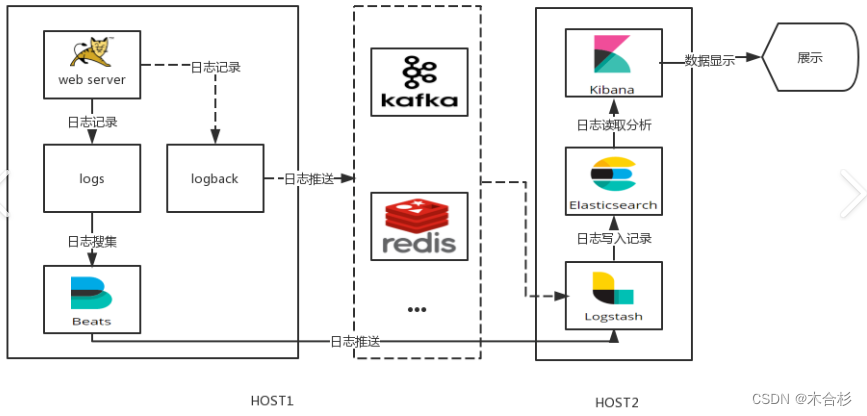
ELK日志分析系统
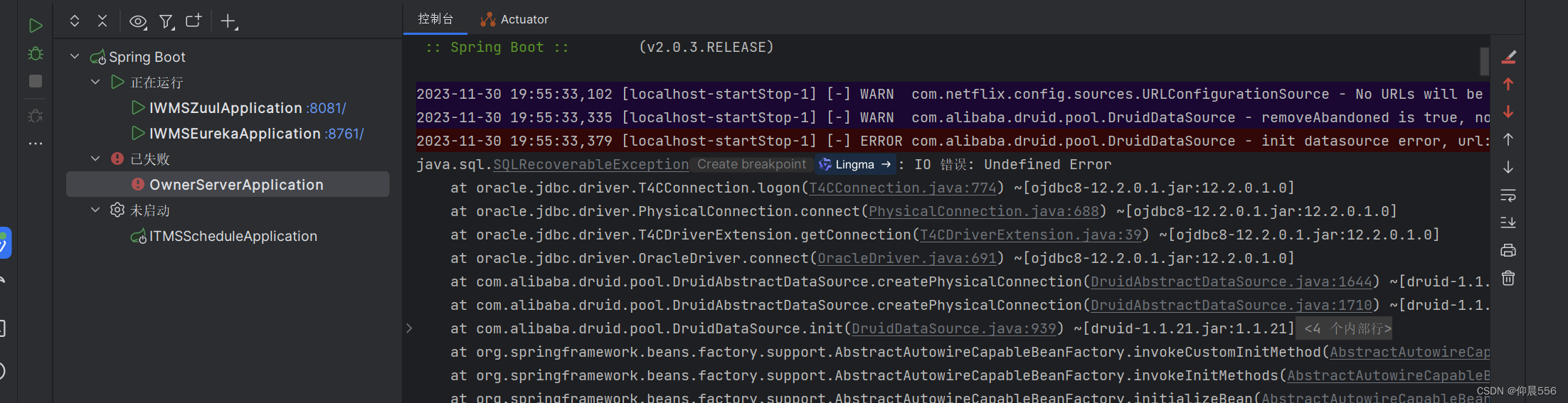
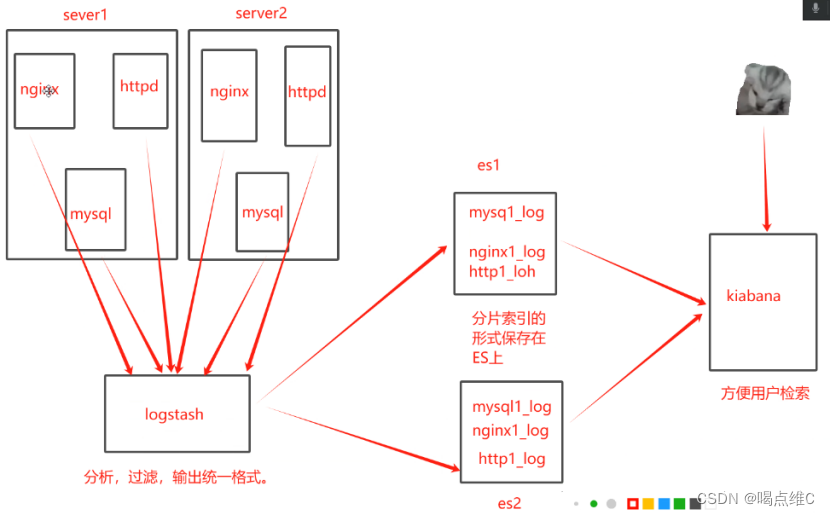
elk是一套完整的日志集中处理方案,由三个开源软件简称组成
E:ElasticSearch ES是一个开源的,分布式的存储检索引擎(索引型的非关系数据库)。存储日志 由Java代码开发的,基于Lucene结构开发的一套 全文检索引擎。拥有web接口,用户可以通过浏览器的形式和ES组件进行通信
作用:存储,允许全文搜索,结构化搜索(索引点),索引点可以支持大容量的日志数据。也可以搜索其他不同类型的文档
L:Logstash,数据收集引擎,支持动态的(实时)从各种服务应用收集日志资源,还可以收集到日志数据进行过滤,分析,丰富,统一格式等等操作,然后把数据同步到ES存储引擎
RUBY语言编写的,运行在Java虚拟机上的一个强大的数据处理工具,数据传输,格式化处理,格式化输出,主要用来处理日志
K:Kiabana,图形化界面,可以更好的分析存储在ES上的日志数据。提供了一个图形化的界面来浏览ES上的日志数据。汇总、分析、搜索。
数据收集工具:
fliebeat:轻量级的开源的,日志收集数据,收集的速度比较快,但是没有数据分析和过滤的能力,一般是结合logstash一块使用
kafka
RabbitMQ 中间件消息队列
