系列文章目录
目录
数据处理之后,然后将数据重新保存到movie_data.xlsx
前言
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
一、Panads
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
import pandas as pd
import numpy as npPandas 基本数据结构
pandas有两种常用的基本结构:
Series- 一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很接近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
DataFrame- 二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
二、Pandas库的series类型
一维Series可以用一维列表初始化:
s = pd.Series([1,3,5,np.nan,6,8])
#index = ['a','b','c','d','x','y'])设置索引,np.nan设置空值
print(s)
#0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64默认情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的。
索引——数据的行标签
s.index #从0到6(不含),1为步长
# RangeIndex(start=0, stop=6, step=1)值
s.values
# array([ 1., 3., 5., nan, 6., 8.])
s[3]
# nan切片操作(类似于 np.array() )
s[2:5] #左闭右开
# 2 5.0
3 NaN
4 6.0
dtype: float64
s[::2]
# 0 1.0
2 5.0
4 6.0
dtype: float64索引赋值
s.index.name = '索引'
s
#索引
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64s.index = list('abcdef')
s
#a 1.0
b 3.0
c 5.0
d NaN
e 6.0
f 8.0
dtype: float64s['a':'c':2] #依据自己定义的数据类型进行切片,不是左闭右开了
#a 1.0
c 5.0
dtype: float64三、Pandas库的DataFrame类型
DataFrame则是个二维结构,这里首先构造一组时间序列,作为我们第一维的下标:
date = pd.date_range("20180101", periods = 6)
