目录
一、正则表达式
1.正则表达式基本介绍
元字符:不表示本来的含义,在正则表达式中有特殊含义的字符
正则表达式就是元字符的使用
2.正则表达式分类
正则表达式分为:
1.基本正则表达式
2.扩展正则表达式
3.基本正则表达式分类
1.代表字符
2.表示次数
3.位置锚定
4.分组与其他
4.代表字符
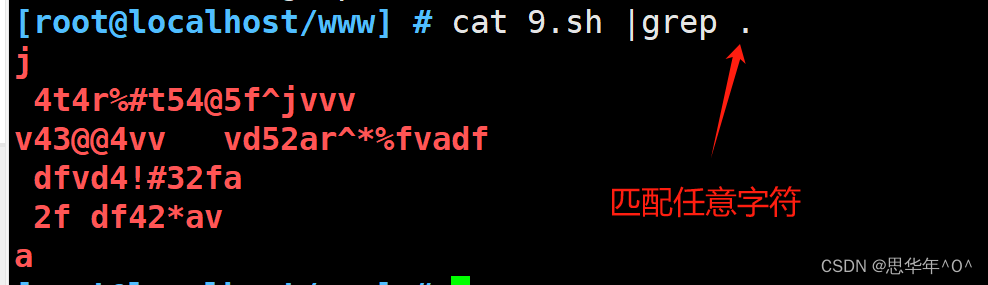
.匹配任意单个字符,包括汉字
[]匹配指定范围内的任意单个字符
[^]匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等,等价于 [ \f\n\r\t\v]。注意
Unicode 正则表达式会匹配全角空格符
元字符点(.)
[root@localhost ~]# ls /etc/|grep rc[.0-6]
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@localhost ~]# ls /etc/|grep 'rc\.' #点需要加转义字符
rc.d
rc.local
[root@localhost ~]# grep r..t /etc/passwd #r..t ..代表任意两个字符
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@localhost ~]# echo abc |grep a.c
abc
[root@localhost ~]# echo abc |grep a\.c #这里需要加引号和转义字符
abc
[root@localhost ~]# echo abc |grep "a\.c"
[root@localhost ~]#
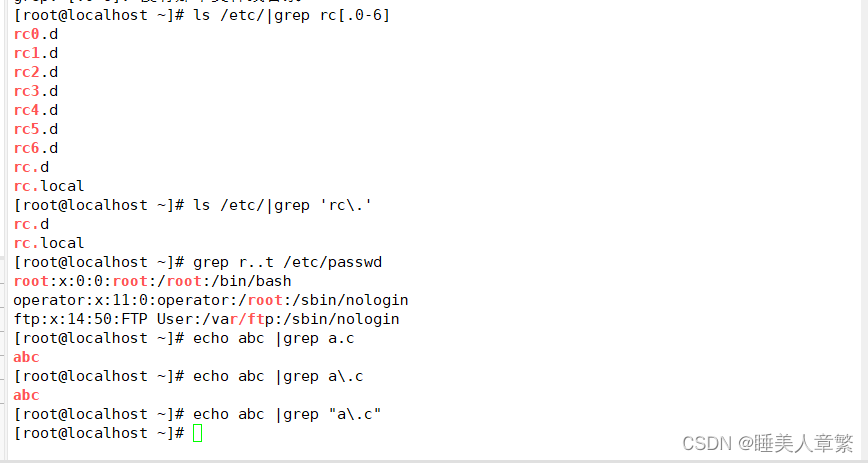
[root@localhost sy]# grep [[:space:]] lc.txt
sjs
osk
skm smod
[root@localhost sy]# grep [[:space:]] lc.txt|cat -A #过滤空行并查看
sjs $
osk$
skm smod$

5.表示次数
* #匹配前面的字符任意次,包括0次
.* #任意长度的任意字符,不包括0次
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
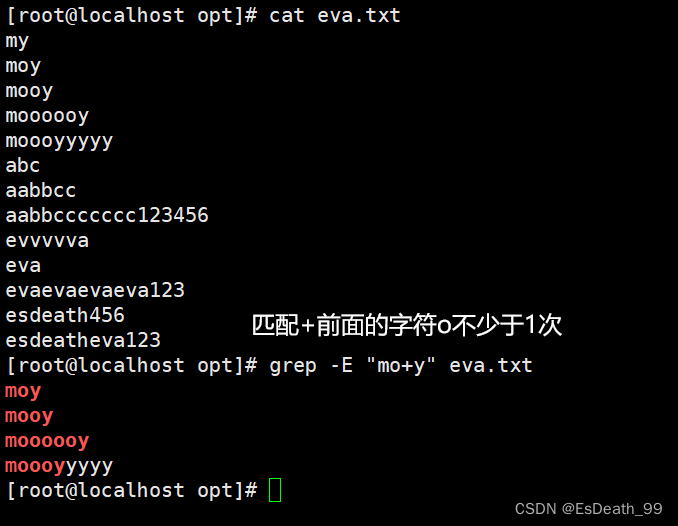
[root@localhost sy]# echo google |grep 'go\{2\}gle' #\{2\}代表前面的o出现2次
[root@localhost sy]# echo goooogle |grep 'go\{2,\}gle' #\{2,\}代表前面的o出现2次以上
goooogle
[root@localhost sy]# echo gooooogle |grep 'go\{2,5\}gle' #\{2,5\}代表前面的o出现2到5次
gooooogle
[root@localhost sy]# echo gooooooogle |grep 'go*gle' #*代表前面的o出现0到任意次
gooooooogle
[root@localhost sy]# echo google |grep 'go*gle'
[root@localhost sy]# echo ggle |grep 'go*gle'
ggle
[root@localhost sy]# echo gjevfnsjkgbgle |grep 'g.*gle' #.*代表任意匹配所有
