在日常人工智能演示中,比较常用的api展示方式如flask,gradio等Web调用方式。在本文中,详细描述了在编写flask api中语法及语音文本图像模版案例等~
Flask是微型的Python Web框架,如果模型本身就是用python语言构建的,那么利用FLask提供Api服务是一个不错的选择。
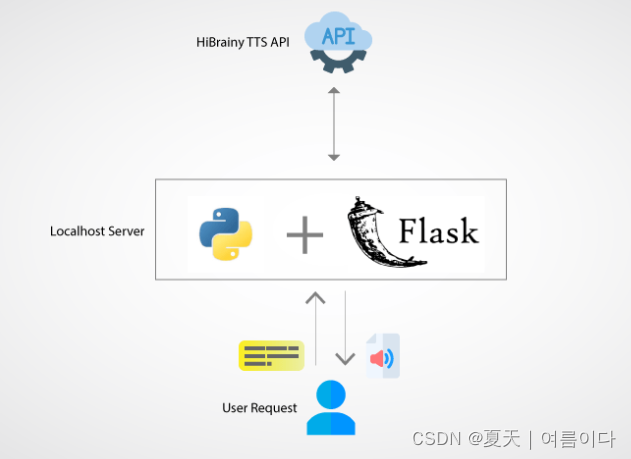
1.深度学习流程

2.Flask重要函数
2.1.flask
语法:
flask():创建一个 flask 应用程序实例
2.2.render_template
语法:
render_template(template_name_or_list, **context):渲染指定的模板文件,并将其传递给模板上下文的变量
#render_template 发送template模块下的html文件
2.3.app.route
语法:
route(rule, options):将一个 url 规则与视图函数绑定,其中rule是一个字符串,表示匹配该 url 规则的 url 字符串;而options则是一个字典,用于在请求对象中设置额外的参数。
定义路由和视图函数 要将URL映射到视图函数,可以使用@app.route()装饰器。视图函数是处理请求并返回响应的函数。也就是根URL映射到名为函数名的视图函数。
2.4.add_url_rule
add_url_rule与app.route都是flask为我们建立路由的方式,两者实现的功能是一样的。
语法:
add_url_rule(rule,endpoint=None,view_func=None)
一共是三个参数:relu、endpoint、view_func,其中rule(path)、view_func是必须填写的参数。
不填写endpoint则会默认使用view_func的名字作为endpoint。
2.5.run
语法:
run(host=none, port=none, debug=none, **options):运行 flask 应用程序,并将其绑定到指定的主机和端口号上。默认情况下,主机为"localhost",端口号为5000。
运行应用程序 最后一步是运行应用程序。在开发过程中,可以使用app.run()方法来启动应用程序。
2.6.request
语法:
request:全局对象,代表客户端向服务器发出的 http 请求。可以使用该对象来访问请求的头部、请求参数、json 数据等等。
2.7.MethodView类视图
视图函数也可以结合类来实现,类视图的好处是支持继承,可以将共性的东西放到父类中,类视图需要使用app.add_url_rule()来进行注册,类视图分为标准类视图和基于调度方法的类视图
标准类视图
标准类视图有标准的写法
- 父类继承
flask.views.View - 子类调用
dispatch_request进行返回,完成业务逻辑 - 子类需要使用
app.add_url_rule进行注册,其中view_func参数不能直接传入子类的名称,需要使用as_view做类方法转换 - 如果同时也指定了
endpoint,endpoint会覆盖as_view指定的视图名,先endpoint名后as_view名
使用类视图,在父类中定义一个属性,在子类中完成各自的业务逻辑,同时都继承父类中的这一个属性
基于方法判断的类视图
如果同一个视图函数需要根据不同的请求方式进行不一样的逻辑处理,需要在视图函数内部进行判断,可以使用方法类视图实现,使用类继承flask.views.MethodView,定义和请求方式同名的小写方法来完成了逻辑处理。
实例:编辑一个页面直接访问是输出用户名密码页面,提交表单后是密码正确与否的提示
from flask.views import View, MethodView
from flask import Flask, render_template, request
app = Flask(__name__)
class MyView(MethodView):
def get(self):
return render_template('index.html')
def post(self):
username = request.form.get('username')
password = request.form.get('password')
if username == "gp" and password == "mypassword":
return '密码正确'
else:
return '密码错误'
app.add_url_rule('/', endpoint='login', view_func=MyView.as_view('login'))
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)在html中定义form标签action属性关联url名
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% macro input(name, type='text', value='') %}
<input type="{
{ type }}" name="{
{ name }}" value="{
{ value }}">
{% endmacro %}
<form action="/" method="post">
<p>用户名:{
{ input('username') }}</p>
<p>密码:{
{ input('password', type='password') }}</p>
{
{ input('submit', type='submit', value='提交') }}
</form>
</body>
</html>2.8.请求用户输入
2.8.1.请求用户输入文本
文本的请求类型如下:
- json
- form
# 请求用户以json文件输入单一文本
input_text = request.json('text')
print("input_text ::: ", input_text)
# 请求用户以表单(form)形式和图片等别的一起输入的文本
input_text1 = request.form('text1')
print("input_text1 ::: ", input_text1)2.8.2.请求用户输入语音文件
# 请求用户输入一个音频
audio_files = request.files.getlist('audio')