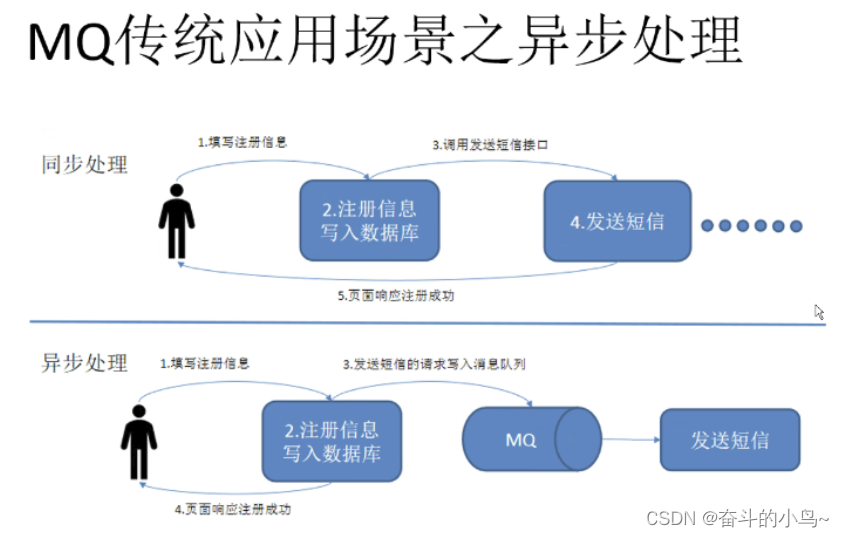
总结:ELK的作用,当我们管理一个大集群时,需要分析和定位的日志就会很多,每一台服务器分别去饭呢西,将会耗时耗力,所以我们应运而生了一个集群的统一的日志管理和分析系统,极大的提高了定位问题的效率。
日志系统的特征:
1、收集,可以收集基本上市面上常用的软件日志
2、传输,收集的日志需要发送到ES上
3、存储,es负责存储数据
4、UI:图形化界面(kiabana)
es的性能调优:
内核优化:
ES是基于lucene架构,实现的一款索引型数据库。lucene可以利用操作系统的内存来缓存ES的索引数据
提供更快的查询速度。在工作中我们会把系统的一半内存留给lucene
机器内存小于64G,50%给es,50%给操作系统,供lucene使用
机器内存大于64G,ES分配4-32G即可,其他的都给操作系统
logstash的命令常用选项:
-f 指定配置文件,根据配置文件识别输入和输出流
-e 测试,从命令行当中获取输入,然后经过logstash加工之后,形成一个标准输出
-t 检测配置文件是否正确,然后退出
logstash -f nginx.conf --path.data /opt/test1
ELK实验:
es1:192.168.233.20(2核4G)
es2:192.168.233.30(2核4G)
logstash kibana:192.168.233.10(4核8G)
三台组件最少要2核4G
三台机器先关防火墙和安全机制
然后查看version

