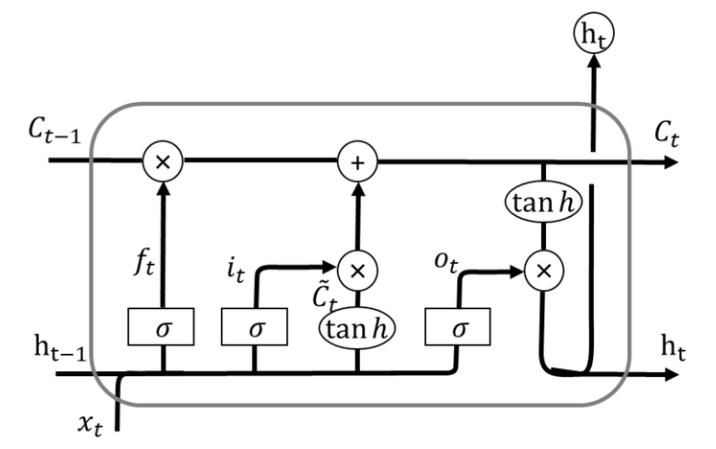
LSTM 应用预测股票数据
所用数据集:https://www.kaggle.com/datasets/yuanheqiuye/bank-stock
基于:tensorFlow 2.x
数据处理
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv('data.csv', index_col=0)
# 将数据分为特征和目标变量
y = np.array(data['open'], dtype='float32').reshape(-1, 1)
X = np.array(data.drop('open', axis=1)).astype('float32')
# 划分数据集为训练集和测试集(95%训练,5%测试)
train_xs, test_xs, train_ys, test_ys = train_test_split(X, y, test_size=0.05, random_state=42)
# y 归一化处理
min_train_ys = train_ys.min()
max_train_ys = train_ys.max()
train_ys = (train_ys - min_train_ys) / (max_train_ys - min_train_ys)
test_ys = (test_ys - min_train_ys) / (max_train_ys - min_train_ys)
# 对x特征进行归一化处理
for dim in range(train_xs.shape[1]):
min_val = train_xs[:, dim].min()
max_val = train_xs[:, dim].max()
train_xs[:, dim] = (train_xs[:, dim] - min_val) / (max_val - min_val)
test_xs[:, dim] = (test_xs[:, dim] - min_val) / (max_val - min_val)
# 重新排列数据以创建时间序列
time_step = 5
input_dim = 13
def create_time_series_data(xs, ys, time_step):
aranged_xs = np.zeros(shape=(xs.shape[0] - time_step + 1, time_step, input_dim))
for idx in range(aranged_xs.shape[0]):
aranged_xs[idx] = xs[idx:idx + time_step]
aranged_ys = ys[time_step - 1:]
return aranged_xs, aranged_ys
aranged_train_xs, aranged_train_ys = create_time_series_data(train_xs, train_ys, time_step)
aranged_test_xs, aranged_test_ys = create_time_series_data(test_xs, test_ys, time_step)
# 保存数据
np.save(r'train_x_batch.npy', aranged_train_xs)
np.save(r'train_y_batch.npy', aranged_train_ys)
np.save(r'test_x_batch.npy', aranged_test_xs)
np.save(r'test_y_batch.npy', aranged_test_ys)
模型训练
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