print("audio_files ::: ", audio_files)
# 请求用户输入的音频拉成一个列表
audio_files = request.files.getlist('audio')
print("audio_files ::: ", audio_files)2.8.3.请求用户输入照片,视频
# 请求用户输入图像
image_files = request.files('')
print("image_files ::: ",image_files)
# 请求用户输入视频
video_files = request.files('')
print("video_files ::: ",video_files)实例1:基础代码结构如下
API设置中常使用Flask()
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello"
if __name__ == "__main__":
app.run(host="127.0.0.1", port="8080")-> 在第 1 行导入Flask
-> 将第 3 行导入的 Flask 分配给 app 变量。
(这样以后使用flask相关的服务端功能时,就可以调用app并使用该方法)
-> 第5行是前面总结的Python装饰器相关的概念。
:通过使用route方法作为装饰器函数,当“/”路由到对应的API时,会执行底层的hello()函数,因此返回“hello”。
from flask import Flask
import joblib
app = Flask(__name__)
@app.route("/getModel",methods=['GET'])
def getModel():
#根据文件路径load模型
model=joblib.load('/data/model.pkl')
return "model 查询到了"
if __name__ == "__main__":
app.run(host='0.0.0.0',port=5003) # 指定ip:port
app.run(threaded=True) #开启多线程
print('运行结束')
实例2:设置2个路由,查看请求方法
# 生成Flask rest-api
from flask import Flask, request
from flask_cors import CORS
## 拉取 app
app = Flask(__name__)
# 安全库
CORS(app)
@app.route("/predict" , methods=["GET", "POST"])
def predict():
if request.method == "POST":
message = {
"name" : "post请求"
}
return message
if request.method == "GET":
message = {
"name" : "get请求"
}
return message
@app.route("/predict2" , methods=["GET", "POST"])
def predict2():
if request.method == "POST":
message = {
"name" : "post请求 2"
}
return message
if __name__ == '__main__':
app.run(host="0.0.0.0", port=50) # debug=True causes Restarting with stat运行结果
如果出错请参考【PS3】
2.9.返回对象
- jsonify()【6】如果返回的是一个字典,那么调用 jsonify 创建一个响应对象。
- 返回函数的输出
3.输入与输出
3.1. 音频输入与输出
语音流输出音频
from flask import Flask,Response
app = Flask(__name__)
@app.route('/')
def stream_audio():
def generate():
with open('audio.wav','rb') as f:
data=f.read(1024)
while data:
yield data
data=f.read(1024)
return Response(generate(),mimetype='audio/wav')
if __name__=='__main__':
app.run()在上面代码中,创建了一个路由,返回一个流式输出的音频文件,在geerate函数中,使用关键字yield将音频文件分块输出,response对象将会包装这个生成器,并设置正确的MIME类型。
将base64解码为wav音频文件[7]
def base64_to_audio(base64_str): # 用 b.show()可以展示
audio = base64.b64decode(base64_str, altchars=None, validate=False)
wavfile = "filename.wav"
with open(wavfile, "wb") as f:
f.write(audio)
return wavfile
return None4.Flask部署深度学习api接口
4.1.语音类
4.1.1.语音转文本(Speech-To-Text),自己需设置前端版本
app.py
from flask import (Blueprint, flash, redirect, render_template, request)
import requests
bp = Blueprint('home', __name__)
@bp.route('/', methods=['GET', 'POST'])
def home():
url = "http://server_ip:port/api/stt"
if request.method == 'POST':
audio_file = request.files['audio']
model_name = request.form['name']
error = None
if not audio_file:
error = "Audio file is required"
if error is not None:
flash(error)
else:
files = {"audio": audio_file, "name": model_name}
