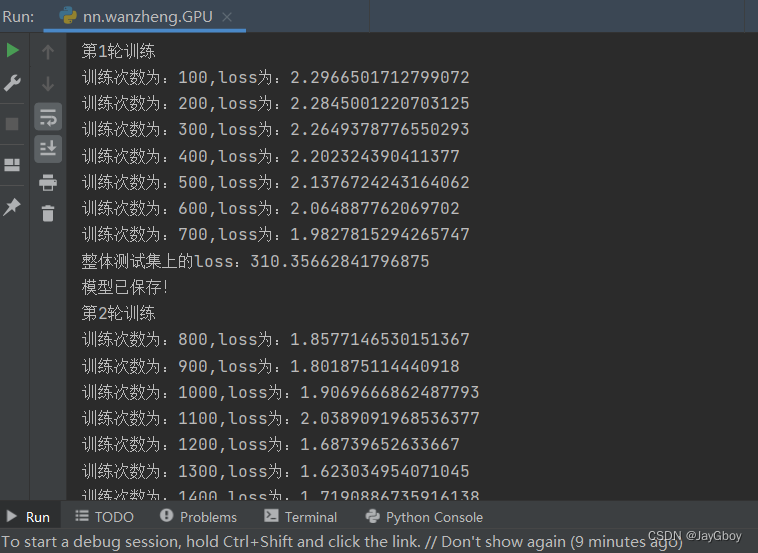
采用GPU训练
以上一篇完整的模型训练套路中的代码为例,采用GPU训练
- 判断电脑GPU可不可用
如果可用的话device就采用cuda()即调用GPU,不可用的话就采用cpu()即调用CPU。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cpu')
- 将模型移动到GPU上
通过调用to(device)方法将模型的参数和缓冲区移动到指定的设备上。
# 将模型移动到GPU上
bs = bs.to(device)
3.将数据也移动到GPU上
在迭代训练和测试数据之前,将数据也移动到GPU上。
# 将数据移动到GPU上
imgs = imgs.to(device)
targets = targets.to(device)
4.损失函数
# 将损失函数转换到device上去
loss_fn = loss_fn.to(device)
完整代码
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
'''创建模型'''
class BS(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=32,
kernel_size=5,
stride=1,
padding=2), #stride和padding计算得到
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
stride=1,
padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), #in_features变为64*4*4=1024
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self,x):
x = self.model(x)
return x
bs = BS()
print(bs)
BS(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
'''
检查gpu是否可以用,并定义设备
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1.数据集加载
train_data = torchvision.datasets.CIFAR10(
root="dataset",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(
root="dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
train_data_sise = len(train_data)
print("训练数据集的长度为:{}".format(train_data_sise))
test_data_sise = len(test_data)
print("测试数据集的长度:{}".format(test_data_sise))
train_dataloader = DataLoader(test_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
#2. 模型
# 实例化网络模型
bs = BS()
bs = bs.to(device) # 将模型移动到GPU上
# 3.损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # 将损失函数转换到device上去
# 进行优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(bs.parameters(), lr=learning_rate)
"""
4.训练循环步骤
4.1 为训练做的参数准备工作
"""
# 开始设置训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 记录是第几轮训练
epoch = 10
# 添加Tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("----第{}轮训练开始----".format(i))
"""
4.2 训练循环
"""
# 训练步骤
for data in train_dataloader:
'''
将训练数据(imgs和targets)也移动到GPU上
'''
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = bs(imgs)
loos_result = loss_fn(outputs, targets)
# 优化器优化模型
# 将上一轮的梯度清零
optimizer.zero_grad()
# 借助梯度进行反向传播
loos_result.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step,
loos_result.item()))
writer.add_scalar("train_loos", loos_result.item(),
total_train_step)
"""
5.测试循环
"""
# 测试步骤开始
total_test_loos = 0
with torch.no_grad():
for imgs, targets in test_dataloader:
'''
将测试数据(imgs和targets)也移动到GPU上
'''
imgs = imgs.to(device)
targets = targets.to(device)
outputs = bs(imgs)
loos_result = loss_fn(outputs, targets)
total_test_loos = total_test_loos + loos_result.item()
"""
6.测试过程的记录和输出
"""
print("整体测试集上损失函数loos:{}".format(total_test_loos))
writer.add_scalar("test_loos", total_test_loos, total_test_step)
total_test_step = total_test_step + 1
torch.save(bs, "test_{}.pth".format(i))
print("模型已保存")
"""
7.结束训练步骤
"""
writer.close()
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度:10000
----第0轮训练开始----
训练次数:100, loss:2.2883076667785645
整体测试集上损失函数loos:359.5490930080414
模型已保存
----第1轮训练开始----
训练次数:200, loss:2.268556594848633
训练次数:300, loss:2.2709147930145264
整体测试集上损失函数loos:354.1183063983917
模型已保存
----第2轮训练开始----
训练次数:400, loss:2.2136073112487793
整体测试集上损失函数loos:339.8271337747574
模型已保存
----第3轮训练开始----
训练次数:500, loss:2.0935685634613037
训练次数:600, loss:1.9720947742462158
整体测试集上损失函数loos:348.37053549289703
模型已保存
----第4轮训练开始----
训练次数:700, loss:2.0508975982666016
整体测试集上损失函数loos:340.7689332962036
模型已保存
----第5轮训练开始----
训练次数:800, loss:2.0063276290893555
训练次数:900, loss:1.9051704406738281
整体测试集上损失函数loos:330.71236646175385
模型已保存
----第6轮训练开始----
训练次数:1000, loss:1.8309434652328491
整体测试集上损失函数loos:317.16005206108093
模型已保存
----第7轮训练开始----
训练次数:1100, loss:1.9521994590759277
训练次数:1200, loss:1.9947333335876465
整体测试集上损失函数loos:301.4514375925064
模型已保存
----第8轮训练开始----
训练次数:1300, loss:1.761196255683899
训练次数:1400, loss:1.6156399250030518
整体测试集上损失函数loos:290.13859045505524
模型已保存
----第9轮训练开始----
训练次数:1500, loss:1.7201175689697266
整体测试集上损失函数loos:282.49458253383636
模型已保存
补充
- 通过
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")指定使用哪一块GPU来进行计算。
具体的GPU编号取决于系统中GPU的配置和可用情况
- 可以通过运行
torch.cuda.device_count()来查看系统中可用的GPU数量以及它们的编号。