# Hyperparams
batch_size = 128 # 批量大小,指定每次迭代训练时传入模型的样本数量。较大的批量大小可以加快训练速度,但可能会占用更多的内存资源。
lr = 1e-4 # 控制模型在每次迭代时更新权重的步长。较小的学习率可以使模型收敛得更慢但更稳定,较大的学习率可以加快收敛速度但可能导致不稳定的训练过程。
epochs = 400 # 训练轮数,指定模型要遍历整个训练数据集的次数。每个 epoch 包含多个批次的训练。
num_neurons = [32, 32, 64, 64, 128, 128] # 神经元数量,指定每个隐藏层的神经元数量。这里给出了一个列表,表示了模型中每个隐藏层的神经元数量。通常情况下,增加神经元数量可以增加模型的表达能力,但也可能增加过拟合的风险。
kp = 0.99 # 保持概率(keep probability),用于控制 Dropout 正则化的保留概率。Dropout 是一种正则化技术,通过随机地丢弃一部分神经元的输出来减少过拟合。保持概率 kp 指定了要保留的神经元输出的比例,例如 kp=1.0 表示保留全部输出。
def load_data():
train_x_batch = np.load(r'train_x_batch.npy', allow_pickle=True)
train_y_batch = np.load(r'train_y_batch.npy', allow_pickle=True)
return (train_x_batch, train_y_batch)
# 载入数据
(train_x, train_y) = load_data()
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).shuffle(buffer_size=128).batch(batch_size)
# 定义模型
model = tf.keras.Sequential([
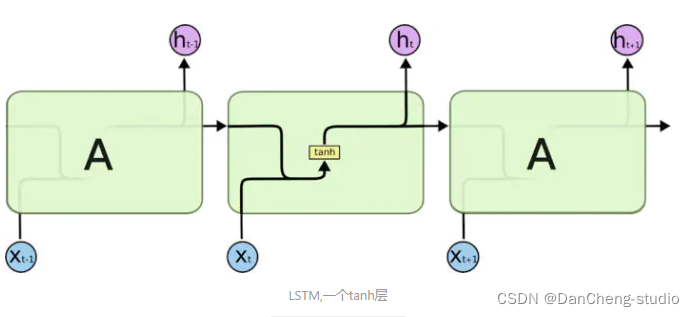
tf.keras.layers.LSTM(num_neurons[0], return_sequences=True, input_shape=(5, 13)),
tf.keras.layers.Dropout(1 - kp),
tf.keras.layers.LSTM(num_neurons[1], return_sequences=True),
tf.keras.layers.Dropout(1 - kp),
tf.keras.layers.LSTM(num_neurons[2], return_sequences=True),
tf.keras.layers.Dropout(1 - kp),
tf.keras.layers.LSTM(num_neurons[3], return_sequences=True),
tf.keras.layers.Dropout(1 - kp),
tf.keras.layers.LSTM(num_neurons[4], return_sequences=True),
tf.keras.layers.Dropout(1 - kp),
tf.keras.layers.LSTM(num_neurons[5]),
tf.keras.layers.Dense(1)
])
# 编译模型
model.compile(optimizer=tf.keras.optimizers.legacy.SGD(learning_rate=lr), loss='mean_squared_error')
# 使用提前停止
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=5)
# 训练模型
history = model.fit(train_data, epochs=epochs, callbacks=[early_stopping])
