“ball”的单词向量中的一个维度。“ball”的高维词向量可能包括颜色、纹理、形状和功能的维度,而低维词向量可能仅包括大小和材料的维度。
NLP中的token详解
token是通过将文本分成更小的单元来创建的。例如,句子“It is sunny outside”可能被tokenized为 [‘It’, ‘is’, ‘sunny’, ‘outside’]。将文本划分为token的过程称为tokenization。
创建token的方法有多种,应该使用哪种方法取决于具体用例。例如,用空格分隔文本是一种常见的方法,但还有许多其他方法。对于给定的数据集和任务来说,最佳的tokenization方法并不总是明确的,不同的方法各有优劣。
尝试不同的tokenization方法以确定哪一种最能满足你的需求非常重要。没有一种万能的tokenization方法,最佳方法往往会根据数据的特征和手头的任务而有所不同。
不同类型的token:子词、单词和句子
如前所述,有多种方法可以对文本进行标记。这些方法可以大致分为两类:句子tokenization和单词tokenization。
句子tokenization涉及将文本划分为单个句子,而单词tokenization涉及将文本划分为单个单词甚至子词。
在下一节中,我们将重点关注单词tokenization及其不同形式:字符、单词和子词tokenization。
字符tokenization(Character Tokenization)
字符tokenization是最基本的tokenization方法,它将每个字符视为一个单独的token。在 Python 中,这可以通过一行代码轻松完成。
text = "Hello World"
tokenized_text = list(text)
print(tokenized_text)
# ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
字符级tokenization不考虑任何文本结构,并将整个字符串视为单个字符的序列。虽然这种方法对于处理拼写错误和不常见的单词很有用,但主要缺点是它需要大量的计算能力、内存和数据来逐个字符地学习单词。因此,字符tokenization在实践中并不常用。
单词tokenization(Word Tokenization)
字符标记化的一种替代方式是单词tokenization,它涉及将文本划分为单独的单词。这消除了模型逐个字符学习单词的需要,从而简化了训练过程。
text = "Hello World"
tokenized_text = text.split( " " )
print (tokenized_text)
# ['Hello', 'World']
然而,单词tokenization可能会导致词汇量非常大,尤其是当语料库包含许多生僻单词时,例如医学术语的文本语料库。
对于神经网络来说,大的词汇量可能是一个问题,因为它需要更多的参数。Lewis Tunstall、Leandro von Werra 和 Thomas Wolf 在《Transformers 自然语言处理》一书中很好地说明了这个问题。
假设我们使用英语中的所有单词作为神经网络的输入。大约有 100 万英语单词,假设每个单词向量维度为 1,000 。这将导致输入层的权重矩阵具有 100 万 x 1,000 = 10 亿个权重。
这几乎与最大的 GPT-2 模型一样多,该模型拥有约 15 亿个参数。具有如此大量输入参数的模型维护成本可能很高,并且可能难以有效训练。
解决此问题的一种方法是通过仅考虑语料库中最常见的单词(例如 100,000 个最常见的单词)来限制词汇量。不属于词汇表的单词被分类为“unknown”并映射到共享的unknown token。
然而,这种方法牺牲了一些潜在的重要信息。如果有一种方法可以保留部分信息和结构而不丢失所有信息,那不是很棒吗?