print(date)
# DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06'],
dtype='datetime64[ns]', freq='D')然后创建一个DataFrame结构:
df = pd.DataFrame(np.random.randn(6,4), index = date, columns = list("ABCD"))
df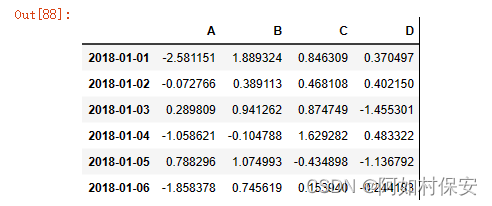
默认情况下,如果不指定index参数和columns,那么它们的值将从用0开始的数字替代。
df = pd.DataFrame(np.random.randn(6,4))
df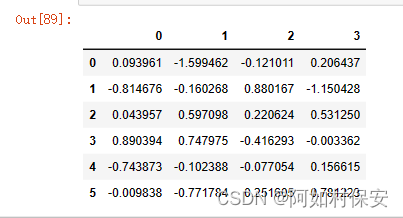
除了向DataFrame中传入二维数组,我们也可以使用字典传入数据:
df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp("20181001"),'C':pd.Series(1,index = list(range(4)),dtype = float),'D':np.array([3]*4, dtype = int),'E':pd.Categorical(["test","train","test","train"]),'F':"abc"}) #B:时间戳,E分类类型
df2
df2.dtypes #查看各个列的数据类型
字典的每个key代表一列,其value可以是各种能够转化为Series的对象。
与Series要求所有的类型都一致不同,DataFrame只要求每一列数据的格式相同。
查看数据
头尾数据
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5):
df.head()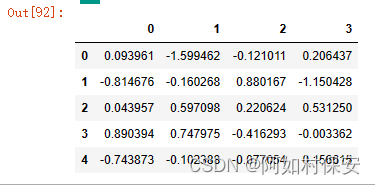
最后3行:
df.tail(3)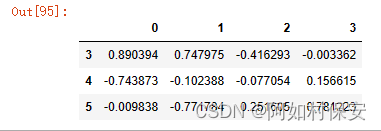
下标,列标,数据
下标使用index属性查看:
df.index
#DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06'],
dtype='datetime64[ns]', freq='D')列标使用columns属性查看:
df.columns
# Index(['A', 'B', 'C', 'D'], dtype='object')数据值使用values查看:
df.values
# array([[ 0.39194344, -1.25284255, -0.24764423, -0.32019526],
[ 0.84548738, 0.20806449, -0.06983781, 0.13716277],