es1和es2一块操作


![]()
修改两台机子配置文件
![]()
![]()
然后vim elasticsearch.yml,这个时候要将同步关闭
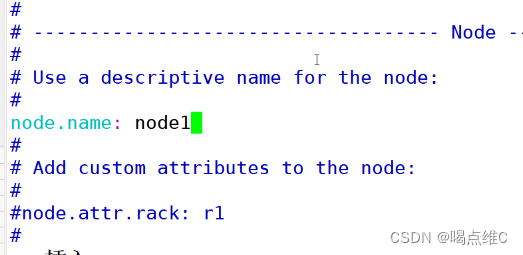
取消注释name名字可以随意

前面叫node1 第二台就得叫node2
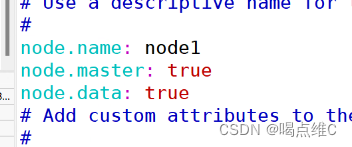
在node1和2下面插入几行

1和2都在下面30行左右找到path.data
path.data: /var/lib/elasticsearch
实验环境下不用打开1和2在43行左右找到bootstrap取消注释

1和2在55行左右找到network.host取消注释,改成0.0.0.0

1和2在60行左右http.port:9200取消注释,并且在下面添加一行

1和2在71行左右找到discovery.zen取消注释,然后在双引号里面添加es1和2的ip地址
![]()
保存退出
检查配置文件是否正确
![]()
es1和es2修改最大文件数的配置文件
![]()
在最后一行添加
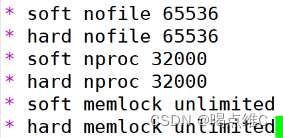
做完之后需要重启
![]()
打开配置文件,如果在工作中遇到这个配置需要重启生效。
![]()
找到这三行

第一行的意思是:一个用户会话的默认最大文件描述符的陷质量
文件描述符:用于表示打开文件或者I/O资源限制的整数
第二行的意思是:一个用户可以打开的最大进程数量的限制32000。一个用户的终端可以运行多少个进程
第三行的意思是:一个用户的终端默认锁定内存的限制,infinity就是不限制
改内核配置文件
![]()
在最后一行插入
![]()
重启reboot

内存映射:将文件或者其他设备映射进程地址空间的方法,允许进程直接读取或者写入文件,无需常规的I/O方式
映射空间越大,ES和lucene的速度越快
2g/262144
4g/4194304
8g/8388608
开启es1和2的服务
![]()
![]()
然后查看端口起没起来
![]()
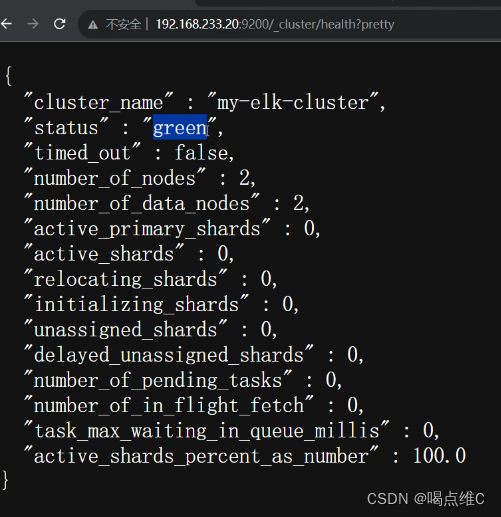
然后用浏览器测试一下