gjevfnsjkgbgle
[root@localhost sy]# echo gjgle |grep 'g.*gle'
gjgle
[root@localhost sy]# echo ggle |grep 'g\?gle' #\?代表一次或者0次
ggle
[root@localhost sy]# echo gooogle |grep 'go\+gle' #\+代表一个以上
gooogle
6.位置锚定
^ 代表开头
$ 代表结尾
\<和\b 代表字符串的开头,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\>和\b 代表字符串的结尾,用于单词模式的右侧
\<单词\> 匹配整个单词
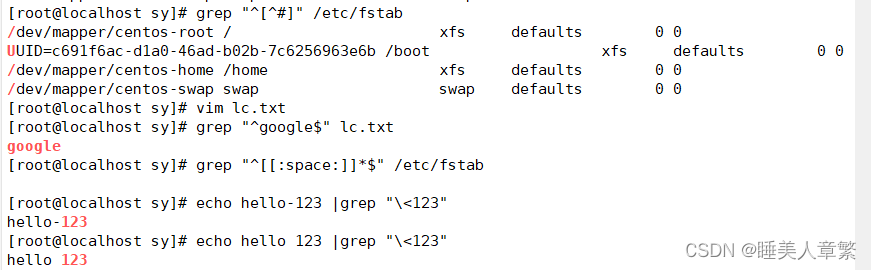
[root@localhost sy]# grep "^[^#]" /etc/fstab #过滤出不是#号开头的行
/dev/mapper/centos-root / xfs defaults 0 0
UUID=c691f6ac-d1a0-46ad-b02b-7c6256963e6b /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
[root@localhost sy]# vim lc.txt
[root@localhost sy]# grep "^google$" lc.txt #只过滤google
[root@localhost sy]# grep "^[[:space:]]*$" /etc/fstab #只匹配空白行[root@localhost sy]# echo hello-123 |grep "\<123" #只匹配123
hello-123
[root@localhost sy]# echo hello 123 |grep "\<123"
hello 123
[root@localhost sy]#
7.分组或其他
分组:使用( ) 将多个字符捆绑在一起,当作一个整体处理,如(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\|:代表或者
[root@localhost sy]# echo abccc |grep "abc\{3\}"
abccc
[root@localhost sy]# echo abcabcabc |grep "\(abc\)\{3\}"
abcabcabc
[root@localhost sy]# echo 1abc |grep "1\|2abc"
1abc
[root@localhost sy]# echo 1abc |grep "\(1\|2\)abc"
1abc
[root@localhost sy]# echo 2abc |grep "\(1\|2\)abc"
2abcifconfig ens33 |grep netmask|grep -Eo '([0-9]{1,3}.){4}'
172.16.114.10
255.255.255.0
172.16.114.255
8.扩展正则表达式
grep -E
1.表示次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} #匹配前面的字符至多n次,<=n,n可以为0
{n,} #匹配前面的字符至少n次,<=n,n可以为0
2.表示分组
() 分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+
后向引用:\1, \2, ...