result = requests.post(url, files=files)
return render_template("index.html", result=result)
return render_template("index.html", result=None)templates/index.py
<div class="form-div">
<form action="", method="POST" enctype="multipart/form-data", method="POST">
<label for="audio">Audio: </label>
<input type="file", name="audio", required> <br>
<label for="name">Model:</label>
<select name="name" id="">
<option value="none" selected disabled hidden>Select model</option>
<option value="tiny">tiny</option>
<option value="tiny.en">tiny.en</option>
<option value="base">base</option>
<option value="small">small</option>
<option value="small.en">Small.en</option>
<option value="medium">medium</option>
</select> <br>
<button type="submit">Transcribe</button>
</form>
</div> 结果如图

4.1.2.语音合成(TTS),无需设置前端版本,post进行请求
import sys
from flask import Flask, request, jsonify,render_template
from flask.views import MethodView
from flask_cors import CORS
import argparse
import base64
import librosa
import numpy as np
import matplotlib.pyplot as plt
import io
import logging
import soundfile
import torch
from flask import Flask, request, send_file
from flask_cors import CORS
from flask.views import MethodView
# check device
if torch.cuda.is_available() is True:
device = "cuda:0"
else:
device = "cpu"
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def infer(text, sdp_ratio, noise_scale, noise_scale_w, length_scale, sid):
global net_g
fltstr = re.sub(r"[\[\]\(\)\{\}]", "", text)
stn_tst = get_text(fltstr, hps)
speed = 1
output_dir = 'output'
sid = 0
with torch.no_grad():
x_tst = stn_tst.to(device).unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1 / speed)[0][
0, 0].data.cpu().float().numpy()
return audio
app = Flask(__name__)
#CORS(app, resources={r'/*': {"origins": '*'}})
class run_api(MethodView):
def __init__(self):
pass
def post(self):
# 请求用户输入
data = request.get_json()
text = data['text']
print("Input text:", text)
# 语音参数
sdp_ratio = 0.2
noise_scale = 0.667
noise_scale_w = 0.1
length_scale = 1.0
sid = 0
# 配置文件
config_name = "./config.json"
hps = HParam(config_name)
hps.set_hparam_yaml(config_name)
# 模型权重
checkpoint_path = "./G_179000.pth"
checkpoint = torch.load(checkpoint_path, map_location=device)
#
text = get_text(text)
out_wav_file = infer(text,sdp_ratio, noise_scale, noise_scale_w, length_scale, sid)
print("Input text : ",text)
return "Success", (hps.data.sampling_rate, out_wav_file)
app.add_url_rule("/", view_func=run_api.as_view("run_api"))
if __name__ == '__main__':
app.run(port=6842, host="0.0.0.0", debug=False, threaded=False)
可参考2
Python Web版语音合成实例详解 - Python技术站 (pythonjishu.com)
语音合成后返回一组Base64编码格式的语音数据,用户需要用编程语言或者sdk将返回的Base64编码格式的数据解码成byte数组,再保存为wav格式的音频。
4.2.文本类
4.2.1.文本生成
# -*- coding: utf-8 -*-
import sys
from flask import Flask, request, jsonify
from flask_cors import CORS
import argparse
import torch