查询地址的健康状态,green就是健康状态没问题,yellow就是有问题
es1和2同步操作
![]()

es1和2同步安装数据包gcc

es1和2同步解压
tar zxvf node-v8.2.1.tar.gz
![]()
es1和2同步cd 到node-v8.2.1
![]()
es1和2同步开始配置
![]()
es1和2同步make -j 2 && make install
![]()
es1和2同步操作,cd到/opt
![]()
es1和2同步要先解压这个文件
![]()
然后cd进去
![]()
![]()
es1和2同步把这个文件拖进来
![]()
解压
![]()
cd进去
![]()
es1和2同步 如果担心速度慢,可以先npm config set registry http://registry.npm.taobao.org/
然后在npm install

改配置文件
![]()
在最后一行插入几行添加

第一行的意思是开启跨域访问的支持
第二行是开启跨域访问之后,允许访问的域名地址 *:所有
重启服务
![]()
查看端口是否起来
![]()
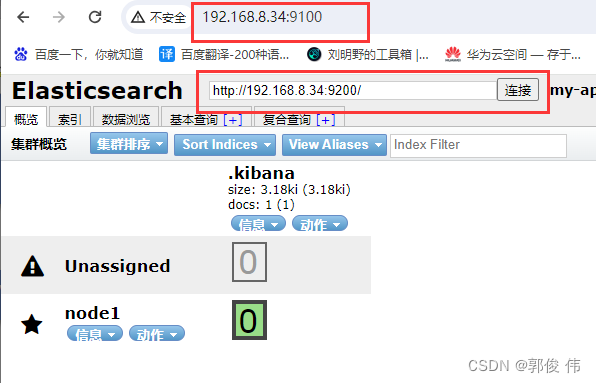
cd 到opt目录下的这个文件
![]()


9100是可视化工具的访问端口,9200还是ES数据库的访问端口
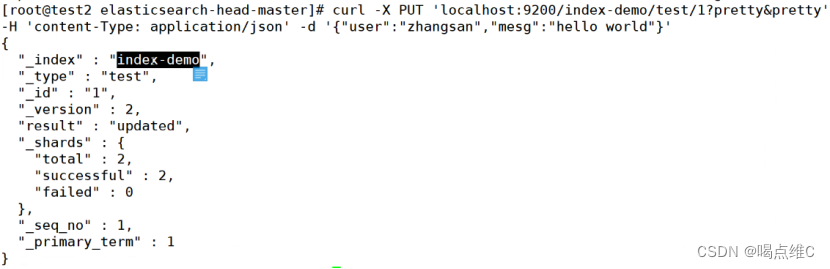
插入索引进行测试
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
在test1进行操作:
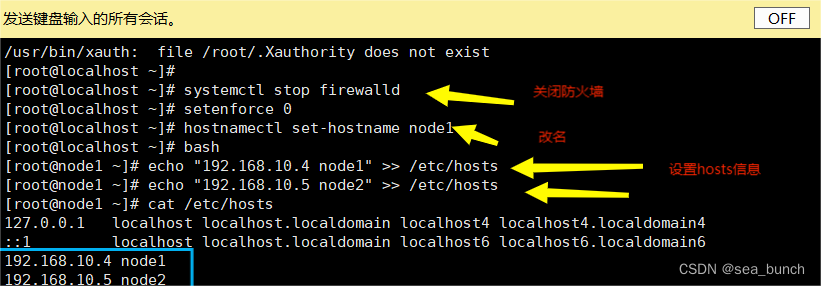
更改主机名
hostnamectl set-hostname apache
![]()
安装nginx服务(nginx)
![]()
yum -y install nginx
![]()
systemctl start nginx
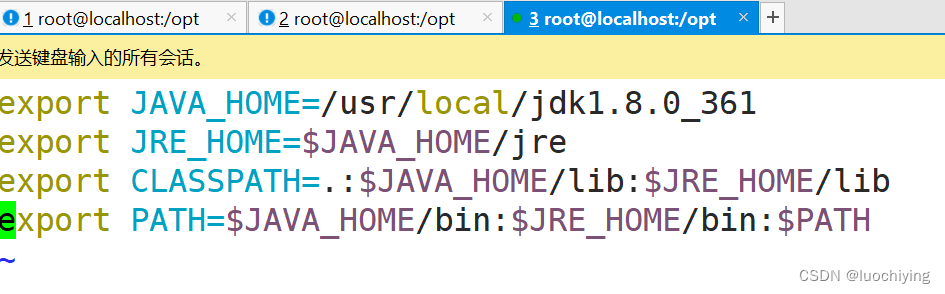
安装java
![]()
cd /opt
拖两个软件
安装logstash
![]()
重启服务和
设置开机自启
systemctl start logstash.service
systemctl enable logstash.service

