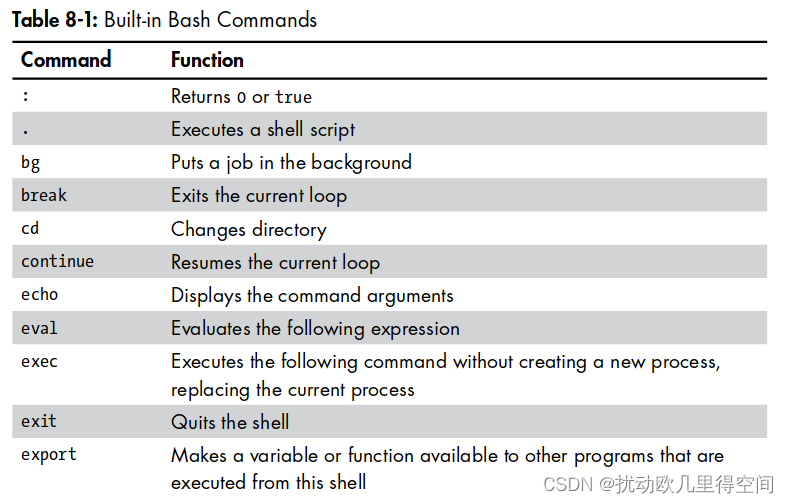
1 介绍
Reddit是一个社交新闻聚合网站,用户可以发布、评价和讨论各种话题。Reddit的内容涵盖了广泛的主题,可以从中获取大量的文本数据进行情绪分析。
2 注册
2.1 注册reddit
你需要先注册一个reddit的账号。
2.2 注册api
https://www.reddit.com/prefs/apps 在这个上面注册一个账号,开通一个api,开通完是这样的
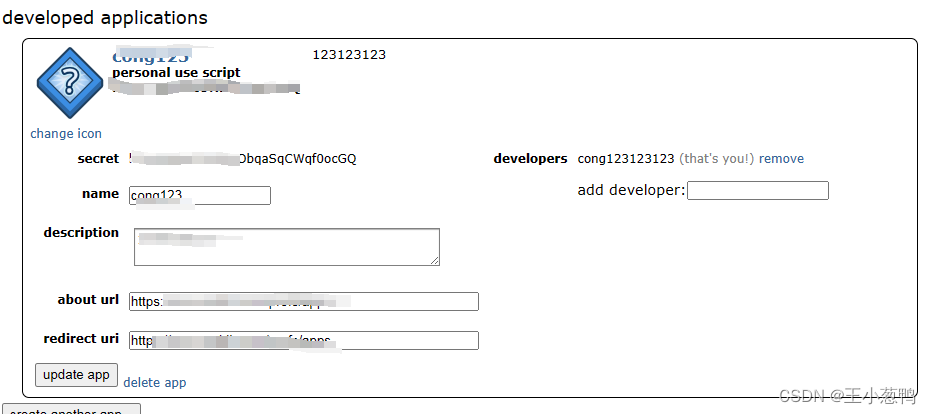
3 代码
3.1 配置
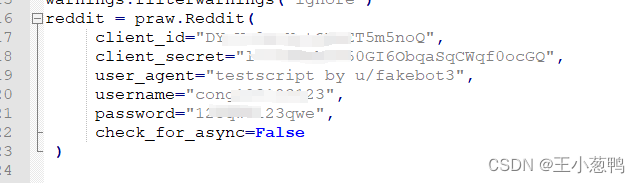
在这个代码里面,你需要4个东西
- client_id 用户的id,就是上面图片中的那一串
- client_secret 密码,就是上图的密码
- username 用户名,这个是reddit的用户名
- password 密码,这个是reddit的密码
3.2 爬取代码
主要是爬取body,这个里面存放的就是内容
需要你去设置要爬取的标题
subreddit_channel = 'politics'
for comment in reddit.subreddit(subreddit_channel).stream.comments():
tmp_df = comment
可以咨询:https://docs.qq.com/doc/DWEtRempVZ1NSZHdQ