1.MySQL请求处理
1.1.查询缓存
MySQL 服务器程序处理查询请求时,会把刚刚处理过的查询请求和结果缓存起来,如果下一次有一模一样的请求过来,直接从缓存中查找结果就好了,就不用再傻呵呵的去底层的表中查找了。这个查询缓存可以在不同客户端之间共享,也就是说如果客户端A刚刚查询了一个语句,而客户端B之后发送了同样的查询请求,那么客户端B的这次查询就可以直接使用查询缓存中的数据。
如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如mysql 、information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。
不过既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
从 MySQL 5.7.20 开始,不推荐使用查询缓存,并在MySQL 8.0中删除。因为缓存的维护也需要较多开销。
1.2.分析请求内容
1.3.对请求分析后,对实现方式进行优化。优化后得到执行计划。执行计划就是服务端如何操作以便响应此请求。
2.存储引擎
将MySQL数据访问部分提取成一个模块,这个模块就是存储引擎。存储对外提供统一的数据访问接口。存储引擎部分主要分析InnoDB。
InnoDB支持以下特性:
B-tree indexes
Backup/point-in-time recovery
Clustered indexes
Compressed data
Data caches
Encrypted data
Foreign key support
Full-text search indexes
Geospatial data type support
Geospatial indexing support
Index caches
Locking granularity–Row
MVCC
Query cache support
Replication support
Storage limits–64TB
Transactions
Update statistics for data dictionary
3.存储引擎粒度
每个表允许设置独立的存储引擎。
示例:创建时指定
mysql> CREATE TABLE engine_demo_table(
-> i int
-> ) ENGINE = MyISAM;
示例:创建后修改
mysql> ALTER TABLE engine_demo_table ENGINE = InnoDB;
4.字符集和比较规则
4.1.字符集
建立字符与二进制数据的映射关系了,建立这个关系最起码要搞清楚两件事儿:
(1). 你要把哪些字符映射成二进制数据?
(2). 怎么映射?
将一个字符映射成一个二进制数据的过程也叫做 编码 ,将一个二进制数据映射到一个字符的过程叫做 解码 。
人们抽象出一个 字符集 的概念来描述某个字符范围的编码规则。
比方说我们来自定义一个名称为 test 的字符集,它包含的字符范围和编码规则如下:
a.包含字符 ‘a’ 、 ‘b’ 、 ‘A’ 、 ‘B’ 。
b.编码规则如下:
采用1个字节编码一个字符的形式,字符和字节的映射关系如下:
‘a’ -> 00000001 (十六进制:0x01)
‘b’ -> 00000010 (十六进制:0x02)
‘A’ -> 00000011 (十六进制:0x03)
‘B’ -> 00000100 (十六进制:0x04)
有了 test 字符集,我们就可以用二进制形式表示一些字符串了,下边是一些字符串用 test 字符集编码后的二进制表示:
‘bA’ -> 0000001000000011 (十六进制:0x0203)