import os
#os.system('apt-get update')
#os.system('apt install gcc')
#os.system('pip install request')
from transformers import pipeline, AutoModelForCausalLM
parser = argparse.ArgumentParser()
parser.add_argument('--prefix', type=str, default='/')
parser.add_argument('--port', type=int, default=8555)
args = parser.parse_args()
chat_history = []
for i in range(3):
chat_history.append({"###提问":"","###回答":""})
app = Flask(__name__)
CORS(app, resources={r'/*': {"origins": '*'}})
def ask(x, context='', is_input_full=False):
history = str(chat_history[-1]) + '\n' + str(chat_history[-2]) + '\n' + str(chat_history[-3]) + '\n'
ans = pipe(
f"### 对话记录: {history}\n" +
f"### 提问: {x}\n\n### 上下文: {context}\n\n### 回答:" if context else f"### 提问: {x}\n\n### 回答:",
do_sample=True,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
return_full_text=False,
eos_token_id=2,
)
return ans[0]['generated_text']
@app.route(args.prefix, methods=["POST"])
def API():
print(request, flush=True)
text1 = request.json['text']
result = ask(text1)
chat_history.append({"###提问":str(text1),"###回答":str(result)})
print(result, flush=True)
output = {
"text": [
{
"历史记录": str(chat_history[-3:])
},
{
"输入": str(text1)
},
{
"@LLM大语言模型": str(result)
}
]
}
return jsonify(output)
if __name__ == '__main__':
MODEL = 'GPT12.8B'
model = AutoModelForCausalLM.from_pretrained(
MODEL,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(device=f"cuda", non_blocking=True)
model.eval()
pipe = pipeline(
'text-generation',
model=model,
tokenizer=MODEL,
device=0
)
app.run(host="0.0.0.0", port=args.port, debug=True) # debug=True causes Restarting with stat
5.设置flask API时出现错误总结
出现400:Bed Request 坏请求
- 请求的文件不存在,或者文件路径不对
出现500:internal server error内部服务器错误
- 文件传输方法不对
***注意输入输出的请求及传输
6.总结
在制作人工智能模型flask api时,总结如下
- 首先设置flask 所需类以及路由,运行端口等
- 第二设置好模型所需的结构,一般情况下都在推理文件中,确保所需类都可以被调用
- 第三确定模型的输入:图片视频文本,每个输入单独写请求
最容易出错的部分就是第三部分,因为模型的话只要调用原有的就可以,出现的大部分错误是在运行后出现400,405,500等错误,首先大概率是api编写错误,其次是网络等问题~
过程中遇到的错误与解决【PS】
【PS1】Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding
致命的Python错误: init_fs_encoding:无法获取文件系统的Python编解码器编码Python运行时状态:核心初始化的ModuleNotFoundError:没有名为'encodings‘的模块

如果将这两个环境变量设置为nil,问题应该会消失: set PYTHONHOME= set PYTHONPATH=
错误原因:pip不小心删除
sudo apt-get remove python-pip-whl
sudo apt -f install
sudo apt update && sudo apt dist-upgrade
sudo apt install python3-pip
pip install certifi
pip install chardet
pip install idna
pip instal urllib3【PS2】 ImportError: cannot import name 'BaseResponse' from 'werkzeug.wrappers' (/usr/local/lib/python3.8/dist-packages/werkzeug/wrappers/__init__.py)
这个错误可以重新安装werkzeug
pip install --upgrade werkzeug==1.0.1然后就好啦~
【PS3】get请求出现404
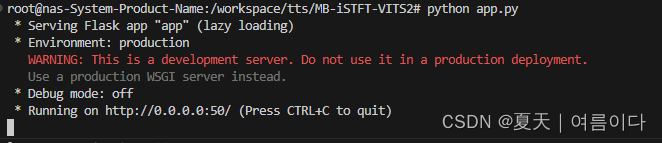
python app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off

警告是因为在开发环境中,Flask应用程序是使用内置的服务器(如SimpleServer或Lighttpd)运行的,而不是使用WSGI服务器。和最终出现的404没有关系!!