创建软连接
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
![]()
测试
logstash -e 'input { stdin{} } output { stdout{} }'
![]()
![]()

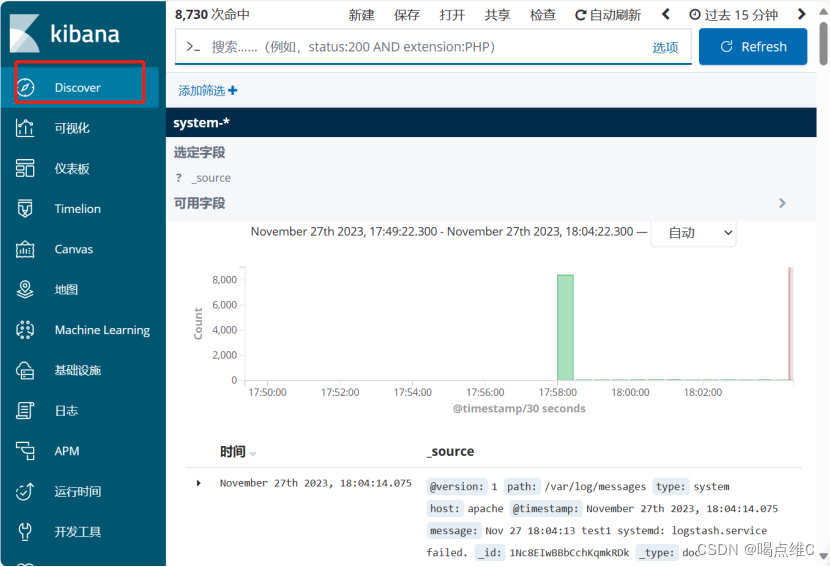
使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch
{ hosts=>["192.168.233.30:9200","192.168.233.100:9200"] } }'

意思是:所有的键盘命令行输出,转化成标准输出(rubydebug的模式),6.0之后,logstash的默认输出格式就是rubydebug格式的标准输出
![]()
如果出现这个报错 可以在后面添加

![]()
区分不同的数据存放目录
6.0之后的logstash自带的输出格式/rubydebug,自动的把输出格式,定义为统一的标准格式输出
cd /opt
把这个软件拖进去
![]()
安装kibana
![]()
修改配置文件
![]()
在第7行改成0.0.0.0
![]()
在第28行取消注释,然后添加ip地址
![]()
在37行 取消注释
![]()
在96行改一下日志路径
![]()
在113行取消注释,改成zh-CN
![]()
创建日志文件
![]()
把日志文件的所有者和所在组改掉
![]()
重启服务和开机自启

查看端口号

在浏览器上进行访问,点击否
创建一个日志路径目录
mkdir log
写配置文件
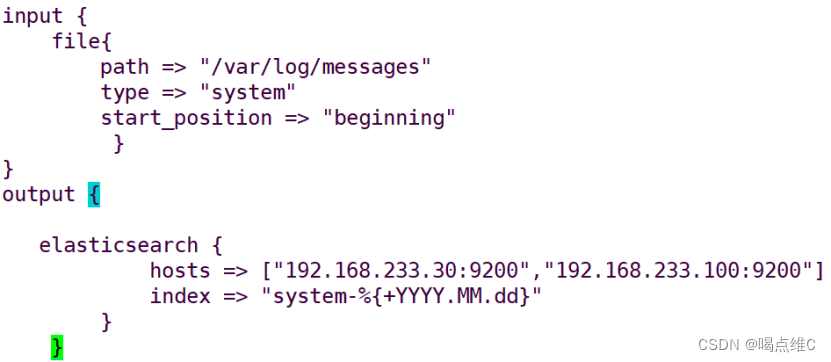
![]()
![]()


