文章目录
prologue
- 没什么事,写一写SAM的paper中关于模型框架的部分和实际代码部分。
paper && code
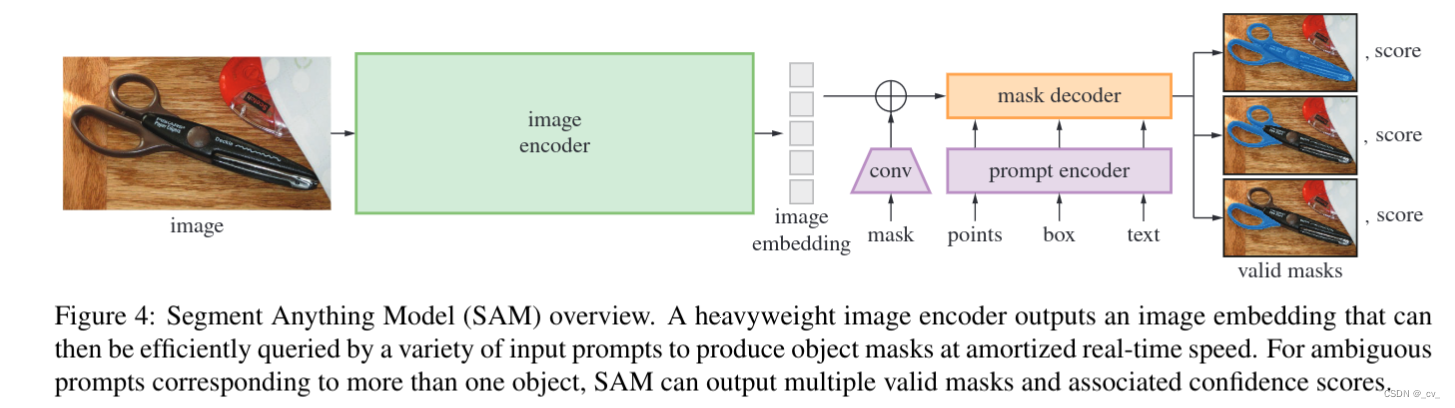
SAM有三个组件,如图所示:图像编码器、灵活的提示编码器和快速掩码解码器。我们在 Transformer 视觉模型 的基础上,对实时性能进行了特定的权衡。文章正文介绍的比较简单,有用的东西都放在附录里面了。顺便说一句上面的图还是很简洁明了的。

在附录A中
Image encoder
一般来说,图像编码器可以是任何输出 C×H×W 图像嵌入的网络。受可扩展性和对强预训练的访问的启发,我们使用 MAE [47] 预训练的视觉转换器 (ViT) [33],并以最小的适应处理高分辨率输入,特别是具有 14×14 窗口注意的 ViT-H/16 和四个等间距的全局注意块。图像编码器的输出是输入图像的 16 倍缩小嵌入。由于我们的运行时目标是实时处理每个提示,我们可以提供大量的图像编码器FLOPs,因为它们每张图像只计算一次,而不是每个提示。
