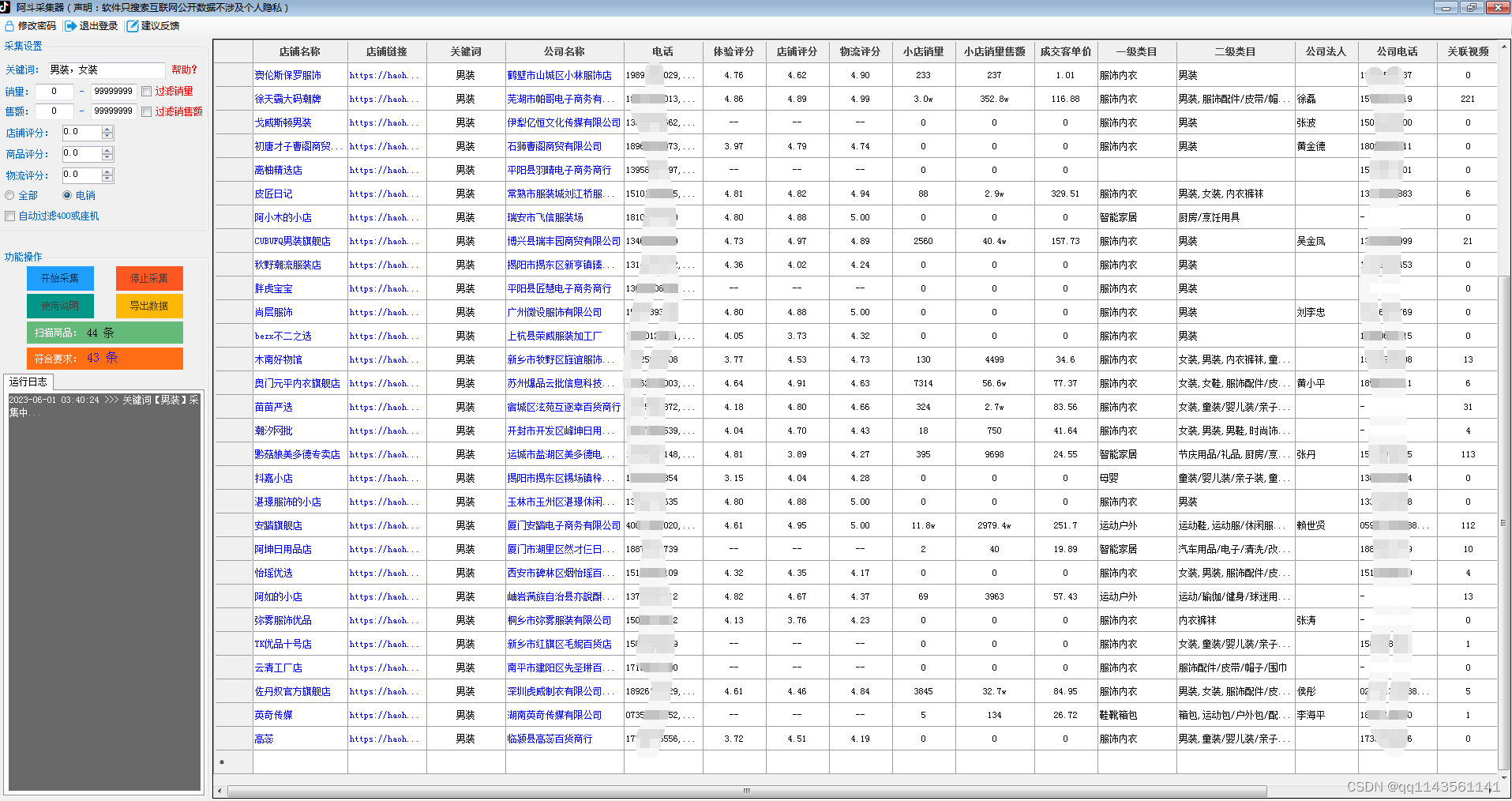
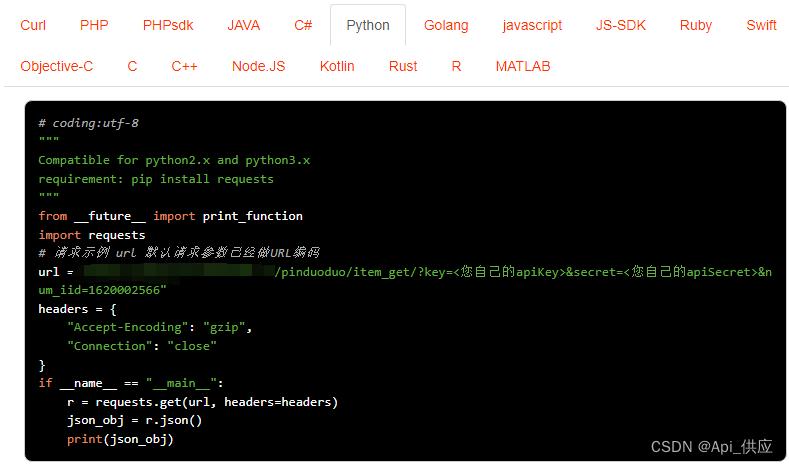
随着互联网的发展,电商平台的竞争也越来越激烈。对于商家来说,要想在激烈的市场竞争中占据一席之地,就需要有自己的优势。其中,采集其他商家的商品信息就是一个比较重要的环节。今天,我们就来介绍如何用爬虫软件实现拼多多商家采集。
一、准备工作
在进行拼多多商家采集之前,需要先准备好以下工具:
Python编程语言
爬虫软件(如:BeautifulSoup、Scrapy等)
拼多多API接口
二、实现步骤
1、导入所需模块
首先,我们需要导入Python中的requests模块和beautifulsoup4模块,以便进行网络请求和解析网页内容。
python
import requests from bs4 import BeautifulSoup
2、发送网络请求
接下来,我们需要使用requests模块向拼多多API接口发送网络请求,获取需要采集的商品信息。
python
url = 'https://s.pinduoduo.com/app/home' response = requests.get(url)
3、解析网页内容
获取到拼多多API接口返回的HTML页面后,我们可以使用beautifulsoup4模块解析网页内容,提取出需要的信息。
python
soup = BeautifulSoup(response.content, 'html.parser') items = soup.find_all('div', class_='item') for item in items: title = item.find('h3').text.strip() price = item.find('span', class_='price').text.strip() img = item.find('img')['src'] print(title, price, img)
4、存储采集结果
最后,我们将采集到的商品信息保存到本地文件或者数据库中,以备后续使用。
python
with open('product.txt', 'w', encoding='utf-8') as f f.write(title + ' ') f.write(price + ' ') f.write(img + ' ')
三、总结
以上就是如何用爬虫软件实现拼多多商家采集的整个过程。当然,在实际使用过程中,还需要考虑一些特殊情况的处理,比如网络异常、页面结构变化等问题。但是,只要我们掌握了基本的思路和方法,就可以很容易地实现商品信息的采集。