子词标记化(Subword Tokenization)
子词tokenization结合了字符和单词tokenization的优点,将稀有单词分解为更小的单元,同时将常用单词保留为唯一实体。这使得模型能够处理复杂的单词和拼写错误,同时保持输入的长度易于管理。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer_output = tokenizer.tokenize("This is an example of the bert tokenizer")
print(tokenizer_output)
# ['this', 'is', 'an', 'example', 'of', 'the', 'bert', 'token', '##izer']
例如,在上面的文本中,单词“tokenizer”被拆分为已知单词“token”和“##izer”,其中“##”表示该token应附加到前一个token。
通过使用子词tokenization,我们可以利用单词tokenization的好处,同时保持合理的词汇量。例如,上例中使用的“bert-case-uncased”分词器的词汇量仅为 30,522 个分词。
语料库和词汇
tokenization的目的是从语料库创建词汇表。语料库是文本的集合(例如用于训练 NLP 模型的数据集),词汇表是在语料库中找到的唯一tokens集(set of unique tokens)。
为了使语料库能够有效地训练 NLP 模型,重要的是它的规模要大并且包含高质量的数据。虽然大型语料库有利于训练,但数据质量更为重要。训练数据中的小错误可能会导致最终模型中出现重大错误,因此使用尽可能准确的数据非常重要。
Tokenization的挑战
选择或创建tokenizer时需要考虑很多因素,例如它如何处理标点符号、是否使用单数形式等。这些选择会对 NLP 模型的词汇量、训练和最终性能产生重大影响。
Tokenization的一个常见问题是处理拼写错误。例如,如果语料库包含单词“hepl”而不是“help”,则模型可能会将其视为词汇表外 (out-of-vocabulary,OOV) 单词。这会显着降低模型性能。
论文《User Generated Data: Achilles’ Heel of BERT》详细研究了这个问题。根据拼写错误率(给定输入字符串中拼写错误的单词的百分比),它显示了模型性能的如下降低:

如上所示,在这种情况下,即使 5% 的错误率也会导致模型性能显着下降 11%。这是因为当分词器遇到拼写错误的单词(如“hepl”)时,它会创建诸如 [‘he’, ‘##pl’] 之类的token,而不是使用正确的token “help”。这也会导致缩写问题。例如,如果使用单词“cmd”而不是“command”,它将被分成两个token。为了解决这些问题,拥有高质量的数据或足够大的数据集以使模型能够学习单词的正确含义非常重要。
现在我们对token和向量有了更好的理解,我们还需要学习一件事:嵌入(embedding)。
NLP 中的嵌入
正如我们已经了解到的,我们从token创建向量。这些向量是token含义及其与词汇表中其他标记的关系的数字表示。
然而,模型必须首先学习这些表示。刚开始,向量是随机初始化的,但通过训练,它们会调整以包含一些含义。在训练期间,这些数字表示(类似于神经网络中的权重)由模型进行调整,以更准确地表示token的含义及其与词汇表中其他token的关系。
在NLP理中,“嵌入”是指将非向量化数据(例如token)映射到对机器学习模型或神经网络有意义的向量空间的过程。通过这样做,模型可以自动学习单词及其含义之间的关系,而不必手动指定它们。
当您可视化单词嵌入时,您可以将结果视为词汇表地图,该地图显示一个token在含义方面如何与其他token相关。每个token都位于具有相似含义的其他token附近。

token、向量和嵌入之间的区别
为了让你的模型能够理解文本,你首先必须对其进行Tokenization、向量化并从这些向量创建嵌入。
- Tokenization:这是将原始文本划分为称为token的单独片段的过程。每个token都分配有一个唯一的 ID,将其表示为数字。
- 向量化:然后将唯一的 ID 分配给随机初始化的 n 维向量。
- 嵌入:为了赋予token含义,必须对模型进行训练。这使得模型能够学习单词的含义以及它们与其他单词的关系。为了实现这一点,词向量被“嵌入”到嵌入空间中。因此,训练后相似的单词应该具有相似的向量。

从文本到向量:操作指南
如前所述,NLP 项目的第一步是对我们的数据集进行tokenization。但在从头开始训练自定义tokenizer之前,我们需要考虑这是否是最有效的方法。创建高质量的语料库并训练tokenizer可能非常耗时,而且可能并不总是能产生最佳结果。
一种替代方法是使用预先训练的tokenizer,这些tokenizer已经在大型数据集上进行了训练,并且无需额外训练即可理解单词和句子的含义。这可以节省时间和资源,甚至可以提供更好的结果。
如果您有兴趣训练自己的tokenizer和Transformer模型,可以参考transformersbook.com的第10章。如果您决定使用预先训练的tokenizer,可以通过以下方式使用 Huggingface 库来实现此目的:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("This is an example of the bert tokenizer")
print(tokens)
