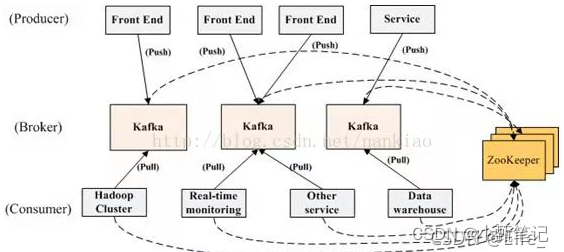
Apache Kafka 是一个分布式流处理平台,被广泛用于构建实时数据流应用程序和大数据处理系统。本文将深入探讨 Kafka 的起源、设计原则以及它在大数据领域中的重要作用。
大数据和实时数据处理背景
在大数据时代,处理海量数据和实时数据成为了一项关键挑战。传统的消息传递系统往往难以满足实时性和可伸缩性的需求。这正是 Kafka 出现的背景。Kafka 最初由 LinkedIn 公司开发,用于满足其实时数据处理和日志收集的需求。
Kafka 的设计原则
Kafka 的设计基于一些关键原则,使其成为一个高性能、可伸缩、持久化的分布式消息系统。
1 分布式架构
Kafka 采用分布式架构,可以轻松地扩展到多个节点,以处理高吞吐量和大规模数据。
// 示例代码:创建 Kafka 生产者
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
2 持久性
Kafka 的消息被持久化存储在磁盘上,保证消息不会丢失,即使消费者未及时处理。
// 示例代码:创建 Kafka 消费者
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "my-group");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(properties);
3 高性能
Kafka 通过批处理和分区等机制,实现了高吞吐量和低延迟的特性。
// 示例代码:Kafka 生产者批量发送消息
Producer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), "Message " + i));
}
producer.close();
Kafka 的应用场景
Kafka 在多个领域都有着广泛的应用,其中包括实时日志处理、事件溯源、流式数据处理等。
1 实时日志处理
Kafka 可以作为实时日志收集和处理的中心枢纽,各种服务可以将日志发送到 Kafka,供其他系统实时消费和分析。
// 示例代码:服务将日志发送到 Kafka
Producer<String, String> producer = new KafkaProducer<>(properties);
producer.send(new ProducerRecord<>("logs-topic", "Service-A", "Log message from Service-A"));
producer.close();
2 流式数据处理
Kafka 提供了流处理功能,使得开发人员可以方便地构建实时数据流应用程序,处理连续的数据流。
// 示例代码:使用 Kafka Streams 处理实时数据流
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> sourceStream = builder.stream("input-topic");
sourceStream.mapValues(value -> value.toUpperCase())
.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), properties);
streams.start();
Kafka 的核心概念
1 Topic 和 Partition
在 Kafka 中,消息被发布到主题(Topic)中。每个主题可以被分成一个或多个分区(Partition)。这种分区的设计提供了水平扩展的能力,也允许数据并行处理。
// 示例代码:创建具有多个分区的主题
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 1 --bootstrap-server localhost:9092
2 生产者和消费者
生产者(Producer)负责向 Kafka 主题发布消息,而消费者(Consumer)则从主题中订阅并处理这些消息。这种解耦的设计使得生产者和消费者可以独立扩展和演化。
// 示例代码:创建 Kafka 消费者组
bin/kafka-consumer-groups.sh --create --bootstrap-server localhost:9092 --group my-group --topic my-topic
3 Offset
Kafka 使用 Offset 来标识每个分区中的消息位置。消费者可以通过记录它们消费的消息的 Offset,以实现断点续传和精确一次处理语义。
// 示例代码:获取消费者组的当前 Offset
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-group --describe
Kafka 的高级特性
除了基本概念之外,Kafka 还提供了一些高级特性,使其更适合复杂的应用场景。
1 事务支持
Kafka 从0.11版本开始引入了事务支持,允许生产者和消费者在多个分区上执行原子操作。
// 示例代码:使用 Kafka 事务
producer.beginTransaction();
try {
producer.send(new ProducerRecord<>("my-topic", "key", "value"));
producer.send(new ProducerRecord<>("my-other-topic", "key", "value"));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.close();
} catch (KafkaException e) {
producer.close();
throw e;
}
2 消息保证
Kafka 提供了不同级别的消息传递保证,包括至多一次(At Most Once)和精确一次(Exactly Once)。
// 示例代码:设置生产者的消息传递语义
properties.put("acks", "all");
Kafka 生态系统的其他组件
Kafka 生态系统中有一些关键的组件,它们进一步扩展了 Kafka 的功能。
1 Kafka Connect
Kafka Connect 是用于可靠地连接 Kafka 与其他数据存储系统的框架。通过 Connect,可以轻松地编写自定义连接器,将数据从其他系统导入或导出到 Kafka 中。
2 Kafka Streams
Kafka Streams 是一个用于构建实时流处理应用程序的库。它允许开发者通过简单的 Java 或 Scala 代码处理和分析 Kafka 主题中的数据。
// 示例代码:使用 Kafka Streams 进行流处理
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> source = builder.stream("input-topic");
source.mapValues(value -> value.toUpperCase())
.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder, properties);
streams.start();
总结
在本文中,深入研究了 Apache Kafka 的起源、设计原则和关键概念,以及其在大数据领域的重要应用。从分布式架构、持久性、高性能等设计原则出发,探讨了 Kafka 在实时数据处理、流式数据处理、实时日志处理等应用场景中的广泛应用,并提供了相应的示例代码。了解 Kafka 的核心概念,如 Topic、Partition、生产者和消费者,以及 Offset 的作用,有助于更好地理解其工作原理。
在高级特性方面,介绍了 Kafka 的事务支持和消息传递保证,为实现原子操作和消息可靠性提供了强大的工具。此外,Kafka 生态系统的其他组件,如 Kafka Connect 和 Kafka Streams,进一步扩展了 Kafka 的功能,使其成为一个强大而全面的实时数据处理平台。
最后,强调了参与 Kafka 社区和利用丰富的学习资源的重要性,以便更好地了解最新的发展和最佳实践。总体而言,Apache Kafka 不仅是一个分布式消息系统,更是构建实时数据处理系统的理想选择,为应对大规模数据和实时性要求提供了可靠的解决方案。























![[ffmpeg] aac 音频编码](https://img-blog.csdnimg.cn/46e1620d67534a27a00c9ab7a93e4c1a.png)