按照标准做法,我们使用通过重新缩放图像和填充较短边获得的 1024×1024 的输入分辨率。因此,图像嵌入为64×64。为了减少通道维度,在[62]之后,我们使用1×1卷积来获得256个通道,然后使用3×3卷积以及256个通道。每个卷积层后面都有一个层归一化[4]。
这部分了解MAE(Masked Autoencoders Are Scalable Vision Learners)和VIT就很熟悉了,MAE是用来做自监督预训练,VIT提特征。
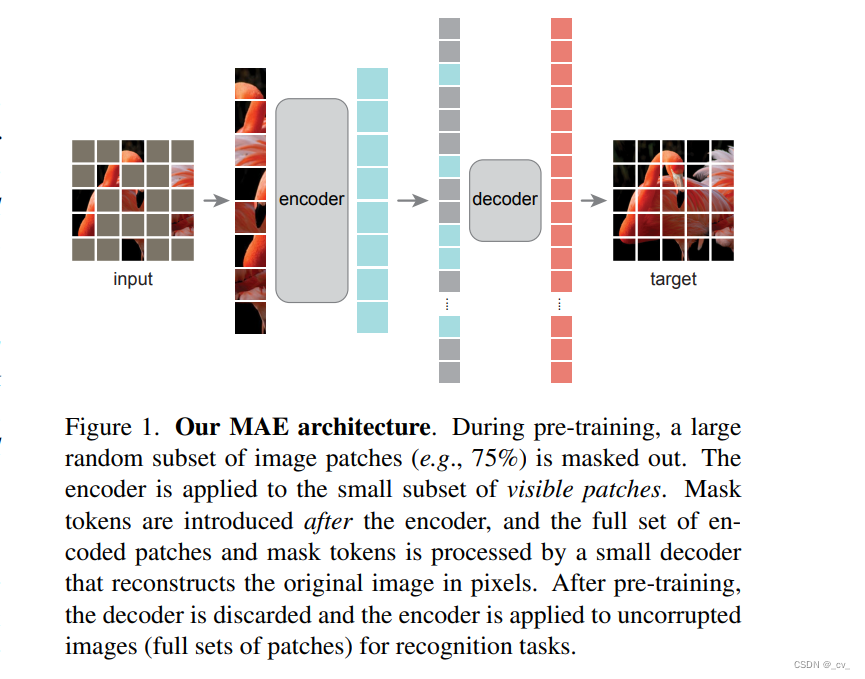
MAE主要就是mask一部分图片块让decoer重建原图;
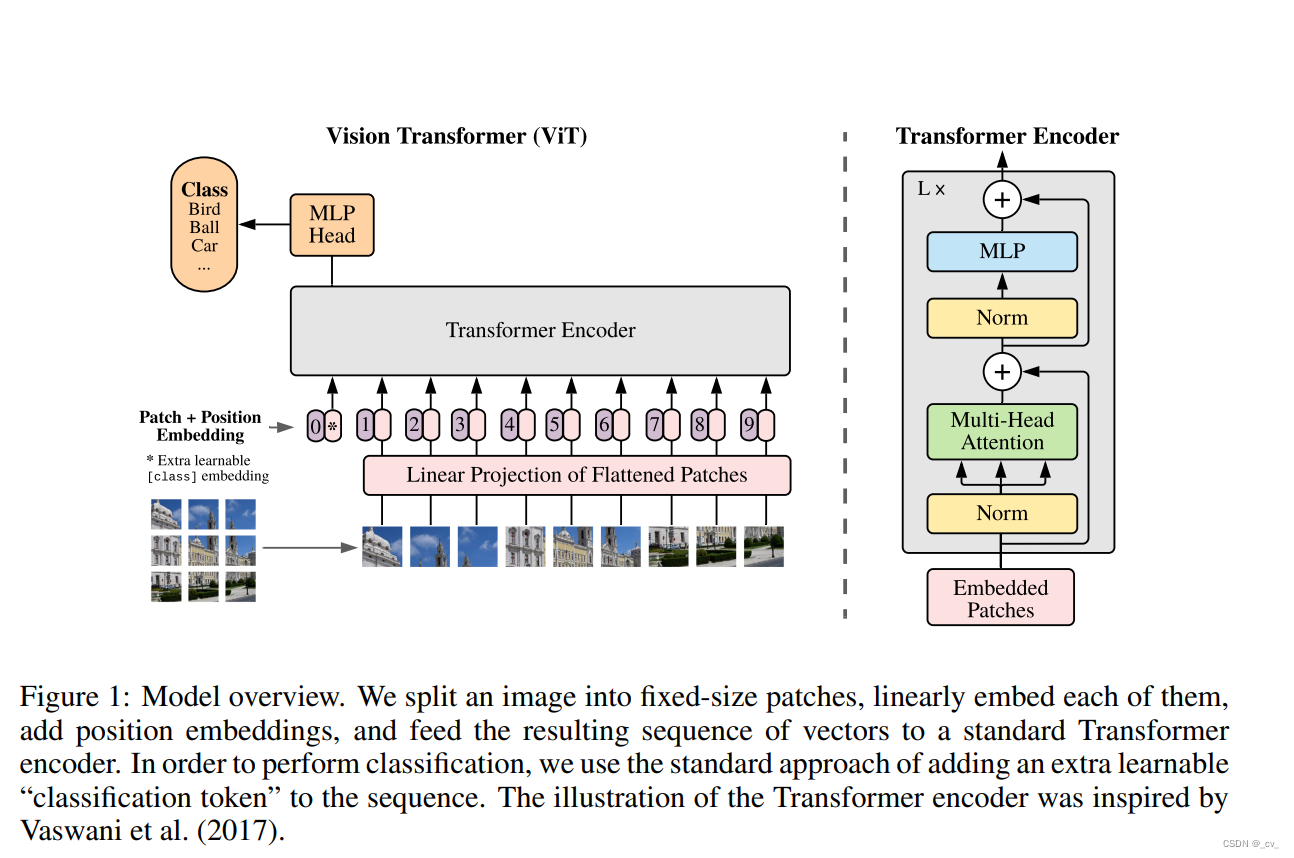
VIT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
原始VIT把图片切成PATCH做分类任务,可以用来提特征。
Prompt encoder
稀疏提示被映射到 256 维向量嵌入,如下所示。一个点表示为点位置位置编码[95]和两个学习嵌入之一的总和,表示该点是否在前景或背景中。框由嵌入对表示:(1)其左上角的位置编码与表示“左上角”和(2)相同结构的学习嵌入相加,但使用表示“右下角”的学习嵌入。