# ['this', 'is', 'an', 'example', 'of', 'the', 'bert', 'token', '##izer']
在此示例中,我们使用预训练的 bert-base-uncased tokenizer来对例句进行tokenization。然后,我们将使用tokenizer的convert_tokens_to_ids函数将标记转换为其相应的数值。
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print (token_ids)
# [2023, 2003, 2019, 2742, 1997, 1996, 14324, 19204, 17629]
编码函数类似于convert_tokens_to_ids,但它还包含特殊tokens,例如(序列开始)和(序列结束)。这些特殊tokens帮助模型了解序列的开始和结束位置。
token_ids = tokenizer.encode( "This is an example of the bert tokenizer" )
print (token_ids)
# [101, 2023, 2003, 2019, 2742, 1997, 1996, 14324, 19204, 17629, 102]
tokens = tokenizer.convert_ids_to_tokens (token_ids)
print (tokens)
# ['[CLS]', 'this', 'is', 'an', 'example', 'of', 'the', 'bert', 'token', '## izer', '[SEP]']
encode函数将 ID 101 的token转换为特殊的[CLS] token,它表示序列开头的 token。ID 为 102 的token是序列末尾的 () token。
这些token被映射到嵌入空间中的密集向量,这些向量对单词的含义及其与其他单词的关系进行编码。要获得token的嵌入,您首先需要创建一个模型。您可以通过导入BertModel并使用该from_pretrained方法来完成此操作。这将下载预训练的bert-base-uncased模型及其权重和嵌入。然后,您可以使用该embeddings.word_embeddings方法返回其词向量。
import torch
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-uncased")
# get the embedding vector for the word "example"
example_token_id = tokenizer.convert_tokens_to_ids(["example"])[0]
example_embedding = model.embeddings.word_embeddings(torch.tensor([example_token_id]))
print(example_embedding.shape)
# torch.Size([1, 768])
返回的词向量大小为 768 维,与 BERT 模型相同。我们可以使用 PyTorch 的余弦相似度函数来比较这些向量的相似度。
余弦相似度是衡量两个事物相似程度的一种方法。它经常用于NLP中来比较两个文本的内容。
为了计算余弦相似度,我们查看两个向量之间的角度。如果向量指向相同方向,则它们更相似,如果它们指向相反方向,则它们不太相似。结果是 -1 到 1 之间的数字,其中 1 表示向量完全相同,-1 表示向量完全不同。
king_token_id = tokenizer.convert_tokens_to_ids(["king"])[0]
king_embedding = model.embeddings.word_embeddings(torch.tensor([king_token_id]))
queen_token_id = tokenizer.convert_tokens_to_ids(["queen"])[0]
queen_embedding = model.embeddings.word_embeddings(torch.tensor([queen_token_id]))
cos = torch.nn.CosineSimilarity(dim=1)
similarity = cos(king_embedding, queen_embedding)
print(similarity[0])
# 0.6469
我们可以看到 King 和 Queen 的向量的相似度得分为 0.6469。
similarity = cos(example_embedding, queen_embedding)
print(similarity[0])
# 0.2392
Queen向量和example向量的相似度为 0.2392。这意味着King和Queen向量在我们的向量空间中比example和queen向量更相似。这表明我们的模型成功地学习了这些单词的“含义”并能够区分它们。
结论
在这篇博文中,我们探讨了自然语言处理 (NLP) 中的token、嵌入和向量的概念。我们讨论了它们是什么,以及它们如何用于训练神经网络。我们还学习了如何在 NLP 实际项目中使用它们。
本博文译自Sascha Metzger的博文。























![二叉树的层平均值[中等]](https://img-blog.csdnimg.cn/direct/57df6d67fc62482ea3e12a3f047860a7.png)