[ 0.7767544 , -2.21517465, -1.11637102, 1.76383631],
[ 0.01603994, 2.00619213, 0.22720908, 1.78369472],
[-0.00621932, 0.59214148, 0.46235154, 0.99392424],
[ 1.11272049, -0.22366925, 0.08422338, -0.5508679 ]])四、pandas读取数据及数据操作
我们将以豆瓣的电影数据作为我们深入了解Pandas的一个示例。
df = pd.read_excel(r"E:\cn桌面\studydata\python\python\作业3\豆瓣电影数据.xlsx",index_col = 0)
#csv:read_csv;绝对路径或相对路径默认在当前文件夹下。r告诉编译器不需要转义
#具体其它参数可以去查帮助文档 ?pd.read_excel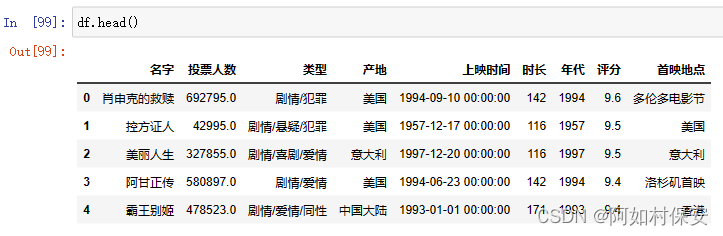

行操作
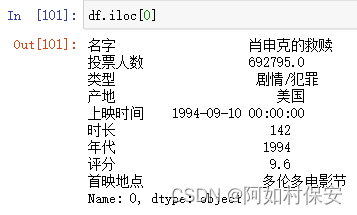
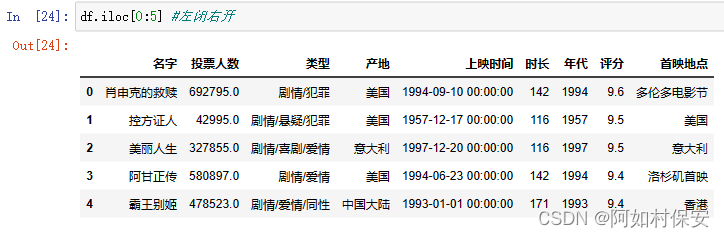
也可以使用loc
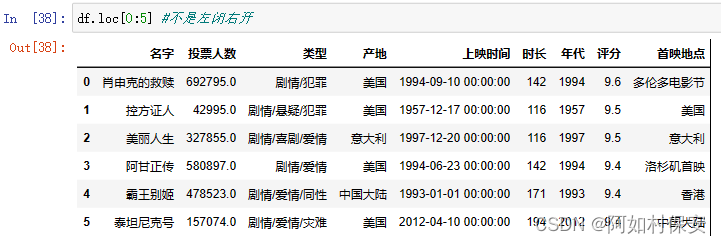
添加一行
dit = {"名字":"复仇者联盟3","投票人数":123456,"类型":"剧情/科幻","产地":"美国","上映时间":"2018-05-04 00:00:00","时长":142,"年代":2018,"评分":np.nan,"首映地点":"美国"}
s = pd.Series(dit)
s.name = 38738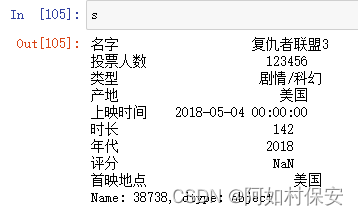
df = df.append(s) #覆盖掉原来的数据重新进行赋值
df[-5:]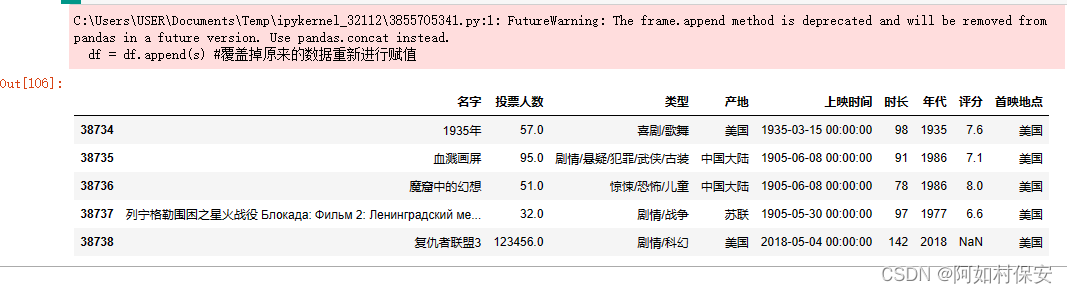
删除一行
df = df.drop([38738])
df[-5:]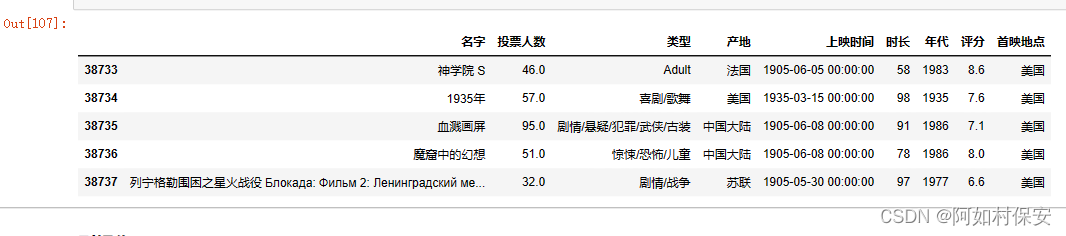
列操作
df.columns
# Index(['名字', '投票人数', '类型', '产地', '上映时间', '时长', '年代', '评分', '首映地点'], dtype='object')
df["名字"][:5] #后面中括号表示只想看到的行数,下同
# 0 肖申克的救赎
1 控方证人
2 美丽人生
3 阿甘正传
4 霸王别姬
Name: 名字, dtype: object
df[["名字","类型"]][:5]
增加一列
df["序号"] = range(1,len(df)+1) #生成序号的基本方式