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
3.练习:
表示qq号
[root@localhost ~]# echo "940132245" |grep "\b[0-9]\{6,12\}\b"
940132245
表示邮箱
echo "zhou@qq.com" |grep -E "[[:alnum:]_]+@[[:alnum:]_]+\.[[:alnum:]_]+"
zhou@qq.com
表示手机号
echo "13703296734"|grep -E "\b1[3456789][0-9]{9}\b"
13703296734

二、awk
1.语法
awk [选项] '表达式 {处理动作}'
表达式:找到特定的行
处理动作:print打印 printf打印
2.选项
-F 指定分隔符
-v 指定变量
-f 脚本
3.基础用法
[root@localhost ~]# awk '{print}'
^C
[root@localhost ~]# awk '{print}'
dd
dd
dd
dd
^C
[root@localhost ~]# awk '{print "hello"}'
1
hello
1
hello
1
hello
^C
[root@localhost ~]# awk 'BEGIN {print 100*20}'
2000awk -F: 'BEGIN {print "hello"} {print $1}' /etc/passwd |head -n3 #先处理BEGIN 中的式子
hello
root
bin[root@localhost ~]# echo {a..b} |awk '{print $1}'
a
[root@localhost ~]# df|awk '{print $5}'
已用%
12%
0%
0%
1%
0%
18%
1%
1%
0%[root@localhost ~]# cat /etc/passwd|awk -F: '{print $1"\t"$3}'|head -n2
root 0
bin 1df |awk -F"( +|%)" '{print $5}'
已用
12
0
0
1
0
18
1
1
0ifconfig ens33|grep netmask |awk '{print $2}' #提前IP地址
172.16.114.10
4.内置变量
awk 选项 '模式{print }'
1.FS :指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
2.OFS:输出时的分隔符
3.NF:当前处理的行的字段个数
4.NR:当前处理的行的行号(序数)
5.$0:当前处理的行的整行内容
6.$n:当前处理行的第n个字段(第n列)
7.FILENAME:被处理的文件名
8.RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次
[root@localhost ~]# awk -v FS=':' '{print $1FS$3}' /etc/passwd |head -n3
root:0
bin:1
daemon:2
[root@localhost ~]# awk -F: '{print $1":"$3}' /etc/passwd |head -n2
root:0
bin:1
[root@localhost ~]# fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd |head -n3
root:0
bin:1
daemon:2
#如果-F -FS一起使用 -F的优先级高[root@localhost ~]# echo $PATH |awk -v RS=':' '{print $0}'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/binawk -F: '{print NF}' /etc/passwd #代表字段的个数
7
7
[root@localhost ~]# awk -F: '{print $NF}' /etc/passwd #$NF最后一个字段
/bin/bash
/sbin/nologin
/sbin/nologin[root@localhost ~]# df |awk -F "[ %]+" '{print $(NF-1)}' #倒数第二行
已用
12
0
0
1
0
18
1
1
0[root@localhost ~]# awk 'NR==2{print $1}' /etc/passwd #只取第二行的第一个字段
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost ~]# awk 'NR==1,NR==3{print $1}' /etc/passwd #打印出1到3 行的第一个字段
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologinawk 'NR==1||NR==3{print $1}' /etc/passwd #打印出1和3行
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin[root@localhost ~]# awk '(NR%2)==0{print NR}' /etc/passwd #打印出函数取余数为0行
2
4
6
[root@localhost ~]# awk '(NR%2)==1{print NR}' /etc/passwd #打印出函数取余数为1的行
1
3
5
[root@localhost ~]# awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/syncawk -F: '$3>1000{print}' /etc/passwd
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin #打印出普通用户 过滤第三列 大于1000 的行awk '/^UUID/{print $1}' /etc/fstab
UUID=c691f6ac-d1a0-46ad-b02b-7c6256963e6b
5.条件判断
awk -F: '{if($3>1000)print $1,$3}' /etc/passwd
nfsnobody 65534
[root@localhost ~]# awk -F: '{if($3>1000){print $1,$3}else{print $3}}' /etc/passwd
0
1
2
3
4
5
6
7
8
11
12
14
99
192
81
999
6.数组
awk数组特性:
1.awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串 1. 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串 2. awk的数组元素的顺序和元素插入时的顺序很可能是不相同的
2.awk数组支持数组的数组
awk 'BEGIN{a[1]="lc";print a[1]}'
lc
[root@localhost ~]# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
Mondayawk 'BEGIN{a[1]=1;a[2]=2;print length(a);print length("hello")}' #可以查看数组长度
2
5
去除重复行
cat b.txt
abc
hlj
lsdn
abc
hlj
njds
lksamnf
kfd
[root@localhost sy]# awk '{a[$1]++}END{for (i in a){print i}}' b.txt
lksamnf
njds
hlj
abc
kfd
lsdn
提取下面的字段中的 IP地址和时间
awk
58.87.87.99 - - [09/Jun/2020:03:42:43 +0800] "POST /wp-cron.php?doing_wp_cron=1591645363.2316548824310302734375 HTTP/1.1" ""sendfileon
128.14.209.154 - - [09/Jun/2020:03:42:43 +0800] "GET / HTTP/1.1" ""sendfileon
64.90.40.100 - - [09/Jun/2020:03:43:11 +0800] "GET /wp-login.php HTTP/1.1"""sendfileo
cat b.txt |awk -F"[ []" '{print $1,$5}'
58.87.87.99 09/Jun/2020:03:42:43
128.14.209.154 09/Jun/2020:03:42:43
64.90.40.100 09/Jun/2020:03:43:11
提取host.txt主机名后再放回host.txt文件 >>
1 www.kgc.com
2 mail.kgc.com
3 ftp.kgc.com
4 linux.kgc.com
5 blog.kgc.com
[root@localhost sy]# cat host.txt |awk -F"." '{print $1}' >> host.txt
[root@localhost sy]# cat host.txt
www.kgc.com
mail.kgc.com
ftp.kgc.com
linux.kgc.com
blog.kgc.com
www
ftp
linux
blog