修改配置文件
![]()

然后重启服务
![]()
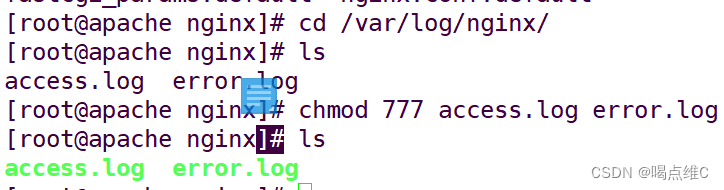
cd到/var/log文件下
![]()
给权限
![]()
查看nginx服务是否开启

写一个配置文件
![]()
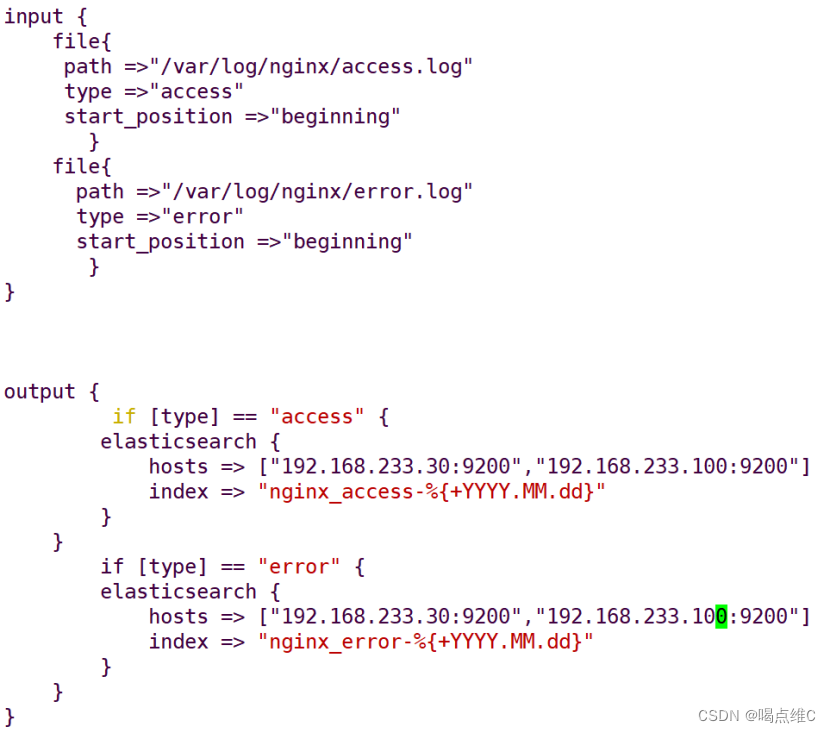
给nginx文件赋权