# 可视化训练过程
plt.plot(history.history['loss'])
plt.ylim(0, 1.2 * max(history.history['loss']))
plt.title('loss trend')
plt.xlabel('Epoch')
plt.ylabel('loss')
plt.show()
# 保存模型
model.save(r'stock_lstm_model.keras')
预测
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
def load_data():
test_x_batch = np.load(r'test_x_batch.npy', allow_pickle=True)
test_y_batch = np.load(r'test_y_batch.npy', allow_pickle=True)
return (test_x_batch, test_y_batch)
# 超参数
num_neurons = [32, 32, 64, 64, 128, 128]
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.LSTM(num_neurons[0], return_sequences=True, input_shape=(None, 13)),
tf.keras.layers.LSTM(num_neurons[1], return_sequences=True),
tf.keras.layers.LSTM(num_neurons[2], return_sequences=True),
tf.keras.layers.LSTM(num_neurons[3], return_sequences=True),
tf.keras.layers.LSTM(num_neurons[4], return_sequences=True),
tf.keras.layers.LSTM(num_neurons[5]),
tf.keras.layers.Dense(1)
])
# 尝试加载模型权重
model.load_weights(r'stock_lstm_model.keras')
# 载入数据
test_x, test_y = load_data()
# 预测
predicts = model.predict(test_x)
predicts = ((predicts.max() - predicts) / (predicts.max() - predicts.min())) # 数学校准
# 可视化
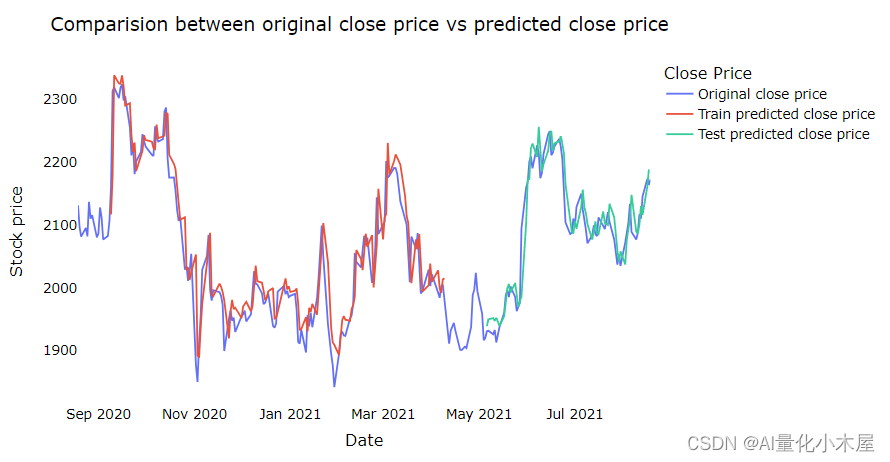
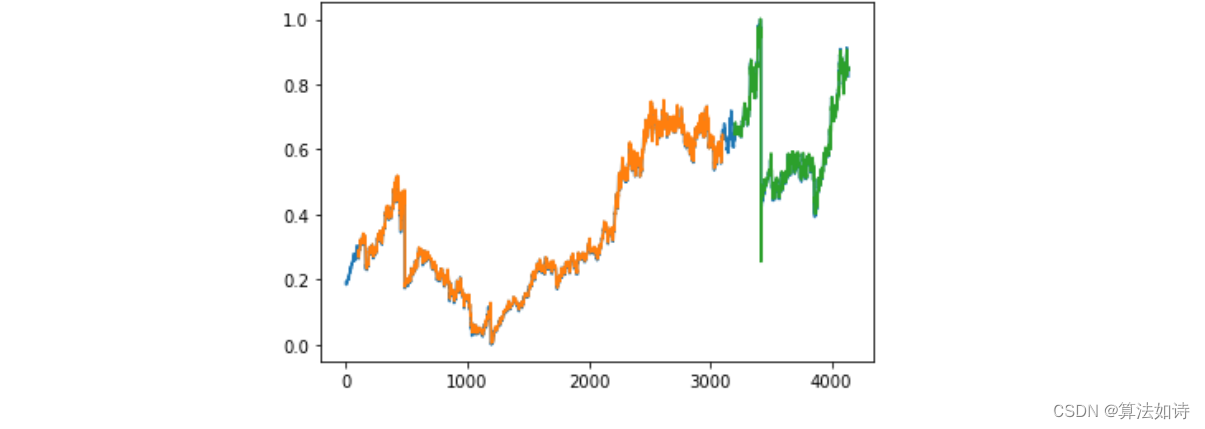
plt.figure(figsize=(12, 6))
plt.plot(predicts, 'r', label='predict')
plt.plot(test_y, 'g', label='real')
plt.xlabel('days')
plt.ylabel('open')
plt.title('predict trend')
plt.legend()
plt.show()




















![P1005 [NOIP2007 提高组] 矩阵取数游戏](https://img-blog.csdnimg.cn/direct/f7ad55ddb3054c3b84bd2607c0bce9e7.png)
![[ Linux Audio 篇 ] 音频开发入门基础知识](https://img-blog.csdnimg.cn/direct/17d7f926deea40ecaa8c65458ff00de4.gif#pic_center)