原因分析
- 上一个项目运行没有终止
- 端口(12.0.0.1:5000)被占用
最终原因
Flask的代码编写错误
【PS4】Flask请求出现500


500错误是指服务器内部出错,无法完成请求的情况。这可能是由于程序错误、错误的配置等原因造成的。
在此处是因为找不到样本中的html文件。
错误原因:文件格式错误
原格式
----app
---templates
----index.html
----run.py
修改后正确
---templates
----index.html
----run.py
在同一目录下!!
【PS5】Flask设置api时出现405,405等
有俩个路由的情况
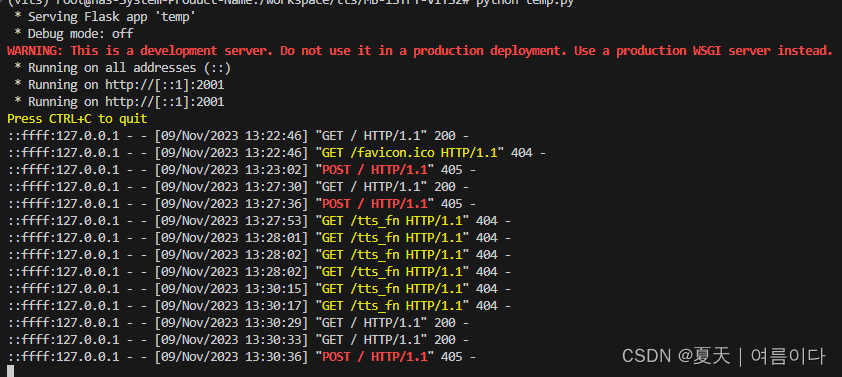
出现405

提交信息后,未找到
【PS6】NameError: name 'api_monitor' is not defined
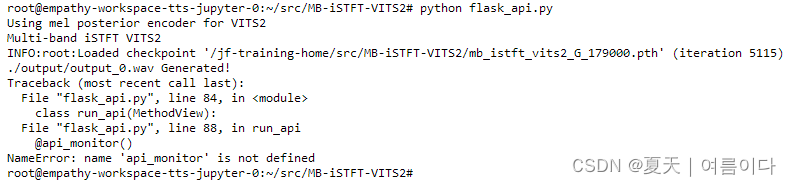
自定义方法,官方文档并没有此方法,自己重新定义或者删掉就可以~
参考文献
【1】app.py · RamAnanth1/Dolly-v2 at main (huggingface.co)
【2】 [Flask/Postman] Flask로 간단한 서버 구현, postman으로 테스트 (tistory.com)
【3】Flask 极致细节:1. 路由和请求响应规则,GET/POST,重定向_@app.route post_破浪会有时的博客-CSDN博客【4】Deploy a Flask REST API - The Docker way and the Serverless way (amlanscloud.com)
【5】Building Scalable REST APIs using Heroku Flask MongoDB: 6 Easy Steps - Learn | Hevo (hevodata.com)【6】Flask 学习-88. jsonify() 函数源码解读深入学习 - 上海-悠悠 - 博客园 (cnblogs.com)
【7】 Base64 Encoding and Decoding Using Python | Envato Tuts+ (tutsplus.com)
【8】How to Build a Text to Speech App (Python & Flask) [TTS API Python Tutorial] (rapidapi.com)
【9】Flask REST API Tutorial - Python Tutorial (pythonbasics.org)






















![pdf文件编辑,[增删改查]](https://img-blog.csdnimg.cn/direct/0c9c29b4616a42e98555485f36a3ea32.png)