‘baB’ -> 000000100000000100000100 (十六进制:0x020104)
‘cd’ -> 无法表示,字符集 test 不包含字符’c’和’d’
4.2.比较规则简介
在我们确定了 test 字符集表示字符的范围以及编码规则后,怎么比较两个字符的大小呢?
最容易想到的就是直接比较这两个字符对应的二进制编码的大小,比方说字符 ‘a’ 的编码为 0x01 ,字符 ‘b’ 的编码为 0x02 ,所以 ‘a’ 小于 ‘b’ ,这种简单的比较规则也可以被称为二进制比较规则,英文名为 binary collation 。
二进制比较规则是简单,但有时候并不符合现实需求,比如在很多场合对于英文字符我们都是不区分大小写的,也就是说 ‘a’ 和 ‘A’ 是相等的,在这种场合下就不能简单粗暴的使用二进制比较规则了,这时候我们可以这样指定比较规则:
(1). 将两个大小写不同的字符全都转为大写或者小写。
(2). 再比较这两个字符对应的二进制数据。
同一种字符集可以有多种比较规则。
4.3.一些重要的字符集
我们看一下一些常用字符集的情况:
(1). ASCII 字符集
共收录128个字符,包括空格、标点符号、数字、大小写字母和一些不可见字符。由于总共才128个字符,所以可以使用1个字节来进行编码,我们看一些字符的编码方式:
‘L’ -> 01001100(十六进制:0x4C,十进制:76)
‘M’ -> 01001101(十六进制:0x4D,十进制:77)
(2). utf8 字符集
收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容 ASCII 字符集,采用变长编码方式,编码一个字符需要使用1~4个字节,比方说这样:
‘L’ -> 01001100(十六进制:0x4C)
‘啊’ -> 111001011001010110001010(十六进制:0xE5958A)
其实准确的说,utf8只是Unicode字符集的一种编码方案,Unicode字符集可以采用utf8、utf16、utf32这几种编码方案,utf8使用1~4个字节编码一个字符,utf16使用2个或4个字节编码一个字符,utf32使用4个字节编码一个字符。
MySQL中并不区分字符集和编码方案的概念,所以后边把utf8、utf16、utf32都当作一种字符集对待。
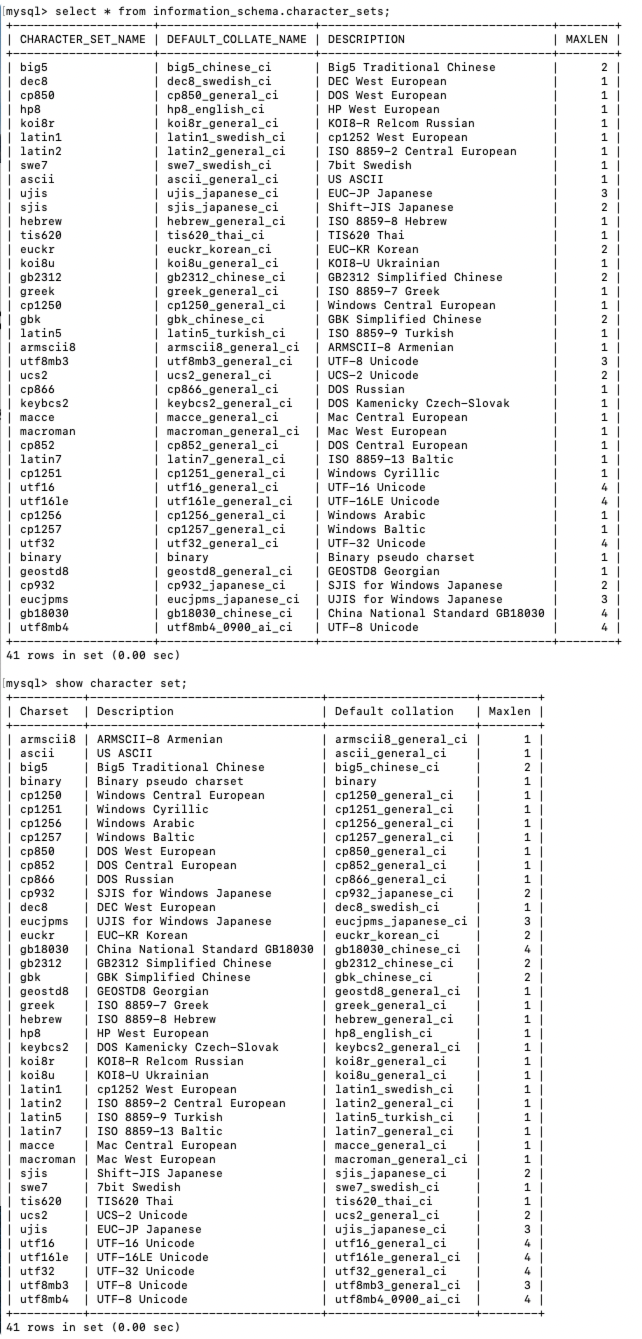
5.MySQL中支持的字符集和排序规则
5.1.MySQL中的utf8和utf8mb4
utf8 字符集表示一个字符需要使用1~4个字节,但是我们常用的一些字符使用1~3个字节就可以表示了。而在 MySQL 中字符集表示一个字符所用最大字节长度在某些方面会影响系统的存储和性能,所以设计MySQL 的大叔偷偷的定义了两个概念:
(1). utf8mb3 :阉割过的 utf8 字符集,只使用1~3个字节表示字符。
(2). utf8mb4 :正宗的 utf8 字符集,使用1~4个字节表示字符。
5.2.MySQL中排序规则分析
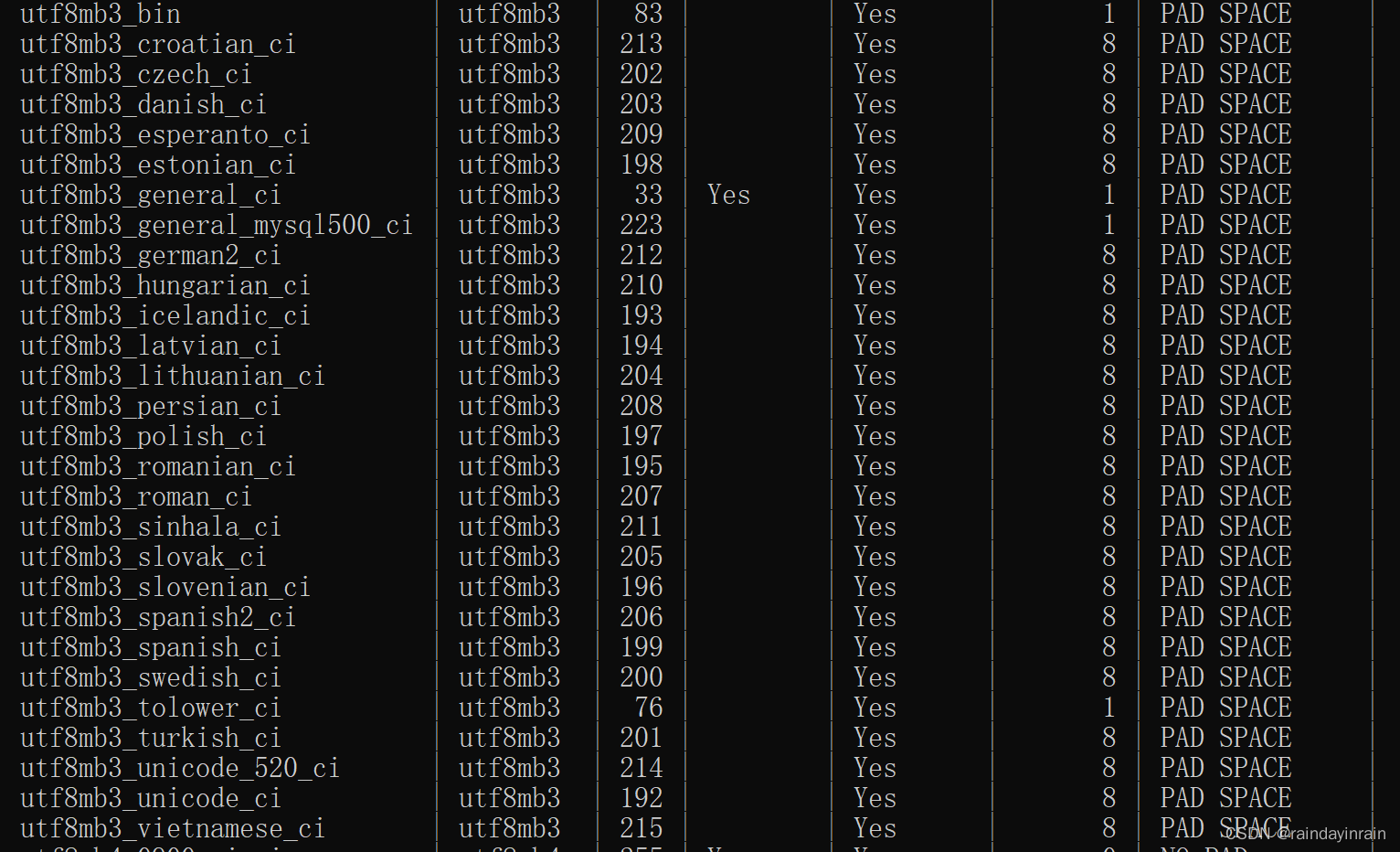
上述是执行:SHOW COLLATION;显示的比较规则中utf8mb3编码方式相关的。可以看到比较规则特点有:
(1). 比较规则名称以与其关联的字符集的名称开头。
(2). 后边紧跟着该比较规则主要作用于哪种语言。
(3). 名称后缀意味着该比较规则是否区分语言中的重音、大小写啥的。
| 后缀 | 含义 |
|---|---|
| _ci | 不区分大小写 |
| _cs | 区分大小写 |
| _ai | 不区分重音 |
| _as | 区分重音 |
| _bin | 以二进制方式比较 |