最后,为了表示自由形式的文本,我们使用来自 CLIP [82] 的文本编码器(任何文本编码器通常都可以)。我们专注于本节的其余部分的几何提示,并在第 D.5 节中深入讨论文本提示。(这里关于clip的部分也就是代码没有放出来的,可以根据这里的细节复现,也有人这么做了)
密集提示(即掩码)与图像具有空间对应关系。我们以比输入图像低 4 倍的分辨率输入掩码,然后使用两个输出通道 4 和 16 的 2×2、stride-2 卷积分别缩小额外的 4 倍。最终的 1×1 卷积将通道维度映射到 256。每一层都由 GELU 激活 [50] 和层归一化分隔。掩码然后按元素添加图像嵌入。如果没有掩码提示,则将表示“无掩码”的学习嵌入添加到每个图像嵌入位置。
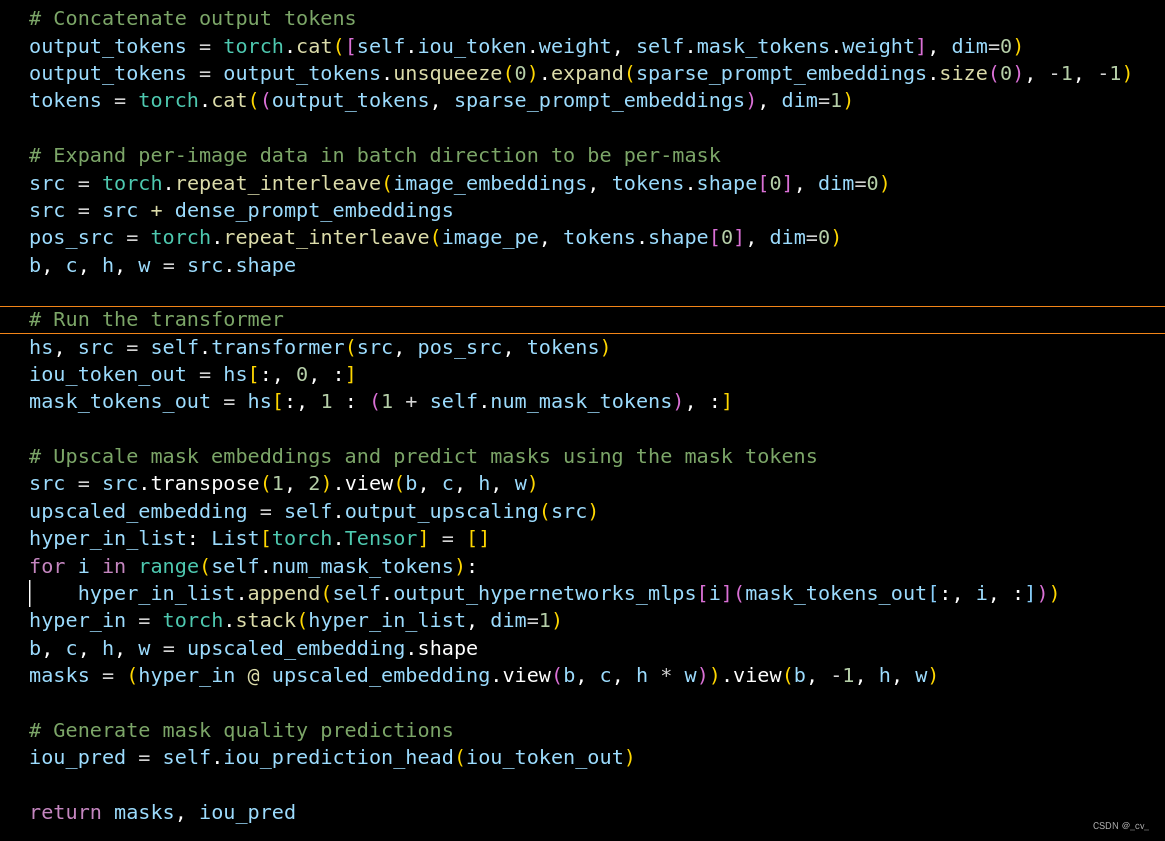
Lightweight mask decoder
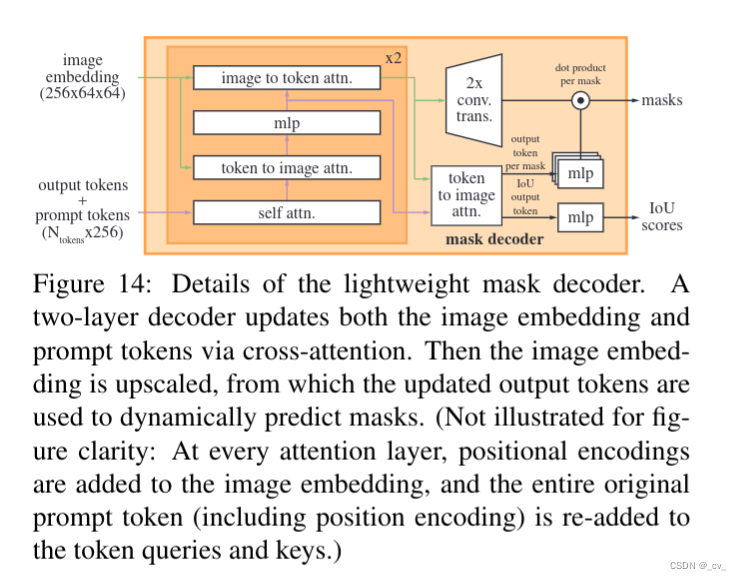
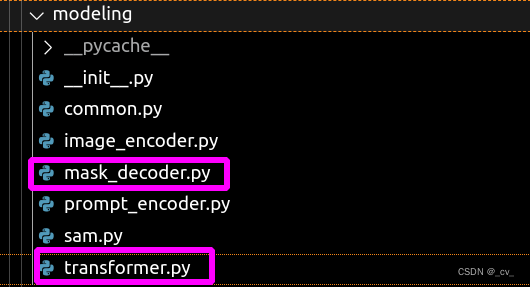
这部分还是看代码来的快,上图左边深色区域在代码transformer.py中,右边浅色部分在mask_decoder.py中。
下图的四块分别对应着左边深橙色的四个步骤,也就是原文如下


右边橙色
Making the model ambiguity-aware
如前所述,单个输入提示可能是模糊的,因为它对应于多个有效掩码,模型将学会对这些掩码进行平均。我们通过简单的修改来消除这个问题:我们没有使用预测单个掩码,而是使用少量输出标记并同时预测多个掩码。
默认情况下,我们预测三个掩码,因为我们观察到三层(整体、部分和子部分)通常足以描述嵌套掩码。
在训练期间,我们计算地面实况和每个预测掩码之间的损失(稍后描述),但仅从最低损失反向传播。这是用于具有多个输出的模型的常用技术 [15, 45, 64]。为了在应用程序中使用,我们想对预测的掩码进行排名,因此我们添加了一个小头(在额外的输出令牌上运行),它估计每个预测掩码与其覆盖的对象之间的 IoU。具有多个提示的歧义非常罕见,三个输出掩码通常变得相似。为了最小化训练时退化损失的计算并确保单个明确掩码接收常规梯度信号,当给出多个提示时,我们只预测单个掩码。这是通过为额外的掩码预测添加第四个输出标记来实现的。这个第四个掩码永远不会为单个提示返回,并且是为多个提示返回的唯一掩码。
累了