执行这个配置文件
![]()
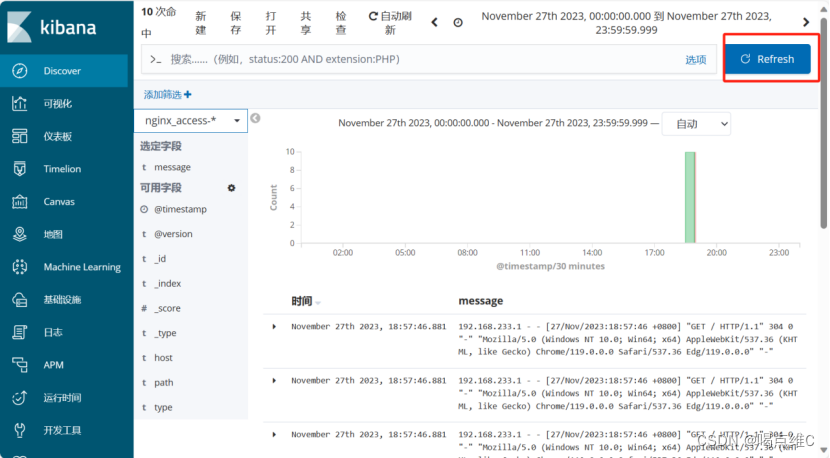
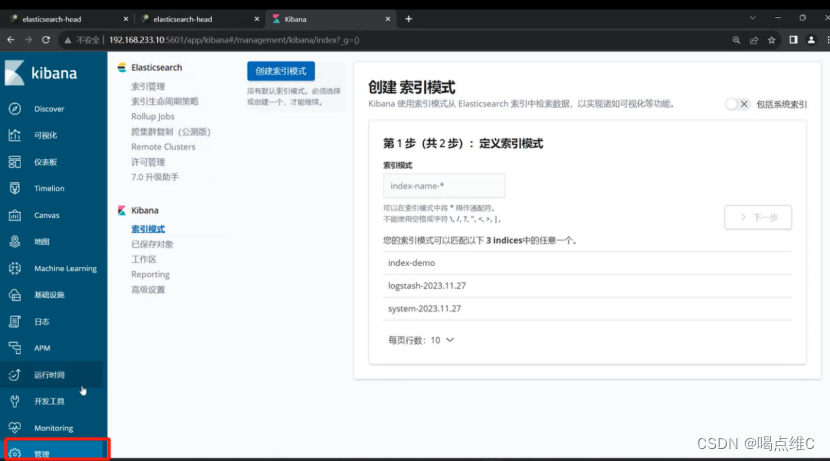
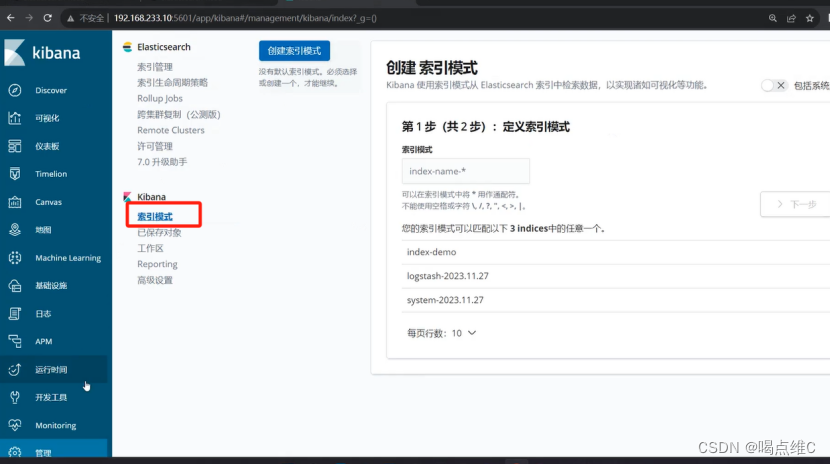
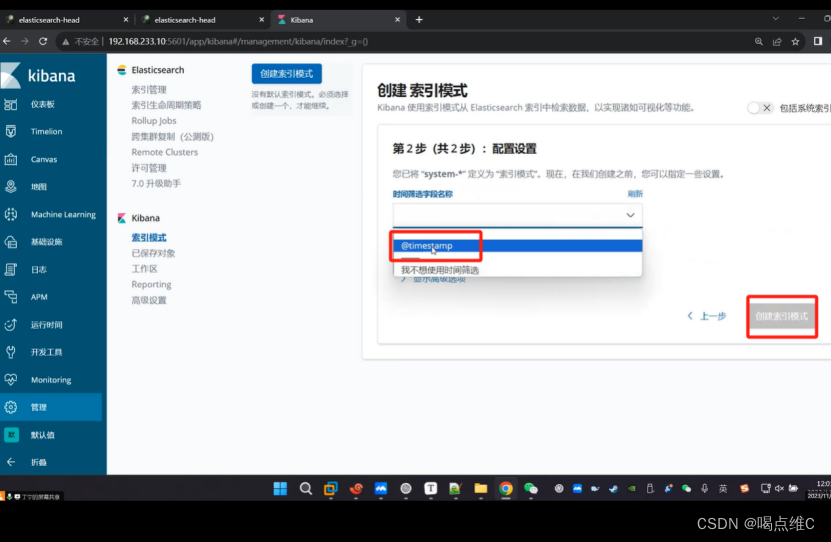
创建索引:

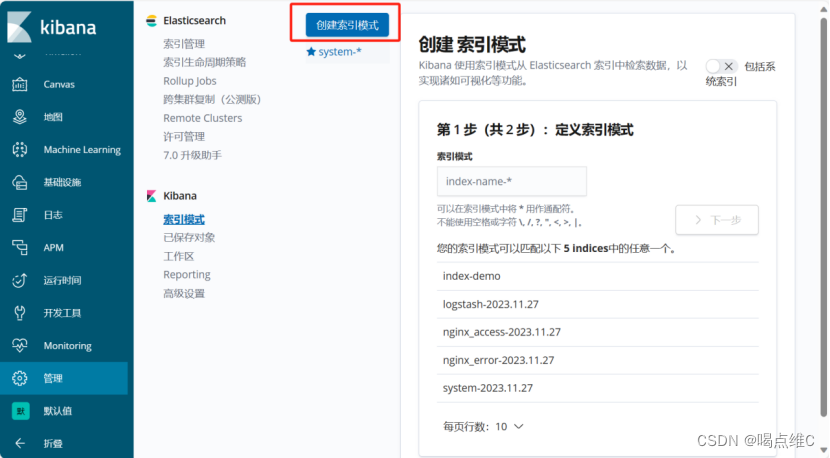

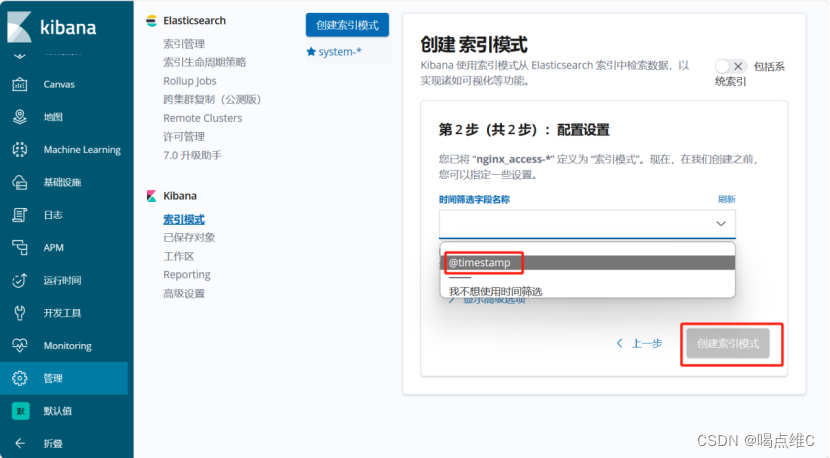
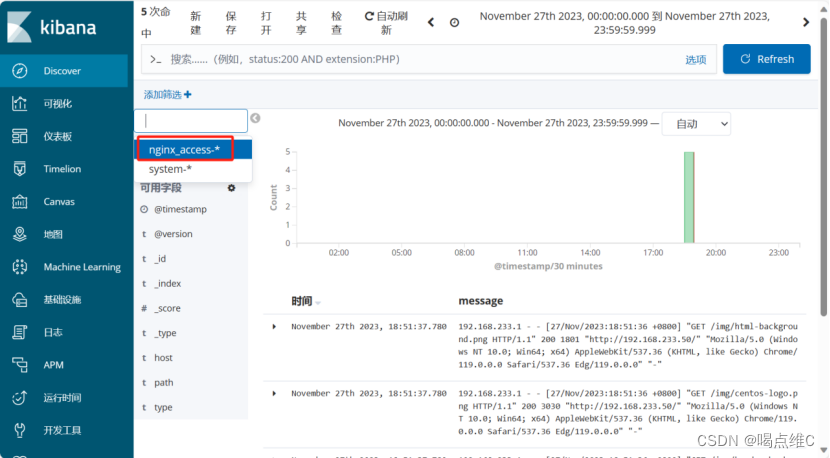
刷新一下
再刷新一下