5.3.MySQL字符集和比较规则的级别
MySQL 有4个级别的字符集和比较规则,分别是:
(1).服务器级别
(2).数据库级别
(3).表级别
(4).列级别
需要注意的是,对于存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则。我们在创建和修改列定义的时候可以指定该列的字符集和比较规则,语法如下:
CREATE TABLE 表名(
列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称],
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
一个实例:比如我们修改一下表 t 中列 col 的字符集和比较规则可以这么写:
ALTER TABLE t MODIFY col VARCHAR(10) CHARACTER SET gbk COLLATE gbk_chinese_ci;
注意:在转换列的字符集时需要注意,如果转换前列中存储的数据不能用转换后的字符集进行表示会发生错误。
5.4.修改注意事项
(1).仅修改字符集或仅修改比较规则
由于字符集和比较规则是互相有联系的,如果我们只修改了字符集,比较规则也会跟着变化,如果只修改了比较规则,字符集也会跟着变化,具体规则如下:
a.只修改字符集,则比较规则将变为修改后的字符集默认的比较规则。
b.只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
5.5.客户端和服务器通信中的字符集
5.5.1.编码和解码使用的字符集不一致的后果
我们知道字符 ‘我’ 在 utf8 字符集编码下的字节串长这样: 0xE68891 ,如果一个程序把这个字节串发送到另一个程序里,另一个程序用不同的字符集去解码这个字节串。
假设使用的是 gbk 字符集来解释这串字节,解码过程就是这样的:
(1). 首先看第一个字节 0xE6 ,它的值大于 0x7F (十进制:127),说明是两字节编码,继续读一字节后是 0xE688 ,然后从 gbk 编码表中查找字节为 0xE688 对应的字符,发现是字符 ‘鎴’。
(2). 继续读一个字节 0x91 ,它的值也大于 0x7F ,再往后读一个字节发现木有了,所以这是半个字符。
(3). 所以 0xE68891 被 gbk 字符集解释成一个字符 ‘鎴’ 和半个字符。
假设用 iso-8859-1 ,也就是 latin1 字符集去解释这串字节,解码过程如下:
(1). 先读第一个字节 0xE6 ,它对应的 latin1 字符为 æ 。
(2). 再读第二个字节 0x88 ,它对应的 latin1 字符为 ˆ 。
(3). 再读第二个字节 0x91 ,它对应的 latin1 字符为 ‘ 。
(4). 所以整串字节 0xE68891 被 latin1 字符集解释后的字符串就是 ‘我’
可见,如果对于同一个字符串编码和解码使用的字符集不一样,会产生意想不到的结果,作为人类的我们看上去就像是产生了乱码一样。
5.5.2.字符集转换的概念
如果接收 0xE68891 这个字节串的程序按照 utf8 字符集进行解码,然后又把它按照 gbk 字符集进行编码,最后编码后的字节串就是 0xCED2 ,我们把这个过程称为 字符集的转换 ,也就是字符串 ‘我’ 从 utf8 字符集转换为 gbk 字符集。
5.5.3.MySQL中字符集的转换
我们知道从客户端发往服务器的请求本质上就是一个字符串,服务器向客户端返回的结果本质上也是一个字符串,而字符串其实是使用某种字符集编码的二进制数据。这个字符串可不是使用一种字符集的编码方式一条道走到黑的,从发送请求到返回结果这个过程中伴随着多次字符集的转换,在这个过程中会用到3个系统变量,我们先把它们写出来看一下:
| 系统变量 | 描述 |
|---|---|
| character_set_client | 服务器解码请求时使用的字符集 |
| character_set_connection | 服务器处理请求时会把请求字符串从 character_set_client 转为 character_set_connection |
| character_set_results | 服务器向客户端返回数据时使用的字符集 |
(1). 从发送请求到接收结果过程中发生的字符集转换:
a.客户端使用操作系统的字符集编码请求字符串,向服务器发送的是经过编码的一个字节串。
b.服务器将客户端发送来的字节串采用 character_set_client 代表的字符集进行解码,将解码后的字符串再按照 character_set_connection 代表的字符集进行编码。
c.如果 character_set_connection 代表的字符集和具体操作的列使用的字符集一致,则直接进行相应操作,否则的话需要将请求中的字符串从 character_set_connection 代表的字符集转换为具体操作的列使用的字符集之后再进行操作。
d.将从某个列获取到的字节串从该列使用的字符集转换为 character_set_results 代表的字符集后发送到客户端。
e.客户端使用操作系统的字符集解析收到的结果集字节串。
(2). 注意点:
a. 服务器认为客户端发送过来的请求是用 character_set_client 编码的。
假设你的客户端采用的字符集和 character_set_client 不一样的话,这就会出现意想不到的情况。
采用MySQL官方客户端程序时,windows系统下,客户端默认采用gbk发送请求;类Unix系统下,客户端默认采用utf8mb3发送请求。
b. 服务器将把得到的结果集使用 character_set_results 编码后发送给客户端。
假设你的客户端采用的字符集和 character_set_results 不一样的话,这就可能会出现客户端无法解码结果集的情况,结果就是在你的屏幕上出现乱码。
c. character_set_connection 只是服务器在将请求的字节串从 character_set_client 转换为 character_set_connection 时使用,它是什么其实没多重要,但是一定要注意,该字符集包含的字符范围一定涵盖请求中的字符,不然会导致有的字符无法使用 character_set_connection 代表的字符集进行编码。
d. 如果执行请求处理计划时,涉及列访问时,访问列的字符集和 character_set_connection 不一致。则MySQL自动将character_set_connection 编码的请求中相应内容转换为列的字符集,再执行列访问。
(3). 最佳实践:
我们通常都把 character_set_client 、character_set_connection、character_set_results 这三个系统变量设置成和客户端使用的字符集一致的情况,这样减少了很多无谓的字符集转换。为了方便我们设置, MySQL 提供了一条非常简便的语句:SET NAMES 字符集名;
这一条语句产生的效果和我们执行这3条的效果是一样的:
SET character_set_client = 字符集名;
SET character_set_connection = 字符集名;
SET character_set_results = 字符集名;
这三个系统变量在服务端层面允许为每个客户端接入维持一份。