df[:5]
删除一列
df = df.drop("序号",axis = 1) #axis指定方向,0为行1为列,默认为0
df[:5]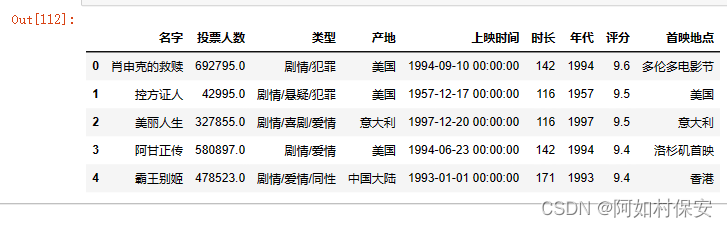
通过标签选择数据
df.loc[[index],[colunm]]通过标签选择数据
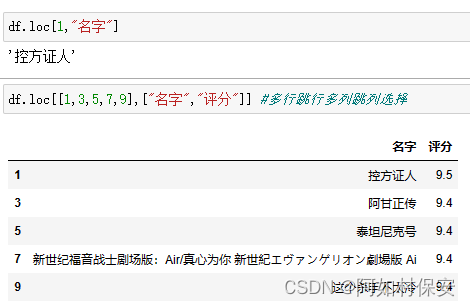
条件选择
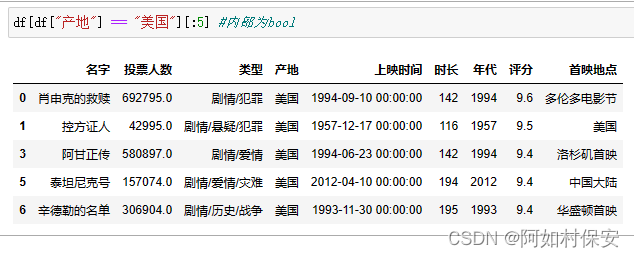
选取产地为美国的所有电影
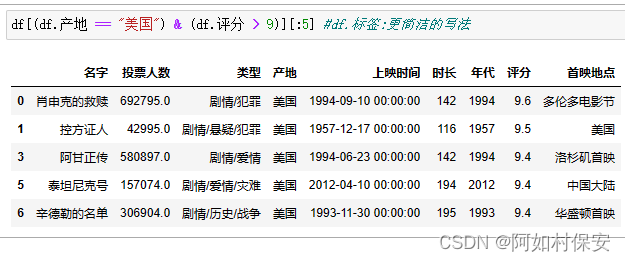
选取产地为美国的所有电影,并且评分大于9分的电影
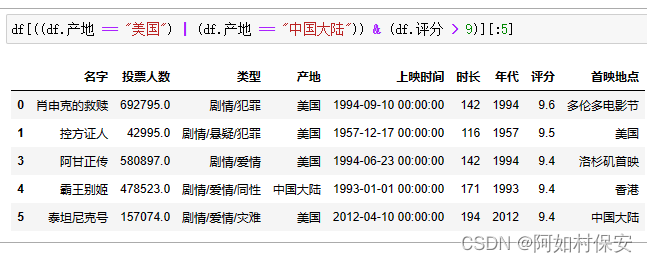
选取产地为美国或中国大陆的所有电影,并且评分大于9分的电影
五、缺失值及异常值处理
缺失值处理方法:
| 方法 | 说明 |
|---|---|
| dropna | 根据标签中的缺失值进行过滤,删除缺失值 |
| fillna | 对缺失值进行填充 |
| isnull | 返回一个布尔值对象,判断哪些值是缺失值 |
| notnull | isnull的否定式 |
判断缺失值
df[df["名字"].isnull()][:10]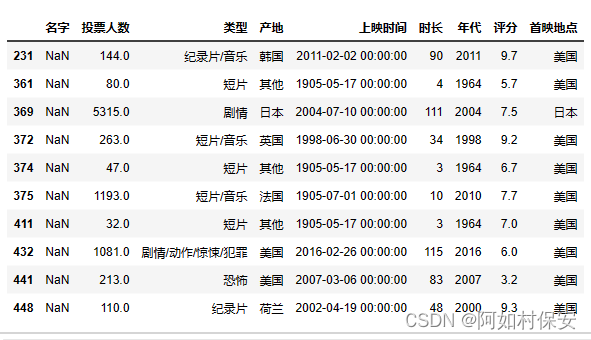
df[df["名字"].notnull()][:5]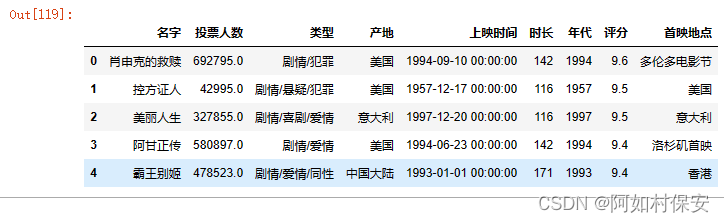
填充缺失值
df["评分"].fillna(np.mean(df["评分"]), inplace = True) #使用均值来进行替代,inplace意为直接在原始数据中进行修改
df[-5:]删除缺失值
df.dropna():删除包含任何一个空值的行
参数:
how = 'all':删除全为空值的行或列
inplace = True: 覆盖之前的数据,直接修改原始 DataFrame,不返回新的 DataFrame
axis = 0: 选择行或列,默认是行(0)
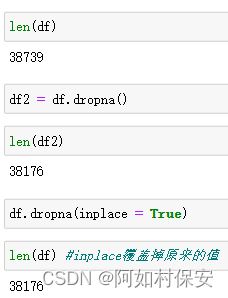
处理异常值
异常值,即在数据集中存在不合理的值,又称离群点。比如年龄为-1,笔记本电脑重量为1吨等,都属于异常值的范围。

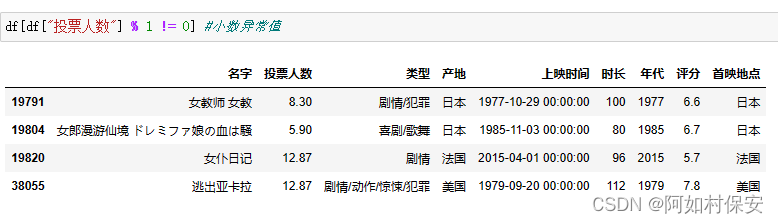
对于异常值,一般来说数量都会很少,在不影响整体数据分布的情况下,我们直接删除就可以了
其他属性的异常值处理。
六、数据保存
数据处理之后,然后将数据重新保存到movie_data.xlsx

总结
本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。下一篇写pandas的数据格式转换。